
Обобщенный метод наименьших квадратов
7.4. Обобщенный метод наименьших квадратов
Рассмотрим теперь модели, в которых переменные отклика коррелированные или они имеют разные дисперсии, так что С(y)≠s2I. В статистическом линейном моделировании большие значения фактора xi могут приводить к большим значениям дисперсии D(yi) переменной отклика. В любой простой или множественной регрессии, если значения переменных y1, y2, ..., yп отклика получаются в следующие один за другим моменты времени, то они, как правило, коррелированы. Для случаев, где допущение С(y)=s2I не соблюдается, используется следующая линейная модель
у=Xw+e (7.4.1)
с соответствующими допущениями Е(у)=Xw, Е(e)=0 и С(y)=С(e)=S=sк2V, где X - матрица модели полного ранга, w - вектор параметров модели и V - известная положительно определённая матрица. Матрица V размеров nxn имеет п2 элементов и, если она неизвестна, то её элементы не могут быть оценены по выборке из п значений переменных отклика. В некоторых случаях (см. пример 7.4.1) предполагается простая структура матрицы V, что позволяет её оценить.
Оценка параметров модели и дисперсии при наличии ковариаций
В следующей теореме приводится оценка вектора w параметров модели (7.4.1) и дисперсии sк2.
Теорема 7.4.1. Пусть для модели у=Xw+e справедливы допущения Е(у)=Xw, Е(e)=0 и С(y)=С(e)=sк2V, где X - матрица полного ранга и V - известная положительно определённая матрица. Тогда для этой модели:
- Наилучшая линейная несмещённая оценка вектора w выполняется по формуле
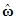 =(XТV–1X)–1XТV–1y. (7.4.2)
=(XТV–1X)–1XТV–1y. (7.4.2)
- Математическое ожидание вектора этой оценки Е(
![]() )=w.
)=w. - Матрица ковариаций вектора
![]() имеет вид
имеет вид
С()=sк2(XТV–1X)–1. (7.4.3)
- Несмещённая оценка дисперсии sк2 делается с использованием выражения
Рекомендуемые материалы
sк2= (у–X)ТV–1(у–X)/(n–р) (7.4.4)
=уТ[V–1–V–1X(XТV–1X)–1XТV–1]у/(n–р), (7.4.5)
где вектор находится по формуле (7.4.2).
Доказательство:
- Так как матрица V положительно определённая, то при разложении Холецкого существует невырожденная матрица Р размеров nxn, так что V=PPТ [Rao, Rao (1998) cтр.173]. Умножая модель у=Xw+e слева на Р–1, получаем Р–1у=Р–1Xw+Р–1e. При этом математическое ожидание E(Р–1e)=Р–1E(e)=Р–10=0 и ковариационная матрица
С(Р–1e) =Р–1С(e)(Р–1)Т [в силу (3.6.10)]
=Р–1sк2V(Р–1)Т
=sк2Р–1PPТ(Р–1)Т
=sк2I.
Таким образом, для модели Р–1у=Р–1Xw+Р–1e соблюдаются допущения теоремы 7.2.4 Гаусса-Маркова и получаемый методом наименьших квадратов вектор
=[(Р–1X)Т(Р–1X)]–1(Р–1X)ТР–1y
даёт наилучшую линейную несмещённую оценку параметров модели. По теоремам П.2.2 и П.5.2 его можно записать в виде
=[XТ(Р–1)ТР–1X]–1XТ(Р–1)ТР–1y
=[XТ(РТ)–1Р–1X]–1XТ(РТ)–1Р–1y [в силу (П.5.4)]
=[XТ(PРТ)–1X]–1XТ(PРТ)–1y [в силу (П.5.5)]
=(XТV–1X)–1XТV–1y.
- Математическое ожидание вектора оценки
![]()
Е()=(XТV–1X)–1XТV–1Е(y)
=(XТV–1X)–1XТV–1Xw
=w.
- Как и по теореме 7.2.3, вектора
![]() оценки имеет ковариационную матрицу
оценки имеет ковариационную матрицу
С()=С[(XТV–1X)–1XТV–1y]
=(XТV–1X)–1XТV–1С(у)[(XТV–1X)–1XТV–1]Т [в силу (3.6.10)]
=(XТV–1X)–1XТV–1(sк2V)V–1X(XТV–1X)–1
=sк2(XТV–1X)–1XТV–1X(XТV–1X)–1
=sк2(XТV–1X)–1.
- Сумма квадратов остатков для модели Р–1у=Р–1Xw+Р–1e находится в виде
SEк=(Р–1у–Р–1X)Т(Р–1у–Р–1X)
=(у–X)Т(Р–1)ТР–1(у–X)
=(у–X)Т(РРТ)–1(у–X)
=(у–X)ТV–1(у–X).
Следовательно по формуле (7.3.7) несмещённая оценка дисперсии находится так sк2= (у–X)ТV–1(у–X)/(n–р). В выражении (у–X)ТV–1(у–X) раскроем скобки
(у–X)ТV–1(у–X)=уТV–1(у–X)–ТXТV–1(у–X)
=уТV–1у–уТV–1X–ТXТV–1у+ТXТV–1X
и подставим =(XТV–1X)–1XТV–1y и Т=уТV–1X(XТV–1X)–1 чтобы получить
уТV–1у–уТV–1X(XТV–1X)–1XТV–1y–уТV–1X(XТV–1X)–1XТV–1у+уТV–1X(XТV–1X)–1XТV–1y
=уТV–1у–уТV–1X(XТV–1X)–1XТV–1y
=уТ(V–1–V–1X(XТV–1X)–1XТV–1)y.
Подставляя в (7.4.4) вместо (у–X)ТV–1(у–X) полученное выражение в правой части, получаем формулу (7.4.5).
□
Обычно говорят, что вектор =(XТV–1X)–1XТV–1y оценки найден обобщённым методом наименьших квадратов. При этом заметим, поскольку матрица X полного ранга, то по теореме П.6.2 матрица XТV–1X положительно определённая.
Математическое ожидание результата sк2 оценки находится по теореме 5.2.1. При этом используется допущение Е(y)=Xw и матрица А=V–1–V–1X(XТV–1X)–1XТV–1, так что
Е(уТ[V–1–V–1X(XТV–1X)–1XТV–1]у)
=sк2след[V–1V–V–1X(XТV–1X)–1XТV–1V]+wТXТ[V–1–V–1X(XТV–1X)–1XТV–1]Xw
=sк2след[In–V–1X(XТV–1X)–1XТ]+wТXТV–1Xw–wТXТV–1Xw
=sк2[след(In–след(XТV–1X(XТV–1X)–1)]
=sк2[след(In)–след(Iр)]=s2(n–р).
Отсюда математическое ожидание Е(sк2)= sк2(n–р)/(n–р)=sк2.
Вектор оценки параметров модели по формуле (7.4.2) получается также и при допущении распределения переменных отклика по нормальному закону. Это доказывается в следующей теореме.
Теорема 7.4.2. Если вектор у имеет нормальное распределение Nn(Xw, sк2V), где матрица X размеров пхр и ранга р, а V - известная положительно определённая матрица, то оценка максимального правдоподобия вектора w параметров и дисперсии sк2 делается соответственно по формулам
=(XТV–1X)–1XТV–1y
и
 к2=(у–X)ТV–1(у–X)/п.
к2=(у–X)ТV–1(у–X)/п.
Доказательство: В данном случае функция правдоподобия имеет вид
L(w, sк2)= ехр[–(у–Xw)T(sк2V)–1(у–Xw)/2].
ехр[–(у–Xw)T(sк2V)–1(у–Xw)/2].
В силу (П.9.4), определитель det(sк2V)=(sк2)ndet(V). Отсюда
L(w, sк2)= ехр[–(у–Xw)TV–1(у–Xw)/(2sк2)].
ехр[–(у–Xw)TV–1(у–Xw)/(2sк2)].
Формулы оценки для и  могут быть получены взятием производных от ln[L(w, sк2)] по q и sк2. Так, натуральный логарифм функции L(w, sк2)
могут быть получены взятием производных от ln[L(w, sк2)] по q и sк2. Так, натуральный логарифм функции L(w, sк2)
ln[L(w, sк2)] =–n/2ln(2p)–n/2ln(sк2)–1/2ln(detV)–(у–Xw)TV–1(у–Xw)/(2sк2).
Раскроем скобки в последнем члене правой части последнего выражения, чтобы получить
(уТV–1у–уТV–1Xw–wТXТV–1у+wТXТV–1Xw)/(2sк2).
Частные производные от ln[L(w,sк2)] по w и sк2 получаются в виде
 =–0–0–0–(0–2XТV–1у+2XТV–1Xw)/(2sк2)
=–0–0–0–(0–2XТV–1у+2XТV–1Xw)/(2sк2)
и
 =–0–n/(2sк2)–0+(у–Xw)TV–1(у–Xw)/[2(sк2)2].
=–0–n/(2sк2)–0+(у–Xw)TV–1(у–Xw)/[2(sк2)2].
Приравнивая эти производные соответственно вектору 0 и числу 0, получаем выражения
XТV–1Xw=XТV–1у
и
sк2=(у–Xw)TV–1(у–Xw)/n. (7.4.6)
Первое из них является выражением нормальных уравнений и, так как матрица XТV–1X положительно определённая, а, следовательно, невырожденная, то их решение даёт
=(XТV–1X)–1XТV–1у.
Подставляя найденный вектор оценки в выражение (7.4.6), находим оценку дисперсии
=(у–X)TV–1(у–X)/n.
Чтобы убедиться, что вектор даёт максимальное значение функции L(w, sк2) или её логарифма, возьмём вторую производную от ln[L(w, sк2)] по w
 =–XТV–1X/sк2.
=–XТV–1X/sк2.
Матрица XТV–1X положительно определённая, а матрица –XТV–1X по определению в разделе П6 отрицательно определённая, следовательно, ln[L(w, sк2)] при w= имеет максимальное значение. Также и для , если взять вторую производную от ln[L(w, sк2)] по sк2, то имеем
 =п/(2sк4)–(у–Xq)ТV–1(у–Xq)/(sк6)
=п/(2sк4)–(у–Xq)ТV–1(у–Xq)/(sк6)
=–п/(2sк4). [в силу (7.4.6)]
Эта производная отрицательная, следовательно ln[L(w, sк2)] при sк2= тоже имеет максимальное значение.
□
Результат неверного допущения о виде ковариационной матрицы
Положим, что для модели (7.4.1) правильным допущением о ковариационной матрице является С(y)=sк2V, но по ошибке (или намеренно) используется допущение С(y)=s2I. При этом вектор оценки находится обычным методом наименьших квадратов по формуле  =(XТX)–1XТy. В ней вектор оценки обозначен , чтобы отличать от наилучшей линейной несмещённой оценки по формуле =(XТV–1X)–1XТV–1y обобщённого метода наименьших квадратов, которая должна использоваться в данном случае. Тогда математическое ожидание и матрица ковариаций вектора получаются соответственно следующими:
=(XТX)–1XТy. В ней вектор оценки обозначен , чтобы отличать от наилучшей линейной несмещённой оценки по формуле =(XТV–1X)–1XТV–1y обобщённого метода наименьших квадратов, которая должна использоваться в данном случае. Тогда математическое ожидание и матрица ковариаций вектора получаются соответственно следующими:
E()= (XТX)–1XТXw=w, (7.4.7)
С()=sк2(XТX)–1XТVX(XТX)–1. (7.4.8)
Отсюда видно, что при неправильном допущении о виде ковариационной матрицы оценка параметров обычным методом наименьших квадратов являются несмещённой, но матрица ковариаций отличается от данной выражением (7.4.3). По пункту 2 теоремы 7.4.1 дисперсии элементов вектора в матрице ковариаций (7.4.8) не могут быть меньше дисперсий элементов вектора в матрице ковариаций С()=s2(XТV–1X)–1. Это можно показать на следующем примере.
Пример 7.4.1. Положим, что имеется линейная модель уi=w0+w1xi+ei, для которой D(уi)=sк2xi и С(уi, уj) =0 при i≠j (i, j=1, 2, …, n). Таким образом, ковариационная матрица вектора у имеет вид
С(у)=sк2V=sк2 .
.
Это пример взвешенных наименьших квадратов, который относится обычно к случаю, когда матрица V диагональная с расположенными по диагонали значениями влияющей на отклик переменной. В этом случае матрица модели имеет вид
X=
и, в силу (7.4.2), имеем
= =(XТV–1X)–1XТV–1y
=(XТV–1X)–1XТV–1y
= . (7.4.9)
. (7.4.9)
Матрица ковариаций вектора дается выражением:
С()=sк2(XТV–1X)–1
= . (7.4.10)
. (7.4.10)
Если для оценки используется обычный метод наименьших квадратов, то вектор оценки =(XТX)–1XТy, как дано в (7.2.2), а ковариационная матрица С() дается формулой (7.4.8), то есть,
С()=sк2(XТX)–1XТVX(XТX)–1
=sк2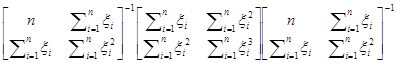
Обратите внимание на лекцию "12.4 Социально-экономическое развитие страны в пореформенный период".
=sк2с , (7.4.11)
, (7.4.11)
где с =1/ . Дисперсия оценки
. Дисперсия оценки  представлена правым нижним диагональным элементом матрицы в (7.4.11):
представлена правым нижним диагональным элементом матрицы в (7.4.11):
D( ) =sк2
) =sк2 , (7.4.12)
, (7.4.12)
а дисперсия оценки  дается соответствующим элементом выражения (7.4.10):
дается соответствующим элементом выражения (7.4.10):
D() = . (7.4.13)
. (7.4.13)
Рассмотрим следующие семь значений переменной x: 1, 2, 3, 4, 5, 6, 7. Используя формулу (7.4.12), получаем D()=0,1429s2 и по формуле (7.4.13) имеем D() =0,1099s2. Таким образом, как и ожидалось, для рассматриваемых значений переменной x использование обычного метода наименьших квадратов даёт оценку наклона с большей дисперсией.



















