
Подготовительные этапы статистического анализа
Глава 1.Подготовительные этапы статистического анализа
В настоящей главе мы рассмотрим основные методы манипулирования с данными в SPSS. Рассматриваемые здесь действия обычно производятся перед началом статистического анализа. Мы начнем обсуждение с самого начала — то есть с того момента, когда к исследователю попадает задание на проведение маркетингового исследования. Далее по порядку будут рассмотрены все основные действия с матрицей данных.
1.1. Материалы, необходимые для проведения статистического анализа
Первым шагом при подготовке к проведению статистического анализа данных в маркетинговых исследованиях является подбор исходных материалов, в которых содержатся основные параметры проводимого исследования. Обычно эти материалы включают в себя следующие документы.
1. Техническое задание на исследование (ТЗ) охватывает все общие параметры исследования: цели и задачи, планируемый размер выборки, информацию о квотах, методе и месте сбора данных, а также другую полезную информацию.
2. Структура аналитического отчета по результатам исследования позволяет определить заранее, какие статистические процедуры понадобятся при написании аналитического отчета по исследованию.
3. Анкета для опроса является основой для составления схемы кодировки переменных в базе данных SPSS.
На основании ТЗ и структуры аналитического отчета исследователь должен еще до получения данных для анализа (заполненных анкет) составить план предстоящих манипуляций с анкетами респондентов: преобразования данных, статистических процедур и методик. Исследователь должен приступить к обработке анкеты сразу после ее получения, не дожидаясь окончания полевых работ: изучить ее структуру и составить перечень переменных, которые впоследствии войдут в базу данных SPSS.
Основными выходными данными на названном этапе являются:
Рекомендуемые материалы
■ планируемый размер выборки;
■ структура выборки (наличие и размер квот);
■ вид опроса (личный, телефонный);
■ информация о параметрах опроса (наличие фактов фальсификации анкет);
■ схема (таблица) кодировки переменных в базе данных SPSS;
■ план-схема преобразования данных;
■ план-схема используемых статистических процедур.
Как вы увидите далее, эти данные являются весьма ценным ресурсом для последующего статистического анализа.
Необходимо отметить, что на рассматриваемом этапе также можно выполнять и другие действия. Так, если заполненные анкеты вводятся в компьютер при помощи специализированного программного обеспечения (например, программы Data Entry или сканерного программного комплекса), на основании имеющейся анкеты и согласно целям и задачам исследования следует сформировать соответствующие формы (для программы Data Entry) или создать шаблоны и макеты анкеты (для сканерного ввода). Только после успешного завершения этого подготовительного шага можно приступать к дальнейшим этапам.
1.2. Общие параметры выборки
Определение общих параметров выборки осуществляется после завершения полевых работ (когда собраны все анкеты). Данный этап состоит из ряда взаимосвязанных шагов. Это:
■ определение реального количества опрошенных респондентов;
■ определение структуры выборки;
■ распределение по месту опроса;
■ установление доверительного уровня статистической надежности выборки;
■ расчет статистической ошибки и определение репрезентативности выборки. Первое, что должно интересовать исследователя после получения заполненных анкет, — это количество респондентов. Оно может быть либо больше, либо меньше запланированного количества анкет. При этом первый вариант лучше с точки зрения статистического анализа, но хуже с точки зрения руководства фирмы, так как дополнительные анкеты являются незапланированными расходами на оплату работы интервьюеров. Второй вариант обычно хуже и с точки зрения анализа (выборка менее представительна), и с точки зрения руководства (заказчик будет недоволен несоблюдением требований, оговоренных в ТЗ).
При оценке разницы между реальным и плановым размером выборки следует принимать в расчет разницу в статистической ошибке (см. ниже). Если она невелика (в ту или другую сторону), репрезентативность всей выборки существенно не страдает. Но если разница достаточно значима, выборка может оказаться непредставительной. Кроме того, при определении общего размера выборки необходимо иметь в виду, что статистическая ошибка всей выборки относится только к общим распределениям. Разрезы существенно увеличивают статистическую ошибку. Поэтому еще до начала опроса следует определить, какая численность каждой из интересующих целевых групп респондентов является достаточной для построения статистически значимых заключений и выводов.
Структура выборки может быть случайной (респонденты отбирались в случайном порядке) или неслучайной (респонденты отбирались на основании заранее известных критериев, например методом квотирования). Эта информация важна при интерпретации результатов статистического анализа. Случайные выборки априори являются репрезентативными, так как на попадание/непопадание каждого респондента в выборку не влияют никакие факторы, кроме случайных. Представительность неслучайных выборок не следует из их определения. Иногда они специально делаются нерепрезентативными относительно генеральной совокупности, однако могут являться весьма представительными относительно какой-либо одной интересующей целевой группы (например, исследуется только мнение мужчин в возрасте после 40 лет).
При анализе структуры выборки необходимо также изучить фильтрационные вопросы анкеты, то есть вопросы, специально предназначенные для отсеивания не подходящих под требования выборки респондентов. Несмотря на то, что такие вопросы позволяют исключить не нужные для конкретного исследования целевые группы, знание доли исключенных категорий позволит впоследствии составить общее представление о параметрах всей генеральной совокупности.
Приведем пример. Методом телефонного опроса исследуется потребительский спрос на московском рынке творожной массы. При этом опрашиваются только лица, покупающие данный продукт, — для чего в анкету добавлен соответствующий фильтрационный вопрос. Однако в дальнейшем потребуется рассчитать емкость рынка исследуемого продукта. Решением данной задачи будет подсчет количества отсеянных респондентов (лиц, не покупающих творожную массу). Таким образом, впоследствии мы сможем определить долю покупателей творожной массы от общей численности населения Москвы.
Еще одна важная для исследователя характеристика выборки — это распределение респондентов по месту опроса (личные интервью). Позже эти данные могут помочь при определении различий между респондентами, опрошенными в разных местах. (Очевидна разница в доходах между посетителями рынков и бутиков.)
Имея в своем распоряжении указанную выше информацию, можно приступать к определению представительности (или репрезентативности) выборки. Прежде всего необходимо установить уровень доверия к результатам опроса. Обычно в маркетинговых исследованиях используется уровень доверия 95 % и 99 %. Мы рекомендуем остановиться именно на первом варианте как на наиболее релевантном по отношению к маркетинговым исследованиям.
В зависимости от выбранного доверительного уровня определяется специфическая константа г, участвующая в формуле расчета статистической ошибки выборки. Константы доверительных уровней, наиболее часто используемых в маркетинговых исследованиях, представлены в табл. 1.1.
Таблица 1.1. Константы доверительных уровней
| Доверительный уровень | Константа z |
| 90 % 95 % 99 % | ±1,64 ±1,96 ±2,58 |
Максимальная статистическая ошибка выборки рассчитывается по следующей формуле:


где — статистическая константа для соответствующего доверительного уровня; p= q = 50 % — вероятность наступления/ненаступления исследуемого события (то есть попадания/непопадания респондента в выборку); для случайных выборок данная вероятность равна 1/2 или 50 %; n — размер выборки (общее количество опрошенных).
Таким образом, для выборки в 1000 респондентов и при уровне доверия к результатам опроса 95 % статистическая ошибка выборки будет равна:

Эта же статистическая ошибка используется для характеристики всех значений в выборке, выраженных в относительных величинах. То есть если в дальнейшем при построении линейных распределений по вопросам анкеты мы выясним, что 32 % респондентов покупают газеты в киосках на улице, — это будет означать, что данное значение варьируется в пределах от 28,9 % (32 % - 3,1 %) до 35,1 % (32 % + 3,1 %).
Для расчета статистической ошибки значений переменных, выраженных в абсолютных величинах, применяется другая формула. При этом ошибка варьируется в зависимости от конкретной анализируемой величины. Ее расчет основан на построении линейных распределений и показан в разделе 2.1.
1.3. Составление схемы кодировки анкеты
Схема кодировки анкеты представляет собой таблицу соответствия вопросов и вариантов ответа анкеты внутреннему представлению переменных в базе данных SPSS. Впоследствии ввод анкет в компьютер и кодирование ответов респондентов производятся согласно данной формализованной структуре. Пример таблицы кодировки представлен в табл. 1.2.
Как вы видите, различные типы вопросов анкеты кодируются в схеме кодировки (и в базе данных SPSS) по-разному. Существует три основных типа кодирования вопросов анкеты.
1. Закрытые вопросы, в которых респондент может указать только один вариант ответа (одновариантные), кодируются одной переменной (например, ql). Тип шкалы в данном случае может быть любым.
2. Закрытые вопросы, в которых респондент может дать несколько вариантов ответа (многовариантные), кодируются несколькими одновариантными переменными (например, q3_l, q3_2). Тип шкалы одновариантных переменных может быть только номинальным (дихотомическим).
3. Открытые вопросы, независимо от количества возможных вариантов ответа на них, кодируются одной переменной. Тип шкалы в данном случае может быть либо интервальным (для числовых данных, например q5_t), либо номинальным (для нечисловых данных, например q4_t).
Таблица 1.2. Кодировка различных типов вопросов
| Вопрос анкеты | Код и тип переменной в базе данных |
| Номер анкеты________ | n_resp – интервальная шкала |
| 1. Покупаете ли Вы мясные полфобриканты? Да Нет | q1 – номинальная шкала Вариант ответа 1 Вариант ответа 2 |
| 2. Как часто Вы покупаете эти продукты? Почти каждый день 2-3 раза в неделю Примерно раз в неделю 2-3 раза в месяц Примерно раз в месяц Реже раза в месяц | q2 – порядковая шкала вариант ответа 1 вариант ответа 2 вариант ответа 3 вариант ответа 4 вариант ответа 5 вариант ответа 6 |
| 3. Где Вы обычно покупаете мясные продукты? (возможно несколько ответов) В магазине На рынке В супермаркете Другое (укажите где именно) ___________________________ | Все варианты ответа являются номинальными переменными q3_1 q3_2 q3_3 q3_4 q3_4t |
| 4. Каких производителей мясных продуктов Вы знаете? _____________________________ | q4_1t – номинальная шкала |
| 5. Укажите Ваш возраст: _________лет | q5_1t – интервальная шкала |
1.4. Ввод данных в компьютер и кодирование переменных
Ввод данных в компьютер является четвертым шагом первого (подготовительного) этапа статистического анализа данных (см. рис. В.2). Он неразрывно связан со следующим шагом — кодированием переменных. В этом разделе мы последовательно рассмотрим эти две взаимосвязанные и взаимообусловленные процедуры.
1.4.1. Способы ввода данных в SPSS
Существует три основных способа формирования базы данных в формате SPSS (перечислены в порядке убывания популярности).
1. Импорт базы данных из других программных источников (Microsoft Access, Microsoft Excel, текстовых файлов и других).
2. Ввод данных непосредственно в SPSS при помощи специализированного программного обеспечения (SPSS Data Entry).
3. Ручной ввод данных в SPSS.
Теперь рассмотрим каждый способ более подробно.
1.4.1.1. Импорт данных из других источников
Данный способ создания базы данных в формате SPSS является наиболее распространенным. Чаще всего он предполагает использование SPSS в качестве вспомогательного средства для статистического анализа данных. При этом построение линейных распределений в графическом виде (диаграмм по общим распределениям) может производиться, например, в Microsoft Excel. Также данный метод применим и если у вас есть программное обеспечение для автоматически сканируемого ввода бумажных анкет в компьютер. В этом случае специализированная программа (например, ABBYY FormReader) создает особую базу данных в собственном формате (во внутреннем представлении).
Рассмотрим пример создания базы данных в SPSS при помощи перекачки данных из другой программы — Microsoft Access, как одной из наиболее распространенных систем управления базами данных (СУБД).
Чтобы осуществить импорт данных в SPSS, необходимо сформировать в соответствующей программе (из которой будет осуществляться импорт) таблицу данных, отформатированную определенным способом. Файл данных SPSS напоминает рабочую книгу Microsoft Excel (электронную таблицу). Однако SPSS, к сожалению, не обладает функциональностью электронной таблицы, и схожесть этих двух программных продуктов заканчивается на внешнем виде. Общая схема построения файла SPSS выглядит примерно так, как на рис. 1.1.
Таблица данных в сторонней программе, из которой будет осуществляться импорт, должна соответствовать именно такой схеме (заголовок переменной → значения переменной). Примеры таблиц из Microsoft Access Base.mdb, Microsoft Excel Base.xls, простого текстового файла MS DOS Base.txt и текстового файла с разделителями Base.csv представлены на рис. 1.2-1.5. Независимо от вида разделителей данных в таблицах их объединяет общая структура: заголовок переменной → данные (значение переменной). Представим, что была создана база данных Microsoft Access Base.mdb, содержащая Таблицу данных.
После того как была создана подходящая для импорта таблица данных, следует открыть SPSS и вызвать диалоговое окно импорта данных при помощи меню File ► Open Database ► New Query. Откроется мастер Database Wizard (рис. 1.6); в его окне необходимо указать источник данных, из которого будет производиться импорт данных. Выберите в списке справа База данных MS Access и щелкните на кнопке Далее.
Следует отметить, что SPSS поддерживает импорт из любых источников данных, совместимых с технологией ODBC (соответствующие драйверы для них должны быть предварительно установлены в Microsoft Windows). Например, чтобы добавить возможность импорта из базы данных Microsoft Paradox (файлы типа *.db), необходимо щелкнуть на кнопке Add Data Source в диалоговом окне Database Wizard. На экране появится стандартное окно Microsoft Windows Администратор источников данных ODBC (рис. 1.7). В этом диалоговом окне представлен список уже установленных в SPSS источников данных. Чтобы добавить новый источник, отсутствующий в данном перечне, следует щелкнуть на кнопке Добавить.
 |

 |
 |
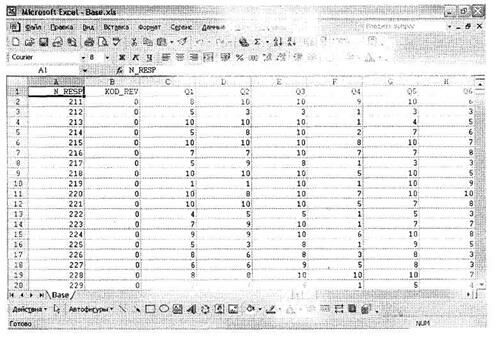 |
Рис. 1.3. Таблицы данных, подходящие для импорта
в SPSS: лист MS Excel
 |
Рис. 1.4. Таблицы данных, подходящие для импорта в SPSS: текстовый файл с фиксированными столбцами
 |

 |
 |

 |
 |
В открывшемся диалоговом окне Создание нового источника данных (рис. 1.8) содержится список всех источников данных, установленных в вашей системе Microsoft Windows. Кроме названий источников, в данном перечне вы можете увидеть номер версии и название файла соответствующего драйвера. Выберите драйвер Microsoft Paradox Driver (*.db) и щелкните на кнопке Готово.
 |
При этом будет открыто новое диалоговое окно Установка драйвера ODBC для Paradox (рис. 1.9). Здесь в строке Имя источника данных следует ввести то название, которое будет в дальнейшем отображаться в диалоговом окне Database Wizard в SPSS (например, База данных Paradox). В этом диалоговом окне можно установить дополнительные параметры. Чтобы вернуться в SPSS, следует закрыть все использован-
ные диалоговые окна установки источника данных ODBC. Вы увидите, что в списке доступных источников в окне Database Wizard появится база данных Paradox.

 |
Вернемся к рис. 1.6. Выберите соответствующий источник данных и щелкните на кнопке Далее, после чего на экране откроется диалоговое окно ODBC Driver Login (рис. 1.10). В этом окне следует указать полный путь к базе данных, из которой будет производиться импорт таблицы (в нашем случае это C:Base.mdb). Щелкните на кнопке 0К для продолжения работы.
 |
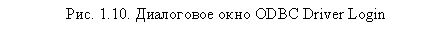 |
Откроется новое диалоговое окно (рис. 1.11). В нем из левого списка всех таблиц, доступных в указанном источнике данных, выберите ту, которая содержит импортируемые данные (в нашем случае Таблица данных), и переместите ее в правый список. Затем щелкните на кнопке Готово, после чего в окне SPSS Data Editor появится импортированная таблица.
Следует отметить, что процедуры импорта данных для разных источников отличны друг от друга. Однако эти различия несущественны, и поэтому мы не будем описывать все типы импорта. Как правило, для таблицы из базы данных Microsoft Access действия, показанные при помощи вышеописанных шагов, достаточны.
1.4.1.2. Ввод данных в SPSS при помощи Data Entry
Данная программа призвана упростить ввод данных в SPSS. При работе с ней генерируются пользовательские формы, содержащие поля анкеты, куда и вводятся данные. Модуль SPSS Data Entry Builder позволяет создавать формы и правила для их заполнения, а модуль SPSS Data Entry Station — вводить анкеты в компьютер в распределенном режиме (то есть с нескольких компьютеров одновременно). Детальное описание работы с программой Data Entry выходит за рамки настоящего пособия. Отметим лишь, что данная программа является самостоятельным приложением Microsoft Windows и не входит в комплект поставки SPSS. Кроме того, программные продукты SPSS достаточно дороги для большинства российских компаний, и поэтому рассматриваемый способ ввода данных не получил должного распространения в нашей стране.

 |
1.4.1.3. Ручной ввод данных в SPSS
Ручной ввод наиболее эффективен при малых размерах выборки, а также для достижения некоторых специфических целей (например, при вводе ранжированных списков в ходе расчета корреляции Спирмана; см. раздел 4.2.1). Как и в случае использования программы Data Entry, существует возможность распределенного ввода анкет с несколькими операторами. Когда все операторы закончат ввод своей части анкет, полученные базы данных сливаются в одну при помощи меню SPSS Data ► Merge files, в котором следует выбрать объект добавления анкеты (Add Cases) или переменных (Add Variables).
1.4.2. Кодирование переменных
После того как в файл SPSS помещена таблица с данными по исследованию, следует перейти к очередному этапу формирования базы данных — кодированию переменных.
Если данные вводились в SPSS методом импорта, вы увидите только имена переменных и их значения. В этом случае кодирование переменных является обязательным шагом и должно проводиться сразу после процедуры импорта. Если для
ввода данных в SPSS использовалась программа Data Entry, все переменные и их значения окажутся, скорее всего, уже закодированными (на этапе генерирования пользовательских форм). При ручном вводе картина может быть такой, как при импорте данных из других источников (если вы предварительно не производили кодирование), либо аналогичной использованию Data Entry. Тем не менее, независимо от способа ввода, на этапе кодирования необходимо произвести ревизию имеющихся переменных и меток их значений — чтобы удостовериться, что в будущем при проведении статистического анализа все используемые величины будут названы осмысленными именами.
Основное рабочее окно SPSS (см. рис. 1.1) содержит специальные вкладки для перемещения между видом файла данных (Data View) и таблицы переменных (Variable View). Кодирование переменных осуществляется на вкладке Variable View. Общий вид окна программы после щелчка на вкладке Variable View показан на рис. 1.121.
 |
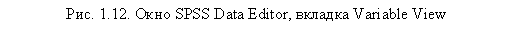
Если в данную таблицу ввести какую-либо переменную (поле Name), все остальные ее поля будут заполнены автоматически значениями по умолчанию. После импорта данных из другой программы все полученные переменные будут представлены также значениями по умолчанию (сохранятся только имена переменных). Рассмотрим более детально структуру таблицы Variable View.
Первое поле таблицы Name предназначено для ввода имени переменной, которое должно состоять только из латинских букв и цифр; имя переменной не может начинаться с цифры. При импорте данных из другого источника данное поле заполняется теми значениями, которые были указаны в исходной базе данных. Все остальные поля рассматриваемой таблицы заполняются программой автоматически, причем SPSS сама определяет, к какому типу относится та или иная переменная, а в качестве меток дублирует имена переменных.
Поле Туре служит для указания типа переменной. Установленный по умолчанию тип Numeric можно изменить, установив курсор в данную ячейку и щелкнув на появившейся кнопке со значком .... Доступные типы переменных представлены на рис. 1.13. Для некоторых из них (например, Numeric) необходимо задать количество используемых разрядов (или букв — для текстовых переменных) и цифр после запятой, а для других (например, Date) — шаблон, по которому отражаются значения.
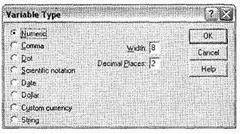 |
 |
Поле Width служит для указания количества разрядов (для числовых переменных) или букв (для текстовых переменных), если они не были указаны в диалоговом окне указания типа переменной. Следующее поле Decimals позволяет указать количество цифр после запятой для числовых переменных.
Поле Label служит для задания метки переменной. Данное поле важно, так как именно указанные в нем значения появляются на графиках и в таблицах при проведении всех видов статистического анализа. В анкетах, используемых при проведении маркетинговых исследований, содержатся как одновариантные вопросы (респонденты могут указать только один вариант ответа), так и многовариантные (респонденты могут указать несколько вариантов ответа). При этом если одновариантные вопросы обычно представляются одной переменной, которая может принимать столько значений, сколько имеется вариантов ответа, то многовариантные вопросы, как правило, кодируются количеством одновариантных переменных, равным числу вариантов ответа. Каждая такая одновариантная переменная всегда принимает только два значения (дихотомии) — отмечено/не отмечено, которые кодируются соответственно двумя цифрами (обычно 1 и 0). Более подробно схема работы с многовариантными переменными описана в разделе 2.2, мы отметим лишь способ кодирования различных переменных.
Так, при кодировании одновариантных переменных поле Label используется для указания формулировки вопроса анкеты (варианты ответа кодируются в другом поле). При кодировании многовариантных переменных, представленных вариантами ответа, формулировка самого вопроса не отражается в рассматриваемой таблице: кодируются только варианты ответа (дихотомические переменные).
Приведем пример. У нас есть одновариантный вопрос Укажите пол респондента — это формулировка данного вопроса, и она отражается в поле Label, а переменной присваивается имя по принципу ql. Формулировка многовариантного вопроса Что для Вас наиболее важно при выборе велосипеда? не будет фигурировать в таблице Variable View. Вместо нее будет указан набор одновариантных дихотомических переменных (по числу вариантов ответа). В поле Label будут указаны названия вариантов ответа, а в поле Name — имена переменных, кодирующие каждый из вариантов ответа (например, переменная q2_l — Цена велосипеда; q2_2 — Качество велосипеда и т. д.).
 |
Поле Values предназначено для указания вариантов ответа в одновариантных вопросах. Общий вид соответствующего диалогового окна представлен на рис. 1.14. Данное поле не заполняется для многовариантных переменных. В окне Value Labels в поле Value указываются числовые коды вариантов ответа, а в поле Value Label — вербальные формулировки вариантов ответа. При задании меток необходимо предлагать разумные варианты ответов, учитывая, что впоследствии именно эти названия (в том же виде) будут фигурировать на графиках и в аналитических таблицах. Например, вариант ответа на вопрос о половой принадлежности респондента следует называть не Мужской или Женский, а Мужчины или Женщины. Также при наименовании переменных и вариантов ответа следует избавляться от лишних слов, как то: предлоги в начале предложения, междометия, вводные слова. Это, с одной стороны, позволит сократить само название, что в дальнейшем облегчит его восприятие, а с другой стороны, избавит таблицы и диаграммы от массы ненужной информации. Итак, наша основная рекомендация при наименовании переменных — формализация названий.
 |
Поле Missing используется редко, так как не несет существенной смысловой нагрузки. В нем можно указать, какие коды следует исключить из анализа (присвоить им статус System Missing). По умолчанию все отсутствующие значения (пропущенные одновариантные вопросы или неотмеченные варианты ответа многовариантных вопросов) представляются в SPSS как System Missing и отражаются для числовых переменных символом,.
Также при помощи поля Missing можно наглядно продемонстрировать разницу между различными типами пропущенных значений — типа «user missing» (значения, специально пропущенные исследователем) и типа «system missing» (значения, которые в принципе должны были присутствовать, но которых не оказалось в базе данных в связи с причинами случайного характера, — в том числе и динамически, не меняя структуры базы данных. Предположим, что для исследования нам нужны только люди с доходом свыше $ 500. Тогда в начале анкеты мы зададим респондентам фильтрационный вопрос (закрытый): Укажите Ваш примерный среднемесячный доход в расчете на 1 члена семьи. При этом респондент может выбрать один из пяти вариантов ответа:
1. до $500;
2. от $ 500 до $ 1000;
3. от $1000 до $1500;
4. свыше $1500;
5. отказываюсь отвечать.
Очевидно, что для дальнейшего анализа нам подходят только те респонденты, которые указали варианты ответа 2-4. Теперь эти три варианта ответа, которые необходимы нам для построения линейных и перекрестных распределений, мы заносим в поле Values, а оставшиеся два — 1 и 5 — в поле Missing. Два последние варианта исключаются из дальнейшего анализа и будут представляться как значение System Missing. Впоследствии, если мы захотим, например, построить общее линейное распределение по всему фильтрационному вопросу (включая все категории), нужно будет просто убрать два пропущенных (в терминологии SPSS — User Missing) значения из поля Missing и добавить их в поле Values. Поле Columns служит для указания ширины столбца при отображении переменной в окне Data View. Следующее поле Align предназначено для выбора выравнивания значений переменной в столбце: по правому краю (Right), по левому краю (Left) или по центру (Center).
Поле Measure является для SPSS единственной возможностью определить тип шкалы имеющихся переменных: номинальная (Nominal), порядковая (Ordinal) или интервальная (Scale). Как показано далее в разделе 2.5 «Статистический анализ данных», важно знать, к какому типу шкалы относится та или иная переменная в базе данных. От этого во многом зависит выбор используемой статистической процедуры. Ниже приведена краткая характеристика трех типов шкалы переменных, используемых в SPSS.
1. Номинальные переменные (Nominal) могут принимать дискретные, не связанные друг с другом значения. Вопросы анкеты, кодируемые номинальными переменными, могут быть как закрытыми (с вариантами ответов), так и открытыми (с текстовым полем вместо прямого указания вариантов ответа). Например, вопрос анкеты Каких производителей мясных полуфабрикатов Вы знаете? с вариантами ответа Царицыно, Черкизовский, Браво и Другое будет закодирован в базе данных SPSS номинальной переменной, так как между вариантами ответа на данный вопрос не существует логического порядка, это просто названия компаний-производителей.
2. Особое место среди номинальных переменных занимают переменные, являющиеся вариантами ответа на многовариантные вопросы или имеющие только два варианта ответа. Тип шкалы данных переменных называется дихотомическим (Dichotomous). Данным переменным в SPSS отводится особая роль, так
как их варианты ответа могут рассматриваться в статистических процедурах как вероятность выбора одной категории или не выбора другой. В качестве вопросов анкеты дихотомические переменные могут кодировать как открытые, так и закрытые вопросы.
3. Порядковые переменные (Ordinal) кодируют такие закрытые вопросы, варианты ответа на которые подчиняются логическому числовому порядку. То есть варианты ответа на такие вопросы представляют собой связанные между собой группы значений. Например, вопрос Как часто Вы покупаете мясные полуфабрикаты? с вариантами ответа: Чаще раза в неделю, Примерно раз в неделю и Реже раза в неделю — кодируется переменной с порядковой шкалой.
4. Интервальными (Scale) являются переменные, не имеющие выделенных категорий. Они содержат числовые данные (например, номер анкеты в базе данных) и кодируют чаще всего открытые вопросы. Интервальные переменные (или другие типы переменных, приводимые к интервальному виду) используются практически во всех статистических процедурах. Они являются основным ресурсом для SPSS.
1.5. Модификация и отбор данных
Этап модификации и отбора данных объединяет целый ряд процедур, используемых для манипуляции с имеющимися данными: условный отбор данных, формирование случайной выборки, сортировка данных, перекодирование переменных, вычисление новых переменных и т. д. В настоящем разделе мы рассмотрим наиболее часто используемые методы автоматизированного управления переменными и их значениями в базах данных SPSS.
1.5.1. Условный отбор данных и случайная выборка
В настоящем параграфе мы рассмотрим такие методы манипуляций с данными, как отбор респондентов по определенному условию (например, выбор из всей базы данных только анкет мужчин), а также формирование случайной выборки.
1.5.1.1. Отбор анкет по условию
Часто при анализе данных в SPSS возникает необходимость отбора только тех респондентов, которые соответствуют определенным требованиям (например, имеют среднемесячный доход свыше $ 1000). В этом случае используют условный отбор данных. Соответствующее диалоговое окно вызывается при помощи меню Data ► Select Cases.
Как вы видите на рис. 1.15,.это диалоговое окно не только позволяет осуществлять условный отбор данных, но и разрешает многие другие манипуляции. При проведении маркетинговых исследований наиболее часто применяются только два параметра: If condition is specified (Условный отбор данных) и Random sample of cases (Формирование случайной выборки). По умолчанию установлен параметр All cases, что означает выбор всех без исключения респондентов.

 |
Выберите параметр If condition is specified и щелкните на кнопке If. Откроется новое диалоговое окно Select Cases: If, позволяющее задать условие, согласно которому будет производиться отбор респондентов (рис. 1.16). Основная рекомендация относительно работы с данным диалоговым окном — заключайте все уравнения (название переменной и ее значение) в круглые скобки. Соблюдение данного требования весьма полезно при составлении длинных последовательностей условий.
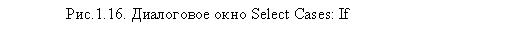 |
 |
В табл. 1.3 представлена расшифровка всех логических и арифметических операндов, используемых при составлении условных выражений. Такие же операнды используются и в других диалоговых окнах, описываемых в разделе 1.5. Это стандартные операнды для составления логических выражений.
Необходимо отметить, что все логические операторы, кроме = и ~=, применимы только для числовых переменных (не для текстовых).
Помимо представленных стандартных логических операторов, существуют специальные предустановленные функции (область Functions) — при щелчке правой кнопкой мыши на любой из них появляется описание соответствующей функции.
Таблица 1.3. Стандартные логические операторы, используемые в SPSS
| Арифметические | Логические | ||
| Оператор | Значение | Оператор | Значение |
| + | Сложение (x + y) | < | меньше (x < y) |
| - | вычисление (x - y) | > | больше (x > y) |
| * | умножение (x * y) | <= | меньше или равно (x <= y) |
| / | деление (x / y) | >= | больше или равно (x >= y) |
| ** | возведение в степень (x ** y) | = | равно (x = y) |
| () | приоритет вычислений | ~= | не равно (x ~ y) |
| | | или (x | y) | & | и (x & y) |
| ~ | отрицание (~ x) |
В приведенном примере мы выбрали все анкеты, полученные от респондентов, являющихся мужчинами (вопрос q37, вариант ответа 1) в возрасте от 26 до 30 лет (вопрос q39, вариант ответа 2). Щелкнув на кнопке Continue и завершив операцию при помощи щелчка на кнопке 0К в главном диалоговом окне, мы увидим, что респонденты, не соответствующие данному условию, оказались исключенными из рассмотрения (их номера перечеркнуты). Можно не только временно исключить из рассмотрения респондентов, не подходящих под определенное условие, но и полностью удалить такие нерелевантные анкеты из базы данных SPSS. Для этого в диалоговом окне Select cases (рис. 1.15) необходимо заменить выбранный по умолчанию параметр Filtered (в области Unselected Cases Are) на Deleted.
1.5.1.2. Отбор анкет случайным образом
Иногда при обработке данных маркетинговых исследований возникает необходимость отбора респондентов не по конкретному условию, а случайным образом (то есть формирование случайной выборки). Эта возможность весьма полезна для уменьшения размера исходной выборки — например, для выполнения статистических процедур, предъявляющих повышенные требования к вычислительным ресурсам компьютера. Также случайная выборка применяется при проверке корректности работы некоторых статистических процедур (например, факторного анализа): сначала процедура проводится для общей выборки, а затем — для случайной выборки из n-го количества респондентов.
Для формирования случайных выборок в диалоговом окне Select Cases, (см. рис. 1.15) предусмотрен параметр Random sample of cases. Выберите этот параметр и щелкните на кнопке Sample. Открывшееся диалоговое окно (рис. 1.17) содержит два способа формирования случайной выборки: с указанием доли респондентов, которых необходимо отобрать из исходной выборки (Approximately), либо с указанием конкретного количества респондентов, которое необходимо отобрать (Exactly). При этом в последнем случае необходимо также указать в поле from the first ... cases количество респондентов, из которого следует осуществить выбор. Для формирования случайной выборки из общего числа опрошенных в данном поле следует указать совокупный размер выборки.
В нашем случае мы случайным образом отобрали 50 % респондентов из исходной выборки.
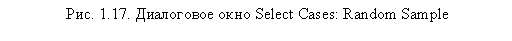 |
 |
1.5.2. Сортировка и группировка данных
Сортировка и группировка данных — наиболее часто применяющиеся операции с данными. Причем эти операции могут производиться как перед началом проведения статистического анализа, так и на других этапах работы.
1.5.2.1. Сортировка файла данных SPSS
При помощи функции сортировки в SPSS можно упорядочить значения переменных по одному или нескольким ключевым полям анкеты. Вызов диалогового окна сортировки осуществляется последовательностью меню Data ► Sort Cases.
 |
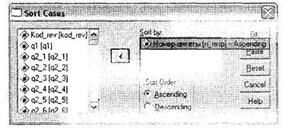 |
Как указано на рис. 1.18, левый список содержит все доступные в текущей базе данных переменные. В область Sort by помещаются переменные, по которым следует произвести сортировку. Порядок следования переменных в данной области соответствует порядку сортировки, то есть сначала сортировка происходит по первой переменной, затем — по второй и т. д. Группа переключателей Sort Order позволяет выбрать направление сортировки: по возрастанию (Ascending) или убыванию (Descending). При этом для каждой переменной можно выбрать свой тип сортировки.
В нашем случае мы отсортировали базу данных по возрастанию номера анкеты.
1.5.2.2. Группировка значений переменных
SPSS позволяет автоматически разделять значения интервальных переменных на заданное число групп. Разделение производится на основании процентилей, то есть образующиеся группы содержат примерно одинаковое количество значений. Результатом работы этой процедуры является новая порядковая переменная, которая содержит столько категорий, сколько было указано групп. Диалоговое окно группировки данных вызывается при помощи меню Transform ► Categorize Variables (рис. 1.19). В область Create Categories for переносятся переменные, значения которых необходимо сгруппировать. Поле Number of categories служит для указали числа групп.
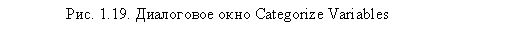 |
 |
В нашем примере мы разделили выборку по номеру анкеты на четыре примерно равных доли — по 25 %.
1.5.3. Перекодирование переменных
Перекодирование переменных служит для трансформации значений переменных с созданием или без создания новых переменных, а также для автоматического кодирования текстовых переменных для преобразования их к числовому виду.
1.5.3.1. Перекодирование внутри одной переменной
Рекомендуется производить перекодирование значений многовариантных переменных (точнее, наборов дихотомий, как было показано в разделе 1.4.2) сразу после создания базы данных. При этом все пропущенные значения (вариант не отмечено) в таких вопросах следует перекодировать из System Missing в нули. В дальнейшем это позволит использовать данные дихотомические переменные (уже с двумя вариантами ответа: 0 и 1) при проведении статистического анализа (например, при построении перекрестных распределений). Альтернативой обработки многовариантных переменных является формирование серии полноценных одновариантных переменных путем кодирования всех возможных взаимодействий между вариантами ответа на многовариантный вопрос. Очевидно, что такая методика подходит только для вопросов с небольшим количеством вариантов ответа.
Перекодирование может осуществляться как внутри одной уже существующей переменной, так и с созданием новой переменной, содержащей перекодированные значения. В последнем случае исходная переменная будет содержать неперекодированные значения, а вновь созданная — перекодированные значения.
Рассмотрим методику перекодирования внутри одной существующей переменной (без создания новой). В качестве примера возьмем случай с многовариантным вопросом Где Вы обычно покупаете кетчуп?, у которого есть четыре варианта ответа:
1. q2_l — рынки;
2. q2_2 — магазины;
3. q2_3 — палатки;
4. q2_4 — другое.
При этом выбор респондентом данных пунктов закодирован в базе данных как 1, а отсутствие выбора — значением System Missing (отражается символом,). Произведем перекодирование отсутствующих значений System Missing в нули.
Вызов диалогового окна перекодировки внутри одной переменной осуществляется при помощи меню Transform ► Recode ► Into Same Variables. Открывшееся диалоговое окно, как и большинство других окон SPSS, в левой области содержит список всех доступных переменных, а в правой (имеющей метку Variables) — место для помещения перекодируемых переменных. Необходимо особо подчеркнуть, что за один цикл использования диалогового окна Recode into Same Variables можно перекодировать сколько угодно переменных, но только одними и теми же кодами. Иными словами, нельзя в одной переменной нули заменить на единицы, а в другой — шестерки на строки Шесть. Для этого придется сначала перекодировать первую переменную (нули на единицы), а затем вновь вернуться в диалоговое окно Recode into Same Variables, щелкнуть на кнопке Reset и затем ввести данные для перекодировки другой переменной.
 |
В нашем случае мы собираемся перекодировать четыре переменные, имеющие одинаковые унарные шкалы, состоящие всего из одного значения 1. Поэтому в описываемом диалоговом окне можно ввести их одновременно в область Variables (рис. 1.20).
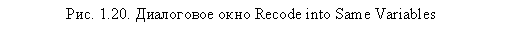 |
При щелчке на кнопке If вызывается диалоговое окно, по внешнему виду и по функциям аналогичное окну Select Cases: If, представленному на рис. 1.16. Из этого окна молено производить перекодирование переменных, помещенных в область Variables, не для всех респондентов, а только для конкретных групп (например, только для мужчин).
В нашем случае мы не будем ставить никаких условий. Щелкните на кнопке Old and New Values, которая открывает диалоговое окно, позволяющее задать перекодируемые значения (рис. 1.21). Это окно разделено на две части. В левой можно указать, какие конкретно значения подлежат перекодировке, а в правой — в какие значения они будут перекодированы. Чтобы указать конкретное значение для перекодировки, введите исходное значение в левое поле Value, а конечное значение — в правое поле Value.
Для специальных значений System Missing есть специальный одноименный параметр. В нашем примере в левой области диалогового окна выберите пункт System Missing, а в правой — в поле Value введите 0. Далее щелкните на кнопке Add, чтобы добавить указанное сочетание в список перекодировки. (Необходимо особо отметить, что значения, не указанные в списке перекодировки, оставляются неизменны.)
 |
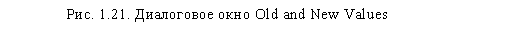 |
После того как были указаны все необходимые варианты перекодирования (в нашем случае — только один), следует закрыть окно щелчком на кнопке Continue и запустить процедуру перекодирования кнопкой ОК. В исходной базе данных SPSS все значения System Missing в переменных q2_l - q2_4 будут перекодированы в нули, единицы при этом сохранятся.
1.5.3.2. Перекодирование с образованием новых переменных
Рассмотрим теперь другой случай перекодирования переменных, в результате которого исходная переменная остается неизменной, а перекодированные значения отражаются в новой переменной. Данная процедура осуществляется при помощи меню Transform ► Recode ► Into Different Variables. Диалоговое окно Recode into Different Variables (рис. 1.22) аналогично окну Recode into Same Variables (рис. 1.20), только добавлена дополнительная область Output Variable, предназначенная для указания имени (Name) и метки (Label) вновь создаваемой переменной, которая будет содержать перекодированные значения.
В качестве примера мы взяли переменную ql6, содержащую ответы на вопрос относительно частоты покупок респондентами плавленого сыра. При этом опрошенные должны были выбрать один из восьми вариантов:
1. каждый день;
2. 3-4 раза в неделю;
3. 1-2 раза в неделю;
4. 1-2 раза в месяц;
5. реже 1 раза в месяц;
6. 1 раз в полгола:
7. 1 раз в год;
8. затрудняюсь ответить.
После перекодирования мы должны получить переменную ql6_rec, в которой интервалы 1,2 и 3 будут объединены в группу с кодом 1 (Частые покупатели); интервалы 4, 5, 6 и 7 — в группу с кодом 2 (Редкие покупатели); а интервал 8 — в значения System Missing.
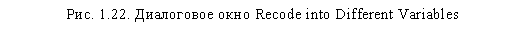 |
 |
Введите в соответствующие поля название и метку новой переменной. Обратите внимание, что в описываемом диалоговом окне также есть кнопка условного отбора данных If. Откройте диалоговое окно Old and New Values, щелкнув на одноименной кнопке (рис. 1.23).
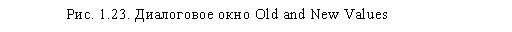 |
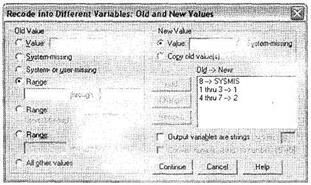 |
Это окно напоминает окно, представленное на рис. 1.21, но в нем также содержатся некоторые дополнительные полезные инструменты. По умолчанию значения исходной переменной, не указанные в списке перекодировки, не попадают в новую переменную. Изменить данное условие по умолчанию можно при помощи параметра Сору old value(s). Также появилась возможность конвертации числовых значений в строковые (параметр Output variables are strings). При этом изменится тип всей новой переменной; следовательно, все исходные значения должны быть перекодированы как
строковые. Существует и обратная возможность — конвертации строковых значений, похожих на цифры, в числовой вид (например, «5» в 5). Данная возможность реализуется при помощи параметра Convert numeric strings to numbers.
В нашем случае мы при помощи параметра Range перекодировали значения исходной переменной — от 1 до 3 — в 1, от 4 до 7 — в 2, а значение 8 — в System Missing. После щелчков в соответствующих диалоговых окнах на кнопах Continue и ОК будет создана новая переменная ql6_rec, содержащая перекодированные по указанной схеме значения переменной ql6.
1.5.3.3. Автоматическое перекодирование
Данная процедура предназначена для автоматического кодирования полей анкеты числовыми значениями типа индекс. В маркетинговых исследованиях эта процедура применяется в основном для текстовых полей в тех случаях, когда в анкете есть либо открытые вопросы (являющиеся текстовыми переменными в базе данных), либо варианты ответа Другое с дополнительным полем для указания респондентом конкретного варианта.
При выполнении процедуры одинаковые ответы из текстовых полей группируются, и им присваиваются соответствующие коды ответа (например, начиная с 1). Для того чтобы автоматическое перекодирование имело практический смысл, необходимо жестко формализовать ответы респондентов в текстовых полях. Если при заполнении анкет допускалась свободная формулировка респондентами своих ответов, следует перед вводом анкет в компьютер (или на этапе ввода) переформулировать их в соответствии с требованиями формализации. Меньшее количество различных вариантов ответа на открытый вопрос является предпочтительным, так как в дальнейшем при построении распределений большое число категорий трудно читается на графиках и в таблицах. Еще одно существенное требование к ответам респондентов на открытые вопросы — это достаточное количество респондентов в каждой группе ответов. Варианты ответов, указанные малым числом опрошенных, обычно относятся к варианту Другое.
Диалоговое окно Automatic Recode (рис. 1.24) вызывается при помощи меню Transform ► Automatic Recode. В нашем примере мы задавали респондентам вопрос Какие марки глазированных сырков Вы знаете?. После списка основных конкурентов на данном рынке в анкете был вариант ответа Другое (переменная q9_13t), в который записывались компании-производители, не вошедшие в данный перечень. Закодируем эти марки числовыми значениями (вместо текстовых полей). Для этого следует перенести из левого списка всех доступных переменных интересующую нас текстовую переменную q9_13t в область Variable ► New Name и в соответствующем поле указать новое имя вновь создаваемой числовой переменной q9_13t_n. Затем, чтобы подтвердить преобразование, необходимо щелкнуть на кнопке New Name. В группе переключателей Recode Starting from есть два параметра, позволяющие присвоить номера вариантам ответа либо по алфавиту, начиная с самого малого значения (Lowest value), либо начиная с конца упорядоченного списка вариантов ответа (Highest value).
После щелчка на кнопке ОК и выполнения указанных преобразований в базе данных будет создана новая числовая переменная (q9_13t_n) с вариантами ответа согласно списку перекодировки. Список также выводится SPSS (в окне SPSS Viewer), он показан на рис. 1.25.
 |
 |
 |
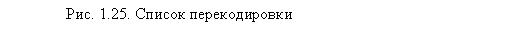
Как видно на рисунке, список разделен на три части: слева находятся значения исходной переменной (q9_13t); в среднем столбце расположены коды, под которыми данные текстовые значения представляются в новой переменной (q9_13t_n); правый столбец дублирует левый. Теперь по вновь созданной числовой переменной можно строить графики, а также использовать ее в других статистических процедурах.
1.5.4. Вычисление новых переменных
Вычисление новых переменных — весьма полезная возможность SPSS. При помощи данной функции можно производить расчеты по формулам любой сложности, задаваемым пользователем.
1.5.4.1. Вычисление новых переменных
Кроме перекодирования переменных, SPSS позволяет создавать новые переменные, содержащие либо совершенно новые значения, либо значения, вычисленные на основании существующих переменных. Таким образом действует процедура Compute Variable, вызываемая при помощи меню Transform ► Compute (рис. 1.26).
В качестве примера мы рассчитаем годовой объем закупок сметаны на основании имеющихся данных о частоте покупок данного продукта в месяц (интервальная переменная q5) и кратности покупок (интервальная переменная q6).
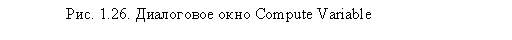 |
 |
В поле Target Variable мы указали имя вновь создаваемой переменной, которая будет содержать вычисленные для каждого респондента годовые объемы покупок сметаны. Далее щелкните на кнопке Type&Label и укажите метку и ее тип (рис. 1.27). В нашем случае в качестве метки в поле Label мы указали Годовой объем закупок сметаны. Новая переменная будет содержать числовые значения, поэтому мы выбрали тип Numeric.
 |
 |
После определения новой переменной в области Numeric Expression следует указать непосредственно рассчитываемое выражение. В нашем случае мы умножаем частоту покупок (q5) на кратность покупок (q6) и затем умножаем на 12 месяцев, чтобы получить объем покупок сметаны в год. После запуска процедуры вычисления новой переменной будет создана новая переменная q100, содержащая годовые объемы покупок сметаны каждым респондентом в выборке.
1.5.4.2. Подсчет значений переменных
Еще одной полезной возможностью SPSS, не рассмотренной при описании процесса модификации и отбора данных, является подсчет значений переменных (как правило, многовариантных).
Приведем пример. Предположим, у нас есть ответы респондентов на многовариантный вопрос Из каких источников Вы получаете информацию о рынке сантехники? с пятью вариантами ответа:
1. q22_l - газеты;
2. q22_2 — журналы;
3. q22_3 — выставки;
4. q22_4 — Интернет;
5. q22_5 — другие источники.
В результате работы описываемой процедуры мы получим новую переменную q100, в которой для каждого респондента в выборке будет отражаться количество используемых источников при поиске информации о рынке сантехники.
 |
Диалоговое окно Count Occurrences of Values within Cases, позволяющее выполнить поставленную задачу, открывается при помощи меню Transform ► Count (рис. 1.28). В полях Target Variable и Target Label следует указать соответственно имя вновь создаваемой переменной (q100) и ее метку (Количество используемых источников). В область Numeric Variables помещаются интересующие нас переменные q22_l - q22_5, значения которых необходимо подсчитать.
 |
Диалоговое окно Count Occurrences of Values within Cases так же, как и многие другие окна SPSS, содержит кнопку If, позволяющую осуществить расчеты не для всех респондентов в выборке, а только для отдельных групп.
Щелкните на кнопке Define Values. Открывшееся диалоговое окно (рис. 1.29) предназначено для указания конкретных значений рассматриваемых переменных, подлежащих подсчету. Так как у нас есть пять дихотомических переменных, соответствующих вариантам ответа на многовариантный вопрос, мы указали 1 в качестве объекта подсчетов.
 |
 |
Запустив процедуру, мы получим новую переменную с результатами расчетов. В дальнейшем мы можем построить по данной переменной линейное распределение (см. раздел 2), чтобы узнать, сколько респондентов используют при поиске сантехники только один, два, три, четыре или пять источников информации.
1.5.5. Коррекция нерепрезентативности выборки
В практике маркетинговых исследований случается, что собранные в ходе опроса данные не соответствуют параметрам генеральной совокупности (то есть являются нерепрезентативными). Такие ситуации возникают, если заложенные перед началом исследования социально-демографические квоты были искажены в результате нарушения методологии проведения исследования, ошибок в работе интервьюеров или недостаточного контроля проведения полевых работ.
Например, в результате проведения контрольных мероприятий после завершения основных полевых работ были выявлены многочисленные факты некорректного заполнения анкет интервьюерами или даже фальсификация анкет, вследствие чего из итоговой базы данных пришлось удалить некоторую часть анкет. Очевидно, что в этом случае социально-демографические квоты, заложенные в начале исследования и обеспечивающие соответствие параметров выборки параметрам общей генеральной совокупности (репрезентативность), скорее всего, изменятся. Это в свою очередь приведет к тому, что выводы, основанные на результатах проведенного опроса, не могут быть отнесены к генеральной совокупности. То есть мы не можем утверждать, что наши выводы действительно отражают мнение реальных потребителей. Исследование фактически теряет свой смысл.
Если полученная выборка является нерепрезентативной, применяется метод коррекции параметров выборки путем взвешивания. Приведем пример. Известно, что доля мужчин всего населения России составляет 45,5 %. В результате проведения всероссийского исследования оказалось, что доля мужчин в выборке составляет 72,1 %. Следовательно, полученная выборка является нерепрезентативной. Для устранения ошибки следует провести взвешивание, то есть скорректировать полученные значения переменной Пол (dl) на весовой коэффициент. Данный коэффициент рассчитывается для каждой социально-демографической группы по следующей формуле:
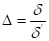
где  — весовой коэффициент;
— весовой коэффициент;  — значение исследуемого параметра в генеральной совокупности;
— значение исследуемого параметра в генеральной совокупности;  — значение исследуемого параметра в выборке.
— значение исследуемого параметра в выборке.
В нашем случае весовой коэффициент должен рассчитываться для двух социально-демографических групп: мужчин и женщин. (Если у вас большое количество групп, весовой коэффициент следует рассчитывать для каждой группы.) Для мужчин А будет равна: 45,5 % / 72,1 % ≈0,63. Так как у нас всего две группы, подлежащие взвешиванию (мужчины и женщины), то весовой коэффициент для женщин будет рассчитан так: (100 % - 45,5 %) / (100 % - 72,1 %) = 54,5 % / 27,9 « 1,95. (Если у вас большое количество групп, подлежащих взвешиванию, вам нужно знать значения параметров генеральной совокупности для каждой из групп.)
Итак, на первом этапе мы получили весовые коэффициенты, которые помогут нам скорректировать полученную нерепрезентативную выборку. Теперь необходимо создать новую переменную в файле данных SPSS, которая будет содержать для каждого респондента его вес (то есть для мужчин — 0,63, а для женщин — 1,95). Проще всего перекодировать с образованием новой переменной (как было описано в разделе 1.5.3.2).
В настоящем пособии мы не описываем важный элемент SPSS — программный синтаксис. Данный элемент является альтернативой использованию диалоговых окон в SPSS. Другими словами, все то, что можно сделать при помощи мыши в диалоговых окнах (и многое другое), можно выполнить посредством программного синтаксиса. В некоторых случаях его использование является предпочтительным. В частности, в нашем примере для создания новой весовой переменной удобнее воспользоваться синтаксисом. Откройте редактор синтаксиса File ► New ► Syntax. На экране появится окно, показанное на рис. 1.30. Введем в нем следующие команды:
if dl=l weight=45.5/72.1 .
if dl=2 weight=54.5/27.9 .
exe .
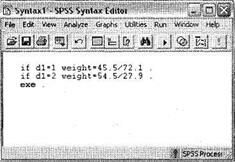 |
Обратите внимание, что в синтаксисе SPSS символ, отделяющий целую и дробную части числа, — всегда точка, а не запятая. Также следует внимательно относиться к точкам в конце каждой строки. Эти точки дают понять интерпретатору SPSS, что следует выполнить данную команду. Последовательность символов ехе. на третьей строке запускает процедуру синтаксиса. Рекомендуется использовать не приблизительные значения весовых коэффициентов (0,63 и 1,95), а вычисляемые выражения (45.5/72.1 и 54.5/27.9); что обеспечивает точность расчетов. После того как вы введете указанные строки в редакторе синтаксиса (см. рис. 1.30), выделите их все (это очень важно) и затем нажмите Ctrl+R или на кнопке ► на панели инструментов окна синтаксиса.
Вам также может быть полезна лекция "4 Государственная политика противодействия наркотизации общества".
В результате работы процедуры синтаксиса будет создана новая переменная weight, содержащая весовые коэффициенты для каждого респондента. Теперь осталось только провести собственно процедуру взвешивания каждого респондента на его весовой коэффициент. В этом вам поможет диалоговое окно Weight Cases (Data ► Weight Cases). В данном диалоговом окне (рис. 1.31) следует выбрать параметр Weight cases by, затем в левом списке всех доступных переменных выбрать весовую переменную (в нашем случае weight) и перенести ее в поле Frequency variable, при щелчке на кнопке ОК база данных будет скорректирована на весовые коэффициенты, и репрезентативность данных будет восстановлена. Для отмены взвешивания следует в данном диалоговом окне установить переключатель в положение Do not weight cases.
 |
 |
Если искажение квот в выборке произошло не только по одной социально-демографической переменной, а сразу по нескольким (например, не только по полу, но и по возрасту и уровню образования), следует сначала создать отдельные весовые переменные для каждой из искаженных социально-демографических переменных, а затем создать новую общую весовую переменную, которая будет произведением всех отдельных весовых коэффициентов (то есть для каждого респондента: вес по полу, вес по возрасту, вес по образованию).
При всей кажущейся простоте корректировки репрезентативности при помощи взвешивания следует иметь в виду, что для использования данного метода существуют серьезные ограничения. Например, часто число респондентов во взвешенной базе данных оказывается иным, чем в невзвешенной. Это происходит из-за того, что сумма весовых коэффициентов по всем респондентам не равна общему количеству респондентов. Также нужно весьма осторожно подходить к интерпретации статистических тестов по взвешенной базе. Поскольку число респондентов с определенными социально-демографическими характеристиками во взвешенной базе искусственно увеличивается (в нашем случае это доля женщин), рассчитанная статистическая значимость является некорректной. Таким образом, взвешивание рекомендуется проводить для построения общих (линейных) распределений.
Итак, в главе 1 мы подробно рассмотрели часто используемые в маркетинговых исследованиях методы манипуляции с данными. SPSS содержит массу других дополнительных возможностей, но в данном пособии мы не стали их приводить, поскольку на практике эти методы не находят широкого применения.
Рекомендуемые лекции
- 4 Государственная политика противодействия наркотизации общества
- 9 Основные методологические и тактические способы управления
- 9 Основные этапы складывания Московского централизованного государства
- 56 Понятие общеcтвенно-экономичеcкой формации и способа производства в историко-материалистической модели социальной реальности
- 80 Мясные кулинарные изделия



















