
Системы технического зрения
ГЛАВА 6. Системы технического зрения
Человек по визуальному каналу получает более 60% всей информации, регулирующей его взаимодействие с внешней средой. (От глаз к мозгу передаются сигналы по двум из трех миллионов нервных волокон, связанных с мозгом). Это же справедливо и для искусственных сенсорных систем: те из них, которые используют визуальную информацию, обладают наибольшей информативностью. В классе ОЛС особое место занимают системы технического зрения (СТЗ), относящиеся к группе бесконтактных пассивных информационных средств. Для большей части СТЗ характерно отсутствие излучателя; система содержит только приемник собственного излучения объекта. Однако в некоторых случаях излучатель используется, это относится, в частности, к рентгеновским телевизионным системам. СТЗ функционируют в широком диапазоне электромагнитного излучения - от 10-1 м (для телевидения ОВЧ) до 10-9 м. Существенной особенностью систем этого типа является необходимость формирования изображения объекта, представляющего собой распределение интенсивности его двумерной функции яркости L(x, y). Заметим, что для большинства систем локации функция распределения интенсивности одномерная - L(z). СТЗ нашли применение в задачах визуального контроля, наблюдения, управления и многих других.
Наибольшее распространение получили системы, работающие в видимом диапазоне волн - 380 … 780 нм. Поскольку, все окружающие предметы поглощают и отражают разное количество света в зависимости от его длины волны, то и спектральная отражательная способность объекта распределяется в видимом диапазоне волн неравномерно. Эта особенность приводит к тому, что поверхность объекта воспринимается разноцветной. Кроме того, и амплитуда отраженного от объекта сигнала, т.е. его яркость неодинакова. Разница в средней яркости соседних структур воспринимается как их контраст. Средняя яркость окружающей среды варьируется в широких пределах: от 10-6 кд/м2 пасмурной ночью, 10-1 кд/м2 в полнолуние, до 107 кд/м2 в солнечный день на снежном поле. Человек способен достаточно уверенно ориентироваться в этом диапазоне яркостей, поскольку его зрение способно воспринимать энергии, крайние значения которых соотносятся как 1: 1011. Однако этот диапазон не является динамическим, т.к. для зрения свойственна адаптация к освещению и при постоянном освещении диапазон воспринимаемых яркостей не превышает 100.
6.1. Основные понятия
 Системы зрения предназначены для восприятия визуальной информации об окружающей среде, обработки и анализа изображений рабочих сцен с целью решения задачи распознавания образов. Обработка визуальной информации, как в живых, так и технических системах заключается в получении некоторого представления сцены - ее изображения и формирование последующего описания. Описание должно, с одной стороны, содержать всю существенную информацию о сцене, а с другой - обеспечивать обработку изображений за необходимое время. В этом смысле, при описании происходит частичное выделение искомой информации, при некоторой потере общей. Баланс этих двух процедур является важнейшей задачей СТЗ. Под распознаванием образов будем понимать процесс, при котором на основании многочисленных характеристик (признаков) некоторого объекта определяется одна или несколько наиболее существенных, но недоступных для непосредственного определения его характеристик, в частности его принадлежность к определенному классу объектов. Данное определение является «кибернетическим» и используется в задачах искусственного интеллекта при анализе любых сложных изображений, когда отсутствует ограничение по времени обработки данных. Функционирование робототехнических систем обычно осуществляется в «реальном масштабе времени» и требует разрешения классического противоречия между быстродействием системы и ее объемом памяти. В этом смысле, далеко не все задачи распознавания являются доступными. Так, например, распознавание сложных трехмерных образов требуют очень высоких ресурсов производительности ~ 1 .. 100 109 MIPS (миллионов операций в секунду). Поэтому, такие задачи «напрямую» в робототехнике не решаются. Здесь традиционным путем является конкретизация начальных условий - позволяющая упростить алгоритмы распознавания. В частности, в большинстве случаев ограничиваются плоскими изображениями объектов. Если требуется восстановить форму объекта, используется несколько изображений, причем таких, на которых видны все точки поверхности и их взаимное положение. Однако и в этом случае, форма объекта может оказаться недоступной для непосредственного рассмотрения. В зависимости от формы различают два класса объектов:
Системы зрения предназначены для восприятия визуальной информации об окружающей среде, обработки и анализа изображений рабочих сцен с целью решения задачи распознавания образов. Обработка визуальной информации, как в живых, так и технических системах заключается в получении некоторого представления сцены - ее изображения и формирование последующего описания. Описание должно, с одной стороны, содержать всю существенную информацию о сцене, а с другой - обеспечивать обработку изображений за необходимое время. В этом смысле, при описании происходит частичное выделение искомой информации, при некоторой потере общей. Баланс этих двух процедур является важнейшей задачей СТЗ. Под распознаванием образов будем понимать процесс, при котором на основании многочисленных характеристик (признаков) некоторого объекта определяется одна или несколько наиболее существенных, но недоступных для непосредственного определения его характеристик, в частности его принадлежность к определенному классу объектов. Данное определение является «кибернетическим» и используется в задачах искусственного интеллекта при анализе любых сложных изображений, когда отсутствует ограничение по времени обработки данных. Функционирование робототехнических систем обычно осуществляется в «реальном масштабе времени» и требует разрешения классического противоречия между быстродействием системы и ее объемом памяти. В этом смысле, далеко не все задачи распознавания являются доступными. Так, например, распознавание сложных трехмерных образов требуют очень высоких ресурсов производительности ~ 1 .. 100 109 MIPS (миллионов операций в секунду). Поэтому, такие задачи «напрямую» в робототехнике не решаются. Здесь традиционным путем является конкретизация начальных условий - позволяющая упростить алгоритмы распознавания. В частности, в большинстве случаев ограничиваются плоскими изображениями объектов. Если требуется восстановить форму объекта, используется несколько изображений, причем таких, на которых видны все точки поверхности и их взаимное положение. Однако и в этом случае, форма объекта может оказаться недоступной для непосредственного рассмотрения. В зависимости от формы различают два класса объектов:
· объекты, все точки которых можно увидеть под определенными углами зрения;
· объекты, некоторые точки невидимы независимо от угла зрения.
Так, полное описание выпуклого объекта можно получить на основании двух его изображений (например, при использовании двух видеодатчиков с правильно выбранным направлением съемки рис. 6.1). Под выпуклым понимается объект, для которого касательная плоскость в любой точке поверхности не разрезает эту поверхность.
Способ расположения видеодатчиков зависит от того, необходима ли информация о рельефе объектов. Двумерные неподвижные датчики такую информацию дать не могут, и поэтому в состав СТЗ входят либо несколько двухмерных датчиков, либо сканер - подвижный двумерный датчик. (Аналогично получают двумерную информацию от одномерного датчика, сканируя им рабочую сцену).
Рекомендуемые материалы
Вообще говоря, поверхность реального объекта является сложной и содержит как выпуклые участки, так и вогнутые. При анализе подобных объектов необходимо выбирать бесконечное множество направлений съемки, покрывающих телесный угол 4p. Однако и в этом случае возможны области недоступные для наблюдения. Таким образом, даже максимально полное трехмерное описание объекта, может оказаться недостаточным для его адекватного распознавания. Поэтому, распознавание образов в СТЗ (как, впрочем, и у человека) основывается на признаках, полученных при анализе частичных изображений.
По назначению СТЗ условно можно разделить на два класса:
1. прикладные (предназначенные для обработки ограниченного количества изображений с заданным быстродействием);
2. универсальные (позволяющие анализировать сложные сцены на основе принципов искусственного интеллекта).
Первые исследовательские СТЗ появились в конце 60-х годов ХХ века. В Стенфордском проекте «глаз - рука» СТЗ содержала телекамеру на основе видикона, устройство полукадрового ввода изображения 606´500 элементов с 16 градациями яркости и ЭВМ типа PDP-6. В 1972 году в Массачусетском Технологическом Институте была разработана опытная система для обработки трехмерных сцен. Родоначальником промышленных СТЗ явилась фирма SRI International выпустившая в 1975 году систему Vicion Module, обрабатывающую бинарные изображения и ставшую прототипом большинства современных СТЗ. (На основе тех же аппаратно-программных принципов в 1978 году была построена классическая система VS-100, фирмы Machine Intellegence Corp.). Сейчас в промышленности СТЗ используются для контроля качества (первыми определять дефекты на печатных платах предложила фирма Hitachi), отслеживания контуров при механической обработке и дуговой сварке, в задачах сборки и монтажа деталей, конвейерной сортировки, видеонаблюдения и др.
Рынок СТЗ быстро растет. Так, если в 1994 году в США было выпущено около 60000 систем со средней стоимостью ~ 20000 долларов, то к началу XXI века их производство увеличилось в 3,4 раза. В мировом рынке США занимает около 40 %, Японии и Франции по 15 %, Великобритании и Германии по 8 %. Выпуском СТЗ занимается более 200 крупных фирм.
Современные СТЗ классифицируются по трем основным признакам.
1. По характеру решаемых задач: мощные, средние, малые и персональные.
2. По структуре вычислительного процесса: однопроцессорные, многопроцессорные, системы на базе матричного процессора, системы поточной обработки.
3. По типу первичного преобразователя: одномерные или 1D (например, на базе ПЗС-линейки), двумерные или 2D (используются стандартные телекамеры), подвижные двумерные или K2D, трехмерные или 3D (рельефные стереокамеры).
В настоящее время в зависимости от технической задачи и типа датчиков наибольшее распространение получили 5 схем построения СТЗ (табл. 6.1).
Таблица 6.1. Схемы построения СТЗ
| Вариант | Тип изображения | Тип вычислительной структуры | Тип датчика | ||||
| плоское | объемное | последовательная | параллельная | смешанная | цветной | черно-белый | |
| 1 | + | - | + | - | - | - | + |
| 2 | + | + | - | м | - | + | + |
| 3 | + | - | - | - | мк | - | + |
| 4 | + | + | - | к | - | - | + |
| 5 | + | + | - | т | - | + | + |
Примечание.
Буквами «м», «мк», «к» и «т» обозначены архитектуры на базе матричного и конвейерного процессоров, транспьютера, а также использующие смешанный «матрично-конвейерный» способ обработки данных.
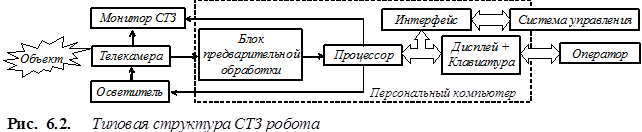
Наиболее распространенной схемой СТЗ является однопроцессорная схема, которая строится на базе персонального компьютера. Системы такого рода иногда называются персональными (рис 6.2). Более 80% эксплуатируемых СТЗ относятся к однопроцессорным. В ряде случаев, предварительная обработка изображений осуществляется аппаратно, с помощью специализированных устройств ввода - фреймграбберов. Так были организованы, в частности, отечественные системы типа «Videoscan» и «Megapixel». Однопроцессорная структура относится к первому поколению СТЗ и имеет существенный недостаток - невозможность обработки сложных (в том числе - цветных) изображений в реальном масштабе времени. Относительно низкое быстродействие этих систем обусловлено невозможностью распараллеливания вычислений и отсутствием специальной шины для передачи изображений. Наиболее распространенным путем повышения производительности СТЗ явилась идеология фирмы Data Translation (США), предполагающая не только аппаратную фильтрацию изображений, но и использование в устройстве ввода программируемых логических матриц, позволяющих изменять алгоритм обработки в зависимости от типа и характера изображения. В большинстве случаев персональная СТЗ включается в состав системы управления соответствующим оборудованием, а ее обучение осуществляется в ручном или полуавтоматическом режиме оператором.
С целью уменьшения времени на пересылочные операции из памяти в процессор и обратно производится разделение потоков информации, т.е. создаются многошинные структуры. Примером такой СТЗ является модель DT - 100, фирмы Data Translation. Большинство таких систем имеют две шины, по одной передается видеоинформация, по другой управляющие сигналы (рис. 6.3а). Это позволяет совмещать во времени процесс управления системой и передачу данных. С точки зрения организации вычислений система включает несколько блоков обработки данных (например, однокристальных) БО1 ... БОN. Каждый блок специализирован на определенный круг задач, которые решаются параллельно. Общее управление работой системы осуществляется персональным компьютером. Такая структура тоже не лишена недостатков, которые связаны с наличием конфликтов на шинах. Их разрешение требует, либо организации жесткой приоритетной дисциплины обращения к шинам, либо использования шинного арбитра и диспетчера заданий. Первый способ дает большой выигрыш по быстродействию, но возможен только для определенного класса задач обработки изображений, второй позволяет анализировать любые изображения, но его реализация ведет к временным потерям на анализ изображения, определение процедур обмена и выдачу текущих заданий блокам обработки данных.
Одним из условий эффективной реализации процесса параллельной обработки, является наличие у задачи свойства «внутреннего параллелизма», благодаря которому задачи могут быть разбиты на «квазинезависимые» части. В целом, реализация этой концепции требует слишком большого числа вычислительных блоков, и поэтому, на существующих параллельных системах используют смешанный последовательно-параллельный принцип организации вычислений. (Примером этой структуры СТЗ является модель 79а фирмы Kawasaki).
Вычислительная система на базе матричного процессора осуществляет параллельную обработку данных при полной загрузке процессоров (рис. 6.3б). Такая структура, называемая SIMD (Single Instruction Multiple Data) представляет собой матрицу процессорных элементов, использующих одно устройство управления. Устройство управления формирует единый поток команд ко всем подчиненным процессорам, которые одновременно выполняют одну и ту же операцию, но со своими данными. Анализ подобной архитектуры показывает, что для «квазинезависимых задач» она достигает максимального быстродействия. Очевидным недостатком СТЗ на базе матричного процессора является их чрезмерная стоимость. Среди известных структур этого типа отметим систему РЕРЕ, использующуюся министерством обороны США для обработки визуальной информации о воздушной обстановке.

Системы на базе конвейерной архитектуры, называемой MISD (Multiple Instruction Single Data), эффективны при обработке массивов данных за длительный период данных. В СТЗ конвейерная (поточная) обработка используется в случае массивов с большим числом элементов поля и числом градаций яркости (рис.6.4). Конвейер состоит из последовательности процессорных элементов, каждый из которых выполняет свою группу операций, а результат появляется на выходе последнего из них. Максимальный эффект достигается в случае когда на конвейере одновременно находится p блоков данных, где p - длина конвейера. На практике такая ситуация возможна только на определенном этапе вычислительного процесса, поскольку массивы имеют конечную размерность и после обработки последнего элемента массива i-ый процессорный элемент переходит в режим ожидания, в то время как конечный результат будет получен только через p-шагов. В настоящее время известен конвейерный видеопроцессор PIPE для обработки сложных изображений в реальном времени.
Последним достижением в области построения высокоскоростных систем параллельной обработки изображений явилось использование транспьютеров. Транспьютерные системы позволяют на одной и той же аппаратуре формировать различные топологии процессоров («линейка», «кольцо», «дерево», «решетка», «гиперкуб» и др.) и различные типы параллельных архитектур (MISD, SIMD, MIMD). Для каждой из задач обработки видеоинформации существуют оптимальные топологии, обеспечивающие их эффективное решение. Так, алгоритмам распознавания и идентификации, характеризующимся сужением потока данных (от большого массива пиксельных данных к данным на уровне объекта) соответствует структура типа «дерево», в корне которого формируется обобщенное описание признаков объектов кадра.
В табл. 6.2 представлены некоторые модели СТЗ, реализованные в рамках рассмотренных схем.
Таблица 6.2. Примеры промышленных СТЗ
| Модель | Тип СТЗ | Область применения | Производительность (тип ЭВМ) | Устройство ввода | Размер кадра, N´N | Цена, тыс. $ |
| Cybe Ikon (США) | мощная | космическая съемка | высокая (IBM 370) | сканеры | 4000´4000 | До 1000 |
| Magiscan (Англия) | средняя | биология, медицина | средняя | специальные телекамеры | 1024´1024 | До 100 |
| VS - 100 (США) | малая | промышленность | малая (LSI - 11) | промышленные телекамеры | 256´256 | 1 … 10 |
| DT - 2871 (США) | персональная | охранные системы | средняя (PDP, IBM PC) | бытовые телекамеры | 512´512 | 0,1 … 1 |
 В робототехнике, как правило, используются достаточно простые схемы СТЗ, поэтому к 2000 году более 70% роботов США оснащались этими средствами. В зависимости от задачи и типа робота наиболее распространены 2D и K2D системы (рис. 6.5). В первом случае, применяются видеодатчики, формирующие плоскую рабочую сцену. Во втором, при сканировании плоской сцены выделяется трехмерная информация. Типичным решением при построении системы управления роботов с СТЗ явилась известная структура «главная машина - сателлит» . Здесь инициализация работы СТЗ осуществляется главной машиной, в качестве которой обычно выступает управляющая ЭВМ робота. Вся обработка видеинформации производится в СТЗ (сателлите), которая затем передает в главную машину соответствующие данные. Чаще всего такими данными являются характеристики рабочей сцены, координаты конкретных объектов и т.д. Описанная структура системы управления получила название двухуровневой: на нижнем уровне производится обработка сенсорной информации, а на верхнем - непосредственное управление манипулятором.
В робототехнике, как правило, используются достаточно простые схемы СТЗ, поэтому к 2000 году более 70% роботов США оснащались этими средствами. В зависимости от задачи и типа робота наиболее распространены 2D и K2D системы (рис. 6.5). В первом случае, применяются видеодатчики, формирующие плоскую рабочую сцену. Во втором, при сканировании плоской сцены выделяется трехмерная информация. Типичным решением при построении системы управления роботов с СТЗ явилась известная структура «главная машина - сателлит» . Здесь инициализация работы СТЗ осуществляется главной машиной, в качестве которой обычно выступает управляющая ЭВМ робота. Вся обработка видеинформации производится в СТЗ (сателлите), которая затем передает в главную машину соответствующие данные. Чаще всего такими данными являются характеристики рабочей сцены, координаты конкретных объектов и т.д. Описанная структура системы управления получила название двухуровневой: на нижнем уровне производится обработка сенсорной информации, а на верхнем - непосредственное управление манипулятором.
Несмотря на свое подчиненное по отношению к главной машине положение, СТЗ способна решать весьма сложные информационные задачи. Преобразование информации в СТЗ обычно представляется в виде последовательности шести основных этапов [ ]:
· восприятия или ввода информации (т.е. получения визуального изображения с помощью видеодатчиков);
· предварительной обработки изображения (предполагает использование методов подавления шума и улучшения изображений отдельных деталей сцены);
· сегментации (обычно, выделения на изображении одного или нескольких интересующих объектов);
· описания (определения характерных параметров объекта: размеров, формы и т.д., необходимых для его выделения из числа всех, образующих сцену);
· распознавания (как этап обработки информации представляет собой идентификацию объекта, т.е. отнесение его к некоторому классу, например, «болт», «блок двигателей»);
· интерпретации (выявления принадлежности к группе распознаваемых объектов, например, «на сцене есть несколько гаек»).
В соответствии с тем, какие этапы преобразования информации реализуются конкретной СТЗ, она может быть отнесена к мощной, средней или малой (персональной). Так, задачи, решаемые малыми СТЗ (их иногда называют СТЗ низкого уровня), ограничиваются восприятием и предварительной обработкой информации. (По словам К. Фу подобные задачи можно сравнить с теми, что решает человек, пытающийся найти свое место в темном зале кинотеатра, куда он попал с яркой улицы). В СТЗ среднего уровня решаются задачи сегментации, описания и распознавания отдельных объектов. Алгоритмы, используемые на нижнем и среднем уровнях, основаны на традиционных подходах к обработке информации и разработаны достаточно хорошо, в то время как процессы верхнего уровня, в значительной степени, не определены.
6.2. Основы формирования и передачи изображений
На первом этапе преобразования информации производится непосредственно формирование изображения, заключающееся в определении значений яркости L(x, y) каждой конкретной точки изображения. Собственно изображение представляет собой распределение яркости элементов сцены в пространственной области, сигнал же изображения представляет собой развертку этого распределения в области временной (рис. 6.6). Данные преобразования реализуются разнообразными телевизионными камерами, используемыми также и для передачи изображения на расстояние.
 Рассмотрим основные вехи в развитии техники передачи изображений. Первые опытные демонстрации изображений на расстоянии были проведены практически одновременно в Англия, США и СССР в 1925 -1926 г.г., а начало регулярного вещания датируется 1928 г. Пионерами были Англия и Германия; вещание в СССР открылось в 1931 г. Первая телевизионная система была оптико-механической и содержала 30 строк разложения изображения. Телевизионные передатчики на этом этапе ничем не отличались от радиопередатчиков и также работали в диапазоне звукового вещания. Решительный шаг к созданию первой передающей телевизионной трубки «иконоскопа» сделали В.К. Зворыкин (США) и С.И. Катаев (СССР). Зворыкин был командирован в США в 1917 г. А.Ф. Керенским, добился там значительных результатов и обратно не был выпущен уже американцами. Первая электронная система разложения изображения была реализована с его участием в США в 1936 г. и имела стандарт разложения в 343 строки. В том же году в Англии началось вещание по стандарту 405 строк. Автором этого стандарта стал еще один выходец из России И. Шоэнберг. В 1938 г. вещание по электронной системе с 455 строками открылось во Франции, Германии и Италии (441 строка). Весной того же года на импортном оборудовании по стандарту разложения 343 строки начал вещать СССР. Все указанные системы использовали чересстрочную развертку, однако, осенью на ленинградском телецентре было установлено отечественное оборудование с прогрессивным разложением сигнала на 240 строк. Во время Второй мировой войны работы продолжались только в США, где и был принят в 1943 г. современный стандарт разложения 525 строк 60 полей/с. В Европе первым возобновил вещание СССР в мае 1945 г., и вскоре у нас был принят стандарт 625 строк 50 полей/с. В настоящее время в мире действуют два стандарта телевизионного разложения: 625/50, охватывающий 150 стран с населением ~ 5 млрд. и 525/60 - 55 стран с населением 1 млрд.
Рассмотрим основные вехи в развитии техники передачи изображений. Первые опытные демонстрации изображений на расстоянии были проведены практически одновременно в Англия, США и СССР в 1925 -1926 г.г., а начало регулярного вещания датируется 1928 г. Пионерами были Англия и Германия; вещание в СССР открылось в 1931 г. Первая телевизионная система была оптико-механической и содержала 30 строк разложения изображения. Телевизионные передатчики на этом этапе ничем не отличались от радиопередатчиков и также работали в диапазоне звукового вещания. Решительный шаг к созданию первой передающей телевизионной трубки «иконоскопа» сделали В.К. Зворыкин (США) и С.И. Катаев (СССР). Зворыкин был командирован в США в 1917 г. А.Ф. Керенским, добился там значительных результатов и обратно не был выпущен уже американцами. Первая электронная система разложения изображения была реализована с его участием в США в 1936 г. и имела стандарт разложения в 343 строки. В том же году в Англии началось вещание по стандарту 405 строк. Автором этого стандарта стал еще один выходец из России И. Шоэнберг. В 1938 г. вещание по электронной системе с 455 строками открылось во Франции, Германии и Италии (441 строка). Весной того же года на импортном оборудовании по стандарту разложения 343 строки начал вещать СССР. Все указанные системы использовали чересстрочную развертку, однако, осенью на ленинградском телецентре было установлено отечественное оборудование с прогрессивным разложением сигнала на 240 строк. Во время Второй мировой войны работы продолжались только в США, где и был принят в 1943 г. современный стандарт разложения 525 строк 60 полей/с. В Европе первым возобновил вещание СССР в мае 1945 г., и вскоре у нас был принят стандарт 625 строк 50 полей/с. В настоящее время в мире действуют два стандарта телевизионного разложения: 625/50, охватывающий 150 стран с населением ~ 5 млрд. и 525/60 - 55 стран с населением 1 млрд.
6.2.1. Понятие о видеосигнале
Сигнал яркости (он же сигнал изображения Y) является аналоговым многоуровневым сигналом. На рис. 6.6 показано распределение яркости в пределах одной строки растра при передаче простого изображения (черной и белой полос на сером фоне).
Полным видеосигналом называется совокупность сигнала изображения и служебных сигналов. Сигнал изображения строится из сигналов яркости и цветности, служебные сигналы представляют собой набор гасящих, синхронизирующих, уравнивающих импульсов, а также импульсов «врезки».
Принципы развертки сигнала в системах черно-белого и цветного телевидения одинаковые, сигнал цветности лишь «подмешивается» в спектр сигнала яркости. Поэтому при анализе развертки видеосигнала не будем уточнять тип сигнала изображения, а рассмотрим этот вопрос при анализе спектра видеосигнала.
 Телевизионное изображение воспроизводится путем последовательного сканирования электронным лучом покрытого электролюминисцирующим веществом экрана. Сканирование происходит слева направо вдоль горизонтальных линий (телевизионных строк) и сверху вниз по строкам. При развертке кадра луч пробегает строку за строкой сверху вниз до самого низа экрана, а затем возвращается назад, и вся процедура повторяется со следующим кадром. За счет инерционности глаза в процессе подобного сканирования вызываемые вспышки света сливаются в линии, а затем в полное изображение. В результате полный телевизионный кадр представляет собой совокупность последовательно высвечиваемых линий, передающих пространственное распределение изображения. В большинстве систем используется чересстрочная развертка, когда весь растр разбивается на два полукадра - четный и нечетный. Сначала прочерчиваются нечетные строки, образуя нечетный полукадр, затем луч отклоняется вверх, и прочерчиваются четные. Сигнал яркости, по существу, формирующий черно-белое изображение сцены, образуется во время прямого хода луча развертки на активных строках (рис. 6.7). Во время обратного хода луч гасится, что достигается подачей на прожектор передающей камеры (видеодатчика) и приемной (кинескопа) гасящих импульсов. Длительность строчного гасящего импульса составляет 12 мкс или около 19% периода строки, длительность кадрового гасящего импульса - 1600 мкс, т.е. ~ 8% периода полукадра. В результате действия строчных гасящих импульсов все активные строки на экране разделены тонкими черными промежутками, хорошо видными на близком расстоянии. Кадровые гасящие импульсы образуют широкие промежутки между кадрами, однако, при устойчивом изображении они не видны, т.к. располагаются за пределами поля экрана.
Телевизионное изображение воспроизводится путем последовательного сканирования электронным лучом покрытого электролюминисцирующим веществом экрана. Сканирование происходит слева направо вдоль горизонтальных линий (телевизионных строк) и сверху вниз по строкам. При развертке кадра луч пробегает строку за строкой сверху вниз до самого низа экрана, а затем возвращается назад, и вся процедура повторяется со следующим кадром. За счет инерционности глаза в процессе подобного сканирования вызываемые вспышки света сливаются в линии, а затем в полное изображение. В результате полный телевизионный кадр представляет собой совокупность последовательно высвечиваемых линий, передающих пространственное распределение изображения. В большинстве систем используется чересстрочная развертка, когда весь растр разбивается на два полукадра - четный и нечетный. Сначала прочерчиваются нечетные строки, образуя нечетный полукадр, затем луч отклоняется вверх, и прочерчиваются четные. Сигнал яркости, по существу, формирующий черно-белое изображение сцены, образуется во время прямого хода луча развертки на активных строках (рис. 6.7). Во время обратного хода луч гасится, что достигается подачей на прожектор передающей камеры (видеодатчика) и приемной (кинескопа) гасящих импульсов. Длительность строчного гасящего импульса составляет 12 мкс или около 19% периода строки, длительность кадрового гасящего импульса - 1600 мкс, т.е. ~ 8% периода полукадра. В результате действия строчных гасящих импульсов все активные строки на экране разделены тонкими черными промежутками, хорошо видными на близком расстоянии. Кадровые гасящие импульсы образуют широкие промежутки между кадрами, однако, при устойчивом изображении они не видны, т.к. располагаются за пределами поля экрана.
 Диапазон яркости определяет разницу между сигналами, соответствующими черному и белому изображениям. Уровень черного составляет ~ 65 ... 70% полной амплитуды сигнала, уровень белого - 10 ... 15% (рис. 6.8). Следовательно, черное передается высоким уровнем. Этот способ кодирования яркости, получивший название негативная модуляция, позволяет снизить среднюю излучаемую мощность, т.к. обычно на изображении преобладают светлые тона. При этом помехи проявляются в виде черных точек, плохо различаемых глазом.
Диапазон яркости определяет разницу между сигналами, соответствующими черному и белому изображениям. Уровень черного составляет ~ 65 ... 70% полной амплитуды сигнала, уровень белого - 10 ... 15% (рис. 6.8). Следовательно, черное передается высоким уровнем. Этот способ кодирования яркости, получивший название негативная модуляция, позволяет снизить среднюю излучаемую мощность, т.к. обычно на изображении преобладают светлые тона. При этом помехи проявляются в виде черных точек, плохо различаемых глазом.
Все служебные сигналы лежат в области «чернее черного». Амплитуда полного видеосигнала (между уровнями черного и синхронизирующих импульсов) составляет 1 В на нагрузке 75 Ом.
Обеспечение синхронной и синфазной работы всех развертывающих схем видеодатчика и кинескопа достигается подачей строчных (в конце прямого хода каждой строки) и кадровых (в конце каждого полукадра) синхроимпульсов. Стандартом установлена длительность кадровых синхроимпульсов - 160 мкс, строчных - 4,7 мкс. Для обеспечения качественного воспроизведения сигнала (чтобы не было смещения строк в начале развертки полукадров, т.е. излома вертикальных линий в верхней части экрана), а также обеспечения устойчивости чересстрочной развертки, сигнал синхронизации усложняется путем «врезки » сточной частоты в кадровые синхроимпульсы и передачи уравнивающих импульсов. Длительность всех этих служебных сигналов составляет 2,35 мкс.
В отечественном телевизионном стандарте принята чересстрочная развертка видеосигнала, которая по ГОСТ 7845-79 характеризуется следующими параметрами:
· числом строк разложения в одном кадре Z (Z = 625 твл - телевизионных линий);
· числом кадров в секунду nк (nк = 25);
· форматом кадра K (K = 4/3);
· периодом развертки кадра Tк (Tк = 40 мс);
· периодом развертки полукадра (поля) Tп (Tп = 20 мс);
· периодом развертки строки Tс (Tс = 64 мкс). При этом Тс = Тк/Z.
 Следовательно, частота развертки полного кадра fк равна: fк = 1/Tк = 25 Гц, частота развертки поля fп = 2 fк = 50 Гц, и, наконец, частота строчной развертки fс = 1/Tс = 15625 Гц.
Следовательно, частота развертки полного кадра fк равна: fк = 1/Tк = 25 Гц, частота развертки поля fп = 2 fк = 50 Гц, и, наконец, частота строчной развертки fс = 1/Tс = 15625 Гц.
Номинальное число элементов разложения N по полю зрения телекамеры (при передаче черно-белого сигнала и хорошей четкости изображения) определяется выражением:
N = K Z2 или 4/3 (625)2 = 520833
Частотный спектр видеосигнала характеризуется верхней fв и нижней fн граничной частотой и зависит как от характера изображения, так и от параметров развертки. Нижняя граничная частота соответствует изображению, имеющему минимальное число изменений яркости. Период этого импульсного сигнала равен периоду полукадра Tп, а его частота - частоте кадровой развертки fн = fп (рис. 6.9а). Следовательно, fп = 50 Гц. (Время смены полукадров в телевизионном стандарте равно 0,02 с, что существенно меньше инерционности глаза, составляющей ~ 0,1 ... 0,15 с). Верхняя граничная частота fв соответствует изображению, содержащему максимальное число элементов, яркость которых позволяет раздельно передать камера (рис. 6.9б). Получим fв = N fк = 520833´25 » 13 МГц. Это значение fв применяется при прогрессивной (построчной) развертке. Передача столь широкополосного сигнала вызывает значительные технические трудности, для уменьшения которых, собственно, и была предложена чересстрочная развертка. В этом случае, значение fв уменьшается вдвое:
fв = K Z2 fн/4 = 6,5 мГц
Таким образом, чересстрочная развертка вдвое сужает спектр сигнала, что весьма существенно при передаче изображений по каналам связи. Обычно в расчетах полагают fв = 6,0 Мгц. При увеличении частоты смены кадров или строк разложения, увеличивается верхний частотный предел fв и расширяется частотный спектр сигнала изображения. (Геометрические размеры каждого элемента разложения d соответствуют высоте строки, которая, в свою очередь, определяется апертурой - размером развертывающего электронного луча).
Разрешающая способность канала передачи изображений определяется числом строк разложения и шириной спектра видеосигнала. Для принятого в нашей стране стандарта 625 строк и 50 полей 1 МГц частоты видеосигнала соответствует разрешающей способности по горизонтали 78 твл. Следовательно, максимальная разрешающая способность телевизионного изображения по горизонтали ограничена величиной 78´6,5 = 507 твл. (Обычно считают, что ширина спектра ограничена 6 МГц и тогда 78´6 = 468 твл). В ряде европейских стран изображение занимает лишь 575 строк из 625. Остальные используются для передачи телетекста. Спектр сигнала яркости при этом соответствует 5 МГц.
 Полный телесигнал передается путем АМ несущей частоты, следовательно, его частотный спектр содержит несущую частоту fнес и две боковые полосы. (В отличие от изображения сигнал звукового сопровождения в телевидении обычно представляет собой ЧМ колебание несущей частоты). Как известно, ширина спектра такого сигнала определяется удвоенной максимальной частотой модулирующего сигнала fв. Поэтому, радиосигнал изображения в отечественном вещании занимает полосу 13 МГц. Для АМ сигнала характерно, что каждая из боковых частот содержит полную информацию о сигнале. Следовательно, без потери качества можно одну из них подавить, сузив, тем самым, и спектр сигнала. Обычно, частично (для сохранения несущей частоты) подавляется нижняя боковая частота (1,25 МГц), верхняя же передается полностью (рис. 6.10). Применительно к телевещанию, это позволяет увеличить число передаваемых каналов в отведенном диапазоне волн. Во всех случаях АМ fнес должна в несколько раз превышать максимальную частоту fв спектра модулирующего сигнала. Например, в отечественном стандарте наименьшая несущая частота соответствует I частотному каналу и равна 49,75 МГц.
Полный телесигнал передается путем АМ несущей частоты, следовательно, его частотный спектр содержит несущую частоту fнес и две боковые полосы. (В отличие от изображения сигнал звукового сопровождения в телевидении обычно представляет собой ЧМ колебание несущей частоты). Как известно, ширина спектра такого сигнала определяется удвоенной максимальной частотой модулирующего сигнала fв. Поэтому, радиосигнал изображения в отечественном вещании занимает полосу 13 МГц. Для АМ сигнала характерно, что каждая из боковых частот содержит полную информацию о сигнале. Следовательно, без потери качества можно одну из них подавить, сузив, тем самым, и спектр сигнала. Обычно, частично (для сохранения несущей частоты) подавляется нижняя боковая частота (1,25 МГц), верхняя же передается полностью (рис. 6.10). Применительно к телевещанию, это позволяет увеличить число передаваемых каналов в отведенном диапазоне волн. Во всех случаях АМ fнес должна в несколько раз превышать максимальную частоту fв спектра модулирующего сигнала. Например, в отечественном стандарте наименьшая несущая частота соответствует I частотному каналу и равна 49,75 МГц.
При передаче изображений в телевещании используется 5 полос частот: в диапазоне метровых волн УКВ (I ... III) - размещается 12 каналов, в диапазоне дециметровых волн УКВ (IV и V) - размещается более 73 радиоканалов. Распределение телевизионных каналов по частотам приведено в табл. 6.3.
Таблица 6.3. Шкала распределения радиочастот в телевещании
| f, МГц | 48,5 ...66 | 76 ...100 | 174...230 | 470 ... 582 ... 960 | |
| Полосы частот | I | II | III | IV | V |
| Телевизионные каналы | I … XII |
Перспективные системы телевещания - телевидение высокой четкости используют полосу пропускания до 60 МГц, при этом частота кадров увеличена до 100 Гц. Соответственно, изменены и другие характеристики сигнала: Z = 1125, K = 16/9.
При передаче цветного изображения сигнал цветности должен встраиваться в спектр сигнала яркости.
6.2.2. Принципы кодирования цвета
 Термин «цвет» даже в научной литературе имеет несколько определений. Одним из наиболее удачных является формулировка Э. Шредингера, определившего цвет как «свойство спектрального состава излучения, общего излучениям, визуально неразличимым для человека». Подобное представление лежит в основе цветовых измерений (колориметрии) и теории цветного зрения. Особенности спектрального состава излучения изучал в XVIII в. И. Ньютон, определивший отдельные составляющие солнечного света. Основные положения теории цветового зрения были заложены М. Ломоносовым, экспериментально установившим, что все цвета могут быть получены путем сложения трех основных (первичных) цветов. Проведенные в XIX в. исследования Г. Гельмгольца и некоторых других ученых показали, что чувствительность S зрительных клеток к свету различных длин волн неодинакова (рис. 6.11). Многочисленные физиологические эксперименты привели к эмпирической зависимости:
Термин «цвет» даже в научной литературе имеет несколько определений. Одним из наиболее удачных является формулировка Э. Шредингера, определившего цвет как «свойство спектрального состава излучения, общего излучениям, визуально неразличимым для человека». Подобное представление лежит в основе цветовых измерений (колориметрии) и теории цветного зрения. Особенности спектрального состава излучения изучал в XVIII в. И. Ньютон, определивший отдельные составляющие солнечного света. Основные положения теории цветового зрения были заложены М. Ломоносовым, экспериментально установившим, что все цвета могут быть получены путем сложения трех основных (первичных) цветов. Проведенные в XIX в. исследования Г. Гельмгольца и некоторых других ученых показали, что чувствительность S зрительных клеток к свету различных длин волн неодинакова (рис. 6.11). Многочисленные физиологические эксперименты привели к эмпирической зависимости:
L = 0,59 G + 0,3 R + 0,11 B
где G, R и B - соответственно зеленая, красная и синяя составляющие спектра излучения. Яркость L, как и ранее, характеризует амплитуду черно-белого изображения. Поскольку представления о черном и белом весьма субъективны, возникла необходимость централизовано установить понятие «белого». Согласно принятому международному определению белым цветом называется цвет свечения абсолютно черного тела при температуре 6500 0С.
Формула, определяющая яркость как взвешенную сумму компонентов цветности, лежит в основе наиболее известной модели аддитивного цветового синтеза, применяемой в светоизлучающих системах (в том числе - цветном телевидении). Согласно аддитивной модели, известной также как цветовая система RGB, любой цвет получается наложением красного, зеленого и синего цветов спектра. Так, например, на экране монитора цвет и яркость каждой точки задается интенсивностью R, G и B составляющих, использующихся при управлении мощностью трехкомпонентной электронной пушки. Для наглядного представления цветовой системы RGB используется цветовой куб, где чистые цвета образуют вершины куба, а оттенки серого лежат на главной диагонали (рис. 6.12). Однако при всей наглядности этой схемы она имеет два существенных недостатка. Во первых, в системе RGB невозможно получить все цвета путем сложения основных составляющих. Во вторых, цветопередача является аппаратно-зависимой (например, от люминофора). В частности, экспериментально установлено, что методика RGB недействительна в сине-зеленой (450 ... 550 нм) области. Это связано с тем, что для имитации спектрального цвета в данной области требуется отрицательная красная составляющая (рис. 6.13). Действительно, согласно цветовому кубу справедливо равенство:
Голубой = Синий + Зеленый
На самом деле, эмпирически установлена справедливость другого выражения:
Синий + Зеленый = Голубой + Красный,
что и приводит к появлению отрицательной красной компоненты:
Голубой = Синий + Зеленый - Красный.
Ясно, что в природе не существует отрицательных составляющих цвета, и, следовательно, в модели аддитивного цветового синтеза голубой цвет может быть получен только искусственно.
Модель RGB используется для описания источников излучения. Если же объект освещается, он является приемником света, отражающим волны. Большинство предметов отражают либо солнечные лучи, либо лучи других источников освещения. Так, например, если объект кажется красным, это означает, что он отражает только длинные волны, поглощая все остальные. Для описания приемников света используется модель субтрактивного цветового синтеза, называемая также CMYK (Cyan - голубой, Magenta - пурпурный, Yellow - желтый и Black - черный). Модель CMYK позволяет получить на бумаге большинство необходимых цветов и широко используется в полиграфии и других системах печати. Важной особенностью такого подхода является возможность корректировать цвета изображений. Так, если изображение (фотография) получилось излишне синим, то необходимо увеличить желтую составляющую, поскольку желтый цвет поглощает синюю компоненту. Аналогично, зеленый цвет корректируется увеличением пурпурной составляющей. На практике, при технической реализации цветной печати изображение раскладывают на голубую, пурпурную и желтую составляющие, образующие на бумаге точечный растр. Затем для увеличения контрастности в растр добавляют чисто черную составляющую, которая оказывается гораздо насыщеннее, чем компонента, образованная сложением C, M и Y цветов. Белый цвет соответствует нулевым значениям всех составляющих C, M, Y и K, в отличие от RGB, где все компоненты соответствуют максимуму.
Система CMYK, также как и RGB является аппаратно-зависимой. Более того, цветовое изображение, полученное в CMYK (например, при печати на принтере) не совпадает с изображением в RGB (представленным на мониторе). Указанные недостатки не позволяют количественно оценивать цветовую информацию, содержащуюся в изображении. Следовательно, возникла необходимость разработки аппаратно-независимых моделей кодирования цвета.
 В последние 20 лет для цифровой обработки изображений широко используются аппаратно-независимые системы кодирования цвета. К наиболее известным относятся система HSV и ее варианты - HSI, HLS, а также телевизионная система YUV (разработанная для стандарта цветного телевидения PAL). Особенностью всех этих систем является раздельность кодирования сигналов яркости и цвета. Применительно к телевидению такой подход получил название компонентного кодирования.
В последние 20 лет для цифровой обработки изображений широко используются аппаратно-независимые системы кодирования цвета. К наиболее известным относятся система HSV и ее варианты - HSI, HLS, а также телевизионная система YUV (разработанная для стандарта цветного телевидения PAL). Особенностью всех этих систем является раздельность кодирования сигналов яркости и цвета. Применительно к телевидению такой подход получил название компонентного кодирования.
Принцип HSV (HSI) очень напоминает способ, используемый художниками для получения нужных цветов - смешивание белой, черной и серой красок с чистыми красками для получения различных тонов и оттенков (tine, shade и tone). При этом, цвет задается не смесью трех основных составляющих как, например, в системе RGB, а с помощью трех независимых величин - цветового тона (hue), насыщенности (saturation) и интенсивности (value, intensity). В качестве геометрической модели используется конус, получаемый как сглаженная проекция цветового куба RGB вдоль его главной диагонали «черный-белый» (рис.6.14). В соответствии с этой моделью цветовой оттенок (тон) H и насыщенность S кодируются как угловая и радиальная характеристики цветового круга - основания конуса. Тон описывается углом цветовой стрелки (например, красный соответствует 00), насыщенность представляется как величина смещения вдоль радиуса круга. Она возрастает по величине от 0 к 1 (или от 0 до 100%) при перемещении от центра круга к его границе соответственно. Насыщенность характеризует насколько тусклым или «сочным» является цвет. Чем больше данный цвет разбавлен белым (чем ближе к центру круга), тем он менее насыщен. Естественные (реальные) цвета имеют низкую насыщенность.
 Величина интенсивности (или цвета) V указывает яркость цвета. Она также меняется от 0 к 1, но по оси OV и не связана с цветовым кругом. По этой оси располагаются серые цвета, так, например, для белого цвета имеем: S = 0, V = 1. Следовательно, добавление белого в любой цвет уменьшает S, а добавление черного уменьшает V. В системе HSV при S = 0, Н не имеет смысла. Действительно, как следует из рис. 6.14 эта точка соответствует вершине конуса.
Величина интенсивности (или цвета) V указывает яркость цвета. Она также меняется от 0 к 1, но по оси OV и не связана с цветовым кругом. По этой оси располагаются серые цвета, так, например, для белого цвета имеем: S = 0, V = 1. Следовательно, добавление белого в любой цвет уменьшает S, а добавление черного уменьшает V. В системе HSV при S = 0, Н не имеет смысла. Действительно, как следует из рис. 6.14 эта точка соответствует вершине конуса.
Другая цветовая система HLS или HSB (буквы H и S также обозначают тон и насыщенность, L и В - яркость) использует то же координатное пространство, но представленное в виде двух пирамид, соединенных основаниями (рис. 6.15). Эта фигура в большей степени соответствует диагональной проекции куба. В модели HLS, также как и в HSV черный и белый цвета образуются при любых значениях H и разных L и S, например, насыщенный черный при L = 0, S = 1, а белый - при L = 1 и S = 0. Голубые цвета соответствуют значению H = 1800. Так, грязно-голубому цвету (смеси серого с голубым) отвечает комбинация: L = 0,5, H = 1800 и S = 0, цвету морской волны: L = 0,5, H = 1800 , но S = 1, и, наконец, небесно-голубому: H = 1800 и L и S = 1.
Поскольку в основе геометрических построений в системе HSV и ей подобных лежит модель RGB, то и пересчет цветов в обе стороны достаточно прост.
 Наличие большого количества разнообразных моделей, применяемых в различных задачах обработки цветных изображений, привело, в конце концов, к необходимости создания единого описания цвета. В качестве всемирного стандарта для определения цвета в настоящее время утвержден цветовой график МКО (CIE), сочетающий абстрактный характер HSV и практичность RGB и CMYK. Этот график, предложенный еще в 1931 г. охватывает все цвета, которые способен видеть человеческий глаз (рис. 6.16). График МКО строится как функция двух переменных х и y, представляющих собой некоторые гипотетические (несуществующие в природе) основные цвета. Тогда, на линии, которая ограничивает цветовое пространство МКО, будут находиться все чистые цвета видимого света. Их можно получить путем смешения источников x и y. (Например, чистый красный с длиной волны 700 нм понимается как результат сложения 70% x и 25% y). Все цвета, лежащие внутри графика и на его границе являются физически реализуемыми.
Наличие большого количества разнообразных моделей, применяемых в различных задачах обработки цветных изображений, привело, в конце концов, к необходимости создания единого описания цвета. В качестве всемирного стандарта для определения цвета в настоящее время утвержден цветовой график МКО (CIE), сочетающий абстрактный характер HSV и практичность RGB и CMYK. Этот график, предложенный еще в 1931 г. охватывает все цвета, которые способен видеть человеческий глаз (рис. 6.16). График МКО строится как функция двух переменных х и y, представляющих собой некоторые гипотетические (несуществующие в природе) основные цвета. Тогда, на линии, которая ограничивает цветовое пространство МКО, будут находиться все чистые цвета видимого света. Их можно получить путем смешения источников x и y. (Например, чистый красный с длиной волны 700 нм понимается как результат сложения 70% x и 25% y). Все цвета, лежащие внутри графика и на его границе являются физически реализуемыми.
Цветовой охват устройства (телекамеры, монитора, сканера, принтера, фотопленки и пр.) характеризует его способность к отображению цветовой гаммы всего цветового диапазона. Для любого устройства он находится внутри пространства МКО. Самый большой цветовой охват имеет фотопленка.
При передаче цветных изображений в большинстве СТЗ применяются устройства аддитивного цветового синтеза, основанные на модели RGB. (К ним относятся и телекамеры и мониторы). Сигнал яркости Y передается непосредственно, а информация о цвете кодируется двухкомпонентным вектором цветности (рис. 6.17). В этой системе, получившей название YUV, к уже известной формуле расчета яркости Y добавляются еще две, определяющие проекции U и V вектора цветности:
Y = 0,59G + 0,30R + 0,11B, U = R - Y, V = B - Y.
 Длина вектора цветности находится через амплитуды его проекций U и V; она кодирует насыщенность цвета. Фазовый сдвиг между проекциями описывает цветовой тон. В телевизионной технике эти вектора обычно нормируют, и круг превращается в эллипс: U = (R-Y)/1,44 и V = (B-Y)/2,03. На основе системы YUV построены и другие известные модели. Примером может служить система цифрового цветного телевидения YCbCr. (Здесь цветоразностные сигналы Cr и Cb строятся из R-Y и B-Y соответственно).
Длина вектора цветности находится через амплитуды его проекций U и V; она кодирует насыщенность цвета. Фазовый сдвиг между проекциями описывает цветовой тон. В телевизионной технике эти вектора обычно нормируют, и круг превращается в эллипс: U = (R-Y)/1,44 и V = (B-Y)/2,03. На основе системы YUV построены и другие известные модели. Примером может служить система цифрового цветного телевидения YCbCr. (Здесь цветоразностные сигналы Cr и Cb строятся из R-Y и B-Y соответственно).
Рассмотрим формирование цветного сигнала в телевизионной камере. Обычно применяются три развертывающих луча, формирующих первичные сигналы изображения ER, EG, EB соответствующие красной, зеленой и синей составляющим цвета передаваемого объекта. Первичные сигналы широкополосные, однако, ни один из них не несет яркостной информации об объекте. (Иногда вместо термина «яркость» используется понятия освещенности Á). Поэтому в системе цветного телевидения из трех первичных цветов формируется четвертый - сигнал яркости EY, для чего первичные сигналы сначала балансируются, а затем матрицируются. Сущность данной процедуры, учитывающей спектральную чувствительность глаза, описывается уже известной зависимостью: EY = 0,30 ER + 0,59 EG + 0,11 EB, где ER = EG = EB. Этот сигнал передается непрерывно на каждой строке развертки во всей полосе частот видеосигнала ~ 6 МГц и позволяет воспроизводить черно-белое изображение на экранах черно-белых и цветных приемников.
Наличие сигнала яркости EY освобождает от необходимости передачи всех трех первичных сигналов изображения. Обычно передаются два из них ER и EB, а «зеленый» восстанавливается по формуле:
EG = (EY - 0,30 ER - 0,11 EB)/0,59
Важной особенностью зрения является зависимость пространственной разрешающей способности глаза от длины волны - она понижена в области красных и синих цветов. Следствием этого является меньшая чувствительность глаза к пространственным изменениям оттенков цвета, чем к изменениям яркости, что позволяет передаваться цветовую информацию с меньшим разрешением. Таким образом, трехкомпонентная модель цветового зрения распространяется только на относительно крупные объекты. Цвет объектов средних размеров является смесью двух цветов: оранжевого и голубого, а мелкие и вовсе различаются только по яркости, т.е. кажутся черно-белыми. Указанные обстоятельства позволяют сократить полосу частот сигнала цветности до 1 ... 1,5 МГц. Поскольку, полная информация о яркости объекта содержится в сигнале EY, из сигналов ER и EB ее можно исключить, и передать эти компоненты в виде цветоразностных сигналов ER-Y и EB-Y. При таком подходе достигается двойной выигрыш. Во-первых, обеспечивается достоверность воспроизведения цветов, т.к. в реальных объектах значительную часть составляют неокрашенные и слабоокрашенные участки. Во вторых, уменьшается амплитуда передаваемых сигналов, что увеличивает энергетическую эффективность передачи. Таким образом, исходные RGB-видеосигналы с телекамеры перед передачей преобразуют в сигнал яркости Y и два цветоразностных сигнала U = ER-Y и V = EB-Y (рис. 6.17). Следовательно, полный цветной телевизионный видеосигнал представляет собой композицию трех сигналов Y, U, V и служебных импульсов. Такой сигнал получил название композитного. При приеме в цветном телевизоре осуществляется обратный процесс восстановления (декодирования): R = Y+U (или ER = EY+ER-Y), B =Y+V (или EB = EY+EB-Y) и, наконец, G = Y - 0,509U - 0,194V (или EG = EY - 0,509 ER-Y - 0,194 EB-Y).
В настоящее время в эксплуатации находятся три совместимых системы цветного телевидения:
· американская NTSC (National Television System Color) - первая система цветного телевидения 1953 г.;
· германская PAL (Phase Alternation Line - строки с переменной фазой) - разработана фирмой Telefunken в 1963 г;
· французская SECAM (Sequentiel couleur a memoire - последовательная цветная с памятью) - предложена А. Франсом в 1954 г.
В каждой из этих систем используется группа из трех составляющих: сигнала яркости и двух цветоразностных. Сигнал яркости частотно уплотняется цветоразностными сигналами, причем спектры цветности переносятся на поднесущую частоту в области высокочастотной части спектра. (Чтобы не возникало путаницы - несущую частоту цветности, в отличие от несущей яркости, называют поднесущей). Методы кодирования и передачи сигналов цветности в этих системах существенно различаются.
В табл. 6.4 представлены основные технические характеристики систем цветного телевидения.
Таблица 6.4. Системы цветного телевидения
| Тип системы | NTSC | PAL | SECAM | ||||
| Вертикальная частота развертки, Гц | 60 | 50 | 50 | ||||
| Горизонтальная частота развертки, кГц | 15374 | 15625 | 15625 | ||||
| Число строк в кадре | 525 | 625 | 625 | ||||
| Число видимых (активных) строк в кадре | 480 | 576 | 576 | ||||
| Тип модуляции цветовой поднесущей | АМ | АМ | ЧМ | ||||
| Полоса видеосигнала, МГц | 4,2 | 5 для B/G, 5,5 для I, 6 для D/K | |||||
| Частота цветовой поднесущей, МГц | 3,60 | 4,43 | 4,41 по U, 4,25 по V | ||||
| Разнос несущих видео/звук, МГц | 4,5 | 5,5 для B/G, 6 для I, 6,5 для D/K | |||||
| Полная ширина сигнала, МГц | 6 | 7 для B/G, 8 для I/D/K | |||||
Система NTSC принята для вещания в США, Канаде, большинстве стран Центральной и Южной Америки, Японии, Южной Корее и Тайване. Именно при ее создании были выработаны основные принципы передачи цвета в телевидении. В NTSC каждая телевизионная строка содержит составляющую яркости Y и два сигнала цветности EI = 0,737U - 0,268V, EQ=0,478U+0,413V. Здесь переход от осей цветового кодирования U, V к осям I, Q обусловлен необходимостью сужения ширины полос цветовых поднесущих до ± 0.5 МГц (в NTSC используется самая узкая полоса видеосигнала). Цветоразностные сигналы передаются путем АМ поднесущих на одной и той же частоте, но с фазовым сдвигом на 90°. Последнее обстоятельство является принципиально важным для разделения сигналов при приеме. Однако из-за неизбежных нелинейных искажений в канале передачи поднесущие оказываются промодулированными сигналом яркости как по амплитуде, так и по фазе. В результате в зависимости от яркости участков изображений изменяются их цветовой тон. Например, человеческие лица на изображении окрашиваются в красноватый цвет в тенях и в зеленоватый - на освещенных участках. Это и является основным недостатком системы NTSC.
В системе PAL используется аналогичная АМ цветоразностных сигналов EU=0,877U и EV=0,493V с фазовым сдвигом на 90°, но через строку дополнительно производится изменение знака амплитуды составляющей EU. В результате при восстановлении в декодере цветовые составляющие надежно разделяются сложением/вычитанием сигналов цветности последовательных телевизионных строк, и паразитная яркостная модуляция приводит лишь к некоторому изменению цветовой насыщенности. Усреднение сигналов двух строк обеспечивает также повышение отношения сигнал/шум, но приводит к снижению вертикальной четкости в два раза. Впрочем, частично это компенсируется увеличением числа телевизионных строк разложения. Система PAL принята в большинстве стран Западной Европы, Африки и Азии, включая Китай, Австралию и Новую Зеландию.
Система SECAM первоначально была предложена во Франции еще в 1954 г., но регулярное вещание после длительных доработок было начато только в 1967 одновременно во Франции и СССР. В настоящее время она принята также в Восточной Европе, Монако, Люксембурге, Иране, Ираке и некоторых других странах. Основная особенность системы - поочередная, через строку, передача цветоразностных сигналов (DR= 1,9U, DB=1,5V) с дальнейшим восстановлением в декодере путем повторения строк. При этом в отличие от PAL и NTSC используется ЧМ поднесущих. В результате цветовой тон и насыщенность не зависят от освещенности, но на резких переходах яркости возникают цветовые окантовки. Обычно после ярких участков изображения окантовка имеет синий цвет, а после темных - желтый. Кроме того, как и в системе PAL, цветовая четкость по вертикали снижена вдвое.
Во всех рассмотренных системах к цветному видеосигналу добавляется сигнал звукового сопровождения, образуя так называемый низкочастотный телевизионный сигнал. Этот сигнал передается через эфир путем модуляции несущей частоты одного из 5 допустимых частотных диапазонов (табл. 6.3). И здесь даже в рамках одной системы существуют различия, связанные с конкретной шириной спектра видеосигнала и его разносом со звуковой частью, полярностью амплитудной модуляции радиоканала изображения и типом модуляции радиоканала звука. В табл. 6.5 представлены основные параметры телевизионных стандартов.
Таблица 6.5. Телевизионные стандарты стран мира
| Стандарт | Число строк, Z | Ширина канала, МГц | Полоса видео, МГц | Разнос видео/ звук, МГц | Полярность модуляции видео | Тип модуляции несущей звука |
| A | 405 | 5 | 3 | 3.5 | + | AM |
| B | 625 | 7 | 5 | 5.5 | - | ЧМ |
| C | 625 | 7 | 5 | 5.5 | + | AM |
| D | 625 | 8 | 6 | 6.5 | - | ЧМ |
| E | 819 | 14 | 10 | 11.15 | + | AM |
| F | 819 | 7 | 5 | 5.5 | + | AM |
| G | 625 | 8 | 5 | 5.5 | - | ЧМ |
| H | 625 | 8 | 5 | 5.5 | - | ЧМ |
| I | 625 | 8 | 5.5 | 6 | - | ЧМ |
| K | 625 | 8 | 6 | 6.5 | - | ЧМ |
| L | 625 | 8 | 6 | 6.5 | + | AM |
| M | 525 | 6 | 4.2 | 4.5 | - | ЧМ |
| N | 625 | 6 | 4.2 | 4.5 | - | ЧМ |
В России принят стандарт SECAM D/K (первая буква относится к диапазону метровых волн, вторая - дециметровых), во Франции - SECAM E/L, Иране - SECAM B, Германии - PAL B/G, Англии - PAL A/I, Бразилии - PAL M/M, Китае - PAL D/K, в США, Японии и Тайване - NTSC M/M. Характерные различия модификаций SECAM связаны с особенностями модуляции несущей частоты, как по видео, так и по звуку, а также частотой разноса звука от видео. Сами же низкочастотные телевизионные сигналы одинаковы. В то же время с точки зрения модуляции радиосигналов отличий между PAL D/K и SECAM D/K нет. Это позволяет использовать телевизионный тюнер, настроенный на PAL D/K, для выделения отечественного SECAM из высокочастотного сигнала. Очевидно, что полученный при этом низкочастотный сигнал все же необходимо подавать именно на SECAM-декодер.
В системе SECAM D/K сигнал яркости занимает всю полосу частот - 6 МГц. Информация о цвете передается внутри этого спектра, путем введения в него поднесущих частот, ЧМ цветоразностными сигналами (рис. 6.18). Поднесущие частоты f0R = 4,4 МГц и f0B = 4,25 МГц, на которой передаются цветоразностные сигналы DR и DB, расположены внутри полосы сигнала яркости, т.е. внутри спектра черно-белого сигнала. (Возможность такого уплотнения спектра обусловлена его дискретностью и, следовательно, наличием свободных промежутков между соседними гармониками). ЧМ поднесущие передаются поочередно через строку, т.е. в пределах каждой строки развертки передается сигнал яркости и только одна из поднесущих foR или foB. Это вдвое сужает участок спектра сигнала яркости, уплотняемого сигналами цветности, что существенно снижает уровень помех. Однако в одной строке будет отсутствовать красный цвет, а в другой - синий. Чтобы этого не происходило, на приемной стороне задерживают цветную строку с помощью пьезокерамической линии задержки.
ЧМ, с максимальной девиацией ± 50 кГц, несущая частота радиосигнала звукового сопровождения выбирается на 6,5 МГц выше несущей частоты радиосигнала изображения. Радиосигнал звука занимает полосу частот 0,25 МГц и обеспечивает передачу звуковых частот 30 ... 15000 Гц.
Качество получения телевизионного сигнала в современных СТЗ непрерывно совершенствуется. Разработки ведутся в направлении расширения полосы передаваемых частот, увеличения частоты передачи полукадров с 50 до 100 (с использованием цифровой памяти), расширения уровня черного сигнала, а также применения цифровых методов коррекции.
6.3. Датчики изображений
В настоящее время промышленно выпускается большая гамма датчиков изображений для самых разных целей (производственных, медицинских, военных и др.). Независимо от назначения и принципа действия все они содержат оптоэлектронный преобразователь, служащий для преобразования сфокусированного оптического изображения в электрический видеосигнал. Это изображение формируется в ЧЭ преобразователя, который изменяет свое состояние под действием излучения объекта. Если это излучение лежит в диапазоне видимых волн (l = 0,38 … 0,78 мкм), датчик относится к классу телекамер, если в диапазоне 0,78 … 1000 мкм - к классу ИК камер. Большинство материалов непрозрачны в видимом и ближнем ИК диапазонах спектра, однако, хорошо пропускают СВЧ излучение. Эта особенность используется при разработке разнообразных тепловизионных камер, функционирующих в широком диапазоне длин волн. Так, для традиционных тепловизоров характерно применение волн среднего ИК диапазона (2 … 10 мкм), для которых ткани организма слабопрозрачны. Системы глубокого проникания работают в СВЧ диапазоне (l = 1 … 100 мм), обеспечивая непосредственное изучение теплового режима органов тела. Изменением длины волны излучения можно регулировать глубину зондирования от 200 … 300 мм при l = 100мм, до 1 … 2 мм при l = 1 мм. При дальнейшем увеличении длины волны разрешающая способность системы падает.
В СТЗ обычно используются телекамеры. Выпускаемые промышленно телекамеры по своим эксплуатационным параметрам разделяют на три класса: «Brand name» (например, японские «Sony», «Panasonic», «Sharp»), «No name», к которым относятся большинство камер, выполненных в виде одной или двух печатных плат, установленных в корпус. Третий класс образуют специализированные телекамеры, разработанные фирмами-лабоРаториями (например, «Watec», Япония, «ЭВС», Россия). Благодаря наличию специалистов длительное время работающих в данной области, телекамеры таких фирм не уступают, а иногда и превосходят системы «Brand name». В таких лабораториях ведутся разработки новых перспективных СТЗ. Так, в одной из них - Human Interface Technology (США) создана камера нового типа - виртуальный глазной дисплей (Virtual Retinal Display - VRD). Это устройство, имеющее вид очков с угловым полем зрения каждого 1200, содержит три миниатюрных лазера, действующих в красной, зеленой и синей областях спектра. Развертка с частотой кадровой развертки 60 Гц осуществляется прямо на сетчатку глаза.
Датчики СТЗ классифицируются по трем основным признакам.
- По размерности: точечные (фотоэлементы), одномерные (линейки) и двумерные (матрицы).
2. По структуре преобразователя «свет-сигнал»: вакуумные (электронно-лучевые трубки) и твердотельные.
3. По рабочему диапазону длин волн: видимого спектра, инфракрасные (в том числе - тепловые) и специальные.
К основным характеристикам телекамер относятся:
· разрешающая способность (апертурная характеристика);
· чувствительность;
· спектральная характеристика.
Разрешающая способность (разрешение) n характеризует свойство телекамеры к воспроизведению мелких деталей. Она показывает, насколько четким получается изображение объекта. Обычно, разрешение измеряется в телевизионных линиях - твл - вертикальных полосах, расположенных по экрану телекамеры. На практике n определяется с помощью разнообразных тестовых таблиц, отдельно для черно-белого и цветного изображений. Например, тестовая испытательная таблица ИТМ-05-98 предназначена для визуальной оценки разрешающей способности по цвету по горизонтали и вертикали на соответствие международным нормам и отечественным стандартам. Она позволяет анализировать аналоговое изображение в системах PAL, SECAM, NTSC, RGB, компонентный сигнал Y, R-Y, B-Y, а также цифровые изображения в форматах 4:2:2, 4:2:0, 4:1:1 и т.п. Для современных телекамер n = 380 ... 600 линий и различается по длине и ширине экрана. В направлении кадровой развертки она ограничена количеством строк разложения. Разрешающая способность зависит как от освещенности, понижаясь с уменьшением последней ниже определенного предела, так и от материала мишени (рис. 6.19).
 Как уже отмечалось, разрешающая способность глаза (острота зрения) весьма высока и существенно зависит от длины волны (скотопическое и фотопическое зрение). Так, например, в области максимальной чувствительности глаз различает более 600 оттенков серого, при остроте зрения ~ 1'. Что касается хроматической разрешающей способности (разрешение по цвету), то она значительно ниже. Например, применительно к полосам красно-зеленых тонов она в 2,5 раза, а сине-зеленых в 5 раз хуже, чем для черно-белых.
Как уже отмечалось, разрешающая способность глаза (острота зрения) весьма высока и существенно зависит от длины волны (скотопическое и фотопическое зрение). Так, например, в области максимальной чувствительности глаз различает более 600 оттенков серого, при остроте зрения ~ 1'. Что касается хроматической разрешающей способности (разрешение по цвету), то она значительно ниже. Например, применительно к полосам красно-зеленых тонов она в 2,5 раза, а сине-зеленых в 5 раз хуже, чем для черно-белых.
 Для бытового телевизионного вещания удовлетворительное изображение получается при 120 ... 150 строках для крупных планов и 250 ... 300 для мелких. Для лучших моделей эти значения выше, однако, существенно различаясь для черно-белого и цветного изображений. Так, для телевизионной трубки (кинескопа) марки 54CTV670i-5 разрешение в канале яркости составляет 420 твл, а в канале цветности - всего 60.
Для бытового телевизионного вещания удовлетворительное изображение получается при 120 ... 150 строках для крупных планов и 250 ... 300 для мелких. Для лучших моделей эти значения выше, однако, существенно различаясь для черно-белого и цветного изображений. Так, для телевизионной трубки (кинескопа) марки 54CTV670i-5 разрешение в канале яркости составляет 420 твл, а в канале цветности - всего 60.
Чувствительность телекамеры S (рис. 6.20) характеризуется величиной минимальной освещенности Á, при которой обеспечивается заданное качество изображения (разрешающая способность или число передаваемых градаций яркости). Заданное качество должно достигаться в достаточно широком динамическом диапазоне освещенностей D = Ámax/Ámin. Телекамера считается хорошей, если этот диапазон составляет 2 … 3 порядка.
Характеристики минимальной освещенности для различных камер выбираются исходя из условий конкретной съемки (табл. 6.6).
Таблица 6.6. Уровни минимальной освещенности телекамер
| Обстановка | Освещенность Á, лк |
| Сумерки | 4 |
| Ясная ночь, полная луна | 0,2 |
| Ясная ночь, неполная луна | 0,02 |
| Ночь, луна в облаках | 0,007 |
| Безлунная ночь | менее 0,002 |
Отечественным стандартом установлено, что ток сигнала в режиме максимальной чувствительности Smax не должен быть меньше 0,1 мкА при освещенности 1 лк.
 Для цветных телекамер характерна существенно меньшая чувствительность (в 5 …10 раз) и разрешающая способность (в 1,5 … 2 раза) по сравнению с черно-белыми камерами. Однако в высокопрофессиональных цветных телекамерах иногда отдельно указывается цветовая чувствительность, определяемая в области максимальной чувствительности. Она определяется как изменение компоненты сигнала цветности при изменении длины волны цвета. У человека эта характеристика весьма высока - в сине-зеленой части спектре глаз фиксирует изменение длины волны в пределах 1 нм.
Для цветных телекамер характерна существенно меньшая чувствительность (в 5 …10 раз) и разрешающая способность (в 1,5 … 2 раза) по сравнению с черно-белыми камерами. Однако в высокопрофессиональных цветных телекамерах иногда отдельно указывается цветовая чувствительность, определяемая в области максимальной чувствительности. Она определяется как изменение компоненты сигнала цветности при изменении длины волны цвета. У человека эта характеристика весьма высока - в сине-зеленой части спектре глаз фиксирует изменение длины волны в пределах 1 нм.
Телекамеры высокой чувствительности называемые «ночными» обладают чувствительностью в диапазоне 0,005 …0,00004 лк.
Спектральная характеристика телекамеры (рис. 6.21) определяется материалом ее мишени. Промышленно выпускаются телекамеры видимого света, так и рентгеновского, УФ и ИК излучений.
Фирма Sony в 1998 г. разработала портативную камеру специального назначения NightShot, работающую в инфракрасном диапазоне и предназначенную для съемок в кромешной темноте (looking throw camera). Телекамеры подобного типа, оснащенные специальными фильтрами, отсекающими часть диапазона видимого спектра, после известных событий 11 сентября установлены в таможенных терминалах США.
Рассмотрение принципов построения телевизионных камер начнем с вакуумных передающих трубок. Вакуумные электронно-лучевые трубки (ЭЛТ) относятся к преобразователям изображения сканирующего типа (в отличие от несканирующих, типа жидкокристаллических, магнитооптических и люминофорных). По способу съема сигнала и типу мишени их принято разделять на следующие классы: диссекторы; суперортиконы (изоконы); видиконы (в том числе плюмбиконы и кремниконы), а также производные от них супервидиконы (секоны) и пировидиконы.
Рассмотрим некоторые популярные вакуумные датчики СТЗ, основанные на различном типе фотоэффекта. К ним, в первую очередь, относятся диссекторы, суперортиконы и видиконы.
Диссектор, схема которого разработана американцем Ф. Фарнсуортом в 1931 г., обладает наивысшей среди всех ЭЛТ разрешающей способностью и чувствительностью. В так называемом режиме «счета электронов» возможна регистрация оптических сигналов от объектов, освещенность Á которых не превышает 10-7 лк. (Для сравнения:1 лк приблизительно соответствует освещенности от свечи на расстоянии 1 м). Принцип действия диссектора основан на внешнем фотоэффекте. Его важной особенностью является отсутствие накопления зарядов на фотокатоде, что приводит, в свою очередь, к отсутствию «смазывания» изображений движущихся объектов. Благодаря этому диссектор называется «трубкой мгновенного действия». Другое его преимущество связано с возможностью формирования различных траекторий развертки. К недостаткам диссектора относятся сравнительно большие габариты.
Схема суперортикона была предложена в 1938 г. советским физиком Г. Браузе. Прибор представляет собой высокочувствительную ЭЛТ с несколькими каскадами усиления и работает по принципу накопления зарядов. Изображение переносится с фотокатода на двухстороннюю мишень, считывается с нее медленными электронами и усиливается фотоэлектронным умножителем. Коэффициент усиления суперортикона достигает ~104, что обеспечивает отношение сигнал/шум около 100 при освещенности фотокатода ~ 0,1 лк. Суперортиконы, также как и диссекторы, способны работать практически в полной темноте. Их основные недостатки связаны со значительными размерами, малой контрастной чувствительностью и сравнительно невысоким динамическим диапазоном. В настоящее время суперортиконы используются во многих телевизионных системах.
Самый распространенный телевизионный датчик видикон представляет собой малогабаритную ЭЛТ с накоплением заряда, действие которой основано на внутреннем фотоэффекте. Проект видикона был разработан в 1925 г. А. Чернышевым, первая промышленный прибор изготовлен в 1950 г . Сейчас выпускаются несколько типов видиконов, отличающихся характеристиками мишени, системы отклонения луча и др. Известные модели видикона - плюмбикон и кремникон, отличаются надежностью, высокими фотоэлектрическими параметрами, малыми габаритами и массой, что позволяет их широко использовать в системах цветного телевидения. Лучшие из видиконов обеспечивают разрешение до 10000 линий. К недостаткам видиконов по сравнению с суперортиконами, относятся меньшая чувствительность и большая инерционность.
Видиконы дали рождение другим телевизионным трубкам супервидикону и пировидикону. Первые появились в 60-х годах ХХ века и представляли собой своего рода гибрид видикона с суперотиконом. Они также содержат секцию переноса заряда, что позволяет обеспечить коэффициент усиления свыше 103, уступая в этом только суперортикону, но превосходя его по массогабаритным показателям. Пировидиконы используются в системах тепловидения.
Некоторые параметры рассмотренных вакуумных трубок приведены в табл. 6.7.
Таблица 6.7. Сравнительная характеристика некоторых типов вакуумных телекамер
| Тип | Принцип действия | l, мкм | n, твл | Отношение сигнал/шум | Á, лк min/max | Æ, мм (m, кг) |
| диссектор | внешний фотоэффект | 0,4 ... 0,8 | 125 ... 3500 | 18 ... 50 | 5 10-6/5 | 25 |
| суперортикон | внешний фотоэффект + каскадное усиление | 0,25 ...1,2 | 500 ... 1000 | 3 ... 80 | 2 10-3/100 | 80 (0,5) |
| видикон | внутренний фотоэффект | 0,1 ... 2,5 | 400 ... 800 | 2 ... 50 | 0,1/1000 | 13 (0,02) |
6.3.1. Видикон
Рассмотрим самую распространенную вакуумную телекамеру - видикон (В). В представляет собой вакуумную колбу, в которой находится фоточувствительная мишень ФМ, прожектор и электронно-оптическая система развертки луча (рис. 6.22). ФМ нанесена на торцевую поверхность оболочки В и содержит сигнальную пластину СП (прозрачный электрод, имеющий вывод наружу). Каждый элемент ФМ, материалом которой служат тонкие - около 5 мкм слои полупроводника (аморфного селена, трёхсернистой сурьмы, окиси свинца и ряда других, включая германий и кремний) изменяет свое сопротивление при внутреннем фотоэффекте. От толщины и свойств материала фотопроводника зависят чувствительность, спектральная характеристика и инерционные параметры прибора.
 Работает В следующим образом. Развертывающий электронный луч термокатода ТК, ускоряясь анодами А1 и А2, проходит через сеточный анод А3 и достигает поверхности ФМ, в результате чего на внутренней поверхности фотопроводника в некоторой его точке создается потенциал, близкий к потенциалу катода, а между противоположными поверхностями фотопроводника устанавливается разность потенциалов. Далее луч (толщина которого составляет ~ 30 мкм) уходит с этой точки ФМ и освещает следующую точку и т.д. Если на ФМ проецируется изображение, то проводимость различно освещенных участков слоя будет неодинаковой - возникает рельеф проводимости, соответствующий рельефу яркости объекта. В течение некоторого промежутка времени t, определяющего инерционность В, каждая из элементарных емкостей (точек экрана) разряжается до определенного значения, зависящего от ее освещенности - возникает потенциальный рельеф. Электронный луч при развертке доводит поверхность всех участков ФМ до одинакового потенциала. При этом, выравнивая потенциалы, луч оставляет на более освещенных участках слоя большее количество электронов. Таким образом, ток дозарядки элементарных емкостей несет в себе информацию о распределении освещенности на ФМ. Протекая, через нагрузочное сопротивление Rн, он создает напряжение видеосигнала. Формирование луча осуществляется прожектором, включающим ТК (эмиттер электронов), модулятор М, управляющий величиной тока (вплоть до запирания прожектора) и двух анодов А1 и А2. Анод А3 представляет собой мелкоструктурную сетку, находящуюся под напряжением, в 1,5 …1,7 раза превышающим напряжения анодов прожектора, что обеспечивает перпендикулярный подход электронов луча по всей поверхности ФМ. Развертка луча осуществляется фокусирующе-отклоняющей системой ФОС, состоящей из системы катушек ФК, КК (корректирующей) и ОК. В зависимости от способа фокусировки и отклонения промышленно выпускаются В с магнитным и электростатическим управлением лучом. (Примерами являются отечественные модели ЛИ 427 и ЛИ 420 соответственно). В робототехнике перспективно использование электростатических ФОС, позволяющих увеличивать скорость развертки при сохранении высокой линейности отклонения луча и реализовывать нестандартные виды развертки (спиральную, радиальную).
Работает В следующим образом. Развертывающий электронный луч термокатода ТК, ускоряясь анодами А1 и А2, проходит через сеточный анод А3 и достигает поверхности ФМ, в результате чего на внутренней поверхности фотопроводника в некоторой его точке создается потенциал, близкий к потенциалу катода, а между противоположными поверхностями фотопроводника устанавливается разность потенциалов. Далее луч (толщина которого составляет ~ 30 мкм) уходит с этой точки ФМ и освещает следующую точку и т.д. Если на ФМ проецируется изображение, то проводимость различно освещенных участков слоя будет неодинаковой - возникает рельеф проводимости, соответствующий рельефу яркости объекта. В течение некоторого промежутка времени t, определяющего инерционность В, каждая из элементарных емкостей (точек экрана) разряжается до определенного значения, зависящего от ее освещенности - возникает потенциальный рельеф. Электронный луч при развертке доводит поверхность всех участков ФМ до одинакового потенциала. При этом, выравнивая потенциалы, луч оставляет на более освещенных участках слоя большее количество электронов. Таким образом, ток дозарядки элементарных емкостей несет в себе информацию о распределении освещенности на ФМ. Протекая, через нагрузочное сопротивление Rн, он создает напряжение видеосигнала. Формирование луча осуществляется прожектором, включающим ТК (эмиттер электронов), модулятор М, управляющий величиной тока (вплоть до запирания прожектора) и двух анодов А1 и А2. Анод А3 представляет собой мелкоструктурную сетку, находящуюся под напряжением, в 1,5 …1,7 раза превышающим напряжения анодов прожектора, что обеспечивает перпендикулярный подход электронов луча по всей поверхности ФМ. Развертка луча осуществляется фокусирующе-отклоняющей системой ФОС, состоящей из системы катушек ФК, КК (корректирующей) и ОК. В зависимости от способа фокусировки и отклонения промышленно выпускаются В с магнитным и электростатическим управлением лучом. (Примерами являются отечественные модели ЛИ 427 и ЛИ 420 соответственно). В робототехнике перспективно использование электростатических ФОС, позволяющих увеличивать скорость развертки при сохранении высокой линейности отклонения луча и реализовывать нестандартные виды развертки (спиральную, радиальную).
Характеристики некоторых моделей В представлены в табл. 6.8. Обозначено: Áном и Ámax номинальная и максимальная освещенности, Iс - ток сигнала, Dl - рабочий диапазон длин волн. Под инерционностью понимается уровень остаточного сигнала Iс ост по истечении 40 мс после прекращения освещения мишени. (Например, для ЛИ-421 это означает, что Iс ост = 0,04 мкА).
Таблица 6.8. Примеры промышленных В
| Модель | Тип мишени | Áном, лк (Ámax, лк) | Инерционность, % через 40 мс | Iс, мкА | Dl, нм | Тип ФОС | Æ, мм |
| ЛИ-421 | Sb2S3 | 1 (1000) | 40 | 0,1 | 400 ... 750 | Ф-Н, О-Н | 26 |
| ЛИ-426 | Sb2S3 | 1 (10000) | 45 | 0,1 | 400 ... 750 | Ф-Е, О-Н | 26 |
| ЛИ-439 | Si | 1 (1,2) | 8 | 0,3 | 400 ... 1100 | Ф-Н, О-Н | 26 |
| ЛИ-465 | CdSe | 1 (2) | 18 | 0,08 | 400 ... 800 | Ф-Е, О-Е | 13,6 |
| ВКБ-102 | 0,7 | Разрешение по горизонтали - 600 твл | 20´40´100 |
Примечания.
1. В типе ФОС обозначено:
Е - электрическая напряженность поля, Н - магнитная. Например, Ф-Е - фокусировка луча - электростатическая, О-Н -отклонение луча - магнитное.
2. Модель ВКБ-102 - охранная система.
В и их разновидности до настоящего времени широко используются для получения высококачественных изображений. Их достоинства: высокая чувствительность и разрешающая способность, широкий температурный диапазон (-80 … +1200С), радиационная стойкость. К недостаткам В необходимо отнести инерционность изображения, значительные габариты и хрупкость. Для современных систем промышленного телевидения разработаны малоинерционные В - кремниконы, в которых на мишени не образуется зарядовый рельеф и развертывающий луч «считывает» лишь сопротивление ее отдельных участков. В широко используются в машиностроении, металлургии, медицине, криминалистике и т.д. в задачах автоматизации операций контроля процессов прецизионной сборки, экспертизы документов, контроля температурных режимов и пр.
Испытания на радиационную стойкость показали надежную работу В при максимальной дозе до 105 рад.
Дальнейшее развитие вакуумных передающих и приемных телекамер происходит в направлении повышения разрешающей способности, яркости и контрастности изображения, улучшения цветопередачи, а также линейности и сведения по всему полю экрана (преимущественно для приемных трубок - кинескопов). Так, увеличение разрешения и яркости (что позволяет увеличить размеры экрана кинескопа до 1 м и более) достигается уменьшением площади триад люминофора с соответствующим уменьшением ячеек теневой маски. Шаг маски и шаг апертурной сетки в трубках типа тринитрон составляет менее 0,25 мм. Наибольшая разрешающая способность ~1000 твл достигается в трубках с дельтавидным расположением электронных прожекторов и точечной теневой маской. Кроме того, для уменьшения температурной деформации маски ее изготавливают из инвара (Fe-Ni), имеющего очень малый коэффициент температурного расширения. Такие модели получили название Super Visual. Улучшение четкости изображения достигается увеличением ускоряющего напряжения трубки. Что касается повышения контрастности, то для этой цели применяют тонирование стекла кинескопа, при котором уменьшается отражение света (трубки Black Trinitron). При этом контрастность возрастает на 30 … 60%.
Бурное развитие полупроводниковой технологии в конце ХХ века привело к появлению и активному внедрению твердотельных телекамер. Их принято разделять на два основных класса:
· ПЗС камеры;
· камеры на базе фотодиодных (фототранзисторных, и иногда фоторезисторных) матриц.
Сравнительные характеристики этих систем представлены в табл. 6.9.
Таблица 6.9. Сравнительная характеристика твердотельных телекамер СТЗ
| Тип ЧЭ | l, мкм | Smax, интегральная | Размер элемента, мкм | Шаг, мкм | Размерность, N´N | fсч, кГц |
| фоторезистор | 0,4 ...30 | 1000 В/Вт | 15´60 | 50 | 64´64 | 10 |
| фотодиод | 0,4 ... 1,1 | 25 мА/Лм | 4´32 | 70 | 128´144 | 1000 |
| фототранзистор | 0,4 ... 1,1 | 1000 мА/Лм | 8´32 | 50 | 128´144 | 100 |
| ПЗС | 0,4 ... 1,3 | 0,1 А/Вт | 3´6 | 8 | 795´596 | 1000 |
Наибольшее распространение получили телевизионные системы на базе ПЗС камер.
6.3.2. Телекамеры на основе приборов с зарядовой связью
В основе работы приборов с зарядовой связью (ПЗС) лежит принцип хранения локализованного заряда в потенциальных ямах, образуемых в полупроводниковом кристалле под действием внешнего поля и передачи этого заряда из одной потенциальной ямы в другую при изменении управляющих воздействий.
Идея ПЗС была выдвинута в 1970 г. американцами У. Бойлем и Д. Смитом, и в настоящее время устройства на ПЗС-структурах используются во многих областях электроники. На их основе создаются ОЗУ большого объема, фильтры, линии задержки и др. Исключительно перспективно их применение и в качестве приемников изображения. Главные достоинства ПЗС - жестко заданный геометрический растр, исключающий проблему геометрических искажений, относительная температурная стабильность параметров, надежность. Первые фоточувствительные интегральные схемы на ПЗС появились в 1977 году. Однако долгое время их использование было практически невозможным в связи с очень низкой чувствительностью, причем различной в красной, синей и зеленой частях спектра. Тем не менее, к середине 90-х годов ХХ века почти по всем техническим параметрам ПЗС камеры (в зарубежной литературе CCD камеры) превзошли телекамеры на ЭЛТ трубках. Возможность миниатюризации камерных головок привела к появлению новых аппаратов - записывающих телекамер - комкордеров (от англ. CAMera + RECorder).
В настоящее время промышленно выпускаются твердотельные передающие камеры на базе ПЗС матриц, содержащие более 600000 элементов и ПЗС линеек с 8192 элементами. Размер ПЗС матрицы описывается параметром, называемым «формат», который соответствует диагонали В, эквивалентного данной матрице. Он измеряется в дюймах и принимает значения: 1’’, 2/3’’, 1/2’’, 1/3’’, 1/4’’. Последние модели «Sony» имеют формат 1/4’’. Габариты ПЗС камер существенно меньше, чем В. Так, плоская черно-белая камера компании Watec WAT-600 имеет размер 29´29´16 мм, цилиндрическая черно-белая камера WAT-704 имеет диаметр 18 мм, цветная камера с вынесенной головкой Elmo QN401E имеет диаметр 7 мм. Размер матрицы влияет на угол поля обзора: при одинаковых объективах камера 1/2’’ имеет больший угол, чем камера с матрицей 1/3’’.
Разрешение современных черно-белых ПЗС камер составляет 380 ... 470 твл. Камеры с высоким разрешением (TSR-480 японской фирмы Elmo с 590 твл) позволяют четко видеть мелкие детали: номера машин, лица и т.д. Разрешение серийных цветных ПЗС камер несколько хуже: 300 ... 350 твл, хотя все эти показатели определяются технологическими факторами, ограничений которых не видно. Так, уже появляются цветные ПЗС камеры с разрешением 470 … 500 твл (SSC C370P фирмы Sony, TSP-482 фирмы Elmo).
Рассмотрим принцип действия ПЗС матрицы. Основными элементами ПЗС являются МОП-емкости (емкости, образованные структурой металл-окисел-проводник) или контакты с барьером Шоттки. Эти дискретные элементы располагаются максимально близко друг к другу, так, чтобы их потенциальные ямы сливались, образуя, тем самым, зарядовую связь. В то же время, самопроизвольного «растекания» зарядов между отдельными элементами быть не должно, для чего они разделены стоп-каналами. На рис. 6.23 показана структура и временные диаграммы работы трехфазного элемента ПЗС.
 Принцип действия устройства основан на накоплении и хранении заряда внутри p-n перехода, который образуется при подаче на металлический электрод на поверхности полупроводника положительного напряжения ~ 10 ... 15 В. (В этом случае, основные носители - «дырки» уходят вглубь полупроводника, и в его толще индуцируется p-n переход).
Принцип действия устройства основан на накоплении и хранении заряда внутри p-n перехода, который образуется при подаче на металлический электрод на поверхности полупроводника положительного напряжения ~ 10 ... 15 В. (В этом случае, основные носители - «дырки» уходят вглубь полупроводника, и в его толще индуцируется p-n переход).
Каждый элемент (ячейка) матрицы включает 2 ... 3 электрода (количество электродов определяется числом фаз управления) и участок подложки в их окрестности. При определенных фазовых напряжениях под электродами поочередно создаются области, обедненные основными носителями и являющиеся потенциальными ямами для неосновных носителей, благодаря чему индуцированный p-n переход начинает работать в режиме накопления заряда. В телевизионных системах образование заряда связано с изменением освещенности ПЗС элемента. Заряд появляется при выбивании квантами света электронов из атомов полупроводника, в результате чего свободные электроны устремляются к p-n переходу, отыскивая положительные дырки и создавая ток через него.
Один из электродов делается прозрачным в видимой части спектра. От его материала в значительной степени зависит спектральная чувствительность ПЗС матрицы. Синтез материала электрода представляет собой сложную технологическую задачу. (Обычно используют поликристаллический кремний, недостатком которого является низкая чувствительность в синей области). Далее, часть свободных электронов рекомбинирует с дырками частично разряжая МОП-емкость, а оставшийся заряд выводится в закрытую от света зону. Перемещение заряда осуществляется управляющими электродами по принципу «бегущей волны» Ф1 - Ф2 - Ф3, когда потенциальные ямы образуются поочередно под 1, 2, 3 электродами (рис. 6.23б). Аналогичным образом осуществляется перемещение заряда дальше по кристаллу. Так, например, для вывода заряда за пределы светочувствительного слоя и записи нового состояния освещенности напряжение понижается на Ф3 и повышается на Ф1 (при этом под первым электродом формируется потенциальная яма).
По своей структуре ПЗС матрицы разделяются на три группы:
· матрицы с переносом кадра;
· матрицы с построчным переносом зарядов;
· матрицы со строчно-кадровым переносом.
Во всех случаях она содержит светочувствительную секцию (или секцию накопления - СН; в некоторых схемах эти секции разделены), секцию хранения СХ, сдвиговые регистры СР (или секции переноса), а также выходной регистр ВР и видеоусилитель ВУ.
Поскольку перенос заряда должен осуществляться в полной темноте, в первых матрицах каждая строка считывалась в активном интервале, а экспозиция (освещение ячейки) осуществлялась во время гасящего импульса. Столь ограниченное время экспозиции приводило к низкой светочувствительности матрицы, и решено было увеличить время экспозиции и снизить время переноса заряда в защищенную от света область. Для этого потребовался накопитель информации, позволяющий сохранять заряд долгое время. Он был реализован в конструкции линейной матрицы с двумя параллельными цепочками - одна используется в качестве СН, другая - СР. Результатом явилась матрица с построчным переносом зарядов, разработанная фирмой Sony, и широко используемая в недорогих телекамерах (рис. 6.24б). СН и СХ совмещены в одну секцию, чувствительные ячейки которой примыкают к вертикальным регистрам сдвига СР и по которым они перемещаются к горизонтальному ВР и ВУ. К недостатку схемы относится сильная чувствительность к ярким фрагментам - так называемые «столбы».
 В ПЗС с кадровым переносом (рис. 6.24а) заряд из секции накопления СН за время переноса сдвигается в секцию хранения СХ. В течение считывания следующего кадра в СН зарядовый рельеф предыдущего вводится построчно в ВР. Первые камеры делали именно по этой схеме (так называемые RCA камеры). До сих пор фирма Philips выпускает RCA камеры. Недостатком схемы является необходимость в двойном количестве ПЗС элементов.
В ПЗС с кадровым переносом (рис. 6.24а) заряд из секции накопления СН за время переноса сдвигается в секцию хранения СХ. В течение считывания следующего кадра в СН зарядовый рельеф предыдущего вводится построчно в ВР. Первые камеры делали именно по этой схеме (так называемые RCA камеры). До сих пор фирма Philips выпускает RCA камеры. Недостатком схемы является необходимость в двойном количестве ПЗС элементов.
 ПЗС матрицы со строчно-кадровым переносом используются в камерах высшего класса (рис. 6.25). Базовой моделью явилась студийная телекамера BVP-50 фирмы Sony. Как известно, телевизионный стандарт предусматривает режим чересстрочной развертки, когда поочередно выводятся четный и нечетный полукадры. Рассмотрим процедуру вывода нечетного полукадра в матрицах со строчно-кадровым переносом. Сначала, сигнал Фн генератора тактовых импульсов ГТИ инициирует параллельный перенос зарядов, содержащихся в светочувствительных элементах нечетных строк каждого столбца в секцию накопления СН. Затем, фазами Фв1 ... Фв3 заряды, принадлежащие одному полукадру, из СН переносятся в секцию хранения СХ регистрами вертикального сдвига РВС. Далее, сигналами Фг1 и Фг2 ГТИ заряды, соответствующие нечетному полукадру построчно перемещаются вдоль ВР (он называется также регистром горизонтального сдвига РГС) и последовательно подаются в выходной каскад, содержащий транзистор сброса ТС и выходной транзистор ВТ. Наконец, весь процесс повторяется для четного полукадра. Перенос зарядов и сброс из СХ в ВР выполняется в интервале гасящего импульса, а считывание из СН - в интервале следующей экспозиции.
ПЗС матрицы со строчно-кадровым переносом используются в камерах высшего класса (рис. 6.25). Базовой моделью явилась студийная телекамера BVP-50 фирмы Sony. Как известно, телевизионный стандарт предусматривает режим чересстрочной развертки, когда поочередно выводятся четный и нечетный полукадры. Рассмотрим процедуру вывода нечетного полукадра в матрицах со строчно-кадровым переносом. Сначала, сигнал Фн генератора тактовых импульсов ГТИ инициирует параллельный перенос зарядов, содержащихся в светочувствительных элементах нечетных строк каждого столбца в секцию накопления СН. Затем, фазами Фв1 ... Фв3 заряды, принадлежащие одному полукадру, из СН переносятся в секцию хранения СХ регистрами вертикального сдвига РВС. Далее, сигналами Фг1 и Фг2 ГТИ заряды, соответствующие нечетному полукадру построчно перемещаются вдоль ВР (он называется также регистром горизонтального сдвига РГС) и последовательно подаются в выходной каскад, содержащий транзистор сброса ТС и выходной транзистор ВТ. Наконец, весь процесс повторяется для четного полукадра. Перенос зарядов и сброс из СХ в ВР выполняется в интервале гасящего импульса, а считывание из СН - в интервале следующей экспозиции.
Изменение потенциала затвора ВТ вызывает появление видеоимпульса на выходе всего устройства и матрицы в целом. Выходной каскад (так называемая плавающая диффузионная область - ПДО) преобразует видеосигналы из формы зарядов в форму напряжений. Заряд инжектируется в ПДО путем кратковременного открытия канала ТС. Частота сдвиговых сигналов в регистрах ПЗС связана с темпом вывода видеосигнала и всего кадра. Ее величина определяется необходимостью сопряжения со стандартным телевизионным оборудованием и зависит от размерности матрицы (числа столбцов и строк) и частотных свойств полупроводника. Тактовая частота ВР в разных ПЗС матрицах варьируется в широких пределах 10 кГц ... 10 мГц.
В табл. 6.10 представлены некоторые характеристики отечественной ПЗС матрицы К1200ЦМ7.
Таблица 6.10. Технические характеристики ПЗС матрицы
| Параметры | СН | СХ | ВР | Количество строк | |||
| Модель | Размерность | Кол-во элементов | Размер, мкм | Кол-во элементов | Размер, мкм | Кол-во элементов | |
| К1200ЦМ7 | 576´360 207360 | 288´360 103680 | 18´19 | 103680 | 21´21 | 362 | 576 |
 Уменьшение габаритов матриц со строчно-кадровым переносом достигается использованием технологии HAD (Hole Accumulated Diode) фирмы Sony, в которой заряд переносится не в сторону от светочувствительной ячейки, а внутрь кристалла. В технологии Hyper HAD, также предложенной фирмой Sony, каждый элемент матрицы содержит микролинзу, что вдвое увеличивает светочувствительность матрицы.
Уменьшение габаритов матриц со строчно-кадровым переносом достигается использованием технологии HAD (Hole Accumulated Diode) фирмы Sony, в которой заряд переносится не в сторону от светочувствительной ячейки, а внутрь кристалла. В технологии Hyper HAD, также предложенной фирмой Sony, каждый элемент матрицы содержит микролинзу, что вдвое увеличивает светочувствительность матрицы.
Функциональная схема телекамеры на основе ПЗС представлена на рис. 6.26. Синхрогенератор СГ задает тактовую частоту управления СХ, СН и ВР. Выходной каскад, включающий ПДО и ВУ, преобразует заряды ПЗС ячеек в последовательность видеоимпульсов. Усилитель-смеситель УС служит для усиления видеоимпульсов и подмешивания в сигнал гасящих и синхронизирующих импульсов, формируя композитный видеосигнал.
Существенным недостатком современных ПЗС камер является их меньшие, по сравнению с ЭЛТ, чувствительность и разрешающая способность. Самые чувствительные ПЗС камеры, по аналогии с В называемые «ночными», способны работать при уровнях освещенности до 0,005 … 0,00004 лк, что соответствует освещенности от звезд, частично закрытых облаками. Что касается разрешения, то телекамера стандартного разрешения с числом элементов по строке около 500 имеет реальную разрешающую способность всего 380 твл. Это значение, получается умножением числа элементов матрицы ПЗС на технологический коэффициент 0,75. Однако даже такое значение превосходит разрешающую способность большинства стандартных видеомагнитофонов. ПЗС камеры высокого разрешения с 760 элементами на строке имеют разрешающую способность примерно 570 твл.
Формат телекамеры непосредственно связан с размером используемого объектива. Самыми распространенными и дешевыми являются черно-белые ПЗС камеры стандартного разрешения и форматом 1/3". Четвертьдюймовые камеры используются в системах видеонаблюдения. Для телекамер форматом 1/2" характерно более высокое отношение сигнал/шум, достигающее при дневной освещенности значения 55 … 60 дБ.
Примеры выпускаемых телевизионных ПЗС камер представлены в табл. 6.11.
Таблица 6.11. Примеры промышленных ПЗС камер
| Модель | Тип | Количество элементов | Ámin, лк | f, МГц | P, Вт | Uип, В | Размеры, мм |
| КТЛ-3 | линейка | 8000 | 0,4 | 3,0 | 15 | Æ38´135 | |
| КТН-15 | матрица | 512´582 (380 твл) | 0,5 | 7,0 | 5,0 | 15 | 34´42´110 |
| WM-202R | матрица «глазок» | 380 твл | 0,8 | 1,2 | 12 | Æ24´50 | |
| SSC-M370 | матрица | 752´582 (570 твл) | 0,08 | 2,3 | 12 | 64´57´155 | |
| WAT-704R | матрица | 537´597 (380 твл) | 0,8 | 1 | 9 | Æ18´50 | |
| WAT-205A | матрица цветная | 537´597 (320 твл) | 8 | 1,5 | 6 | 45´47´29 |
Примечание. Модели SSC-M370 и WAT разработаны фирмами Sony и Watec, Япония.
Самая маленькая цифровая фотокамера, разработанная фирмой Sony, весит 26 г., имеет ОЗУ емкостью 64 МБ и способна хранить около 1000 фотографий.
Различные системы на основе ПЗС матриц и линеек нашли широкое применение в самых различных областях. Не рис. 6.27 в качестве примера показано использование ПЗС линейки в системе управления оптическим фокусом видеокамеры. Схема этого устройства похожа на схему устройства автофокусировки головки наведения (рис. 5.78). В одном из наиболее известных решений, известных как TCL (Through the Camera Lens), луч света прошедший сквозь  объектив направляется полупрозрачным зеркалом на датчик - линейку ПЗС. При этом из пучка лучей, образующих изображение объекта апертурной маской выделяются два крайних, которые разделительными линзами фокусируются в плоскости ПЗС датчика. Разница между полученным сигналом и опорным, записанным в памяти микропроцессора камеры, является сигналом управления приводом объектива.
объектив направляется полупрозрачным зеркалом на датчик - линейку ПЗС. При этом из пучка лучей, образующих изображение объекта апертурной маской выделяются два крайних, которые разделительными линзами фокусируются в плоскости ПЗС датчика. Разница между полученным сигналом и опорным, записанным в памяти микропроцессора камеры, является сигналом управления приводом объектива.
Подведем итоги. Достоинствами телевизионных ПЗС камер являются: высокое быстродействие (малая инерционность), возможность фиксации (запоминания) изображения, высокая линейность по полю, устойчивость к внешним возмущающим воздействиям, а также малые габариты и вес. Недостатками - меньшая чувствительность и разрешающая способность, чем у вакуумных трубок и геометрический шум.
6.3.3. Фотодиодные матрицы
Наряду с телекамерами на ПЗС структурах нашли распространение и фотодиодные матрицы (ФДМ), также работающие на принципе накопления зарядов. Их главным достоинством является возможность поэлементной адресации и параллельного вывода данных. В основе работы ФДМ лежит свойство p-n перехода, находящегося под обратным потенциалом накапливать заряд, пропорциональный падающему на переход потоку электронов. ФДМ широко используются в оптических преобразователях, сканерах, принтерах и др.
Основой ФДМ является ячейка, содержащая фотодиод и три МОП-транзистора V1, V2 и V3 (рис. 6.28). В начале цикла записи на транзистор V1 поступает импульс стирания Uст открывающий транзистор в результате чего барьерная емкость фотодиода заряжается напряжением по цепи +Eсм - Eп. После закрытия V1 барьерная емкость разряжается фототоком, причем, чем выше освещенность ячейки, тем быстрее происходит разряд. Если через определенный промежуток времени tнак. на транзистор V2 подать адресный импульс Uа (режим вывода сигнала), то по цепи V3 - V2 потечет ток от источника -Еп. Величина этого тока зависит от степени открытия V3 потенциалом на емкости фотодиода (т.е. от оставшегося через время tнак заряда на фотодиоде). Таким образом, выходной сигнал ячейки зависит от ее освещенности Á, а совокупность сигналов ФДМ дает информацию о распределении света на ее чувствительной поверхности (рис. 6.28).
Новый цикл записи начинается подачей очередного импульса стирания от внешнего формирователя на общую (для всех ячеек шину), при этом полностью заряжаются емкости фотодиодов, «стирая» сохранившиеся на них потенциалы. Время tнак определяет накопленную ячейкой энергию светового потока Ф и, следовательно, ее фоточувствительность.
 Как уже отмечалось, функция преобразования фотодиода близка к линейной (рис. 6.29).
Как уже отмечалось, функция преобразования фотодиода близка к линейной (рис. 6.29).
Схема телекамеры на основе ФДМ представлена на рис. 6.30. Основной режим работы телекамеры - «считывание с накоплением». В этом режиме, после короткого импульса стирания Uст, в течение интервала времени tнак происходит «запись» распределения освещенности на ячейках, после чего на выбранную строку поступает адресный импульс и на выходных шинах одновременно возникают потенциалы ячеек этой строки. Таким образом, организуется параллельно-последовательное считывание информации. (Параллельно - элементы строки, последовательно - строки, причем в произвольном порядке).
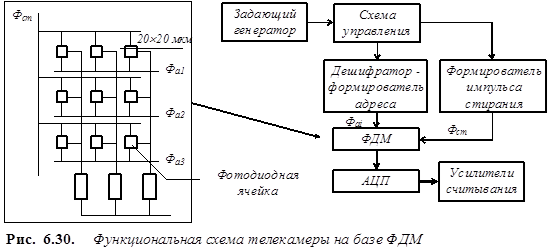
Частота вывода кадров fк в этом режиме определяется величиной tнак и варьируется в диапазоне 200 ... 5000 Гц. Задающий генератор устанавливает частоту следования управляющих импульсов, а схема управления определяет режим работы камеры. Дешифратор-формирователь адреса устанавливает амплитуду и длительность адресных импульсов и распределяет их по адресным входам ФДМ в соответствие с заданным порядком считывания (подобно считыванию из ОЗУ). Данные из ячеек поступают через усилители считывания и АЦП в буферное устройство, используемое для согласования последовательности и скорости вывода данных из камеры и их ввода в процессор обработки изображений.
Фотодиодные телекамеры используются в специальных задачах робототехники. Достоинствами ФДМ являются возможность поэлементной адресации, высокое быстродействие, малые масса и габариты, высокая механическая прочность и надежность. К недостаткам ФДМ следует отнести в первую очередь, малую разрешающую способность, а также геометрическую неоднородность (вследствие различия фотоэлектрических характеристик отдельных ячеек).
Рассмотренные выше три типа телевизионных датчиков являются базовыми при построении СТЗ. В табл. 6.12 представлены их некоторые сравнительные характеристики.
Таблица 6.12. Сравнительные характеристики отечественных датчиков СТЗ
| Модель | Тип | Á, лк | n*, твл/мм | e, % | l, мкм | Размер кадра, N´N | Отношение сигнал/шум | m, г | V, см3 |
| ЛИ-427 | ЭЛТ (В) | 1 ... 200 | 50 | 2 | 0,4 ... 0,8 | 500´500 | 80 | 50 | 10 |
| ЛИ-214 | ЭЛТ (С) | 10-5...10 | 50 | 2 | 0,4 ... 0,55 | 500´500 | 100 | 500 | 100 |
| 1200ЦМ7 | ПЗС | 0,1 ... 20 | 30 | 2 | 0,4 ... 1,1 | 360´576 | 100 | 5 | 0,5 |
| ФМ-100 | ФДМ | 0,1 ... 200 | 15 | 3 | 0,4 ... 1,1 | 100´100 | 50 | 5 | 0,5 |
6.4. Устройства ввода и хранения изображений
Рассмотренные выше вопросы преобразования информации в СТЗ были посвящены принципам получения изображений в видеодатчике СТЗ - телекамере. Этот этап, называемый восприятием, выполняется, вообще говоря, безо всякого участия вычислительных средств. Остальные же этапы (предварительная обработка, сегментация, описание и т.д.) предполагают использование вычислительных ресурсов СТЗ. В этой связи, особое значение приобретает правильное построение устройств ввода изображений (фремграбберов, от англ. framegrabber - «захват изображения»), осуществляющих ввод и фильтрацию видеоинформации, и определяющих форму представления и способ обработки данных в процессоре СТЗ. (Первый промышленный фреймграббер выпустила фирма Data Translation, США).
 Конструктивно устройство ввода обычно выполняется в виде печатной платы, установленной на шине компьютера СТЗ, на входной разъем которой поступает стандартный видеосигнал. Выходная информация зависит от назначения и сложности устройства ввода. В ряде случаев это просто интерфейс между телекамерой и компьютером, в других - блок предварительной обработки, выполняющий значительную долю функций СТЗ (рис. 6.31). Структура интерфейса, а также объем требуемой памяти для хранения изображений в значительной мере определяются видом представляемой информации (строка, бинарный массив, полутоновое или цветное изображение), а также типом телевизионного датчика. Хотя в большинстве случаев выходным сигналом датчика является стандартный видеосигнал, характеристики интерфейса зависят от размерности кадра изображения и от того, черно-белое или цветное изображения подлежат обработке. Так, например, передача одного кадра бинарного изображения сравнительно небольшого формата 256´256 в стандартном телевизионном режиме требует ввода в память около 3,3 106 элементов изображения в секунду, а обработка цветного изображения того же формата требует пропускной способности канала не менее 10 Мбайт/c. Для современных неспециализированных компьютеров такая задача в реальном времени трудно выполнима. Для ее упрощения довольно часто используется буферизация (и «медленный ввод», например, по половине кадра), либо аппаратная выборка графического (контурного) изображения, при которой из полного массива выбирается только самая необходимая информация. Другими словами, ввод видеоинформации, а также и другие этапы преобразования (реализуемые программными средствами) могут рассматриваться как последовательное уменьшение размерности информационного массива, т.е. сжатие информации.
Конструктивно устройство ввода обычно выполняется в виде печатной платы, установленной на шине компьютера СТЗ, на входной разъем которой поступает стандартный видеосигнал. Выходная информация зависит от назначения и сложности устройства ввода. В ряде случаев это просто интерфейс между телекамерой и компьютером, в других - блок предварительной обработки, выполняющий значительную долю функций СТЗ (рис. 6.31). Структура интерфейса, а также объем требуемой памяти для хранения изображений в значительной мере определяются видом представляемой информации (строка, бинарный массив, полутоновое или цветное изображение), а также типом телевизионного датчика. Хотя в большинстве случаев выходным сигналом датчика является стандартный видеосигнал, характеристики интерфейса зависят от размерности кадра изображения и от того, черно-белое или цветное изображения подлежат обработке. Так, например, передача одного кадра бинарного изображения сравнительно небольшого формата 256´256 в стандартном телевизионном режиме требует ввода в память около 3,3 106 элементов изображения в секунду, а обработка цветного изображения того же формата требует пропускной способности канала не менее 10 Мбайт/c. Для современных неспециализированных компьютеров такая задача в реальном времени трудно выполнима. Для ее упрощения довольно часто используется буферизация (и «медленный ввод», например, по половине кадра), либо аппаратная выборка графического (контурного) изображения, при которой из полного массива выбирается только самая необходимая информация. Другими словами, ввод видеоинформации, а также и другие этапы преобразования (реализуемые программными средствами) могут рассматриваться как последовательное уменьшение размерности информационного массива, т.е. сжатие информации.
Основными задачами фреймграббера являются: кодирование видеосигнала (в том числе его квантование и дискретизация), частотная фильтрация («сглаживание» изображения), буферизация и ввод массива данных.
 Кодированием видеосигнала называется процедура представления черно-белого или цветного изображения дискретным массивом двоичных данных, однозначно соответствующим исходному.
Кодированием видеосигнала называется процедура представления черно-белого или цветного изображения дискретным массивом двоичных данных, однозначно соответствующим исходному.
Процедура кодирования включает дискретизацию (рис. 6.32) - частотное преобразование непрерывного видеосигнала в пиксельный и квантование - амплитудное преобразование сигналов яркости и цветности (рис. 6.33).
Дискретизация - представление непрерывного аналогового сигнала последовательностью его значений (отсчетов). Эти отсчеты берутся в моменты времени, отделенные друг от друга интервалом, называемым периодом дискретизации Tд. Дискретизация является преобразованием по полю; она реализует преобразование развертки видеосигнала Uс(t) в решетчатую функцию Uс [T] (обычно 100 нс < Tд < 1,5 мкс). Функция преобразования при дискретизации имеет вид:
 Uс (t) Þ Uс [T] Þ Umn,
Uс (t) Þ Uс [T] Þ Umn,
где m и n - дискретные отсчеты абсциссы x и ординаты y отдельных точек светочувствительной поверхности телекамеры (они однозначно определяются через периоды строчной и кадровой разверток). Для цветной телекамеры мы имеем дело с тремя преобразованиями, и для каждой компоненты получим:
UY Þ (UY) mn, UU Þ (UU) mn, UV Þ (UV) mn.
Здесь индексы Y, U, V - определяют соответствующую компоненту полного видеосигнала.
Чем меньше период Tд и выше частота дискретизации fд = 1/Tд, тем меньше различия между исходным сигналом и его дискретизированным значением. Ступенчатый вид дискретизированного сигнала может быть сглажен фильтром нижних частот, с помощью которого обычно и осуществляется восстановление аналогового сигнала из дискретизированного. Однако при восстановлении необходимо выполнения известное ограничения: fд ³ 2fmax, где fmax - верхняя частота спектра исходного аналогового сигнала (это условие определяется известной теоремой Найквиста-Котельникова). Если это условие не выполняется, то дискретизация сопровождается необратимыми искажениями. Примером искажений, связанных с недостаточно высокой частотой временной дискретизации (в том числе с частотой кадров разложения), является картина движущегося велосипеда с вращающимися спицами колеса (стробоскопический эффект). Поэтому, при дискретизации телевизионного сигнала с граничной частотой 6 МГц, необходимо, чтобы fд > 12 … 14 Мгц.
Квантование (преобразование по амплитуде) представляет собой замену величины отсчета сигнала ближайшим значением из набора фиксированных величин - уровней квантования. Следовательно, квантование - это округление величины отсчета. Уровни квантования делят весь диапазон возможного изменения значений сигнала на конечное число интервалов - шагов квантования. Обычно при квантовании производится представление абсолютного значения решетчатой функции Uс [T] º Umn в двоичном виде. Функция преобразования при квантовании описывается зависимостью:
Umn (N) Þ 2N DUmn
где DUmn = Uc min - разрешающая способность АЦП, соответствующая минимальному уровню видеосигнала (уровню белого), N - разрядность АЦП.
Таким образом, в результате кодирования полный видеосигнал преобразуется в трехмерную дискретную функцию изображения - (UYUV)mn:
(UYUV)mn = U(N, m, n, UY,UU,UV, t).
Здесь (UYUV)mn - дискретная амплитуда пикселя, расположенного на пересечении m-ой строки и n-ого столбца.
Искажения сигнала, возникающие в процессе квантования, называют шумом квантования. Обычно, при оценке шума вычисляют разность между исходным сигналом Uс и его квантованным значением Uс(N), а в качестве показателей шума принимают среднеквадратичное значение этой разности. Особенностью шума квантования является его связь непосредственно с сигналом, поэтому его нельзя устранить последующей фильтрацией. Шум квантования убывает с увеличением числа уровней квантования N. Нормой считается N = 10, что при двоичном кодировании позволяет квантовать видеосигнал на 1024 уровня. (Для монохромного изображения эти уровни называются градациями яркости). Таким образом, в результате проведенных преобразований видеосигнал представляет собой последовательность кодовых слов, каждое из которых передается в пределах одного интервала дискретизации.
Способы квантования и дискретизации видеосигнала в СТЗ в значительной степени определяют ее эксплуатационные характеристики - быстродействие и разрешающую способность.
Быстродействие СТЗ, как правило, задается числом обрабатываемых изображений в секунду и зависит от размера и типа изображения и числа градаций яркости. Оно связано со временем ввода и временем обработки данных процессором СТЗ. Как уже отмечалось, работа с массивами изображений требует очень высокой пропускной способности канала передачи данных. Так, только ввод 10 полутоновых кадров размером 512´512 элементов при 256 градациях яркости за секунду, требует пропускной способности интерфейса » 2,6 Мбайт/с. Цифровой же поток при чересстрочном вводе такого же цветного изображения с двухбайтовой глубиной цвета составит 512´512´25´2 » 13 Мбайт/c.
Режим реального времени требует обработки одного поля изображения в темпе кадровой развертки, т.е. за 1/50 с, или 20 мс. Обычно, для улучшения качества изображений (с учетом эргономических требований) необходимо обеспечить большие значения частот кадровой развертки - 85 … 120 Гц. С этой целью устройства ввода и вывода изображений оснащаются графическими процессорами. Так, например, при 24 битовом представлении изображения в «естественных цветах» с разрешением 1024´768 и вертикальной разверткой 85 Гц скорость передачи данных составляет более 200 Мбайт/с. Такая производительность превышает возможности стандартных локальных компьютерных шин. Частота строчной развертки устройства вывода изображений (например, монитора) должна составлять не менее 768´85 = 66 кГц.
Основными путями решения проблемы реального времени при вводе и выводе изображений являются:
· разработка новых типов локальных шин (подобных тем, которые установлены на графических станциях);
· создание специализированного быстродействующего программного обеспечения.
 Так, стандарт локальной шины AGP (Accelerated Graphics Port) обеспечивает пропускную способность шины канала - 533 Мбайт/с (по сравнению с 132 Мбайт/с для шины PCI), причем именно с такой скоростью смогут обмениваться данными процессор, видеоадаптер и оперативная память.
Так, стандарт локальной шины AGP (Accelerated Graphics Port) обеспечивает пропускную способность шины канала - 533 Мбайт/с (по сравнению с 132 Мбайт/с для шины PCI), причем именно с такой скоростью смогут обмениваться данными процессор, видеоадаптер и оперативная память.
Разрешающая способность СТЗ оценивается двояко: по полю (пространственное разрешение) и амплитуде. Первая характеризует размер пикселя изображения и определяется частотой дискретизации устройства ввода (рис. 6.34). Чем тоньше деталь, тем выше соответствующая ей частота видеосигнала. Разрешение по элементам изображения ограничивается «муар-эффектом», заметным у всех устройств ввода и вывода (особенно у мониторов и сканеров). Он является проявлением интерференции волн и определяется критерием Найквиста. «Муар-эффект» возникает, когда размер фрагмента изображения соответствует порогу разрешения.
Для телекамер на основе ПЗС и ФДМ разрешение по полю соответствует количеству элементов матрицы. Чем больше элементов разложения содержит матрица, тем выше разрешение системы в целом. Например, ФДМ свойственно невысокое пространственное разрешение ~ 104 (100´100) элементов (для СТЗ Insight 32, Англия или Hitachi Zosen Corp., Япония). Что касается ПЗС-камер, оно достигает (2 … 3) 106 элементов и выше. При описании пространственного разрешения устройств используются разные единицы измерения. Так, в телевидении разрешающая способность измеряется в линиях (твл) на единицу длины, причем учитываются и белые и черные линии - твл/мм, в оптике учитываются только черные линии, а в вычислительной технике разрешение характеризуется количеством точек на дюйм (dpi). Следовательно, разрешение в 300 dpi соответствует 300 черным точкам на 1 дюйме, или 150 полосам на дюйме. Для устранения этого разночтения при определении разрешающей способности устройства используют тестовые таблицы и процедуры.
При выборе разрешения по амплитуде (уровней квантования видеосигнала) учитывают особенности зрения. Так, на основании физиологических исследований установлено, что человек не способен различить 2% изменения градаций серого тона. Другими словами, глаз распознает не более 64 уровней серого, что позволяет для качественной оцифровки полутонового изображения использовать 6-ти разрядный АЦП. Однако здесь есть два момента. Во-первых, для любого АЦП характерно наличие шума, уровень которого примерно соответствует его младшему разряду. Во-вторых, чувствительность глаза обладает логарифмической характеристикой, что позволяет ему различать в нижней части диапазона яркостей больше оттенков, чем в верхней. Технические устройства (сканеры и мониторы) имеют линейную характеристику, и поэтому для обеспечения необходимого разрешения малых яркостей требуется при дискретизации не менее 8 бит. В профессиональных системах применяются 10-ти и более разрядные АЦП.
Как уже отмечалось, спектральная чувствительность глаза во всем диапазоне видимого света неодинакова. Она максимальна в области желто-зеленых тонов - примерно такая же, как и для серого цвета. Красные и синие тона различаются гораздо хуже. Обычно поступают просто - для каждой цветовой составляющей выбирают разрешение равное 1 байт, что и образует известную величину » 16,8 миллионов цветов (256´256´256). Такое количество цветов намного превышает возможности человеческих глаз. Большинство людей различает приблизительно 128 цветовых тонов при 30 значениях насыщенности и 50 уровнях яркости. Это соответствует максимум 128´30´50 = 192000 цветам. Данный режим также получил название True Color, в отличие от упрощенного цветового режима с разрешением в 5 бит на цветовую составляющую и названного High Color (32768 цветов).
6.4.1. Принципы хранения изображений
Запись больших объемов видеоинформации осуществляется на носитель, в качестве которого чаще всего используется магнитная лента шириной 8, 12,7 или 25 мм. Принцип магнитной записи был предложен и впервые осуществлен датским инженером В. Поульсеном в 1898 г. Он основан на способности определенных материалов, приобретать остаточную намагниченность X в результате воздействия магнитного поля. Чаще всего это поле создается универсальной магнитной головкой, непосредственно взаимодействующей с носителем и записывающей, воспроизводящей или стирающей видеоинформацию. Магнитная головка представляет собой сердечник из магнитомягкого материала с нанесенной на него обмоткой. Материал сердечника (пермаллой, феррит и др.) характеризуется высокой магнитной проницаемостью m и низкой коэрцитивной силой. Сердечник содержит зазор, ширина которого составляет 0,1 … 10 мкм. При записи в обмотку магнитной головки подают ток записываемого сигнала Ic, который намагничивает сердечник и возбуждает в области зазора магнитное поле рассеяния. Поле пронизывает носитель, движущийся через область зазора и намагничивающий его в соответствии с сигналом. Принцип считывания информации (воспроизведения) мало отличается от ее записи. Как известно, зависимость остаточной намагниченности X носителя от напряженности поля H нелинейна. Для ее линеаризации в магнитную головку наряду с током сигнала Ic подается ток подмагничивания Iп, частотой в 4 …6 и амплитудой в 6 … 8 раз выше наибольшей частоты сигнала. В этом случае зависимость становится практически линейной до значений Iп = (0,3 … 0,4) Iнас, где Iнас - ток записи, соответствующей магнитному насыщению носителя.
 Различают аналоговую и цифровую запись изображений. При аналоговой записи, сигналы записываются на дорожки продольно, поперечно и перпендикулярно направлению движения ленты (рис. 6.35). В первом случае, разноименные магнитные полюса участков расположены на одной и той же стороне рабочего слоя (рис. 6.35а). Поперечный вид записи реализуется путем формирования строчек остаточной намагниченности на ленте подвижными магнитными головками, перемещающимися перпендикулярно ей с большой скоростью (рис. 6.35б). При этом строчки записи уже не оказываются строго поперечными, а имеют некоторый наклон в сторону движения ленты. Разновидностью поперечного вида записи является наклонно-строчный (диагональный) вид, когда магнитные дорожки располагаются под острым углом к направлению движения ленты. Этот вид записи, появившийся в 60-х годах ХХ века получил особое распространение при записи телевизионных сигналов. Его существенной особенностью явилась возможность записи на одной строке носителя целого телевизионного поля. (Для сравнения: при поперечной записи на одной строке можно было записать всего 15 … 20 твл).
Различают аналоговую и цифровую запись изображений. При аналоговой записи, сигналы записываются на дорожки продольно, поперечно и перпендикулярно направлению движения ленты (рис. 6.35). В первом случае, разноименные магнитные полюса участков расположены на одной и той же стороне рабочего слоя (рис. 6.35а). Поперечный вид записи реализуется путем формирования строчек остаточной намагниченности на ленте подвижными магнитными головками, перемещающимися перпендикулярно ей с большой скоростью (рис. 6.35б). При этом строчки записи уже не оказываются строго поперечными, а имеют некоторый наклон в сторону движения ленты. Разновидностью поперечного вида записи является наклонно-строчный (диагональный) вид, когда магнитные дорожки располагаются под острым углом к направлению движения ленты. Этот вид записи, появившийся в 60-х годах ХХ века получил особое распространение при записи телевизионных сигналов. Его существенной особенностью явилась возможность записи на одной строке носителя целого телевизионного поля. (Для сравнения: при поперечной записи на одной строке можно было записать всего 15 … 20 твл).
Одной из основных проблем, возникающих при записи видеоизображений, является необходимость передачи широкополосного видеосигнала без искажений. Как известно, при стандарте 625 строк в кадре и передаче 25 кадр/с полоса частот видеосигнала располагается в пределах 0 … 6 МГц. Минимальная длина волны l, которую удается записать в современной промышленной аппаратуре магнитной записи, лежит в пределах 0,3 … 2 мкм. Следовательно, для записи сигнала с частотой fmax = 6 МГц при длине волны, например, 2 мкм необходима относительная скорость носителя и головки vотн = l fmax ~ 12 м/с. Такая весьма высокая относительная скорость достигается, главным образом, за счет быстрого вращения магнитных головок, а также использования нескольких магнитных головок (2 … 4), поскольку значительных скоростей протяжки vл магнитной ленты достичь очень сложно. Обычно, vл £ 40 см/с. Однако, и при таких скоростях движения носителя, возникают аэродинамические эффекты, существенно ухудшающие качество записи и воспроизведения. Поэтому, вместо непосредственной записи изображения на носитель, используют метод ЧМ, при которой видеосигнал модулирует некоторую несущую частоту fн = (1,1 … 1,5) fmax. Спектр записываемых частот в этом случае переносится в более высокочастотную область, уменьшая, тем самым, наибольшую длину записываемых волн l. Недостатком такого подхода является расширение необходимой полосы частот, которая для видеосигнала (0 … 6 МГц) увеличилась до 0,5 … 11 МГц.
В современных системах записи vотн = 25 м/с. Это означает, что система «носитель-головка» должна пропускать полосу частот от fmin = 0,5 МГц до fmax = 11 МГц, которая соответствует полосе длин волн от lmin = 25 м/с : 0,5 МГц = 50 мкм до lmax = 25 м/с : 11 МГц = 2,3 мкм. При записи цветных видеоизображений сигнал цветности выделяется из полного композитного видеосигнала фильтром высоких частот. Далее, он модулирует поднесущую частоту из диапазона 550 … 800 кГц и записывается на носитель совместно с яркостным сигналом, несущая которого fн > 8,2 МГц. Сигнал яркости также выполняет высокочастотное подмагничивание сигнала цветности.
Качество изображения, воспроизводимое повременными аналоговыми видеомагнитофонами, настолько высоко, что при их правильной настройке и выборе соответствующей видеоленты, изображения объекта, передаваемые непосредственно с видеокамеры и с видеомагнитофона визуально неотличимы. Важнейшим недостатком аналоговых систем записи является ограничение на многократное копирование видеоинформации. Уровень шума каждый раз возрастает на 1,5 … 3 дБ. Поэтому, в последнее время широкое применение получила цифровая запись видеоизображений. Цифровая видеозапись требует значительного расширения пропускной способности канала записи по сравнению с аналоговой. Так, для известного цифрового формата магнитной видеозаписи D1 с раздельным кодированием сигналов яркости и цветности 4 : 2 : 2 при частоте дискретизации сигнала яркости 13,5 МГц, а сигналов цветности R-Y и B-Y 6,75 МГц и 8 битовом квантовании амплитуды поток информации составит (13,5 + 2 ´ 6,75) МГц ´ 8 бит = 216 Мбит/с. Цифровой композитный сигнал требует существенно меньшей пропускной способности канала. Например, при записи в формате D2 при частоте дискретизации сигнала, равной четвертой гармонике цветовой поднесущей (4 ´ 4,43 МГц), получим 4 ´ 4,43 МГц ´ 8 бит = 142 Мбит/с. Заметим, что в обоих случаях полоса записываемых частот намного шире, чем при аналоговой записи.
 Запись видеосигналов на магнитную пленку производится видеокамерами. Большинство из них в качестве датчика изображений используют ПЗС-матрицы разной размерности. Так, типовая матрица размером 0,5 дюйма содержит ~ 400000 элементов, разделенных на 581 строку и 756 столбцов. В последних моделях количество элементов превышает 106. В простых мобильных видеокамерах формируется композитный видеосигнал (он обычно присутствует на видеовыходе или разъеме SCART), в камерах среднего класса - компонентный. Телекамеры этих типов получили общее название camcorder (от англ. camera + recorder - записывающая камера). Тип выходного сигнала какордера зависит от формата записи - композитный, например, в VHS и SVHS камерах и компонентный - в камерах типа Betacam. Для профессиональных целей применяются цветные RGB-камеры, содержащие три ПЗС-матрицы, отдельно на каждую цветовую составляющую (рис. 6.36). На выходе RGB-камеры присутствуют как стандартный композитный видеосигнал, так и отдельно три цветовые составляющие. Следствием этого является возможность прямого подключения цветовых каналов, что улучшает качество воспроизведения.
Запись видеосигналов на магнитную пленку производится видеокамерами. Большинство из них в качестве датчика изображений используют ПЗС-матрицы разной размерности. Так, типовая матрица размером 0,5 дюйма содержит ~ 400000 элементов, разделенных на 581 строку и 756 столбцов. В последних моделях количество элементов превышает 106. В простых мобильных видеокамерах формируется композитный видеосигнал (он обычно присутствует на видеовыходе или разъеме SCART), в камерах среднего класса - компонентный. Телекамеры этих типов получили общее название camcorder (от англ. camera + recorder - записывающая камера). Тип выходного сигнала какордера зависит от формата записи - композитный, например, в VHS и SVHS камерах и компонентный - в камерах типа Betacam. Для профессиональных целей применяются цветные RGB-камеры, содержащие три ПЗС-матрицы, отдельно на каждую цветовую составляющую (рис. 6.36). На выходе RGB-камеры присутствуют как стандартный композитный видеосигнал, так и отдельно три цветовые составляющие. Следствием этого является возможность прямого подключения цветовых каналов, что улучшает качество воспроизведения.
Как уже отмечалось, телевизионный растр состоит из 625 (или 575 активных) строк разложения. Все видеокамеры обеспечивают получение такого разрешения по вертикали. Что же касается разрешения по горизонтали, то в идеале оно могло бы составить 625´4/3 = 833, или, по крайней мере, 575´4/3 = 767 элемента в строке. На самом деле это разрешение зависит от ширины полосы пропускания канала видеозаписи. Так, при передаче полной полосы частот видеосигнала в системе PAL (5 МГц) информация о яркости передается с разрешением 320 твл (перепадов яркости) в строке. Таким образом, при максимальном качестве аналоговое телевизионное изображение имеет разрешение по горизонтали в 640 элементов. (Это соответствует, кстати, известному режиму VGA). Поэтому, разрешение черно-белого изображения составляет 575´640 элементов.
Однако реально ширина спектра записанного на магнитном носителе черно-белого изображения ограничена частотой ~ 4 МГц, что соответствует 512 элементами в строке. Спектр записанного сигнала цветности не превышает 1,5 МГц, т.е. цветных элементов в строке допускается и того меньше ~ 200 элементов. Лучшее качество изображения получают на основе компонентного принципа, когда сигналы цветности и яркости передаются и записываются на пленку раздельно. В таких устройствах можно записать аналоговый видеосигнал с полосой частот до 5 МГц, т.е. получить разрешение по горизонтали до 640 элементов в строке.
В табл. 6.13 представлены самые распространенные системы аналоговой магнитной записи.
Таблица 6.13. Основные принципы аналоговой магнитной записи изображений
| Формат | VHS | Betacam |
| Характеристика | Бытовой | Hi-Fi |
| Тип сигнала | Композитный | Компонентный |
| Ширина спектра, МГц | 4 | 5 |
| Разрешение видео (реальное) | 575´512 | 575´640 |
| Разрешение телевизионное (PAL) | 575´767 (max 625´833) |
Проведем обзор основных форматов магнитной видеозаписи. Как уже отмечалось, низкочастотный телевизионный видеосигнал является композитным, т.е. представляет собой результат сложения яркостного сигнала Y, двух цветовых поднесущих, модулированных сигналами цветности U (R-Y или Cr) и V (B-Y или Cb), а также служебных импульсов, причем частоты цветоразностных сигналов лежат в пределах полосы спектра яркостного сигнала. Из-за строчной структуры телевизионного разложения в спектральной области все они имеют гребенчатую структуру, расстояния, между соответствующими пиками которых равны строчной частоте. При этом частоты поднесущих выбраны так, чтобы спектральные пики сигналов цветности оказались между пиками яркостного сигнала. В результате путем использования специальных гребенчатых фильтров возможно эффективное разделение этих сигналов. Однако, подобные фильтры весьма сложны и дороги, а потому в основном используются в профессиональной аппаратуре высокого разрешения. В бытовых аналоговых устройствах ограничиваются более простыми полосовыми фильтрами, заметно снижающими четкость изображений. Например, в видеомагнитофонах и камерах классов VHS (Video Home System) и Video-8, использующих только композитные видеосигналы, разрешение ограничено 240 твл. Кроме того, даже полное использование всех различий сигналов все равно не позволяет идеально разделить их. Поэтому более эффективным оказывается использование не единого композитного сигнала, а двух композитных сигналов Y и C. Y несет сигнал яркости и синхроимпульсы, а C (Chrominance) - модулированные цветовые сигналы. Такой комбинированный сигнал называется S-Video, он используется при записи/воспроизведении в аппаратуре классов S-VHS и Hi-8. Разрешение в этом случае достигает 400 твл. Следующим шагом к повышению качества явился переход к компонентному сигналу YUV. Он используется в профессиональной аппаратуре класса Betacam и обеспечивает разрешение до 500 твл. Наилучшее качество достигается в RGB устройствах: здесь отсутствуют кодирование и модуляция сигналов и достигается наиболее простая и точная передача сигнала. (Однако визуально достоинства этого формата практически неразличимы). В последние годы ХХ века было разработано несколько цифровых форматов представления видеосигнала. Аппаратура, работающая в этих форматах, выпускается фирмами Sony, Panasonic, JVC и др.
В табл. 6.14 представлен обзор распространенных форматов магнитной записи.
Таблица 6.14. Сравнительные характеристики форматов магнитной записи
| Формат записи | Тип записи | Вид сигнала | Ширина ленты, мм | Скорость ленты, м/с | Отношение сигнал/шум, дБ | Коэффициент компрессии |
| VHS | Аналоговая | композитный | 12,65 | 23,39 | 43 | - |
| S-VHS | Аналоговая | Y/C | 12,65 | 23,39 | 45 | - |
| Hi8 | Аналоговая | Y/C | 8 | 20,5 | 44 | - |
| Betacam | Аналоговая | YUV | 12.65 | 101,5 | 49 | - |
| Betacam SP | Аналоговая | YUV | 12,65 | 101,5 | 51 | - |
| Betacam SX | Цифровая | YUV 4:2:2 | 12,65 | 59,575 | 51 | 10:1 |
| Digital Betacam | Цифровая | YUV 4:2:2 | 12,65 | 96,7 | 55 | 2:1 |
| DV | Цифровая | YUV 4:2:0 | 6,35 | 18,831 | 54 | 5:1 |
| DVCam | Цифровая | YUV 4:2:0 | 6,35 | 28,2 | 54 | 5:1 |
| DVCPro | Цифровая | YUV 4:1:1 | 6,35 | 33,813 | 54 | 5:1 |
| DVCPro50 | Цифровая | YUV 4:2:2 | 6,35 | 67,626 | 62 | 3.3:1 |
| Digital-S | Цифровая | YUV 4:2:2 | 12,65 | 57,8 | 55 | 3.3:1 |
Первыми цифровыми устройствами в телевидении стали цифровые корректоры временных искажений, кадровые синхронизаторы, генераторы специальных эффектов, микшеры и коммутаторы. Активный переход к цифровому телевидению произошел с появлением первого промышленного цифрового видеомагнитофона фирмы Sony. Во-первых, значительно улучшилось собственно качество воспроизводимого изображения и звука, во вторых, намного возросло количество допустимых перезаписей информации на носитель, практически без потери качества. К примеру, перезапись на видеомагнитофонах формата VHS, без допустимых для телевещания потерь качества не допускается вообще, формат S-VHS допускает одну-две перезаписи, а Betacam SP три-четыре. Для цифрового видеомагнитофона это число составляет несколько десятков. Однако цифровая запись изображений порождает ряд известных проблем, связанных со значительным расширением полосы частот, занимаемой сигналом. Так, если в студийном аналоговом видеомагнитофоне для передачи видеосигнала с частотой 6 МГц требуется записывать и воспроизводить полосу частот около 12 МГц, то в цифровом видеомагнитофоне для передачи такого же видеосигнала необходимо расширить полосу частот, по крайней мере, до 120 МГц. Другими словами, пропускная способность канала цифровой видеозаписи должна быть на порядок выше, чем аналоговой. Следовательно, и каналы связи должны иметь пропускную способность в несколько сотен мегабит в секунду. Техническое решение этой проблемы предполагает кодирование сигнала (т.е. его дискретизацию по времени, квантование по уровню и преобразование в одну из модуляционных форм), а также компрессию. Кодирование производится как композитного, так и компонентного видеосигналов.
6.4.2. Кодирование видеосигнала
Композитный сигнал в системах PAL и NTSC дискретизируется с частотой 4fц равной четвертой гармонике цветовой поднесущей. В системе NTSC строка содержит 910 элементов, из которых 768 образуют активную часть цифровой строки. В системе PAL на интервал аналоговой строки приходится нецелое число отсчетов с частотой 4fц, и, следовательно, длительность цифровой строки не равна длительности аналоговой. Все строки поля (за исключением двух) содержат по 1135 элементов, а две - по 1137. Скорость передачи цифровых данных в системе NTSC составляет 143 Мбит/с, а в системе PAL - 177 Мбит/с
Более распространенный в последнее время компонентный телевизионный видеосигнал на выходе телекамеры также имеет аналоговую форму. Для его представления в цифровом виде в соответствии с рекомендацией ITU-R 601устанавливаются правила раздельной дискретизации, квантования и кодирования сигнала яркости Y и двух цветоразностных сигналов R-Y (Cr) и B-Y (Cb). Кодирование видеосигнала, также как и рассмотренного ранее звукового, предполагает использование линейной ИКМ. Полоса частот, требуемая для обеспечения заданной пропускной способности, зависит от характеристик канала. В качестве примера рассмотрим кодирование сигнала в режиме линейной ИКМ на видеомагнитофон профессионального цифрового формата магнитной видеозаписи D1. Здесь сигнал яркости и оба цветоразностных сигнала имеют одинаковые полосы частот 3,375 МГц.
Частота дискретизации сигнала яркости fдY выбирается вчетверо большей верхней частоты этого сигнала и равна 4´3,375 МГц = 13,5 МГц. Частоты дискретизации каждого цветоразностного сигнала принимаются вдвое выше верхних частот сигналов, что соответствует 2´3,375 МГц = 6,75 МГц. (Согласно критерию Найквиста fд ³ 2fв). Частоты дискретизации fд связаны с гармониками строчной частоты, что обеспечивает неподвижную ортогональную структуру отсчетов телевизионного изображения. Существенно, что величинам 13,5 и 6,75 МГц кратна как частота строчной развертки стандарта телевизионного разложения 625/50, так и стандарта 525/60. (Собственно, и выбор в качестве базовой именно частоты 3,375 МГц во многом связан с этими соображениями кратности). Указанные обстоятельства позволили ввести единый мировой стандарт цифрового кодирования компонентного видеосигнала, при котором в активной части строки содержится 720 элементов яркостного сигнала и по 360 - каждого цветоразностного. (Системы 625/50 и 525/60 различаются числом строк разложения Z и длительностью гасящих импульсов). Таким образом, соотношение частот дискретизации всех трех компонентов видеосигнала в данном случае (13,5; 6,75 и 6,75 МГц) по отношению к fв выражается как 4:2:2. Поэтому рассматриваемый формат получил название компонентного формата 4:2:2. Записываемый поток видеоинформации в формате 4:2:2 при 8 битовом квантовании составляет (13,5+2´6,75) МГц´8 бит = 216 Мбит/с. При 10 битовом квантовании этот поток расширяется до 270 Мбит/с. (При записи телевизионных программ к нему необходимо добавить соответствующий поток аудиоинформации). Существуют и другие форматы представления компонентного сигнала в цифровом виде. Кодирование по стандарту 4:4:4 предполагает использование частоты 13,5 МГц для всех трех компонентов: R, G, B или Y, Cr, Cb. Это означает, что все компоненты передаются в полной полосе и для каждой из них в активной части кадра оцифровывается 576 строк по 720 элементов. Скорость цифрового потока при кодировании 4:4:4 и 10-битовом слове достигает 405 Мбит/с.
Итак, самый популярный студийный сигнал - цифровое видео D1 (или CCIR 601) использует систему NTSC и может кодироваться цифровым потоком в 270 Мбит/с. Пропускная способность канала рассчитывается и другим способом, исходя из растрового представления. В каждой строке растра содержится 858 точек, в кадре - 525 строк. Имеем по компоненте Y: 858 точек/строку´525 строк/кадр´30 кадр/с´10 бит/точку » 135 Мбит/с. По компонентам R-Y (Cr) и B-Y (Cb) соответственно: 429 точек/ строку´525 строк /кадр´30 кадр/с´10 бит/точку » 68 Мбит/с. Всего получим: 27 млн. точек/с ´ 10 бит/точку = 270 Мбит/с.
Во всех рассмотренных случаях получается очень большой поток данных, который трудно как передавать, так и записывать. Рассмотрим еще один пример. Одна минута цифрового видеосигнала с разрешением SIF (сопоставимым с VHS и равным 288 ´ 358 точек) и цветопередачей в режиме true color, займет: 288´358´24 бита´ 25 кадров/с´60 с = 442 Мб.
Таким образом, не только пропускная способность канала, но и ограничения на память современных носителей (компакт-диска или жесткого диска), не позволяет записать изображение в несжатом виде.
До недавнего времени магнитная лента являлась единственным средством хранения больших массивов видеоинформации. Сейчас ее успешно заменяют оптические носители, и, в первую очередь, оптические диски высокой плотности - DVD (digital versatile disk) и HD-DVD. До появления этих систем различные фирмы самостоятельно боролись с проблемой малых скоростей передачи данных и невысокой емкости носителя, пока не был сформулировано требование - обеспечить 120 мин запись с вещательным качеством. Это требование, поставленное по заказу Голливуда, и привело к появлению системы DVD, а также специальных принципов сжатия видеоинформации. Информация хранится на дорожках дисков в виде последовательности пит - бинарных элементов с разной отражательной способностью. Емкость дисков DVD доведена до 40 Гбайт, допустимая пропускная способность канала составляет 10,08Мбит/с. Заметим, что это значение существенно ниже требуемого, которое составляет для формата D1 - 216 Мбит/с. Указанное обстоятельство означает, что и DVD диски не позволяют воспроизводить видеопотоки в реальном времени. Поэтому, общепринятым решением является кодирование и сжатие изображения.
Устройства DVD используются при развитии цифровых телевизионных систем высокой четкости. Необходимая для этих систем скорость воспроизведения должна составлять 23 Мбит/с. В 2001 г. систему такого рода создала фирма Pioneer на базе голубого полупроводникового лазера с l = 410 ... 450 нм и числовой апертурой оптической системы, равной 0,6. Новые технологии позволили получить и четко считывать питы длиной 0,26 мкм при шаге дорожек 0,44 мкм.
6.5. Форматы хранения изображений в СТЗ
После первых этапов преобразования информации в СТЗ изображение представляет собой дискретный массив точек (пикселей), расположенный либо в памяти устройства ввода, либо непосредственно в памяти СТЗ. В случае полутонового изображения каждый пиксель кодируется 1 … 2 байтами, в зависимости от разрядности АЦП. При формировании цветных изображений первоначальный объем информации, обычно раза в 3 больше. Что же касается записи движущихся объектов, то в большинстве случаев удается сохранить лишь несколько десятков секунд изображения. В СТЗ различают 4 типа изображений - монохромные, полутоновые, а также изображения в естественных цветах и палитровые.
Монохромные или двухградационные (в том числе черно-белые) изображения применяются в простых промышленных СТЗ, системах контроля и т.д., где требуется определить наличие объекта в поле зрения. Монохромное изображение является самым компактным - каждый пиксель кодируется одним битом. Однако хранить и обрабатывать изображения в таком виде неудобно и поэтому битовое представление пикселя преобразуется в байтовое. Наибольшее распространение на практике получили полутоновые изображения. Здесь пиксель также кодируется одним байтом, и его яркость может принимать значения от 0 до 255. В последнее время все чаще приходится работать с цветными изображениями, особенно в таких областях как металлургия, медицина, криминалистика. При сохранении цветного изображения в естественных цветах каждый пиксель представляется в виде RGB-тройки. Для запоминания одного элемента такого изображения требуется 3 байта, что позволяет закодировать в изображении ~ 16,8 106 цветов и оттенков. Этот режим, получивший название True Color, применяется в системах обработки фотографий, репродукций и др. Очевидным недостатком режима True Color является значительный размер массива изображения. Для более компактного хранения цветного изображения разработано палитровое представление. В этом случае, изображению априорно придается цветовая палитра, состоящая из 16 или 256 RGB-троек, с помощью которых косвенно определяются цвета изображения. Один пиксель кодируется 4 или 8 битами, причем числовое значение не прямо определяет цвет элемента, а дает ссылку на цветовую палитру. Подобное упрощение приводит к 3 … 6 кратному уменьшению размера массива, однако в ряде операций обработки изображений возникают цвета, которых не было в исходном изображении. (Поэтому, палитровые изображения также часто приходится преобразовывать в полутоновые или естественные цвета). Палитровое представление используется в компьютерной графике. Что же касается промышленных СТЗ, то большинство из них имеют дело с полутоновым растровым изображением.
Во всех случаях изображения должны быть представлены в максимально компактной и стандартной форме - в виде графического файла. До недавнего времени многие компьютерные фирмы занимались разработкой собственных пакетов обработки изображений, и, соответственно, собственных графических форматов файлов. Сейчас в различных областях компьютерной графики применяются более сотни таких форматов. Тем не менее, несмотря на такое разнообразие форматов все они по способу представления изображений могут быть отнесены к одному из двух типов:
· растровые (точечные);
· векторные.
Растровое изображение представляет собой совокупность отдельных пикселей (расположенных на правильной сетке) записанную в ячейки памяти в виде таблицы (или битовой карты - bitmap). Физический размер ячейки выражается через разрешение (количество пикселей или точек на дюйм - dpi). При представлении изображения на экране монитора разрешение обычно составляет около 100 dpi, для принтера ~ 600, для фотонаборного аппарата более 3500. Главное достоинство растрового представления изображения - простота, приведшая к тому, что практически все устройства ввода изображений поддерживают точечную графику (сканеры, видеокамеры, цифровые фотоаппараты). Существенно и то, что эти графические форматы позволяют получать реалистичные изображения (туман, дымку и т.д.). В то же время растровое представление требует значительных объемов памяти для хранения изображений. Эффективность сжатия файла зависит от сложности изображения. Так, изображение в естественных цветах и большого разрешения сжимается плохо. К недостаткам также относится невозможность трансформации изображений (поворота, масштабирования и т.д.). Поэтому растровые файлы при печати обычно не масштабируются
Исторически термин «растр» (raster) ассоциировался с ЭЛТ и указывал на то, что устройство при воспроизведении изображения на ЭЛТ создает образы строк. Изображения в растровом формате являлись набором пикселей, организованных в виде последовательностей строк развертки.
В векторной графике все изображения описываются в виде совокупности математических объектов - контуров, каждый из которых рассматривается как независимый объект, который можно перемещать и масштабировать до бесконечности. С векторными данными всегда связаны информация об атрибутах (цвете и толщине линии) и набор соглашений (или правил), позволяющий программе начертить требуемые объекты. Эти соглашения могут быть заданы как явно, так и в неявном виде. Они программно-зависимы, несмотря на то, что используются для одних и тех же целей. Векторная графика является объектно-ориентированной. К ее достоинствам относится компактность (т.к. сохраняется не все изображение, а некоторые основные данные). Кроме того, описание цветных характеристик почти не увеличивает размера файла. Однако векторному представлению изображений свойственны и недостатки. Важнейший из них связан с тем, что изображение объекта нереалистично. Кроме того, различные векторные форматы значительно отличаются друг от друга (во всяком случае, в большей степени, чем растровые), т.к. каждый из них проектировался для конкретных целей.
В 70-х годах ХХ века, когда компьютерная графика делала первые шаги, обработка изображений базировалась преимущественно на векторных данных. Векторные экраны и перьевые плоттеры были единственными легкодоступными устройствами вывода. Сегодня изображения чаще всего хранятся и отображаются в растровом виде. Это стало возможным вследствие использования высокоскоростных процессоров, недорогой оперативной и внешней памяти, а также устройств вывода-ввода с высокой разрешающей способностью. Кроме того, изображения, формируемые стандартными видеодатчиками имеют растровую форму.
Большинство существующих графических форматов, строятся на основе растрового или векторного представления изображений, а также на основе их комбинаций. Приведем некоторые примеры.
Наиболее распространенные растровые форматы - PCX, Microsoft BMP, TIFF и TGA; векторные - AutoCAD DXF и Microsoft SYLK. Форматы, содержащие векторные и растровые данные одновременно получили название метафайлов. Самым известным примером является формат Microsoft WMF.
Форматы видеоданных и анимации хранят последовательности изображений - фреймы, каждый из которых может быть как растровым, так и векторным. Самые примитивные из форматов хранят все изображения целиком, более сложные хранят только одно изображение и несколько цветовых таблиц для данного изображения. (После загрузки новой цветовой таблицы цвет изображения меняется и создается иллюзия движения объектов). Еще более сложные форматы анимации хранят только различия между двумя фреймами и изменяют только те пиксели, которые меняются при отображении данного фрейма. Иллюзия плавного движения достигается отображением 20 и более фреймов в секунду. Примерами форматов анимации могут служить TDDD и TTDDD.
Развитием принципов анимации явилось появление мультимедиа-форматов, позволяющих объединять в одном файле графическую, звуковую и видеоинформацию. Примерами служат известные форматы RIFF фирмы Microsoft, QuickTime фирмы Apple, MPEG и FLI фирмы Autodesk.
В формате трехмерного файла хранятся описание формы и цвета объемных моделей воображаемых и реальных объектов. Объемные модели обычно конструируются на основе векторного представления из многоугольников и гладких поверхностей, объединенных с описаниями соответствующих элементов цвета, текстуры, отражений и т.д. Программы визуализации, которые пользуются трехмерными данными - это, как правило, программы моделирования и анимации (например, Lightwave фирмы NewNek и 3D Studio фирмы Autodesk).
6.5.1. Структура графического файла
Графический файл состоит из двух основных частей: заголовка и собственно данных. В начале заголовка стоят несколько числовых значений, которые указывают спецификацию файла (TIF, BMP и т.д.). В англоязычной литературе их называют «магическими числами ».
Все программы обработки изображений различают форматы файлов не по расширениям, а по «магическим числам». Поэтому, в принципе, например, TIF-файлу можно дать любое название, что никак не отразится на возможности его считывания. Исключением из этого правила являются фото-CD файлы, которые не имеют ни магических чисел, ни обычного заголовка.
 За «магическим числом» следует основное содержание заголовка, содержащее общие сведения о файле, в том числе, высоту и ширину изображения, его тип (цветное палитровое/«в искусственных цветах» или монохромное полутоновое/«двухградационное»), с какого места начинаются в файле видеоданные, использовалось ли сжатие данных и т.д. Если файл содержит палитровое изображение, то после заголовка в большинстве случаев (но не всегда!) следует таблица цветов, в соответствии с которой элементам изображения присваиваются значения RGB-троек.
За «магическим числом» следует основное содержание заголовка, содержащее общие сведения о файле, в том числе, высоту и ширину изображения, его тип (цветное палитровое/«в искусственных цветах» или монохромное полутоновое/«двухградационное»), с какого места начинаются в файле видеоданные, использовалось ли сжатие данных и т.д. Если файл содержит палитровое изображение, то после заголовка в большинстве случаев (но не всегда!) следует таблица цветов, в соответствии с которой элементам изображения присваиваются значения RGB-троек.
Далее записываются видеоданные. Способ их хранения зависит от типа изображения и формата файла. Поэтому, создание универсальных программ считывания и записи основных графических форматов является нетривиальной задачей. Данные (структура данных), называемые файловыми элементами, подразделяются на три категории: поля, теги и потоки. Полем называется структура данных в графическом файле, имеющая фиксированный размер. Фиксированное поле может иметь не только фиксированный размер, но и фиксированную позицию в файле. Тег представляет собой структуру данных, размер и позиция которой изменяются от файла к файлу. Поля и теги спроектированы таким образом, чтобы помочь программе обработки изображений получить быстрый доступ к нужным данным. Если позиция в файле известна, то программа получает доступ к ней непосредственно, без предварительного чтения промежуточных данных. Файл, в котором данные организованы в виде потока, не дает таких возможностей и должен читаться последовательно. Поток позволяет поддерживать блоки данных переменной длины. Теоретически могут существовать «чистые» файлы фиксированных полей (содержащие только фиксированные поля), «чистые» теговые и «чистые» потоковые файлы. Однако реально такие файлы большая редкость. Чаще применяются комбинации двух и более элементов данных. Так, известные форматы TIFF и TGA используют и теги, и фиксированные поля, а файлы формата GIF - фиксированные поля и потоки.
 Простейшим способом организации пиксельных значений в растровом файле является использование строк развертки. В таком случае, пиксельные данные в файле будут представлять собой последовательности наборов значений, где каждый набор будет соответствовать строке изображения (рис. 6.37). Несколько строк представляются несколькими наборами, записанными в файле от начала до конца. Этот метод является общим при сохранении данных изображений организованных в строки.
Простейшим способом организации пиксельных значений в растровом файле является использование строк развертки. В таком случае, пиксельные данные в файле будут представлять собой последовательности наборов значений, где каждый набор будет соответствовать строке изображения (рис. 6.37). Несколько строк представляются несколькими наборами, записанными в файле от начала до конца. Этот метод является общим при сохранении данных изображений организованных в строки.
Несмотря на то, что векторные файлы значительно отличаются друг от друга, большинство из них также имеет стандартную базовую структуру (рис. 6.38). Непосредственно векторные данные записываются очень компактно. Так, например, в формате ASCII, три элемента изображения (окружность синего цвета, черная прямая и красный прямоугольник), могут быть записаны следующим образом: «CIRCLE, 40, 100, 100, BLUE»; «50, 136, 227, BLACK»; «RECT, 80, 65, 25, 78, RED». Здесь цифрами обозначены координаты характерных точек (например, центра тяжести) и размеры характерных линий (например, радиуса). Замкнутые линии векторных изображений могут быть заполнены цветом, который, в общем случае, не зависит от цвета контура элемента. Таким образом, каждый элемент изображения связан с двумя или более цветами, один из них задан для контура элемента, а остальные - для заполнения. Цвета заполнения, в частности, могут быть прозрачными. Если не принимать в расчет палитру и информацию об атрибутах, можно сказать, что размер векторного файла прямо пропорционален количеству содержащихся в нем объектов. Это специфическая особенность векторных файлов, поскольку размер растрового файла не зависит от сложности описанного в нем изображения (на него может повлиять только способ сжатия данных).
В завершении приведем краткий обзор основных графических форматов, использующихся в СТЗ. Наиболее простым форматом уже много лет является PCX-формат. Его основное достоинство, связанное с наглядностью представления видеоданных в структуре файла, привело к появлению многочисленных программ обработки изображений именно из PCX-формата. Самым распространенным, пожалуй, является TIF-формат, называемый также теговым форматом. В нем можно хранить все типы изображений и каждая программа обработки должна включать процедуры чтения и записи TIF-файлов. Недостатком TIF-формата является его сложность, что приводит к возникновению проблем со сжатием изображений и совместимостью файлов. Известный формат BMP, разработанный для системы Windows, широко используется в настоящее время в графических системах, хотя и имеет ряд недостатков, связанных с организацией заголовков файлов. Формат TGA (Targa) обеспечивает очень надежное кодирование видеоданных и практически исключает несовместимость между программами. Недостаток этого формата связан с тем, что разрешение изображения в файле не запоминается. Наибольшее число библиотек изображений создано в GIF-формате, разработанном фирмой Compuserve. Его задачей являлось обеспечение максимального сжатия видеоданных при их записи в память. Он эффективен при сохранении палитровых изображений, содержащих максимум 256 цветов в максимально компактной форме.
Видеофайлы часто имеют очень большой объем, и поэтому во всех перечисленных форматах они подвергаются сжатию либо автоматически, либо путем выбора соответствующей функции. Однако, применяемые при этом методы не очень эффективны, особенно если речь идет о записи изображений в естественных цветах. В этом случае весьма полезен формат JPEG, в котором сжатие данных производится методом дискретного косинусного преобразования (ДКП).
Обзор некоторых распространенных форматов хранения изображений в СТЗ представлен в табл. 6.15
Таблица 6.15. Сравнительный анализ некоторых графических форматов
| Название, фирма | Тип изображения | Назначение | Платформа | Общая оценка |
| РСХ (Zsoft Corporation) | Растровое (Bitmap) | Графические редакторы на IBM РС | IBM PC | Хорошо работает при обмене данными в РС-средах, хранит простые изображения, использует схему RLE сжатия данных, но аппаратно зависим |
| BMP/DIB (Microsoft) | Растровое | Хранение и обработка изображений в среде Windows | То же | Стандартный формат для Windows. Аппаратно независим, использует алгоритм RLE сжатия |
| TIFF (Aldus Corporation) | Растровое | Обмен данными в настольных издательских системах | IBM PC, Macintosh, рабочие станции UNIX | Используется для обмена между несвязанными приложениями или платформами, предполагает высокое качество изображения |
| EPS (Adobe Systems и Aldus) | Растровый, Векторный | Обмен данными и их перенос с помощью языка PostScript | То же | Предназначен для создания технологий, позволяющих приложениям работать с PostScript-изображениями |
| JPEG | Сжатый растровый | Хранение и отображение фотографических изображений | То же + аппаратная реализация | Является основным форматом для хранения цифровых фотографий. Качество регулируется Q-фактором (1 -соответствует максимальному сжатию, 100 - минимальному) |
| GIF (CompuServe Incorporated) | Растровое | Передача графических данных в режиме on-line по сети CompuServe | IBM PC, рабочие станции UNIX | Отличный формат для обмена между платформами, хорош для хранения, прост в реализации, использует LZW сжатие. |
| MPEG (ISO) | Движущийся растровый | Компрессия/декомпрессия видео со звуком для multimedia/hypermedia | Независим от платформ, реализуется аппаратно | Использует сложную процедуру покадрового и внутрикадрового сжатия видео и аудио информации в реальном времени, но требует существенной вычислительной мощности |
| DXF | Векторный | Для САПР | Поддерживается всеми САПР-программами, включая AutoCAD |
Примечания.
1. Обозначения:
TIFF - от англ. Tag Image File Format - формат изображения с признаками, EPS - от англ. Encapsulated PоstScript - включающий PоstScript, JPEG - от англ. Joint Photographic Experts Group - объединенная группа экспертов по фотографии, GIF - от англ. Graphics Interchange Format - формат взаимообмена с графикой, MPEG - от англ. Moving Picture Expert Group - группа экспертов по движущимся изображениям, DXF - от англ. Drawing eXchange Format - формат графического обмена.
2. Формат GIF по размеру изображения и глубине цветов подобен PCX, по структуре - TIFF.
3. PostScript - универсальный, не зависящий от платформы язык описания страницы разработан фирмой Adobe Systems.
6.5.2. Сжатие изображений
Одной из важнейших процедур обработки изображений является сжатие. Ее целью является уменьшение физического размера массива данных. В СТЗ применяется сжатие как статических, так и динамических изображений. В первом случае говорят о графических файлах, во втором - о видеоизображениях.
6.5.2.1. Сжатие графических файлов
Сначала рассмотрим наиболее известные принципы сжатия статических изображений. Процедуры сжатия могут встраиваться в спецификацию графического формата или выполняться отдельно. Существует два основных подхода к сжатию изображений: сжатие без потери информации (примерами являются методы Хаффмена, LZW, группового кодирования - RLE и др.) и сжатие с потерей информации (например, дискретное косинусное преобразование - ДКП, JPEG и MPEG). В большинстве спецификаций графических форматов включены процедуры сжатия. Анализ этих процедур показывает, что чаще всего они являются модификациями нескольких базовых методов сжатия, к которым относятся: метод группового кодирования (RLE); метод Лемпела-Зива-Велча (LZW); метод CCITT (один из вариантов этого сжатия является сжатие по алгоритму ДКП, применяемого в формате JPEG), метод фрактального сжатия и ряд других.
Заметим, что сжатие растровых, векторных и метафайловых данных осуществляется по-разному. В растровых файлах сжимаются толькоданные изображения, заголовок и все остальные данные (таблица цветов, концовка и т.п.) всегда остаются несжатыми. При этом несжатые данные занимают очень незначительную часть растрового файла. Векторные файлы обычно не имеют «родной» формы сжатия данных, т.к. в них хранятся математические описания изображения, а не сами данные изображения. Учитывая, что представление данных в компактной форме заложено в основу любого векторного формата, их сжатие дает очень незначительный эффект.
Методы сжатия изображений разделяются на две категории: симметричные и асимметричные.
Симметричные методы используют при сжатии и распаковке примерно одинаковые алгоритмы. Поэтому длительность процедур сжатия и распаковки примерно одинаковы. Такие алгоритмы применяются в программах обмена данными (например, протоколы V42).
При асимметричном сжатии в одном направлении выполняется значительно больший объем работы, чем в другом. Обычно на сжатие затрачивается намного больше времени и системных ресурсов, чем на распаковку. Это имеет смысл, например, если создается база данных изображений - изображения сжимаются для хранения всего однажды, зато распаковываться с целью отображения они могут неоднократно.
Алгоритмы сжатия изображений базируются на модификациях стандартных кодировщиков. Таких программ существует довольно много и они, как правило, специализированные, т.е. созданы специально для обработки данных только определенных типов. Их особенностью является применение процедуры подстановки данных из словаря. Примером подобного алгоритма, получившего название неадаптивного кодировщика, является алгоритм сжатия CCITT. Он содержит статический словарь предопределенных подстрок, о которых известно, что они появляются в кодируемых данных достаточно часто. В отличие от него адаптивный кодировщик не содержит априорных эвристических правил для сжимаемых данных. Адаптивные компрессоры, такие как LZW, не зависят от типа обрабатываемых данных, поскольку строят свои словари полностью из поступивших (рабочих) данных. Они не имеют предопределенного списка статических подстрок, а, наоборот, строят фразы динамически, в процессе кодирования. Наконец, метод полуадаптивного кодирования основан на применении обоих принципов кодирования. Кодировщик работает в два прохода. При первом он просматривает все данные и строит свой словарь, при втором - выполняет кодирование. Этот метод позволяет построить оптимальный словарь прежде, чем приступить к кодированию.
Рассмотрим подробнее некоторые типовые алгоритмы сжатия изображений без потерь информации. Существует два основных подхода; либо оптимизируется кодирование минимального элемента информации - байта, либо удаляется избыточная информация. Представителем первого подхода является метод Хаффмана, второго - метод LZW, разработанный Лемпелем и Зивом и дополненным Велчем, а также групповое кодирование.
В методе Хаффмана сжатие проводится в два этапа. Сначала считываются данные, и определяется частота встречаемости отдельных байтов данных. Затем байты кодируются, причем, наиболее часто встречающиеся значения кодируются меньшим количеством символов. (Например, самое часто встречающееся значение яркости -183 кодируется одним битом, что в 8 раз меньше, чем при использовании стандартной кодовой таблицы). По мере снижения частоты появления значений используются все более длинные слова для их кодирования. В сжатый файл записывается поток битов и информация о том, как этот поток интерпретировать. Этот метод используется, например, при факсимильной передаче. Кодирование по Хаффману неэффективно, если значения данных распределены статистически равномерно.
Групповое кодирование (RLE) - представляет собой алгоритм сжатия данных, поддерживаемый большинством растровых файловых форматов, включая такие популярные как TIFF, BMP и PCX. В СТЗ данный алгоритм имеет также и другое название КДС - кодирование методом длин серий. Алгоритм RLE позволяет сжимать данные любых типов, невзирая на содержащуюся в них информацию. Групповое кодирование уменьшает физический размер повторяющихся строк символов. Такие повторяющиеся строки, называемые группами, обычно кодируются в двух байтах. Первый байт определяет количество символов в группе и называется счетчиком группы. На практике закодированная группа может содержать от 1 до 128 или 256 символов. Второй байт содержит значение символа в группе, которое находится в диапазоне от 0 до 255 и называется значением группы. Например, несжатая символьная группа из 15 символов А обычно занимает 15 байтов:
ААААААААААААААА
После RLE-кодирования та же строка займет всего два байта: 15А. Схемы RLE просты и быстры, но эффективность сжатия зависит от типа данных изображения, подлежащего кодированию. Черно-белые изображения, содержащие значительно больше белого цвета (например, страница книги), кодируются очень хорошо, поскольку включают большие объемы непрерывных данных постоянного цвета. Однако, сложные изображения с большим количеством цветов, типа фотографий, кодируются значительно хуже.
Анализ эффективности алгоритмов сжатия без потерь показывает, что для черно-белых изображений наиболее эффективны модифицированные алгоритмы Хаффмана.
Схема сжатия без потерь Лемпела-Зива-Велча, названная в честь разработчиков LZW-сжатием является одной из наиболее распространенных в компьютерной графике. Этот метод применяется в различных форматах файлов изображений в частности в GIF и TIFF, а также включен в стандарт сжатия для модемов V.42bis и post-Script Level 2. Основой метода явился созданный в 1977 г. А. Лемпелом и Д. Зивом первый компрессор из широко известного семейства архиваторов LZ. В соответствии с алгоритмом первая часть файла передается без сжатия, и кодируются лишь та часть изображения, в которой содержатся уже переданные данные (например, где значения яркости повторяются). Алгоритмы сжатия LZ77 широко использовались для сжатия текста, а также стали основой таких архивирующих программ как ZOO, LHA, PKZIP и ARJ. Алгоритмы сжатия LZ78 часто применялись для сжатия двоичных данных, например, бинарных изображений. В 1984 г. сотрудник фирмы Unisys Т. Велч модифицировал компрессор LZ78 с учетом применения высокоскоростных дисковых контроллеров. Алгоритм LZW относится к алгоритмам, основанным на словарях.
Подведем итоги.
Чем больше количество деталей в изображении, тем хуже оно сжимается. Это характерно для полутоновых изображений и изображения в истинных цветах. Степень сжатия составляет ~5%. Палитровые изображения сжимаются без потерь весьма эффективно, особенно при использовании комбинации LZW и RLE (КДС) методов. В лучшем случае, степень сжатия достигает 50%. В то же время, использование этих методов сжатия иногда приводит к увеличению размера графического файла.
Принципиально другой подход используется в методах сжатия изображений с потерей информации. Он основан на частотном представлении изображения. Действительно, информационное содержание видеосигнала чаще удобно анализировать, не рассматривая его изменение во времени, а раскладывая на частотные составляющие. Тогда, благодаря удалению менее существенных компонент можно упростить запоминание сигнала и, следовательно, уменьшить требуемую емкость памяти. Правда, некоторая часть информации теряется безвозвратно. Наиболее известным способом кодирования с потерей информации является сжатие с помощью ДКП (DCT). ДКП - это общее имя определенного класса операций, на которых базируются различные методы сжатия, в основе которых лежит цифровое частотное кодирование. Для примера рассмотрим процесс сжатия полутонового изображения, состоящего из матрицы байтовых элементов. На первом этапе производится преобразование значений яркости и цвета каждого элемента в частотную область. Для упрощения процедуры изображение разбивается на субматрицы размером 8´8 элементов, в которых определяются частотные составляющие фрагментов. Затем сокращают число этих составляющих, сохраняя только самые существенные, и, наконец, записывают их возможно более компактным способом.
ДКП определяется следующей процедурой:
PDCT = DCT*P*DCTT
Здесь P - блок изображения размером 8´8 элементов, P - блок данных после ДКП, DCT - матрица косинусного преобразования, DCTT - соответствующая ей транспонированная матрица. Знаком * обозначено матричное умножение.
Матрица ДКП имеет вид представленный на рис. 6.39. Для упрощения записи в каждом коэффициенте учтены только три цифры после запятой.

 Процедура ДКП реализуется с помощью последовательности матричных перемножений, поблочно (размер блока 8´8 элементов). Сначала производится умножение видеоданных P на транспонированную ДКП матрицу DCTT, затем результат умножается на собственно матрицу ДКП. Результатом этого преобразования является новая матрица, численные значения элементов которой быстро уменьшаются от левого верхнего угла к правому нижнему (рис. 6.40). Она характеризует распределение частот в видеоданных: в левом верхнем углу размещаются наиболее важные данные. Сжатие выполняется путем устранения менее важных составляющих, для чего проводится квантование преобразованных (частотных) данных. Идея квантования заключается в выборке из матрицы тех составляющих изображения, которые превышают некоторый частотный порог. Выбор правильного порога является отдельной проблемой. Если он будет слишком высоким, то потеряется большая часть видеоданных, хотя и само сжатие будет значительным. Тогда восстановленное изображение будет сильно отличаться от исходного. На практике, можно обеспечить степень сжатия до 80%, прежде чем потери качества изображения будут заметными [ ]. Квантование осуществляется умножением «частотной матрицы» на матрицу делителей, определяемую с помощью алгоритма «делитель - качество». Так, при квантовании «с качеством 2» при котором потери практически незаметны в матрице сохраняется лишь небольшое число ненулевых элементов, значения которых также невелики [ ]:
Процедура ДКП реализуется с помощью последовательности матричных перемножений, поблочно (размер блока 8´8 элементов). Сначала производится умножение видеоданных P на транспонированную ДКП матрицу DCTT, затем результат умножается на собственно матрицу ДКП. Результатом этого преобразования является новая матрица, численные значения элементов которой быстро уменьшаются от левого верхнего угла к правому нижнему (рис. 6.40). Она характеризует распределение частот в видеоданных: в левом верхнем углу размещаются наиболее важные данные. Сжатие выполняется путем устранения менее важных составляющих, для чего проводится квантование преобразованных (частотных) данных. Идея квантования заключается в выборке из матрицы тех составляющих изображения, которые превышают некоторый частотный порог. Выбор правильного порога является отдельной проблемой. Если он будет слишком высоким, то потеряется большая часть видеоданных, хотя и само сжатие будет значительным. Тогда восстановленное изображение будет сильно отличаться от исходного. На практике, можно обеспечить степень сжатия до 80%, прежде чем потери качества изображения будут заметными [ ]. Квантование осуществляется умножением «частотной матрицы» на матрицу делителей, определяемую с помощью алгоритма «делитель - качество». Так, при квантовании «с качеством 2» при котором потери практически незаметны в матрице сохраняется лишь небольшое число ненулевых элементов, значения которых также невелики [ ]:
Полученные значения можно экономно запомнить, применяя, например, кодирование по Хаффману. Если установить зигзагообразную траекторию обхода коэффициентов, то можно получить очень длинную непрерывную последовательность из 26 нулей.
Восстановление сжатого изображения производится обратным ДКП. При этом все шаги выполняются в обратном порядке.
 ДКП является очень эффективным способом сжатия. При его использовании необходимо в изображении выделить яркостную и цветовую компоненты. Поэтому если изображение представлено в цветовых моделях RGB или CMYK, его следует преобразовать в одну из аппаратно-независимых моделей - HSV или YUV. Яркостную информацию сжимают непосредственно, а цветовую с помощью ДКП. Следовательно, и палитровые изображения с помощью ДКП также не сжимаются. Это связано с тем, что в них цвет пикселей представлен не непосредственно, а лишь через индексы в таблице цветов. Поэтому палитровые изображения тоже необходимо преобразовать в форму HSV или YUV моделей, что оправданно лишь в редких случаях.
ДКП является очень эффективным способом сжатия. При его использовании необходимо в изображении выделить яркостную и цветовую компоненты. Поэтому если изображение представлено в цветовых моделях RGB или CMYK, его следует преобразовать в одну из аппаратно-независимых моделей - HSV или YUV. Яркостную информацию сжимают непосредственно, а цветовую с помощью ДКП. Следовательно, и палитровые изображения с помощью ДКП также не сжимаются. Это связано с тем, что в них цвет пикселей представлен не непосредственно, а лишь через индексы в таблице цветов. Поэтому палитровые изображения тоже необходимо преобразовать в форму HSV или YUV моделей, что оправданно лишь в редких случаях.
Теперь рассмотрим некоторые особенности спецификации JPEG. На сегодняшний день JPEG является одним из наиболее актуальных направлений развития технологии сжатия изображений. Принцип JPEG-кодирования также не является одним алгоритмом сжатия; он может рассматриваться как набор методов сжатия, пригодных для удовлетворения нужд пользователя. В основе JPEG лежит схема ДКП кодирования (рис. 6.41).
Аббревиатура JPEG происходит от названия комитета по стандартам Joint Photographic Experts Group (дословно - объединенная группа экспертов по фотографии), входящего в состав Международной организации по стандартизации (ISO). В 1982 году ISO сформировала группу экспертов по фотографии (PEG), возложив на нее обязанности по проведению исследований в области передачи видеосигналов неподвижных изображений и текстов по каналам ISDN (интегральной цифровой сети связи). В 1987 году PEG и CCITT объединили свои группы в комитет, который должен был провести исследования и выпустить один стандарт сжатия данных. Новый комитет получил название JPEG.
Схема JPEG была специально разработана для сжатия цветных и полутоновых (т.е. многоградационных) изображений - фотографий и другой сложной графики. При этом анимация, черно-белые иллюстрации и документы, а также типичная векторная графика, как правило, сжимаются плохо. Практически JPEG хорошо работает только с изображениями, имеющими глубину хотя бы 4 … 5 битов на цветовой канал.
Алгоритм JPEG преобразует каждый компонент цветовой модели отдельно, что обеспечивает его полную независимость от любой модели цветового пространства (например, от RGB, HSI или SMY). Лучшая степень сжатия достигается в случае применения цветового пространства YUV или YCbCr. Спецификация на JPEG файлы показывает, что это расширение позволяет хранить одно и то же изображение с разными разрешениями в порядке иерархии. Так, изображение может быть сохранено с разрешениями 250´250, 500´500, 1000´1000 и 2000´2000 пикселей (что позволяет поддерживать его отображение на экранах мониторов с низким разрешением, лазерных принтерах среднего разрешения и на высококачественных устройствах печати). Степень сжатия изображения с фотографическим качеством может составить от 20:1 до 25:1 без заметной потери качества. Регулирование качества кодировщика JPEG осуществляется с помощью Q-фактора. В различных программах обработки изображений используются разные диапазоны изменения Q-фактора, но типичные значения находятся в диапазоне 1... 100. При Q = 100 сжатие мало: изображение будет иметь значительный размер, но высокого качества. Оптимальное значение Q-фактора зависит от содержимого изображения и подбирается индивидуально.
Отметим, что JPEG не всегда является лучшей схемой сжатия, т.к. она не удовлетворяет всем возможным потребностям в сжатии. Например, изображения, содержащие большие области одного цвета, сжимаются плохо. JPEG вводит в такие изображения артефакты, особенно заметные на сплошном фоне. Кроме того, JPEG сжатие весьма медленно. В настоящее время этот метод реализуется также и аппаратно.
Компоненты цветности в JPEG кодируются методом субдискретизации. Суть этого подхода, заключающегося в уменьшении количества пикселей для каналов цветности, основана на меньшей чувствительности глаза к цветовой информации. Например, при сохранении цветного изображения размером 1000´1000 пикселей можно использовать все 1000´1000 пикселей яркости, но только 500´500 пикселей для каждой компоненты цветности. При таком представлении каждый пиксель цветности будет охватывать ту же область, что и блок 2´2 пикселей яркости. Следовательно, для кодирования блока 2´2 требуется всего 6 пиксельных значений (4 значения яркости и по 1 значению для каждого канала цветности U и V). В несжатом виде такой блок требует 12 пиксельных значений (4 + 4 + 4). Существенно, что уменьшение объема данных на 50% практически не отражается на качестве большинства изображений.
Таким образом, при сжатии изображения в цветовой модели YUV яркостную компоненту Y (также как и полутоновые изображения) сжимают непосредственно. Информация о цвете U и V в соседних элементах изображения объединяется. Так, при субдискретизации 4:2:2 производится суммирование значений U и V для четырех соседних элементов, а запоминается только среднее значение. Тогда, даже несжатый по яркости, но субдискретизированный по цвету массив из 4-х элементов изображения будет представлен 6 байтами, что соответствует 12 (48:4) битам на элемент. Уже при этом достигается 50% сжатие информации. Еще более высокая степень сжатия достигается при субдискретизации 4:1:1, когда объединяются значения восьми соседних элементов. Благодаря этому количество данных на элемент изображения сокращается с 24 до 10 бит. Сжатие достигает 58%, хотя уже становятся заметными некоторые цветовые искажения. Большее сжатие применяют только для подвижных изображений. Стандарт JPEG предлагает несколько различных вариантов определения коэффициентов дискретизации, или относительных размеров каналов субдискретизации. Канал яркости всегда остается с полным разрешением (дискретизация 1:1). Для обоих каналов цветности обычно производится субдискретизация 2:1 в горизонтальном направлении и 1:1 или 2:1 - в вертикальном. При этом подразумевается, что пиксель цветности будет охватывать ту же область, что и блок 2´1 или 2´2 пикселей яркости. Согласно терминологии JPEG, эти процедуры называются 2hlv и 2h2v-дискретизацией соответственно.
В последние годы в СТЗ используется также и фрактальное сжатие изображений. Фрактальное кодирование - это математический процесс, применяемый для кодирования растров, которые содержат реальное изображение, в совокупность математических данных, которые описывают фрактальные свойства изображения. Фрактальное кодирование (наиболее известен формат FIF) основано на том факте, что все естественные и большинство искусственных объектов содержат избыточную информацию в виде одинаковых, повторяющихся рисунков, которые называются фракталами. Фрактальное представление подобно векторной двухмерной и объемной графике оперирует математическими описаниями объектов, а не их реальными изображениями. Существенное различие между векторной и фрактальной графикой состоит в том, что фрактальные описания выводятся из реальных изображений объектов, тогда как векторные - это чисто искусственные структуры. Фрактальное кодирование изображения требует исключительно большого объема вычислений, включающего миллионы и даже миллиарды итераций. Декодирование фрактального изображения процесс гораздо более простой, так как вся трудоемкая работа была выполнена при поиске всех фракталов во время кодирования. В процессе декодирования нужно лишь интерпретировать фрактальные коды, преобразовав их в растровое изображение. Фрактальное представление имеет два существенных достоинства. Во-первых, фрактальное изображение можно масштабировать без введения артефактов и потери деталей, как это характерно для растровых изображений. Во-вторых, размер физических данных, используемых для записи фрактальных кодов, значительно меньше (более чем в 100 раз) размера исходных растровых данных. Именно этот аспект фрактальной технологии, называемый фрактальным сжатием, вызвал наибольший интерес в сфере формирования и воспроизведения компьютерных изображений.
Рассмотренные методы сжатия изображений с потерей информации по своему характеру несимметричны, т.к. сжатие длится гораздо дольше, чем распаковка.
В завершении приведем результаты сравнительного анализа некоторых известных графических форматов (табл. 6.16).
Таблица 6.16 . Степень сжатия базового изображения в некоторых форматах
| Параметры изображения: 640´480´24 | |||
| Сжатие без потерь | Сжатие с потерями | ||
| Формат | Размер (байты) | Формат | Размер (байты) |
| BMP | 921656 | JPEG (Q=0) | 26591 |
| IFF | 751138 | JPEG (Q=5) | 45734 |
| PCX | 789801 | JPEG (Q=8) | 83256 |
| PNG | 310827 | JPEG (Q=10) | 114171 |
| PNG-Adaptive | 261427 | FIF (Q=65) | 15074 |
| TGA-24 | 24921644 | FIF (Q=85) | 24740 |
| TIFF-LZW | 303976 | FIF (Q=90) | 31952 |
| TIFF | 929472 | FIF (Q=100) | 172542 |
| GIF87 (8-bit) | 141458 |
Подведем некоторые итоги. Простой способ получения графического файла заключается в использовании известной процедуры Print Screen. Полученный экранный кадр хорошо сжимается методом КДС (в формат РСХ), и LZW (в форматы GIF и TIF). Палитровое изображение методом КДС не сжимается совсем. Его лучше сохранять в форматах GIF и TIF (т.е. использовать LZW-метод). Метод JPEG для палитровых изображений неэффективен. Полутоновое изображение плохо сжимается и КДС и LZW методами. TIF-формат позволяет запоминать со сжатием изображение в истинных цветах (известных как True Color).. С этой целью целесообразно использовать LZW-метод. Методы JPEG-сжатия эффективны и для полутоновых изображений и для изображений в истинных цветах. Но поскольку цветовая информация сжимается лучше (особенно при использовании субдискретизации), коэффициенты сжатия для полутоновых изображений оказываются меньшими, чем для True Color изображений, но большими, чем при сжатии без потерь (КДС и LZW).
6.5.2.2. Сжатие видеоизображений
Как известно, видеосигнал состоит из нескольких различных сигналов, объединенных в единое целое. Эта комбинация, называемая композитным видеосигналом редко используется в компьютерном видео. Чаще всего композитный (составной) видеосигнал перед оцифровкой разделяется на базовые компоненты. В «живом» видео применяются цветовые модели YUV, YIQ и YCbCr, позволяющие существенно уменьшить объем данных без ущерба для качества изображения. При анализе подвижных изображений оперируют кадрами или фреймами. Один фрейм видеоданных обычно имеет значительный размер, так, для разрешения 512´482 он будет содержать 246784 пикселя. Если каждый пиксель кодируется 3 байтами, то для хранения этого фрейма потребуется 740352 байта памяти. Следовательно, объем памяти, необходимый для хранения 10-секундной видеопоследовательности при скорости воспроизведения 30 фреймов в секунду составит более 220 Мбайт. Для обеспечения эффективной работы с такими массивами изображений в реальном масштабе времени были созданы программные кодеки и спецификация MPEG (динамический или Motion JPEG - Motion Picture Expert Group). Данная спецификация, разработанная экспертной группой ISO (официальное название - ISO/IEC JTC1 SC29 WG11), предназначена для формирования стандартов кодирования и сжатия видео- и аудио-данных. На сегодняшний день известны:
· MPEG-1, созданный для записи изображений (обычно в формате SIF, 288´358) и звукового сопровождения на CD-ROM с учетом максимальной скорости считывания ~1,5 Мбит/с. Качественные параметры видеоданных в этом формате во многом аналогичны стандарту VHS-видео.
· MPEG-2, предназначенный для обработки видеоизображений телевизионного качества при пропускной способности канала передачи данных 3 … 15 и до 50 Мбит/с. Технология MPEG-2 применяется в телевещании, спутниковом телевидении и т.д. Благодаря специальной процедуре сжатия полоса частот для передачи одного канала сокращается на 90%, что позволяет, например, по кабельной сети передавать в 10 раз больше программ.
· MPEG-3, разработанный для телевизионных систем высокой четкости (high-defenition television, HDTV) со скоростью потока данных 20 … 40 Мбит/с. Позже он стал частью стандарта MPEG-2 и отдельно теперь не упоминается. (Известный формат MP3 - MPEG-Audio Layer-3, не имеющий отношения к MPEG-3, предназначен только для сжатия аудиоинформации).
· MPEG-4, задающий общие правила работы с цифровыми видео- и аудиоданными для интерактивного мультимедиа, графических приложений и цифрового телевидения.
Принцип действия MPEG систем основан на сжатии изображений методами субдискретизации и ДКП. Так, рассматривая тот же пример с фреймом 512´482 и используя процедуру субдискретизаци 4:1:1, получим поток данных размером 512´482´30´10/8 байт = 9,25 Мбайт/с. Обычно, степень сжатия при подобном внутрифреймовом кодировании колеблется в пределах от 20:1 до 40:1, что зависит от содержимого фрейма. Однако если рассматривать не отдельно взятый фрейм (неподвижное изображение), а совокупность таких фреймов, то можно достичь и более высокой степени сжатия. Действительно, в обычной видеопоследовательности различия между фреймами весьма незначительны. Если же кодировать только те пиксели, которые отличают один фрейм от другого, то объем данных, необходимых для хранения каждого фрейма значительно уменьшится. Этот тип сжатия получил название межфреймового или дельта-сжатия. Так, типичные схемы компенсации движения могут обеспечить степень сжатия 200:1 и выше. Один из подобных способов компрессии, называемый GOP (Groupe of Picture) используется в стандарте MPEG-2. В соответствие с алгоритмом GOP видеосигнал разбивается на три группы кадров:
· I-кадр, Intra frame - начальный (исходный) кадр группы, содержащий полную нескомпенсированную информацию о всех деталях изображения. Эти кадры кодируются только с применением внутрикадрового сжатия по алгоритмам, аналогичным JPEG;
· P-кадр, Predictive frame - вычисленный (предсказуемый) кадр, содержащий только информацию об изменениях, по сравнению с предыдущими кадрами. Обработка таких кадров производится с использованием предсказания вперед: кадр разбивается на макроблоки 16´16 пикселей, каждому макроблоку ставится в соответствие наиболее похожий участок изображения из опорного кадра. Это наиболее скомпенсированный кадр, степень сжатия которого превышает возможную для I-кадров в 3 раза.
· B-кадр, Bi-directional frame - кадр, использующий для своего восстановления при воспроизведении информацию как предыдущего, так и последующего кадров. Он кодируются одним из четырех способов: предсказанием вперед; обратным предсказанием, двунаправленным и внутрикадровым предсказанием.
Видеоинформация кодируется последовательностью из 15 кадров, которая имеет следующий вид: I-B-B-P-B-B-P-B-B-P-B-B-P-B-B-I. В этой последовательности I-кадр, начинающий каждую новую группу, является ключевым, поскольку содержит полную информацию об изображении. B и P кадры получаются в предположении, что различия между I-кадрами не слишком велико. Подобное представление весьма эффективно для большинства видеосюжетов. Однако на практике встречаются динамичные сцены, которые приходится кодировать более короткими группами. Кроме того, сюжет может быть насыщен фрагментами, кодирование которых возможно лишь с ухудшением качества. К ним относятся бури, молнии, мелкие детали и т.п.
Решение этой проблемы двояко. Можно временно увеличить поток информации или же применить специальную обработку этих кадров. Оба этих подхода предусмотрены стандартом MPEG-2. (При длительности фильма свыше 120 мин в большинстве случаев применяют кодирование с переменной скоростью). Во всех случаях в процессе кодирования и обработки велико влияние «человеческого фактора».
6.6. Базовые алгоритмы обработки изображений
Одной из наиболее быстро развивающихся областей техники является направление, связанное с обработкой визуальных данных. В настоящее время существуют десятки коммерческих пакетов обработки статических и динамических изображений (фотографий, видеофильмов, текстов и др.). В этом секторе работает много крупных фирм, в том числе Adobe Systems Inc, (США), ABBYY (Россия) и т.д. Существующие системы контроля доступа используют программы распознавания лиц, отпечатков пальцев и радужной оболочки глаза. Также известны системы распознавания номеров транспортных средств, штрих-кодов и пр. Многие из этих программ функционируют в реальном масштабе времени, выполняя все необходимые процедуры в темпе поступления данных. Часто это требует реализации ряда алгоритмических функций аппаратными средствами.
Все рассмотренные системы относятся к классу СТЗ.
Проблема зрительного восприятия уже много лет будоражит ученые умы. Большой вклад в ее решение внес Г. Гельмгольц, чей трактат по физиологии зрения, актуален до сего времени. Активные исследования процедур обработки изображений начались в начале XX века. Одной из первых в этом ряду была работа Л. Вертхеймера, обнаружившего, что при восприятии движущегося изображения, оно представляется не как совокупность отдельных точек, а как целостная структура. (Аналогией здесь является стая птиц, воспринимаемая как единое целое, в котором отдельные птицы не различаются). В результате подобных исследований, была обнаружена зрительная кора головного мозга, ответственная как за получение изображения, так и его интерпретацию. Элементы зрительной коры были локализованы к концу 50-х годов ХХ века, однако некоторые ее функции еще не нашли объяснения до настоящего времени. В те же годы делаются первые попытки построения алгоритмов обработки изображений и распознавания образов. Эти алгоритмы, созданные в нейрофизиологических лабораториях и сейчас весьма популярны, хотя их компьютерные реализации либо узкоспециализированы, либо весьма ненадежны.
С позиций бионики, зрение - это процесс, порождающий по изображениям внешнего мира некоторое описани, не перегруженное существенной информацией. Полезность некоторого описания (представления) зависит от того, насколько хорошо оно соответствует цели, для достижения которой используется. Характерным примером является представление, сформированное сетчаткой. У многих животных оно имеет мало общего с реальным изображением. Так, рецепторы сетчатки лягушки определяют только движущиеся объекты; сетчатка некоторых пауков (аттидов), состоящая из двух диагональных полос в виде буквы «V », позволяет отличить потенциальную добычу от потенциального брачного партнера, имеющего такой узор на спине. Зрительная система кролика может быть названа «детектором мелких хищных птиц» (поскольку безошибочно реагирует на перемещающиеся вверху небольшие объекты). Особенно интересен с этой точки зрения орган зрения мухи, который непосредственно связан с ее системой управления. Управление полетом мухи осуществляется с помощью пяти независимых, очень быстродействующих и жестко запрограммированных подсистем. Одна из этих подсистем управляет посадкой: если приближающаяся поверхность стремительно расширяется, муха автоматически устремляется на посадку в ее центр. Система управления горизонтальным движением предназначена для отслеживания объектов, имеющих определенные угловые размеры. В соответстви с ее алгоритмом будет дана команда на перехват другой мухи, находящейся на удалении в нескольких сантиметров, но не на «перехват» слона, расположенного в полукилометре.
В настоящее время доказано, что при обработке визуальной информации зрительный аппарат животных и людей широко использует операторные принципы, в соответствие с которыми над массивом элементов, образующих изображение, выполняются некоторые типовые процедуры (фильтрация, дифференцирование и др.). Кроме того, и сам этот массив представляет собой совокупность не точек, а фрагментов, включающих отрезки границ, текстуры и т.д. Попытки описать эти процедуры привели к появлению оригинальных моделей (операторы Хюкеля и Робертса, алгоритм интерпретации изображения по граням, ребрам и затененным областям Уолша), широко используемым в СТЗ.
Иерархия информационных процессов при описании изображения может быть грубо представлена в виде трех уровней:
· представление характеристик двухмерного изображения (типа изменений значений яркости и локальных геометрических свойств);
· представление характеристик видимых поверхностей (ориентации, отражающей способности, расстояния) в системе координат наблюдателя;
· представление трехмерной структуры (в сочетании с какими-либо свойствами поверхности) в системе координат объекта.
Наибольшего успеха удалось достичь в исследовании первого уровня описания. Физиологи обнаружили визуальные каналы, обладающие избирательностью по ориентации и пространственной частоте. На основании этих результатов была предложена операторная модель, в которой каждая точка поля зрения содержит четыре настраиваемых на пространственный размер фильтра (маски), предназначенных для анализа изображения. Размер маски, соответствующей каналу, растет линейно с увеличением эксцентриситета (углового расстояния от центральной ямки). В порядке увеличения размера маски каналы называются N, S, T и U. Канал S обладает наибольшей чувствительностью как по отношению к тонической (амплитудной), так и фазной стимуляции, канал U - наименьшей. Размеры рецептивных полей составляют: 3,1’ (для канала N - это примерно 9 колбочек центральной ямки), 6,2’ (канал S), 11,7’ (канал T), 21’(канал U).
 Алгоритмическую основу каналов образуют Ñ2G-фильтры (рис. 6.42). Оператор Ñ2G аппроксимирует полосовой фильтр шириной 1,25 октавы, соответствующей половине энергии спектра. Обозначено: Ñ2 - оператор Лапласа (Ñ2 = ¶2/¶x2 + ¶2/¶y2), а символ G обозначает распределение Гаусса:
Алгоритмическую основу каналов образуют Ñ2G-фильтры (рис. 6.42). Оператор Ñ2G аппроксимирует полосовой фильтр шириной 1,25 октавы, соответствующей половине энергии спектра. Обозначено: Ñ2 - оператор Лапласа (Ñ2 = ¶2/¶x2 + ¶2/¶y2), а символ G обозначает распределение Гаусса:
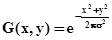
Ñ2G фильтр обладает двумя существенными свойствами. Во-первых, он реализует дифференциальный оператор, вычисляющий первую и вторую пространственную производную изображения, что позволяет четко выделять границы. (Именно в контуре изображения содержится большая часть информации об объекте; по оценкам физиологов - до 90%). Во-вторых, он допускает настройку на разных масштабных уровнях, что позволяет обнаруживать границы на размытых участках на больших фрагментах изображения и обнаруживать малые элементы изображения на его хорошо сфокусированных участках. Физиологическая реализация Ñ2G-фильтра основана на взаимодействии возбуждающих и тормозящих функций, реализуемых центральной и периферической областями рецептивных полей.
Алгоритмическое обеспечение СТЗ можно условно представить в виде двух групп алгоритмов, выполняющих функции:
· обработки изображений;
· анализа визуальных образов.
Если СТЗ содержит алгоритмы исключительно первой группы, то, согласно приведенной ранее классификации, ее можно отнести к СТЗ нижнего и среднего уровня.
Сущность обработки изображений заключается в приведении исходного изображения сцены к виду, достаточного для его распознавания. Сюда относятся многочисленные процедуры формирования и улучшения изображения (включающие компенсацию оптических помех и сглаживание), бинаризация, получение контурного представления изображения, выделение элементов сцены и определение их признаков. Конечной целью обработки изображений в СТЗ является подготовка объектов сцены к распознаванию, т.е. отнесению их к некоторым заранее заданным классам. Несмотря на многообразие представленных процедур, обработка изображений в СТЗ разбивается на три основные этапа:
· ввод и предварительная обработка изображения;
· сегментация;
· описание.
В свою очередь, этап предварительной обработки изображений принято разделять на две базовых процедуры: формирование изображения и его кодирование (сжатие). При этом кодирование, в зависимости от вида сцены, может проводиться как до, так и после сегментации. В частности, для сцен, содержащих несколько объектов, сегментация предшествует кодированию. Для удобства представим базовые процедуры обработки изображений в виде табл. 6.17.
Таблица 6.17. Этапы обработки изображений
| Обработка изображений | ||
| 1 | Ввод изображения (восприятие) | |
| 2 | Предварительная обработка: | Формирование Кодирование |
| 3 | Сегментация | |
| 4 | Описание |
6.6.1. Предварительная обработка изображений
Все методы предварительной обработки изображений можно подразделить на пространственные и частотные.
 Пространственные методы обработки являются процедурами, оперирующими непосредственно с пикселями изображения. В общем виде, функции предварительной обработки в пространственной области записываются в виде выражения:
Пространственные методы обработки являются процедурами, оперирующими непосредственно с пикселями изображения. В общем виде, функции предварительной обработки в пространственной области записываются в виде выражения:
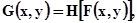
где F (x, y) и G (x, y) - соответственно изображение на входе и выходе преобразователя, H – оператор (функция преобразования). В качестве характеристики изображения используется яркость L(x, y).
Частотные методы обработки связаны с переводом изображения в комплексную плоскость с помощью преобразования Фурье.
Первый этап предварительной обработки представляет собой формирование изображения. Формированием изображения называется процедура непосредственного получения изображения в виде массива дискретных элементов - пикселей, образующих матрицу или контур и расположенного в памяти видеопроцессора. Пример изображения некоторого (тестового) объекта G(x, y) представлен на рис. 6.43.
На этапе формирования изображения в СТЗ производится его фильтрация, т.е. аппаратная или программная компенсация оптических помех и сглаживание дискретного изображения, а также выделение контуров - краев и линий. (Как уже отмечалось во введении, до 90% всей информации об изображении содержится в его контуре).
Основные этапы формирования изображений приведены в табл. 6.18.
Таблица 6.18. Этапы формирования изображений
| Формирование изображений | ||
| 1 | Выбор порога яркости (улучшение) | |
| 2 | Фильтрация | Компенсация помех Сглаживание |
| 3 | Выделение контуров | |
| 4 | Бинаризация |
Преобразование цифрового изображения L(m, n) на этапе выделения контуров значительно уменьшает объем визуальной информации - обычно передаются только координаты и яркость элементов, относящихся к границам перепадов яркости. Величина этого перепада задается относительно некоторого значения яркости, называемого порогом.
 Рассмотрим некоторые особенности выбора порога яркости. Качество изображения в СТЗ сильно зависит от освещенности рабочей сцены. Если она занижена, то увеличивается количество помех на изображении (вплоть до потери объекта), при очень сильной освещенности происходит засветка изображения (и опять же потеря объекта). В современных СТЗ предусмотрены средства автоматической адаптации при изменении освещения, получившие название систем автоматической регулировки освещения. Использование этих средств позволяет компенсировать некоторые помехи, в частности, блики и тени.
Рассмотрим некоторые особенности выбора порога яркости. Качество изображения в СТЗ сильно зависит от освещенности рабочей сцены. Если она занижена, то увеличивается количество помех на изображении (вплоть до потери объекта), при очень сильной освещенности происходит засветка изображения (и опять же потеря объекта). В современных СТЗ предусмотрены средства автоматической адаптации при изменении освещения, получившие название систем автоматической регулировки освещения. Использование этих средств позволяет компенсировать некоторые помехи, в частности, блики и тени.
Наиболее известный способ улучшения изображения предполагает программную (покадровую) регулировку яркости и контрастности вводимого изображения. Для каждого кадра строится гистограмма распределения яркости изображения L(x, y) (рис. 6.44), и вычисляются ее параметры: математическое ожидание (среднее значение) и дисперсия. На рисунке обозначено n - количество пикселей L(x, y) - яркость.
 Каждая точка гистограммы определяет, какое количество пикселей на изображении имеет данное значение яркости. При этом среднее значение гистограммы определяет общую яркость изображения, а дисперсия (размах гистограммы) - его контрастность. Иногда вместо гистограммы распределения яркости используется функция плотности вероятности P(Ln) нормированного значения яркости Ln [0,1] (рис. 6.45).
Каждая точка гистограммы определяет, какое количество пикселей на изображении имеет данное значение яркости. При этом среднее значение гистограммы определяет общую яркость изображения, а дисперсия (размах гистограммы) - его контрастность. Иногда вместо гистограммы распределения яркости используется функция плотности вероятности P(Ln) нормированного значения яркости Ln [0,1] (рис. 6.45).
Обычно перед началом работы производится настройка уровня освещенности по гистограмме изображения. Данная процедура является рекуррентной. Вычисленные параметры гистограммы распределения яркости текущего кадра сравниваются с оптимальными - определенными заранее экспериментальным путем; после чего соответствующим образом изменяются значения регистров фреймграббера. Затем считывается следующий кадр, снова строится гистограмма, вычисляются ее параметры и т.д. Так продолжается до тех пор, пока отклонение текущего среднего значения и дисперсии от оптимума не становится меньше некоторой заранее заданной величины (например,10 %). В этом случае, настройка заканчивается, и управление передается основной части программы.
Коррекция гистограммы дает общее улучшение качества на всем поле изображения. Для улучшения изображения малых участков указанный подход применяют к некоторой окрестности изображения. Тогда, для каждого пикселя строится гистограмма точек данной окрестности, которая используется для отображения яркости пикселя, расположенного в центре выбранной окрестности. Далее центр перемещается на соседний пиксель, и вся процедура повторяется снова.
Процедура бинаризации, т.е. преобразования полутонового изображения в бинарное, может проводиться непосредственно после гистограммного улучшения с помощью гистограммы полутонов. Так, если в изображении представлены светлые объекты на темном фоне гистограмма будет двухмодальной - яркости пикселей объектов и фона образуют две области. Бинаризованное изображение тестового объекта приведено на рис. 6.46. Для отделения объекта от фона выбирается пороговое значение яркости Lпор, которое разделяет эти области.  Любая точка изображения с яркостью L(x, y) > Lпор принадлежит объекту, а в противном случае - фону. Выходное бинаризованное изображение D(x, y) содержит лишь две градации яркости: 0 или 1, причем:
Любая точка изображения с яркостью L(x, y) > Lпор принадлежит объекту, а в противном случае - фону. Выходное бинаризованное изображение D(x, y) содержит лишь две градации яркости: 0 или 1, причем:
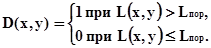
Таким образом, на изображении D(x, y) пиксели со значением 1 принадлежат объектам, а пиксели со значением 0 - фону.
Фильтрация изображения является, пожалуй, наиболее длительной и сложной стадией предобработки. На данный момент, в мире существует огромное количество различных способов фильтрации и у каждого есть свои достоинства и свои недостатки. В общем случае, фильтрация решает следующие основные задачи:
· «сглаживание» или подавление высокочастотной помехи (типа «снег»);
· повышение контрастности;
· выделение контура.
Как известно, на начальных этапах преобразования на изображение действуют аппаратурные помехи, искажающие функцию распределения интенсивности света L(x, y). (Сюда относятся искажения, вносимые оптикой, дискретизацией по полю из-за отдельного расположения ячеек светочувствительной поверхности и неоднородностью их фотоэлектрических характеристик и т.д.). Фильтрация помех - сглаживание чаще всего проводится после получения цифрового изображения, и смысл ее заключается в усреднении (по определенному правилу) значения функции L(m, n) внутри небольшого анализируемого фрагмента (программного окна), сканирующего изображение.
 Обычно спектр визуальных помех содержит более высокие пространственные частоты, чем спектр изображения. Для их устранения используется фильтр нижних частот, подавляющий высокие частоты (при этом ухудшается резкость изображения).
Обычно спектр визуальных помех содержит более высокие пространственные частоты, чем спектр изображения. Для их устранения используется фильтр нижних частот, подавляющий высокие частоты (при этом ухудшается резкость изображения).
В отличие от него, фильтр верхних частот оставляет без изменения высокие частоты и сглаживает области, содержащие мало деталей. Примеры высоко и низкочастотной фильтраций тестового объекта показаны на рис. 6.47.
В большинстве случаев, сглаживающие фильтры апроксимируются выражениями вида:
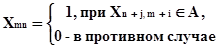
 Данная запись означает, что пикселю с номером (m, n) присваивается значение «1», если соседние пиксели, лежащие в некотором программном окне, принадлежат изображению объекта A.
Данная запись означает, что пикселю с номером (m, n) присваивается значение «1», если соседние пиксели, лежащие в некотором программном окне, принадлежат изображению объекта A.
Большинство фильтров используют методы пространственной области, т.к. оперируют с некоторой окрестностью точки. Данная окрестность называется апертурой фильтра и бывает, как правило, квадратной или прямоугольной формы (рис. 6.48). Используются также и другие апертуры, например круг, крест и пр. Однако квадратная апертура является наиболее предпочтительной из-за простоты ее реализации. Размер программного окна, как правило, составляет (3´3) или (5´5) пикселей.
Если в функции фильтра значение центрального пикселя апертуры не учитывается, то такая апертура называется выколотой.
Обычно, фильтрация изображения осуществляется путем последовательного (построчного) сканирования апертурой выбранного фильтра. При достижении конца строки центр апертуры перемещается на начало новой, и все повторяется до тех пор, пока не будет достигнут конец массива.
Степень сглаживания изображения целиком определяется апертурой фильтра. Чем больше размер апертуры, тем выше степень сглаживания изображения. Однако с увеличением размерности апертуры N растет и время обработки - пропорционально N2.
Среди линейных методов фильтрации наибольшее распространение получили методы порогового сглаживания, анизотропной и рекуррентной фильтрации.
Метод порогового сглаживания является одним из простейших. Он основан на сканировании цифрового изображения программным окном (апертурой) размерностью N´N (N = 3, 5 или 7) и вычислении на каждом шаге значения средней яркости Lср группы элементов:
 ,
,
здесь lij - элементы функции яркости L(m, n), N - количество пикселей в окрестности точки (m, n).
Далее, значение средней яркости Lср сравнивается со значением яркости центрального элемента сканирующего окна lij, и в случае, если lij > Lср+eL, где eL - заданное пороговое значение, то вместо lij анализируемому элементу приписывается значение Lср.
Так, при сканировании массива изображения квадратной апертурой размерностью 3´3, яркость центрального пикселя изображения (точку e) можно определить из выражения:
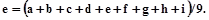
Часто используется выколотая квадратная апертура размерностью 3´3 (это связано с тем, что деление на 8 можно осуществить путем сдвига двоичного числа на три позиции, что гораздо быстрее, чем выполнять деление на 9):
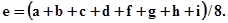
Сущность анизотропной фильтрации заключается в свертке исходного массива изображения L(m, n) размерности I´J и сглаживающего массива W(m, n) размерности N´N (N < I, J). Как и при пороговом сглаживании N = 3, 5 или 7.
Элементы «сглаженного» массива B(m, n) вычисляются согласно выражению:
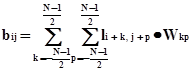
При анизотропной фильтрации величина интенсивности каждого пикселя умножается на соответствующий вес этого пикселя. Так, если по каким-либо основаниям полагают, что пиксели, занимающие левое верхнее положение в апертуре фильтра должны иметь наибольший вес, то формула изменится следующим образом:
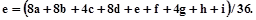
Для обработки краевых элементов кадра, к нему программно добавляются нулевые строки и столбцы. Сглаживающий массив нормируется, так, чтобы при фильтрации не изменялась средняя яркость изображения.
Наиболее распространены сглаживающие массивы W(m, n) следующих видов:


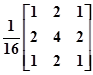
Аналогичный принцип положен в основу метода рекуррентной фильтрации, однако, здесь используются не только элементы исходного массива L(m, n), но и элементы уже «сглаженного» массива B(m, n). Поэлементные операции проводятся согласно выражению
 ,
,
здесь элементы lij берутся сначала из исходного массива L(m, n), а затем из массива B(m, n).
Особенностью рекуррентной фильтрации является экономия памяти СТЗ, т.к. нет необходимости в сохранении исходного массива. Новые значения яркости пикселей, вычисленные на предыдущем этапе, записываются поверх старого изображения, затирая его. Этот способ значительно экономит память, так как данные о яркости содержатся в одном массиве. В то же время, метод обычной (нерекуррентной) анизотропной фильтрации, использующий два массива, является более точным, т.к. при этом не накапливаются ошибки, сделанных на предыдущих этапах вычислений. Сглаживающий массив W (m, n) выбирается из тех же соображений, что и при обычной анизотропной фильтрации.
Существенным недостатком линейных фильтров является размывание кромок и других характерных деталей объекта.
Наиболее известными нелинейными методами фильтрации являются медианный фильтр и метод расширения-сжатия.
Медианная фильтрация очень эффективна при подавлении шумов, особенно импульсного характера; при этом сохраняются резкие перепады - кромки. Медианой последовательности x1, x2, ...xn, где n - нечетное, называется средний по значению член ряда, получающегося при упорядочивании последовательности по возрастанию. Для четного n медианой является среднее арифметическое двух средних членов. Например, mediana (0, 2, 5, 0, 8) = 2, mediana (0, 2, 5, 3, 0, 8) = 3.
Медианный фильтр для некоторой окрестности изображения (x, y) описывается выражением:
Lm(x, y) = mediana L(x, y)
где Lm(x, y) - новое значение интенсивности (яркости) текущего пикселя изображения, L(x, y) - интенсивность в некоторой окрестности этого пикселя.
Для квадратной апертуры размерностью 3´3 данная формула будет выглядеть следующим образом:
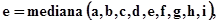
причем значение пикселя e будет определяться пятым (по возрастанию) значением яркости пикселей в этой окрестности. Качество фильтрации изображения, как и для линейных фильтров, растет прямо пропорционально размеру апертуры фильтра.
Данный фильтр, как и линейный, может применяться к изображению как рекуррентным, так и нерекуррентным способом. Недостатком медианного фильтра является его очень низкая скорость, поэтому он применяется, как правило, с малыми апертурами (3´3, 5´1), а также с изображениями, которые плохо обрабатываются линейными фильтрами.
Вообще, чем больше апертура фильтра, тем лучше удаляются помехи, имеющие большую площадь. Также, для улучшения качества можно использовать несколько проходов, что позволяет уничтожить те помехи, которые остались после первых итераций.
Фильтр типа «сжатие-расширение» применяется только в бинаризованных изображениях, когда используются две градации яркости пикселей: объект-фон. Процедура сжатия заключается в уменьшении размеров объекта и увеличении размеров отверстий (при этом устраняются мелкие фрагменты). В процессе расширения, наоборот, объект увеличивается в размерах, причем его полости заполняются, восстанавливая тем самым целостность. Поскольку обе процедуры быстрые, их часто используют вместе, делая многопроходными. Например, сначала выполняется 15 сжатий изображения, а затем 20 расширений.
В зависимости от формы применяемой апертуры различают три типа процедур сжатия-расширения: 8-ми связное, 4-х связное и диагональное. В каждом случае используют апертуры размерностью 3´3, однако, при 8-ми связном сжатии-расширении используется квадратная апертура (учитываются все пиксели - соседи центрального), при 4-х связном - крестообразная апертура (направления сканирования: вверх, вниз, влево и вправо), а при диагональном сжатии-расширении - Х-образная. Во всех процедурах обрабатываются только пиксели, принадлежащие объекту.
Для фильтрации помех и сглаживания изображений применяются также различные интегральные методы. К ним относятся дискретные преобразования Фурье, Уолша, Адамара и др. Подобные преобразования, в целом, осуществляются медленнее, чем рассмотренные выше, т.к. требуют большего объема вычислений.
 После фильтрации (сглаживания) изображений проводится выделение краев и линий - границ перепада яркости и для дальнейшей обработки используются только элементы, принадлежащие этим границам. При таком представлении изображений, называемом контурным, достигается значительное сжатие визуальной информации и повышение скорости ее окончательной обработки.
После фильтрации (сглаживания) изображений проводится выделение краев и линий - границ перепада яркости и для дальнейшей обработки используются только элементы, принадлежащие этим границам. При таком представлении изображений, называемом контурным, достигается значительное сжатие визуальной информации и повышение скорости ее окончательной обработки.
Алгоритмы выделения контуров разделяются на две группы: операторные и корреляционные.
Алгоритмы этой группы основаны на использовании операторов пространственного дифференцирования, которые выделяют в каждом заданном фрагменте изображения элементы, находящиеся на границе различных по освещенности (яркости) областей.
Метод определения краев и линий основан на предположении, что соответствующие им точки изображения вызывают экстремумы функции освещенности L и их можно определить по максимумам нормы градиента. Понятие градиента иллюстрирует рис. 6.49.
Градиент освещенности Гij в точке (i, j) определяется как двумерный вектор
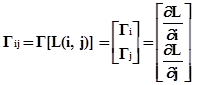
Фрагменты, в которых работают дифференциальные операторы, задаются на каждом шаге сканирования изображения программным окном. (В программах обработки изображений такое сканирование организуется с использованием операторов цикла).
Простейшие дифференциальные операторы работают в программном окне размерностью 2´2, и самый простой из них использует только два элемента окна, кроме анализируемого элемента lij.
 Норма градиента Гij определяется выражением:
Норма градиента Гij определяется выражением:
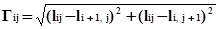
или, чтобы избежать операций возведения в степень и извлечения корня и ускорить счет:
Гij = |lij - li+1,j| + |lij - li,j+1|
Вид градиента освещенности зависит от формы границы, или, точнее от вида сопрягаемых поверхностей, образующих границу (рис. 6.50). Цифрой 1 обозначена граница, образованная двумя плоскостями, цифрой 2 - выпуклая поверхность, цифрой - 3 сопряжение выпуклой поверхности и плоскости.
Самыми популярными дифференциальными операторами являются операторы Робертса и Собеля.
 Оператор Робертса (рис. 6.51) позволяет точнее вычислить норму градиента по сравнению с простым дифференциальным оператором 2´2, поскольку использует все элементы программного окна. Имеем:
Оператор Робертса (рис. 6.51) позволяет точнее вычислить норму градиента по сравнению с простым дифференциальным оператором 2´2, поскольку использует все элементы программного окна. Имеем:
Гij = |lij - li+1,j+1| + |li+1,j - li,j+1|
Значение Гij можно определить с помощью маски, определяемой выражением: 
(В обоих случаях операторы с модулями разности дают большую погрешность определения нормы градиента, чем исходные формулы).
 Операторы пространственного дифференцирования, работающие в программном окне размерностью 3´3, позволяют не только определить норму градиента (т.е. величину перепада яркости), но и проследить линию или контур изображения. Данный оператор обеспечивает одновременно фильтрацию и выделение контура и носит название «оконтуривающего фильтра ».
Операторы пространственного дифференцирования, работающие в программном окне размерностью 3´3, позволяют не только определить норму градиента (т.е. величину перепада яркости), но и проследить линию или контур изображения. Данный оператор обеспечивает одновременно фильтрацию и выделение контура и носит название «оконтуривающего фильтра ».
Оператором Собеля (рис. 6.52) норма градиента Гij находится следующим образом:
Гij = |Гxij| + |Гyij|,
причем предварительно вычисляются нормы градиента по координатам X и Y кадра:
Гxij = (li+1,j-1 +2li+1,j +li+1,j+1) - (li-1,j-1 + 2li-1,j + li-1,j+1),
Гyij = (li-1,j+1 +2li,j+1 +li+1,j+1) - (li-1,j-1 +2li,j-1 + li+1,j-1).
Направление контуров и линий оценивается по соотношению значений Гxij и Гyij.
Используя маски для определения Гxij и Гyij получим для нормы градиента Гij следующее выражение:
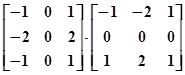
После применения данного оператора, на выходе алгоритма образуется массив, каждый элемент которого соответствует величине градиента в данной точке изображения. (На рис. 6.50 и 6.51 для наглядности изображения объекта инвертированы).
Недостатком обоих операторов является их неприемлемость для «толстых» контуров. С этой целью, иногда используются методы «утончения» контура. Известен алгоритм утончения, основанный на раздельном сканировании внешнего и внутреннего контуров и последующем определении тонкого контура, как среднего значения между точками обоих контуров. Такой подход требует применения алгоритмов обхода контура (связанных с процедурами сегментации и кодирования).
Вторая производная изображения определяется с помощью преобразования Лапласа. Оператор Лапласа Lij является оператором производных второго порядка. Он представляется в виде процедуры:
 ; или в виде маски
; или в виде маски 
6.6.2. Сегментация
В результате предварительной обработки изображение сцены содержит один или несколько достаточно гладких контуров произвольной формы. Процедура разделения составляющих сцену контуров и «соотнесения» их с определенными объектами называется сегментацией. В случае если сцена содержит несколько объектов, то процедура сегментации проводится между этапами формирования изображения и кодирования.
Алгоритмы сегментации, как правило, основываются на двух фундаментальных принципах: разрывности и подобия. Наиболее распространено использование первого принципа, в соответствии с которым, производится программный обход контура по установленному закону. На практике, соединение точек контура осуществляется при анализе характеристик пикселей в некоторой окрестности (3´3, 5´5) каждой точки (x, у) образа, который уже подвергся процедуре обнаружения контура. Таким образом, процедура сегментации (называемая иногда анализом связности) может реализовываться вслед за выделением контура, и использовать алгоритмы, подобные фильтрующим. В то же время, на практике использование сегментации одновременно с фильтрацией затруднено, особенно для контуров с резкими вырезами. Под анализом связности элементов дискретного изображения понимают поиск ближайших соседей, расстояние между которыми не превышает одного пикселя. Если считать, что каждый пиксель связан только с четырьмя соседними элементами, то говорят о четырехсвязной области, если с восемью, включая диагональные - то восьмисвязной (рис. 6.53а и 6.53б соответственно). Обычно, во избежание неоднозначности, пользуются методом восьмисвязности. Неоднозначен, например, объект представленный на рис. 6.52в. Действительно, при четырехсвязном представлении его можно интерпретировать как четыре отдельных объекта, касающиеся друг друга. При восьмисвязном представлении удается локализовать разрывы в контуре, и тем самым обозначить на изображении отдельные сегменты. Если эти сегменты принадлежат замкнутому контуру, то считается, что обнаруженный контур является контуром объекта. Наиболее простой алгоритм обхода контура представленный на рис. 6.52г предполагает перемещение сканирующего окна (3´3) от точки к точке, в процессе которого производится нумерация точек контура и определяется его замкнутость. В результате описанной процедуры все точки замкнутого контура получают привязку к абсолютной системе координат. Подобное представление изображения занимает значительный объем в памяти, т.к. каждая точка характеризуется двумя координатами. Размерность выходного массива оказывается равной размерности массива исходного изображения. (При размерности простейшего бинарного изображения 256´256 этот массив занимает 4К 16-ти разрядных слов).
Для более компактного представления данных в СТЗ часто используется кодирование изображений.
6.6.3. Кодирование изображений
Под кодированием изображения понимается обычно обратимое преобразование информации, позволяющее получить компактный («сжатый») массив чисел, однозначно описывающий это изображение в удобной для данной вычислительной структуры форме.
В СТЗ различают три типа кодирования:
· кодирование собственно изображения с помощью кодов длин серий (КДС);
· кодирование контура кодами Фримана;
· частотное кодирование с использованием Фурье-преобразований.
Процедура кодирования изображений в СТЗ обычно представляет собой упаковку контура. Она реализуется одновременно с обходом контура и заключается в присвоении каждой его точке некоторого значения.
В общем случае, эффективность того или иного метода упаковки можно оценить с помощью коэффициента сжатия информации Ск:
Ск = Vи/Vк,
где Vи - объем исходного массива изображения; Vк - объем памяти, необходимый для записи закодированного изображения.
Для увеличения коэффициента сжатия изображение преобразуется из пространства абсолютных координат в некоторое пространство относительных (обобщенных) координат.
 Сущность кодирования методом длин серий (известного в компьютерной обработки изображений как метод RLE) заключается в представлении изображений однородными отрезками строки развертки, где уровни яркости (или цвет элементов) одинаковы. При этом каждая серия характеризуется уровнем яркости и длиной (числом пикселей). Исследования, проведенные для бинарных изображений, показали, что использование КДС обеспечивает сжатие информации в 4 ... 7 раз. Приведем пример записи в КДС, объекта представленного на рис. 6.54а: 4,7,6; 3,6,1; 9,6,1; 3,5,1; 10,5,1; 3,4,2; 11,4,1; 4,3,1; 10,2,1; 5,2,6.
Сущность кодирования методом длин серий (известного в компьютерной обработки изображений как метод RLE) заключается в представлении изображений однородными отрезками строки развертки, где уровни яркости (или цвет элементов) одинаковы. При этом каждая серия характеризуется уровнем яркости и длиной (числом пикселей). Исследования, проведенные для бинарных изображений, показали, что использование КДС обеспечивает сжатие информации в 4 ... 7 раз. Приведем пример записи в КДС, объекта представленного на рис. 6.54а: 4,7,6; 3,6,1; 9,6,1; 3,5,1; 10,5,1; 3,4,2; 11,4,1; 4,3,1; 10,2,1; 5,2,6.
КДС наиболее удобны для упаковки «неизрезанных» изображений (т.е. изображений с гладким контуром).
Весьма распространенным методом кодирования непосредственно контуров изображения является использование цепных кодов Фримана (рис. 6.54б). При кодировании по Фриману, контур, начиная с некоторой точки, задается последовательностью векторов, принимающих дискретные значения с углом наклона модуля кратного 450. Значение модуля равно Ö2, если угол наклона вектора составляет 450 и 1, при вертикальном или горизонтальном его положении. Изменение направления векторов при переходе от одной точки кривой к другой отражает характер изменения моделируемой кривой.
(Цепной код для той же фигуры имеет вид: 0, 0, 0, 0, 0, 6, 7,7, 5, 6, 4, 4, 4, 4, 4, 3, 2, 4, 2, 2, 1)
Запись в цепных кодах эффективна для контурных изображений с «изрезанной» линией.
Выбор способа кодирования зависит от признаков объекта, которые будут использоваться на стадии описания изображений. Так, при использовании геометрических признаков (периметра, площади, момент инерции) эффективнее кодирование с помощью КДС, а при использовании локальных признаков, типа углов, отверстий, целесообразно применение цепных кодов.
6.6.4. Описание изображений
Под описанием понимается определение характерных параметров объекта - признаков (дискрипторов), необходимых для его выделения из числа всех, образующих сцену. Выбор описания является очень ответственной задачей: если описание выбрано удачно, то распознавание (идентификация) может быть проведена достаточно легко, и наоборот. Чаще всего формирование признаков производится непосредственно разработчиком СТЗ или экспертом, хорошо знающим конкретную задачу. Поэтому, универсальных подходов к выбору признаков не существует, и при распознавании объектов велика роль субъективного фактора. В то же время, некоторые общие принципы существуют. Так, в большинстве случаев к признакам, входящим в описание, предъявляется требование инвариантности к повороту, трансляции (переносу) и гомотетии (изменению масштаба). Инвариантность к гомотетии особенно существенна, когда объекты располагаются не на плоскости, а в пространстве.
По своей физической сущности признаки разделяются на глобальные и локальные. Глобальный признак изображения - это признак, который можно вычислить для любого изображения объекта. Идентификация объектов на основании этих признаков производится по соотношению их численных значений. Примерами таких признаков могут служить: площадь изображения объекта, моменты инерции (полярные и декартовы), минимальный и максимальный радиус-векторы изображения и т.п.
Локальные признаки характеризуют не все изображение, а его часть. К локальным признакам относятся: величина угла между двумя контурными линиями, число и параметры отверстий на изображении объекта и т.п.
Данные признаки относятся к классу геометрических. Наряду с ними могут применяться и эмпирические признаки, выбор которых определяется интуицией разработчика.
При вычислении признаков, рассматриваются изображения объектов, контуры которых уже выделены. Практически всегда используются инвариантные к повороту и трансляции признаки - площадь $ и периметр изображения P, а также, зависящий от них коэффициент формы Kф или пераунд, равный: Kф = $/P2.
Полярные моменты изображения определяются формулами:
 и
и 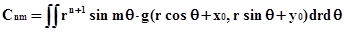
Здесь g(x, y) - функция интенсивности света на поле изображения (предполагается, что вне объекта, на фоне - интенсивность равна нулю), r и q -радиус и угол в полярных координатах с исходной точкой, имеющей координаты x0 , y0.
Если изображение преобразовать в двоичный код и выделить контур, то выражения для полярных моментов упрощается:
 и
и  соответственно, где k - точки контура.
соответственно, где k - точки контура.
Особенностью полярных моментов является их инвариантность относительно трансляции изображения. За точку отсчета обычно принимается центр тяжести изображения, определяемый выражением:
 ,
, 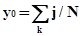
Здесь N - число точек контура, i - абсцисса этих точек, j - ордината.
Наряду с полярными моментами изображения в качестве признаков достаточно часто используют и декартовы моменты порядка pq, которые вычисляются следующим образом:
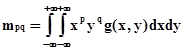
Как и для полярных моментов, последовательность mpq однозначно определяет изображение g(x, y). Обычно при описании объекта из полное интегральное выражение апроксимируется несколькими первыми членами. Частным случаем декартовых моментов являются моменты центральные. Так, если взять за точку отсчета центр тяжести изображения (центр площади), то можно определить центральные моменты изображения:
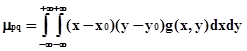
Особенностью центральных моментов является инвариантность некоторых их комбинаций к вращению, трансляции и гомотетии. Для бинарных изображений вычисление центральных моментов упрощается:
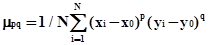
где N - количество точек изображения с координатами xi, yi, a x0 и y0 - координаты центра тяжести.
Заметим, что геометрические признаки, несмотря на свою распространенность могут классифицировать далеко не все объекты. Так, в [ ] приведены пример объектов, для которых одинаковы площадь, периметр и пераунд, а также моментные инварианты первого и второго порядков (рис. 6.55).
6.7. Распознавание изображений
Распознаванием называется процесс, при котором на основании набора признаков некоторого изображения объекта определяется его принадлежность к определенному классу. Следовательно, распознавание реализует функцию анализа визуального образа. В большинстве промышленных СТЗ предполагается, что этот образ формируется сегментированными объектами, т.е. объектами, разделенными друг относительно друга, или представляющими собой набор отдельных элементов. В противном случае, когда на сцене присутствует несколько неразделенных объектов, задача многократно усложняется, за исключением тех моментов, когда априорно речь идет об известных перекрывающихся объектах [ ]. Задачи такого уровня сложности требуют активного применения методов искусственного интеллекта и экспертных систем. Другое ограничение связано с тем, что распознавание должно проводиться в тех же условиях, что и формирование признаков объекта. Во всяком случае, различия в значениях признаков объекта, полученных на этапе обучения СТЗ и при распознавании, не должны быть слишком велики. Существенно, что такие же ограничения имеют место и при распознавании объектов человеком - если при распознавании признаки имеют другие численные значения, то объект может быть не опознан. (Характерным примером является детский рисунок).
Следует отметить, что хотя до настоящего времени не создано единого описания процесса распознавания изображений, существует большое количество частных методов. Обзор некоторых из них и обширная библиография приведены в [ ]. Условно все методы распознавания можно разделить на две группы: теоретические и структурные.
Теоретические методы распознавания строятся на основе сравнения текущего вектора признаков объекта с заданным с помощью некоторого решающего правила. Предполагается, что заданный вектор признаков формируется при обучении СТЗ. Рассмотрим объект, который описывается вектором признаков вида V = (v1, v2, … vn)T , где vi - i-ый признак объекта. Распознавание, как процедура отнесения заданного объекта к некоторому классу, представляет собой выбор из N классов объектов. Следовательно, при распознавании производится определение N функций p1(V), p2(V), … pN(V), таких, чтобы для каждого V*, принадлежащего классу oi выполняется неравенство вида:
pi (V*) > pj (V*), j = 1, 2, … N; i ¹ j.
Таким образом, неизвестный объект, обладающий вектором признаков V* распознается (относится к j-му классу), если при подстановке V* во все функции, pi (V*) будет иметь наибольшее значение [ ].
Строго говоря, определить реальное значение признаков объекта невозможно - они изменяются при каждом измерении. Поэтому задача распознавания ставится так: определить вероятность Pоб того, что объект принадлежит к заданному классу (Pоб Î А). Поскольку распознавание является вероятностной процедурой, возможны варианты, когда объект идентифицируется как принадлежащий другому классу Pлож (Pоб Î В) и как не принадлежащий никакому классу вообще Pпр (Pоб ÏА, В). Вероятности Pлож и Pпр иногда называют вероятностью ложной тревоги и вероятностью пропуска цели соответственно.
Структурные методы распознавания основываются на теории формальных языков, базируемых на математических моделях грамматик. (Наиболее известной является модель американского лингвиста Н. Хомского). Идея состоит в построении описания сложного объекта в виде иерархической структуры более простых подобразов (образ описывается более простыми подобразами, каждый подобраз - еще более простыми подобразами и т. д).
При распознавании производится сравнение двух векторов признаков объекта - эталонного V и текущего V*. Для большинства практических задач в качестве компонент эталонного вектора используются геометрические параметры: площадь поверхности $, коэффициент формы Kф, число вершин или отверстий объекта k, комбинации центральных моментов вплоть до пятого mpq, члены разложения в ряд Фурье Fj и т.п. Следовательно, эталонный вектор признаков объекта можно представить в виде: V = ($, Kф, k, mpq, Fi), i = 1, … 4. Текущий вектор признаков V* формируется в результате ввода и предварительной обработки изображения: V* = ($*, Kф *, k1, mpq, Fi). Тогда процедура распознавания сведется к определению расстояния DV между данным изображением и эталоном: DV = V* - V. Эффективность этой процедуры характеризуется величиной вектора DV, и растет с уменьшением последней. Критерием эффективности алгоритма распознавания будем считать функцию: DV ® min.
6.7.1. Пример алгоритма распознавания
Одно из наиболее интересных направлений распознавания образов связано с развитием систем контроля доступа. Эти системы позволяют ограничить круг пользователей, имеющих доступ как к физическим, так и виртуальным объектам, включая, например, узлы компьютерных систем.
 В качестве примера рассмотрен алгоритм распознавания лиц, разработанный фирмой ITC, США. Модель лица представляется в виде набора некоторых элементов - масок. Каждая маска характеризуется геометрическими признаками - координатами относительно выбранного центра изображения. (Таким центром может быть геометрический центр лица или середина переносицы). В алгоритме анализируются пять масок: правый и левый глаз, нос, рот, правая и левая носогубная складка и подбородок.
В качестве примера рассмотрен алгоритм распознавания лиц, разработанный фирмой ITC, США. Модель лица представляется в виде набора некоторых элементов - масок. Каждая маска характеризуется геометрическими признаками - координатами относительно выбранного центра изображения. (Таким центром может быть геометрический центр лица или середина переносицы). В алгоритме анализируются пять масок: правый и левый глаз, нос, рот, правая и левая носогубная складка и подбородок.
Элементы распознаваемого лица хранятся в виде «вырезанных» из оцифрованного растрового изображения областей прямоугольной формы. В зависимости от маски, размеры областей варьируются в пределах: от 15´11 пикселей - для носогубных и до 31´13 - для рта. Изображение квантуется на 256 градаций яркости.
Как и для большинства алгоритмов распознавания, программы такого рода состоят из двух частей:
· предварительное обучение, на котором производится описание лица пользователя и занесение его признаков в базу данных (регистрация);
· распознавание (выбор наиболее похожего изображения из базы данных).
Регистрация выполняется за несколько этапов. На первом производится традиционная предобработка регистрируемого изображения с целью удаления шумов и выделения контуров с помощью градиентного фильтра (например, фильтра Робертса размером 3´3). В результате, на изображении выделяется овал, определяющий форму лица. На следующем этапе осуществляется масштабирование изображения до заданного формата (составляющего 64 пикселя по горизонтали) и находится приблизительный центр лица.
 Далее производится поиск правого глаза на изображении. С этой целью в выделенной области осуществляется фильтрация изображения локальным фильтром, содержащим стандартную маску правого глаза (рис. 6.56а). Вычисляется значение суммы разностей приведенных яркостей пикселей исходного изображения и соответствующих им пикселей фильтра. Приведенное значение яркости вычисляется по формуле:
Далее производится поиск правого глаза на изображении. С этой целью в выделенной области осуществляется фильтрация изображения локальным фильтром, содержащим стандартную маску правого глаза (рис. 6.56а). Вычисляется значение суммы разностей приведенных яркостей пикселей исходного изображения и соответствующих им пикселей фильтра. Приведенное значение яркости вычисляется по формуле:
L = L0 (Lф/Lи),
где L0 - исходное значение яркости, Lф - суммарная яркость пикселей фильтра, Lи - суммарная яркость пикселей исходного изображения в текущей фильтруемой области.
Таким образом, результатом фильтрации является отклик w:
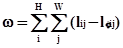
здесь W и H - соответственно ширина и высота фильтра (маски), lij и lфij - значения яркости пикселя изображения и пикселя фильтра соответственно. Минимум w соответствует левому верхнему углу области изображения размером W´H, содержащему искомый элемент - правый глаз.
Далее в секторе изображения с центром в правом глазе и дугой ~20° ищется левый глаз (рис. 6.56б), после чего осуществляется поворот изображения так, чтобы глаза оказались на одном уровне по горизонтали (рис. 6.57а). Изменение ориентации требует уточнения первоначального положения центра лица (как середины отрезка, соединяющего глаза), и координаты масок определяются относительно нового центра (рис. 6.57б).
 На следующих этапах выделяются области остальных масок (рта, носа, подбородка и носогубных складок) и осуществляется их поиск по величине отклика w. Таким образом, в процессе регистрации, формируется полная модель лица, которая сохраняется в базе данных. Модель описывается набором векторов rk, связывающих центр лица с центрами найденных элементов.
На следующих этапах выделяются области остальных масок (рта, носа, подбородка и носогубных складок) и осуществляется их поиск по величине отклика w. Таким образом, в процессе регистрации, формируется полная модель лица, которая сохраняется в базе данных. Модель описывается набором векторов rk, связывающих центр лица с центрами найденных элементов.
Алгоритм распознавания (верификации) близок к алгоритму регистрации. Текущее изображение лица сравнивается со всеми моделями из базы данных, в результате чего формируется некоторый функционал F, равный:
F = (S÷rk*÷ C1k; Svk C2k),
здесь rk* - вектора соединяющие центры k-ых элементов исходного изображения с центрами элементов верифицируемого лица, C1k, C2k - весовые коэффициенты, показывающие влияние смещения и отклика каждого элемента на результирующий счет. Параметр vk = min wk вычисляемый через величину откликов, определяется по всей области, в которой производилась фильтрация с помощью соответствующей маски.
В результате верификации принимается решение об идентичности сравниваемых лиц (рис. 6.58). Лица считаются идентичными при условии, что 100 - F ³ P, где P – заранее заданный порог сравнения.
6.7.2. Особенности получения трехмерных изображений
 В завершении вкратце рассмотрим принципы анализа трехмерных сцен. Этому вопросу в последнее время уделяется значительное внимание, созданы соответствующие алгоритмы распознавания. В большинстве случаев они относятся к различным частным задачам, во всяком случае, универсальных описаний трехмерных объектов не получено [ ]. СТЗ, как правило, ограничиваются анализом плоских изображений и этого оказывается достаточно для надежного распознавания типовых объектов промышленного назначения. Однако при этом возникает необходимость надлежащей ориентации объектов в поле зрения телекамеры. Типичным решением является обеспечение ортогональности оптической оси камеры и рабочей сцены. Кроме того, необходимо, чтобы в поле зрения оказалась именно та поверхность объекта, которая использовалась на этапе описания, при формировании признаков объекта. Все эти ограничения выполнимы в случае детерминированной рабочей сцены, когда существует возможность ее некоторого упорядочивания. В более сложных задачах все же приходится учитывать трехмерный характер рабочей сцены.
В завершении вкратце рассмотрим принципы анализа трехмерных сцен. Этому вопросу в последнее время уделяется значительное внимание, созданы соответствующие алгоритмы распознавания. В большинстве случаев они относятся к различным частным задачам, во всяком случае, универсальных описаний трехмерных объектов не получено [ ]. СТЗ, как правило, ограничиваются анализом плоских изображений и этого оказывается достаточно для надежного распознавания типовых объектов промышленного назначения. Однако при этом возникает необходимость надлежащей ориентации объектов в поле зрения телекамеры. Типичным решением является обеспечение ортогональности оптической оси камеры и рабочей сцены. Кроме того, необходимо, чтобы в поле зрения оказалась именно та поверхность объекта, которая использовалась на этапе описания, при формировании признаков объекта. Все эти ограничения выполнимы в случае детерминированной рабочей сцены, когда существует возможность ее некоторого упорядочивания. В более сложных задачах все же приходится учитывать трехмерный характер рабочей сцены.
 В СТЗ под трехмерным понимают изображение, содержащее информацию о трех геометрических измерениях объекта. Оно может быть получено с помощью двух телекамер (3D), или могут использоваться специальные приемы. (В этом случае, обычно говорят о 2,5D или K2D изображениях). При использовании 2-х телекамер, каждая из них обрабатывает свой плоский 2D образ, на основании описанных выше принципов. Если известна ориентация каждой камеры и расстояние между ними, всегда можно восстановить третью координату объекта (рис. 6.59). Основная трудность этого метода заключается в идентификации каждой точки объекта по их плоским изображениям на двух камерах, особенно в случае нечетких изображений. Обычно две телекамеры используются в задачах телеуправления, в мобильных роботах и др. (Примерами таких роботов являются отечественные разработки МРБ-25, МГТУ им. Н.Э. Баумана и «Богомол», ИФТП). При необходимости, результирующее 3D изображение может быть выведено на обычный монитор, что применяется, например, в задачах телеуправления. С этой целью, в одно поле вводится информация с одной камеры, а в другое - с другой. Другими словами, нечетный полукадр развертки образует видеосигнал, например, с левой телекамеры, а четный - с правой. Ясно, что такое изображение субъективно воспринимается как двоящееся. Поэтому, для получения бинокулярного эффекта необходимо использовать стереоочки.
В СТЗ под трехмерным понимают изображение, содержащее информацию о трех геометрических измерениях объекта. Оно может быть получено с помощью двух телекамер (3D), или могут использоваться специальные приемы. (В этом случае, обычно говорят о 2,5D или K2D изображениях). При использовании 2-х телекамер, каждая из них обрабатывает свой плоский 2D образ, на основании описанных выше принципов. Если известна ориентация каждой камеры и расстояние между ними, всегда можно восстановить третью координату объекта (рис. 6.59). Основная трудность этого метода заключается в идентификации каждой точки объекта по их плоским изображениям на двух камерах, особенно в случае нечетких изображений. Обычно две телекамеры используются в задачах телеуправления, в мобильных роботах и др. (Примерами таких роботов являются отечественные разработки МРБ-25, МГТУ им. Н.Э. Баумана и «Богомол», ИФТП). При необходимости, результирующее 3D изображение может быть выведено на обычный монитор, что применяется, например, в задачах телеуправления. С этой целью, в одно поле вводится информация с одной камеры, а в другое - с другой. Другими словами, нечетный полукадр развертки образует видеосигнал, например, с левой телекамеры, а четный - с правой. Ясно, что такое изображение субъективно воспринимается как двоящееся. Поэтому, для получения бинокулярного эффекта необходимо использовать стереоочки.
 Другой распространенный способ получения «псевдотрехмерных» изображений, требует только одного телевизионного датчика и связан с применением «структурированной подсветки» (рис. 6.61). В частности, он используется в лазерных 3D-сканерах. Объект освещается от проектора через матрицу - транспарант с периодической системой полос, а изображение воспринимается камерой, расположенной под некоторым параллаксным углом к оси проектора. Зная расстояние (период) между полосами, а также взаимное положение камеры и проектора, можно восстановить форму объекта. Полученное изображение объекта в виде бинарных искривленных линий можно интерпретировать как результат фазовой пространственной модуляции оптического сигнала. Действительно, если периодическую сетку, спроецированную на плоский экран считать несущим сигналом, то любая неплоская поверхность вносит фазовую модуляцию в этот сигнал, причем закон модуляции линейно связан с профилем поверхности в направлении оптической оси камеры. Данный способ также позволяет восстановить третью координату объекта. Рис. 6.60а и б иллюстрируют принцип восстановления рельефа объекта и наблюдаемая на экране его трехмерная модель. Обозначив Tx - период полос транспаранта вдоль оси Х, b - паралаксный угол, определим период полос, воспринимаемых камерой: Txk = Tx/tgb. Следовательно, для любой точки на изображении с координатами xk, yk, принадлежащей i-ой линии транспаранта можно восстановить третью координату zk:
Другой распространенный способ получения «псевдотрехмерных» изображений, требует только одного телевизионного датчика и связан с применением «структурированной подсветки» (рис. 6.61). В частности, он используется в лазерных 3D-сканерах. Объект освещается от проектора через матрицу - транспарант с периодической системой полос, а изображение воспринимается камерой, расположенной под некоторым параллаксным углом к оси проектора. Зная расстояние (период) между полосами, а также взаимное положение камеры и проектора, можно восстановить форму объекта. Полученное изображение объекта в виде бинарных искривленных линий можно интерпретировать как результат фазовой пространственной модуляции оптического сигнала. Действительно, если периодическую сетку, спроецированную на плоский экран считать несущим сигналом, то любая неплоская поверхность вносит фазовую модуляцию в этот сигнал, причем закон модуляции линейно связан с профилем поверхности в направлении оптической оси камеры. Данный способ также позволяет восстановить третью координату объекта. Рис. 6.60а и б иллюстрируют принцип восстановления рельефа объекта и наблюдаемая на экране его трехмерная модель. Обозначив Tx - период полос транспаранта вдоль оси Х, b - паралаксный угол, определим период полос, воспринимаемых камерой: Txk = Tx/tgb. Следовательно, для любой точки на изображении с координатами xk, yk, принадлежащей i-ой линии транспаранта можно восстановить третью координату zk:
zk = D xk /tga = (xk – iTxk)/tgb.
В завершении заметим, что в описанных подходах к анализу трехмерных сцен, собственно обработка информации производится на двухмерных образах. Третья координата используется, как правило, для вычисления дальности до объекта или при определении взаимного положения нескольких объектов сцены. Обширная библиография, посвященная алгоритмам обработки трехмерных сцен приведена в [ ].
Вопросы для самостоятельной подготовки
1. Когда поверхность воспринимается разноцветной?
2. В чем разница между кадром и полем?
3. Что такое цветоразностные сигналы?
4. Как получить черный цвет в системе RGB?
"7 Коренные изменения в семейное право" - тут тоже много полезного для Вас.
5. Что такое чувствительность телекамеры, и какой тип камеры обладает наивысшей чувствительностью?
6. Как соотносятся пропускные способности каналов цифровой и аналоговой записи изображений?
7. Зависит ли разрешающая способность видикона и ПЗС-камеры от полосы частот сигнала изображения?
8. В чем разница между дискретизацией и квантованием видеосигнала?
9. Применяется ли субдискретизация к полутоновым изображениям?
10. В чем сущность медианной фильтрации?



















