
Элементы теории компиляции
Элементы теории компиляции
Формальные грамматики
G = <VN, VT, P , S >
VN -множество нетерминальных символов;
VT - множество терминальных символов ;
P - множество правил вывода;
S Î VN - начальный нетерминальный символ.
Пример грамматик :
Метаязык
Рекомендуемые материалы
::= есть по определению
| или (исключающее)
[] необязательные символы
, перечисление
<нетерминальный символ>
<SELECT>::= select <IDS> from <IDS>
<IDS>::= <WRD> | <WRD> , <IDS> ; рекурсивное определение индефикаторов
<WRD>::=<LET>|<LET><WRD>
<LET>::= a|b|c…|z
Разберем строку:
for (i=0; i<10; i++)
< FOR >::=for(< инициализация >;< условие >;< изменение >)
< инициализация >::=< переменная >=< число >
< условие >::=< переменная >< знак сравнения >< число >
< изменение >::=< переменная >++ | < переменная >--
< переменная >::=< буква > | < буква >< переменная >
< буква >::=a|b|…|z
< число >::=< цифра > | < цифра >< число >
< цифра >::=1|2|…|9|0
< знак сравнения >::=< | >
Язык – множество {XÎV*T }, цепочек терминальных символов, таких, что они получаются из начальных нетерминальных символов.
L(G) ={ XÎV*T | S=>*x}
Классификация языков по Хомскому
Язык – множество {XÎV*T }, цепочек терминальных символов, таких, что они получаются из начальных нетерминальных символов.
L(G) ={ XÎV*T | S=>*x}
Классификация основывается по типу правил. Если в одном языке правила можно отнести к разным типам, то выбирается худший тип.
Типы:
0-тип: Не накладывает ограничения на правила, поэтому и не рассматривается.
1-тип: Контекстно-зависимые грамматики.
Правила имеют следующую форму:
vαw::=vβw
v,wÎV* – цепочки любых символов(контекст)
αÎVN
βÎV*
Пример:
φ->A |
[A]-> [C] |
(A)->(B) | => S=>(A)=>(B) =>(x)
B->x |
C->y |
2-тип: Контекстно-свободные грамматики.
Правила имеют следующую форму:
α::=β
αÎVN
βÎV*
A->BcD
D->cA
3-тип: Автоматические грамматики (рекурсии).
· Левосторонние α::=wβ α::=w α, β ÎVN wÎVT
· Правосторонние α::=βw α::=w
aabbbbaaaabb┘
1.  S->bB
S->bB
2. S->aA
3. A->aF
4. B->bF
5. F->aA
6. F->bB
7. F->┘
Распознающие автоматы – автоматы Мура с множеством выделенных состояний - конечных. Этот автомат недетерминированный и частичный.
| S | A | B | F | |
| q | A | F | A | |
| b | B | F | B |
====> переход к полному автомату
| S | A | B | F | Err | |
| a | A | F | (E) | A | (E) |
| b | B | (E) | F | B | (E) |
Переход от праволинейной грамматики к автоматам
S->select ==> S->s<elect>
<elect> -> e<lect>
<lect> -> l<ect>
<ect> -> e<ct>
<ct> -> c<t>
<t> -> t
Трансляторы.
Трансляторы - программа или устройство, переводящее входную строку из одного языка в другой без потери списка.
aÎA bÎB

Для упрощения процесс транслирования разбивают на шаги
aÎA a1ÎA1 a2ÎA2 bÎB

Виды трансляторов:
· Интерпретаторы – перевод из одного языка в другой по шагам.
· Компиляторы - переводит целиком.
Претрансляция
-текстовая замена макроопределений.
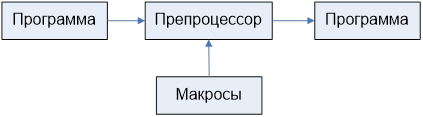
Структура компилятора
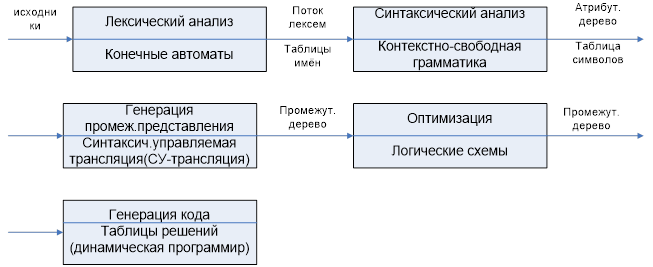
Функции компиляторов.
1. Лексический анализ – выделяет лексемы в строчке и проверяет на правильность.
2. Синтаксический анализ – проверяет порядок лексем.
3. Семантический анализ- проверка на правильность присваивания.
4. Генерация выходного текста
Схема работы компилятора
Лексический анализ.
Функции лексического анализа:
1. Выделения численных констант
2. Выделение индификаторов
3. Выделение сложных символов: /* */ //
4. Определение ошибок ввода
Для лексического анализа используются автоматные (регулярные) грамматики. В средствах лексического анализа используются регулярные выражения.
< нетерм. символ > → [< нетерм. символ >]< терм. символ >
A→Bc
B→Cc
C→d
< нетерм. символ > → < терм. символ >[< нетерм. символ >]
A→eC
C→cC
C→c
Зададим последнюю с помощью автомата
A C E
a - C,E -
e C - -
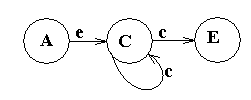
Приведем к детерминированному
A C E {-} {C,E}
c {-} {C,E} {-} {-} {C,E}
e C {-} {-} {-} {-}
Lex - команда Unix. Предназначена для ганерации программы на Си,
которая будет проводить лексический анализ входного текста в
соответствии с правилами.
Формат файла на lex:
раздел деклараций : имя_значение.
%%
раздел правил : шаблон_действие (регулярное выражение).
%%
Код на Си
Раздел деклараций: %token лексемы
Раздел правил: нетерм.симв: | цепочка символов { код на Си }
;
Для обработки ошибок описываем функцию
yyerror()
{ printf (“Ошибка”); }
Подсчёт идентификаторов во входном потоке
############### P.l ###############
digit [0-9]
letter [a-z]
%%
{letter}({letter}|{digit})* { i++; }
%%
int i;
main()
{
yylex();
printf( “ %d", i );
}
yyerror (){}
#########################################
yylex() - из раздела правил преобразует в Си
В командной строке пишем :
$ flex -oprogname.c progname.l
$ cc -o progname progname.c -lfl
$ ./progname [ < filename ]
Синтаксический анализ
Выделяют 2 типа синтаксического анализа: сверху вниз и снизу вверх. Используются контекстно-свободные грамматики.
< нетерм. символ > → < цепочка символов >
A→bC
C→eA
A→dCCA
A→b
c→E
Слева должен быть нетерм. символ – без контекста
Пример:
select name1, name2 from tab1, tab2
S x,x,…x f x,x,…,x
Анализ сверху вниз
1) S→sXfX
2) X→xY
3) Y→,xY
4) Y→E
s x , x f x , x , x
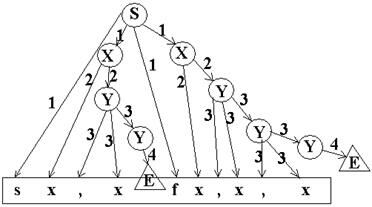
Анализ снизу вверх
1) S→sXfX
2) X→xY
3) X→x
4) Y→,xY
5) Y→,x
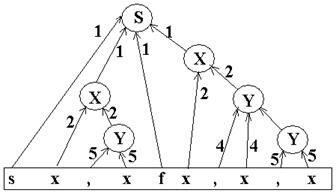
S и q грамматики
-Контекстно-свободные грамматики , на которые наложены ряд ограничений :
правые части правил начинаются с терминальных символов, причем для одного и того же левого символа правые части начинаются с разных символов.
S -> aT
S -> TbS
T -> bT
=
T -> bS
=
q-грамматика отличается от s-грамматики наличием аннулирующего правила (в правой части есть пустой символ)
=> ε
Из-за аннулирующих правил для q-грамматики вводится понятие следующего символа. N(A) - множество терминальных следующих (Next) за А символов.
В данном случае за А могут следовать a или b - {a,b}.
LL(1)- грамматика
Правая часть может начинаться с нетерминального символа, но при этом должна сохраняться детерминальность в выборе правил, т.е. множества выборов из правил при одном и том же нетерминальном символе не должны пересекаться.
LL(1)=Left-left most- самый самый левый.
F(α) - множество терминальных символов, стоящих первыми (First) в цепочках, выводимых из строки α.
N(А) - множество терминальных символов, следующих (Next) в цепочках за данным
нетерминальным символом А.
Множество выбора для каждого правила формируется с учетом множества первых и
множества следующих символов.
1. S -> AbB E(1) = F(AbB) = {a, b, c, e}
2. S -> d E(2) = {d}
3. A -> CAb E(3) = F(CAb) = {a, e}
4. A -> B E(4) = F(B) N(A) = {c}U{b} = {c}U{b}
5. B -> cSd E(5) = F(cSd) = {c}
6. B -> ε E(6) = F(ε) U N(B) = { ε }U {b, d, ┤}
7. C -> a E(7) = {a}
8. C -> ed E(8) = {e}
МП-автоматы (автоматы с магазинной памятью) – в стек помещается начальный нетерминальный символ
x Δ
( ↓x ↓x
) ↑x -
┤ - +
Преобразуем выражение (()())
( ( ) ( ) ) ┤
Δ x x x x x x
Δ x Δ x Δ
Δ Δ
LL(1) грамматики распознаются с помощью метода рекурсивного спуска.
Пусть дана грамматика:
1. I -> LP {ab)
2. P -> LP {ab}
3. P -> DP {1,2}
4. P -> E N(P)ﺩ
5. L -> a|b
6. D -> 1|2
Метод рекурсивного спуска позволяет писать программы синтаксического анализа на языке, допускающем рекурсию, прямо по грамматическим правилам.
Метод рекурсивного спуска:
###########
int c
main()
{I();printf(“+”);}
I()
{c=getchar();
Switch(c) {
case ‘a’:
case ‘b’: L();P(); break;
default printf (“-”); exit(0);
}
}
L() {}
D() {}
P()
{ c = getchar();
Switch(c) {
case ‘a’:
case ‘b’: L();P(); break;
case ‘1’:
case ‘2’: D();P(); break;
case “n” : break;
default printf (“-”); exit(1);
}
}
###################################
LR-грамматика
Left-Right most- самый правые части для самых левых нетерминальных символов.
Грамматика с предшествованием .
Правила расстановки отношений между символами грамматики :
1. Если Si и Sj входят в одну свёртку, то они равны Si =Sj
…Si Sj …
Свёртка –правая часть правила.
2. Если Sj в правой части свёртки, то Si < Sj
Si Sj…
3. …Si Sj => Si > Sj
4. …Si Sj … => Si > Sj
Все отношения не являются симметричными.
1. S -> sXfX | s  X X f f X
X X f f X
2. X -> x | s < x x > f f < x
3. X -> xY | x Y Y > f
4. Y -> ,x | x < , , x
5. Y -> ,xY |
В грамматике с предшествованием между двумя одинаковыми символами не стоят разные отношения.
├ s x , x f x ┤ расставим знаки в цепочке символов.
=> ├ < s < x < , x > f < x > ┤ =>
Y X
=> ├ < s < x < (, x) > f (< x >) ┤ =>
X
=> ├ < s < (x Y) > f X > ┤ => ├ < s X f X > ┤ = > ├ < S > ┤
YACC – BISON
Yet Another Compilator of Compilators
Предназначен для генерации программы на Си, которая бы проводила синтаксический разбор входной информации. Грамматика может быть неоднозначна, поэтому для преодоления этого нужно использовать правила предшествования.
Имеет следующую структуру:
%{
Раздел деклараций
}%
%token лексем
%%
Раздел правил Интерпретирует правила типа:
Нетерм. символ : цепочка символов {код на Си} {или}|цепочка символов{код на Си};
%%
Пользовательский код
Пример. Рассмотрим предыдущий пример.
s x, x f x
Программа будет состоять из двух частей: синтаксический разбор (на yacc) и лексический на lex).
В лексическом разборе мы будем определять буквы x, y, z и запятую. И передавать в yacc программу найденное.
1. На YYAC
##########prim1.y################
%token S X F Z
%%
es: S iks F iks {printf(“OK!”);} //первое правило
;
iks: X
| X igrek
;
igrek: Z X
| Z X igrek
;
%%
yyerror() { printf(" Ошибка! "); }
main() {
yyparse(); } //функция, которая получается из раздела правил
#####################################
2. На Lex
########prim1.l################
%{
#include "prim1_y.h" //там лексемы будут определены как макросы
%}
%%
s { return( S ); }
x { return( X ); }
f { return( F ); }
[,] { return( Z ); }
. { return( yytext[0] ); }
%%
##########################
Синтаксический разбор будет выглядеть так:
$ yacc -d -o prim1_y.c prim1.y
# по -d создается prim1_y.h, в котором описываются макросы X Y Z P
$ lex –o prim1_l.c prim1.l
$ cc -o prim1 prim1_y.c prim1_l.c
Семантический анализ
Используется для проверки типов данных при операциях и области действия переменных.
Атрибутная грамматика – это четверка G = <VN,VT, P, S >, в которой
VN - нетерминальный словарь (множество нетерминальных символов);
VT - терминальный словарь (множество терминальных символов ) ;
P - множество грамматических правил;
S Î VN - начальный нетерминальный символ.
A(x) множество атрибутных символов
Атрибут определяется для каждого правила, входящего в грамматику .
а0<i0>= fpa0<l0> fpa1<l1>… aj<ij>
ak<ik> атрибут xi
Атрибуты делятся на 2 вида :
1.Синтезируемые атрибуты
а<0>= fpa<0>(…)
2.Наследуемые атрибуты
x0→x1 … xi … xnp
а<i>= fpa<i>(…)
Таким образом, атрибутная грамматика :
АГ = <Г,Аs,Аi, R >
Г- контекстная свободная грамматика
Аs – множество синтезируемых атрибутов
Аi – множество наследуемых атрибутов
R- семантические правила
Пример : Число из 2сс перевести в 10сс(систему исчисления) 1011
Грамматика
P→S
S→B
S1→BS2
B→1|0
V(D)=V(S)
V(S)=V(B)*20 ; p(S)=1
V(S1)=V(B)*2p(S^2) +V(S2); p(S1)=P(S2)+1
Значения атрибутов терминальных символов – это константы, т.е. они определены ,но нет семантичных правил.
Дерево разбора обходится сверху вниз слева направо.
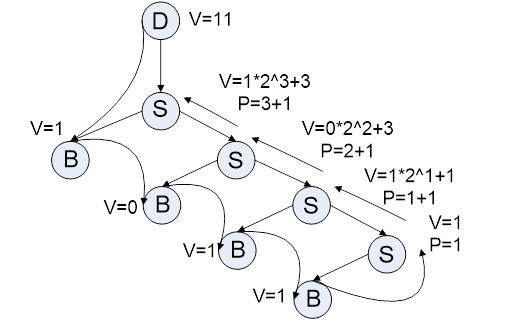
Система семантического анализа атрибутных грамматик с использованием грамматик.
ELEGANT, FGC-2,OX,RIE или можно использовать Lex иYacc.
#### B2d.l #####
%{
#include <stdlib.h>
# include <b2d_y.h>
%}
bit [0-9]
%%
{bit} {yylval.val=atoi(yytext); /*формирование числового значения, yylval- передаваемый в yacс значение */
Return(BIT);}
. {return(yytext[0]);} /* . любой символ*/
##############
#### B2d.y #####
%{
#include <math.h>
long double p=0;
%} // для передачи используется union
%union {
int val;
}
%token <val> BIT // лексемы, которые будут обмениваться Lex и Yacc
% type <val> str
%%
dec: . str {printf(“%d”,$1);}
;
str: BIT {$$=$<val>1;}
|BIT str {$$=$ <val>1*pow(2L,p+$1); p++;}
;
%%
Yyerror() {}
Main() {yyparse()}
##############
$ yacc –d –o bed_y.c b2d.y
$ lex –o b2d_l.c b2d..l
$ cc –o b2d b2d_l.c b2d_y.c –lfl –lm
-----
$ b2d <enter>
1011 <enter>
Оптимизация
1.Предварительные вычисления выражений.
x:=2 ; y:=3 ; z:=x+y+10; => z=15;
2. Исключение невыполнимых ветвей.
Switch
……..
Case : ……. Break; exit(0);
3. Выделение общих частей.
a:= (x+y)*z-35 |оптимизируем ==> w:= (x+y)*z; a:=w-35;
b:= (x+y)*z/a | b:=w/a;
4. Вынесение за цикл.
Выносятся значения, которые в цикле не вызываются.
… for (i=0; i<strlen(S); i++) printf(“%c”, S[i])…
… l=strlen(S); for (i=0; i<l; i++) …
5. Вычисление логических выражений.
if (i<strlen(str)&&str[i] !=’x’)
cand если не выполняется 1-ое условие, то не выполнять дальнейшие условия.
Лучше делать вложенные циклы.
6. Изменение последовательности команд с целью оптимизации межрегистровых передач и обращения к памяти.
/без примера/
Пример1. Язык логических схем.
 Метка 1;
Метка 1;
 Goto 1
Goto 1
P – условие;
U0 – начало
нет
]
да
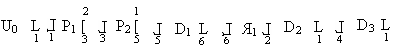
[ P1 : x > y; P2 : y > x; D1 : z:=x; D2 : x:=x-y; D3 : y:=y – x]
Пример2.
==>
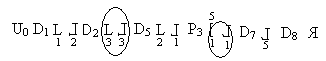
==>
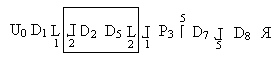
==>
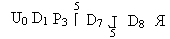
Генерация выходного кода
При рассмотрении вопросов генерации выходного текста надо иметь в виду то, что реально выходной текст программы после трансляции - это, как правило, не выполняемый код, а некоторая промежуточная форма, поскольку программа в дальнейшем может быть
загружена для выполнения в разные места памяти и т.д. С другой стороны, выполняемая
программа (или программа в близком к такой форме виде) машинно-зависима, то есть
использует конкретную систему команд и другие конкретные архитектурные особенности. Основная идея генерации выходного кода заключается в подстановке входных конструкций в готовые шаблоны.
Язык:
сreate id 0
create iid 0
create sch 3
create ssh 2
inc sch
loop sch
inc id
loop ssh
inc iid
pool
pool
print id
print iid
#### forc.l #####
%{ …
# include “forc_y.h” //файл с лексемами
%}
letter [a-z]
digit [0-9]
%%
inc {return (INC) ;}
create {return (CREATE) ;}
print {return (PRINT) ;}
loop {return (LOOP) ;}
pool {return (POOL) ;}
{letter}+ {strcpy(yylval.var, yytext); return(VAR);}
{digit}+ {sscanf(yytext,”%d”, &yylval.val); return(VAL);}
…
############
### forc.y #####
%union
{int val; char var[16];}
%token <var> VAR
%token <val> VAL
%token CREATE INC LOOP POOL PRINT
%%
prog: str {printf ( “main() {%s}”,$1);}
;
str: oper {sprintf($$,”%s”,$1);}
| oper str {sprintf($$,”%s n %s”,$1,$2);}
;
oper: CREATE VAR VAL {sprintf($$,”int %s=%d”,$<var>2, $<val>3);}
|INC VAR {sprintf($$,”%s++”,$<var>2);}
|LOOP VAR str POOL {sprintf($$,”for(;%s>=0;%s--){%s}”,<var>2,<var>2, $3);}
|PRINT VAR {sprintf($$,”printf(”%s”,%s)”, “%d”,$<var>2) ;}
%%
…
############
На более низком уровне для подстановки используются таблицы решений генерации выходного кода.
ADD [регистр или память], регистр
A1+A2
A1 регистр регистр память память
A2 регистр память регистр память
код ADD A1,A2 ADD A2,A1 ADD A1,A2 move A1,R
или ADD A2,R
ADD A2,A1
Загрузка программ
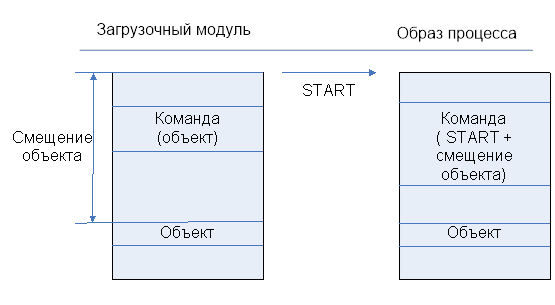
Загрузочный модуль, который получился в результате компиляции, может быть самодостаточным (в виде одного файла или программа перед загрузкой собирается из нескольких объектов).
Программа лежит на диске. Образ процесса загружен в оперативную память.
Виды загрузки :
1. Абсолютная загрузка
· Для однозадачной системы
· Для виртуальной адресации
1.1. с разделами памяти , с физическими непересекающимися адресами.
2. Относительная загрузка
Адреса в программе при загрузке пересчитываются
2.1. с базовой адресацией
Программист задаёт адреса относительно какого-то числа
3. Загрузка с использованием позиционно-независимого кода
Адресация относительно текущей команды
+ не надо перечитывать адреса
- не все процессы поддерживают такую адресацию
4. Оверлей = перекрытие
Абсолютная адресация
Самый простой способ загрузки при котором программа загружается с одного и тоже адреса.
Допустима загрузка с случаях :
1. однозадачная система (RT11)
2. в системах трансляции виртуального адреса физическим.
Начальное содержимое образа процесса формируется простым копированием загрузочного модуля в память.
a.out
 Формируются поля START => копируется текст, данные , стек => передаётся управление с позиции START
Формируются поля START => копируется текст, данные , стек => передаётся управление с позиции START
Абсолютная адресация с разделами памяти
Существует несколько допустимых стартовых адресов
 Если заранее неизвестен раздел,то готовится несколько загрузочных модулей.
Если заранее неизвестен раздел,то готовится несколько загрузочных модулей.
Относительная загрузка
Позволяет загружать программы каждый раз с нового адреса.
При загрузке пересчитываются адресные поля команд ,использующих абсолютную адресацию.
Таблица перемещений.

Относительная загрузка с базовой адресацией
Несколько регистров используется для хранения начала текста, данных, стека.
Эти регистры не используются для программистом (компилятором ), адресация в программе используется относительно их.
Команда (базовый регистр + смещение)
Загрузка с использованием позиционно - независимого кода.
Относительная адресация, адрес которой получается сложением адреса команды и её адресного кода.
Диагностика ишемической болезни сердца - лекция, которая пользуется популярностью у тех, кто читал эту лекцию.
-f PIC
В начале функции адрес точки её входа помещается в регистр и вся адресация осуществляется относительно его . Используется при создании разделяемых библиотек UNIX.
Оверлей = перекрытие.
Используется для отображения большого количества объектов в ограниченном адресном пространстве.

Необходимо правильно разделять процедуры между оверлеями.Менеджер оверлея при обращении к процедуре смотрит есть ли подключённая процедура в текущем оверлее, если есть-подключает.



















