
Организация процессов обработки данных в БД
ТЕМА 4. ОРГАНИЗАЦИЯ ПРОЦЕССОВ ОБРАБОТКИ ДАННЫХ В БД
Изучаемые вопросы:
1. Технологии обработки данных: OLTP и OLAP.
2. Понятие целостности базы данных.
3. Различные архитектурные решения, используемые при реализации многопользовательских СУБД.
Литература:
1. Технологии обработки данных: OLTP и OLAP.
OLTP-системы — системы оперативной обработки транзакций. Основная функция подобных систем заключается в одновременном выполнении большого количества коротких транзакций от большого числа пользователей. Сами транзакции выглядят относительно просто, например, "снять сумму денег со счета А, добавить эту сумму на счет В".
Рекомендуемые материалы
Системы OLTP характеризуются:
¾ поддержкой большого числа пользователей;
¾ малым временем отклика на запрос;
¾ относительно короткими запросами;
¾ участие в запросах небольшого числа таблиц.
Практически все запросы к базе данных в OLTP-системах состоят из команд вставки, обновления, удаления. Запросы на выборку в основном предназначены для предоставления пользователям возможности выбора из различных справочников. Большая часть запросов, таким образом, известна заранее еще на этапе проектирования системы. Таким образом, критическим для OLTP-приложений является скорость и надежность выполнения коротких операций обновления данных.
Исторически такие системы возникли в первую очередь, поскольку реализовывали потребности в учете, скорости обслуживания, сборе данных и пр. Однако вскоре пришло понимание, что сбор данных — не самоцель и накопленные данные могут быть полезны: из данных можно извлечь информацию.
И возникает другой тип систем (и соответственно, класс задач) — системы поддержки принятия решений DSS (Decision Support System), ориентированные анализ данных, на выполнение более сложных запросов, моделирование процессов предметной области, прогнозирование, нахождение зависимостей между данными (например, можно попытаться определить, как связан объем продаж товаров с характеристиками покупателей), для проведения анализа "что если:". (аналитические системы). Под DSS понимают человеко-машинный вычислительный комплекс, ориентированный на анализ данных и обеспечивающий получение информации, необходимой для принятия решений в сфере управления.
¾ использование больших объемов данных;
¾ добавление в систему новых данных происходит относительно редко крупными блоками (например, раз в квартал загружаются данные по итогам квартальных продаж из OLTP-приложения);
¾ данные, добавленные в систему, обычно никогда не удаляются;
¾ перед загрузкой данные проходят различные процедуры "очистки", связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны;
¾ небольшое число пользователей (аналитики);
¾ очень часто новый запрос формулируется аналитиком для уточнения результата, полученного в результате предыдущего запроса (интерактивность);
¾ скорость выполнения запросов важна, но не критична.
Перечисленные характеристики требуют особой организации данных, отличных от тех, что используются в OLTP-системах (нормализованные реляционные таблицы).
Аналитические системы, ориентированные на аналитика, можно разделить на
статические DSS, известные в литературе информационными системами руководителя (Executive Information Systems — EIS) и
динамические DSS.
EIS-системы содержат в себе предопределенные множества запросов и, будучи достаточными для повседневного обзора, неспособны ответить на все вопросы к имеющимся данным, которые могут возникнуть при принятии решений. Результатом работы такой системы, как правило, являются многостраничные отчеты, которые нельзя "покрутить", "развернуть" или "свернуть", чтобы получить желаемое представление данных и после тщательного изучения которых у аналитика появляется новая серия вопросов. Конечно, можно вызвать программиста (если он захочет придти), и он (если не занят) сделает новый отчет достаточно быстро — скажем, в течение часа (это очень сомнительно — так быстро в жизни не бывает: предположим, часа три). Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по несколько в час.
Вторая группа (динамические DSS), напротив, ориентированы на обработку нерегламентированных (ad hoc) запросов аналитиков к данным. Наиболее глубоко требования к таким системам рассмотрел в 1993 г. E. F. Codd, положившей начало концепции OLAP. В последние годы в этом направлении оформился ряд новых концепций хранения и анализа корпоративных данных:
¾ концепция хранилища данных (Data Warehouse);
¾ оперативная аналитическая обработка OLAP (On-Line Analytical Processing);
¾ интеллектуальный анализ данных — (Data Mining).
Концепция хранилища данных определяет процесс сбора, отсеивания, предварительной обработки и накопления данных с целью
¾ долговременного хранения данных (1);
¾ предоставления результирующей информации пользователям в удобной форме для статистического анализа и создания аналитических отчетов (2).
Концепция OLAP — концепция комплексного многомерного анализа данных, накопленных в хранилище. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям (чтобы не мешать оперативным пользователям). Но в этом случае мы рискуем наступить на свои грабли, поскольку беремся анализировать оперативные данные, которые напрямую для анализа непригодны.
Замечание: термин OLAP очень популярен в настоящее время и OLAP-системой зачастую называют любую DSS-систему, основанную на концепции хранилищ данных и обеспечивающих малое время выполнение (On-Line) аналитических запросов, не зависимо от того, используется ли многомерный анализ данных. Что не совсем верно.
Концепция интеллектуального анализа данных определяет задачи поиска функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
Примерная структура информационно-аналитической системы, построенной на основе хранилища данных, показана ниже. В конкретных реализациях отдельные компоненты этой схемы часто отсутствуют.
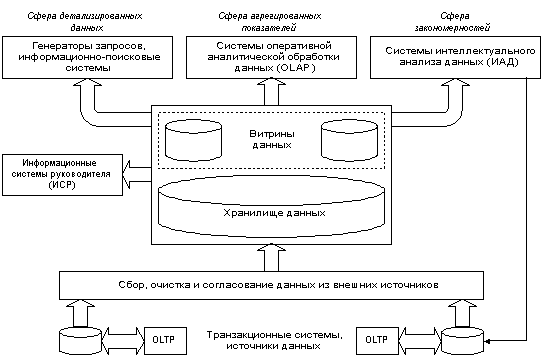
Рисунок 4.1. Структура OLAP
Какова побудительная причина появление концепции хранилищ данных?
Казалось бы, зачем строить хранилища данных — ведь они содержат заведомо избыточную информацию, которая и так имеется в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется рядом причинами, в том числе
¾ разрозненностью данных (OLTP-системы, текстовые отчеты, xls-файлы);
¾ хранением их в форматах различных СУБД и в разных узлах корпоративной сети.
Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах.
Есть и еще одна причина, оправдывающая появление отдельного хранилища — сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
Можно констатировать, что практически в любой организации сложилась парадоксальная ситуация: — информация вроде бы, где-то и есть, её даже слишком много, но она неструктурированна, несогласованна, разрознена, не всегда достоверна, её практически невозможно найти и получить. В результате можно говорить об отсутствие информации при наличии и даже избытке.
Для того, чтобы извлекать полезную информацию из данных, они должны быть организованы способом, отличным от принятого в OLTP-системах Почему?
В OLTP-системах используются нормализованные таблицы базы данных. Нормализация эффективна, если отношения часто перестраиваются (вставка,. . .), но дает отрицательный эффект в случае операции выборки (особенно в случае сложных запросов). А в DSS-системах только операции выборки, и данные редко меняются, поэтому данные целесообразно хранить в виде слабо нормализованных отношений, содержащих заранее вычисленные основные итоговые данные. Большая избыточность и связанные с ней проблемы тут не страшны, т.к. обновление происходит только в момент загрузки новой порции данных. При этом происходит как добавление новых данных, так и пересчет итогов.
Выполнение некоторых аналитических запросов требует хронологической упорядоченности данных. Реляционная модель не предполагает существования порядка записей в таблицах.
В случае аналитических запросов чаще используются не детальные, а обобщенные (агрегированные данные).
В результате данные, применяемые для анализа, стали выделять в отдельные специальные базы данных, впоследствии получивших название хранилищ данных (Data Warehouse).
Хранилище данных (определение Билла Инмона(Bill Inmon)) — предметно-ориентированный, интегрированный, привязанный ко времени и неизменяемый набор данных, предназначенный для поддержки принятия решений. Базовые требования к хранилищу данных:
Ориентация на предметную область. Хранилище должно разрабатываться с учетом специфики предметной области (клиенты, товары, продажи), а не прикладных областей деятельности (выписка счетов, контроль запасов, продажа товаров).
Интегрированность и внутренняя непротиворечивость. Поскольку данные в хранилище поступают из разных источников (OLTP-системы, архивы и пр.), необходимо привести их к единому формату (дата: 5 января, 5.01,:). В процессе загрузки хранилища должна быть обеспечена, очистка и согласованность данных.
Привязка ко времени. Учет хронологии достигается введением атрибутов "Дата" и "Время". Упорядочение по этим атрибутам позволяет сократить время выполнения аналитических запросов.
Неизменяемость. Данные не обновляются в оперативном режиме, а лишь регулярно пополняются из систем оперативной обработки по заданной дисциплине.
Поддержка высокой скорости получения данных из хранилища.
Возможность получения и сравнения так называемых срезов данных (slice and dice);
Полнота и достоверность хранимых данных;
Поддержка качественного процесса пополнения данных.
OLAP-технология
Термин OLAP был предложен в 1993 г. Эдвардом Коддом (E. Codd — автор реляционной модели данных) По Коду OLAP-технология — это технология комплексного динамического синтеза, анализа и консолидации больших объемов многомерных данных. Он же сформулировал 12 принципов OLAP, которые позже были переработано в так называемый тест FASMI:
Fast (быстрый) — предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
Analysis (анализ) — возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
Shared (разделяемой) — многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
Multidimensional (многомерной) — многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (ключевое требование OLAP);
Information (информации) — возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
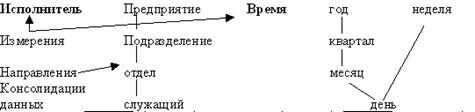
В самом общем виде OLAP=многомерное представление=куб
OLAP-технология представляет для анализа данные в виде многомерных (и, следовательно, нереляционных) наборов данных, называемых многомерными кубами (гиперкуб, метакуб, кубом фактов), оси которого содержат параметры, а ячейки — зависящие от них агрегатные данные
 |
При том гиперкуб является концептуальной логической моделью организации данных, а не физической реализацией их хранения, поскольку храниться такие данные могут и в реляционных таблицах ("реляционные БД были, есть и будут наиболее подходящей технологией для хранения корпорационных данных" — E. Codd).
По Кодду, многомерное концептуальное представление (multi-dimensional conceptual view) представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса (то, по чему ведется анализ). Например, для продаж это могут быть тип товара, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей - измерений (dimensions) — находятся данные, количественно характеризующие процесс — меры (measures): суммы и иные агрегатные функции (min, max, avg, дисперсия, ср. отклонение и пр.). Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения (уровней иерархии), где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению (различные уровни их детализации). В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений.
Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных.
Поддержка многомерной модели данных и выполнение многомерного анализа данных осуществляются отдельным приложением или процессом, называемым OLAP-сервером. Клиентские приложения могут запрашивать требуемое многомерное представление и в ответ получать те или иные данные. При этом OLAP-серверы могут хранить многомерные данные разными способами
2. Понятие целостности базы данных.
Обеспечение целостности данных является важнейшей задачей при проектировании и эксплуатации систем обработки данных (СОД). Проблема целостности состоит в обеспечении правильности данных в базе данных в любой момент времени». Целостность – актуальность и непротиворечивость информации, ее защищенность от разрушения и несанкционированного изменения.
Целостность является одним из аспектов информационной безопасности наряду с доступностью – возможностью с приемлемыми затратами получить требуемую информационную услугу, и конфиденциальностью – защитой от несанкционированного прочтения.
Целостность данных – неотъемлемое свойство базы данных, и ее обеспечение является важнейшей задачей проектирования БнД. Целостность данных описывается набором специальных предложений, называемых ограничениями целостности. Ограничения целостности представляют собой утверждения о допустимых значениях отдельных информационных единиц и связях между ними. Эти ограничения определяются в большинстве случаев особенностями предметной области. При выполнении операций над БД проверяется выполнение ограничений целостности.
Различают логическую и физическую целостность БД.
Логическая целостность – состояние БД, характеризующееся отсутствием нарушений ограничений целостности, присущих логической модели данных (т.е. неявных ограничений), и явных ограничений, заданных декларативным или процедурным путем.
Физическая целостность – отсутствие нарушений спецификаций схемы хранения, а также физических разрушений данных на носителе.
Для контроля целостности БД применяется также механизм триггеров. Триггер – это действие, которое активизируется при наступлении указанного события (вставки, удаления, обновления записи). Триггеры специфицируются в схеме базы данных. Более широким понятием по отношению к триггеру является понятие хранимая процедура. Хранимые процедуры описывают фрагменты логики приложения, хранятся и исполняются на сервере, что позволяет улучшать характеристики производительности.
Транзакции. Транзакция представляет собой законченную совокупность действий над БД, которая переводит ее из одного целостного в логическом смысле состояния в другое.
К транзакциям предъявляется набор требований, известный под названием ACID (Atomicity, Consistency, Isolation, Durability). Эти требования вытекают из определения транзакции.
Атомарность. Транзакция представляет собой некоторый набор законченных действий. Система обеспечивает их выполнение по принципу «все или ничего» - либо выполняются все действия, тогда транзакция «фиксируется»; либо, если возможность выполнить все действия отсутствует, например, в случае сбоев, транзакция «откатывается» назад, а БД остается в исходном состоянии.
Согласованность. Предполагается, что в результате выполнения транзакции система переходит из одного корректного состояния в другое.
Изолированность. При выполнении транзакции данные могут временно находиться в несогласованном состоянии. Такие данные не должны быть видны другим транзакциям, пока изменения не будут завершены (т.е. пока вес модификации не будут формально зафиксированы).
Долговечность. Если транзакция зафиксирована, то ее результаты должны быть долговечными. Состояния всех объектов сохранятся даже в случае аппаратных или системных сбоев.
Блокировки. Наиболее популярные алгоритмы управления одновременным доступом основаны на механизме блокировок. Блокировка заключается в запрещении некоторых операций над данными, если ее обрабатывает другой пользователь. В такой схеме всякий раз, когда транзакция пытается получить доступ к какой-либо единице данных, на эту единицу накладывается блокировка.
3. Различные архитектурные решения, используемые при реализации многопользовательских СУБД.
Понятие базы данных изначально предполагало возможность решения многих задач несколькими пользователями. Важнейшей характеристикой современных СУБД является наличие многопользовательской технологии работы. Разная реализация таких технологий в разное время была связана как с основными свойствами вычислительной техники, так и с развитием ПО.
Централизованная архитектура.
При использовании этой технологии база данных, СУБД и прикладная программа (приложение) располагаются на одном компьютере (мэйнфрейме или персональном компьютере) (рис.4.2). Для такого способа организации не требуется поддержки сети и все сводится к автономной работе. Работа построена следующим образом:
База данных в виде набора файлов находится на жестком диске компьютера.
На том же компьютере установлены СУБД и приложение для работы с БД.
Пользователь запускает приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации.
Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД.
СУБД инициирует обращения к данным, обеспечивая выполнение запросов пользователя.
Результат СУБД возвращает в приложение.
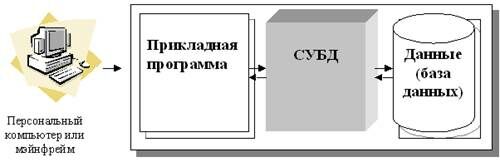 |
Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
Рисунок 4.2. Централизованная архитектура
Подобная архитектура использовалась в первых версиях СУБД DB2, Oracle. Основным недостатком этой модели является резкое снижение производительности при увеличении числа пользователей.
Технология с сетью и файловым сервером (архитектура "файл-сервер").
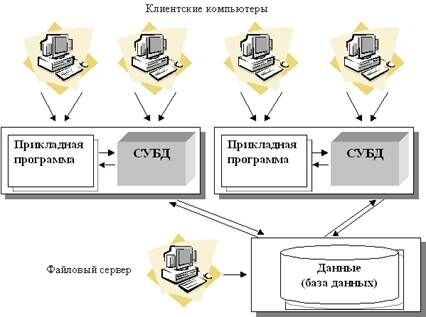 |
Увеличение сложности задач, появление персональных компьютеров и локальных вычислительных сетей явились предпосылками появления новой архитектуры файл-сервер. Эта архитектура баз данных с сетевым доступом предполагает назначение одного из компьютеров сети в качестве выделенного сервера, на котором будут храниться файлы базы данных. В соответствии с запросами пользователей файлы с файл-сервера передаются на рабочие станции пользователей, где и осуществляется основная часть обработки данных. Центральный сервер выполняет в основном только роль хранилища файлов, не участвуя в обработке самих данных (рис. 4.3.).
Рисунок 4.3. Архитектура "файл-сервер".
Работа построена следующим образом:
БД в виде набора файлов находится на жестком диске специально выделенного компьютера (файлового сервера).
Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлены СУБД и приложение для работы с БД.
На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации.
Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на файловом сервере.
СУБД инициирует обращения к данным, находящимся на файловом сервере, в результате которых часть файлов БД копируется на клиентский компьютер и обрабатывается, что обеспечивает выполнение запросов пользователя (осуществляются необходимые операции над данными).
При необходимости данные отправляются назад на файловый сервер с целью обновления БД.
Результат СУБД возвращает в приложение.
Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
В рамках архитектуры "файл-сервер" были выполнены первые версии популярных так называемых настольных СУБД, таких, как dBase и Microsoft Access. Основные недостатки данной архитектуры:
При одновременном обращении множества пользователей к одним и тем же данным производительность работы резко падает.
Неоптимально расходуются ресурсы клиентского компьютера и сети. В результате возрастает сетевой трафик и увеличиваются требования к аппаратным мощностям пользовательского компьютера.
Используется навигационный подход, ориентированный на работу с отдельными записями.
Низкий уровень безопасности – хищение и нанесение вреда, внесение ошибочных изменений.
Недостаточно развитый аппарат транзакций служит источником ошибок в плане нарушения смысловой и ссылочной целостности информации при одновременном внесении изменений.
Технология "клиент – сервер".
Использование технологии "клиент - сервер" предполагает наличие некоторого количества компьютеров, объединенных в сеть, один из которых выполняет особые управляющие функции (является сервером сети).
Архитектура "клиент - сервер" разделяет функции приложения пользователя (клиента) и сервера. Приложение-клиент формирует запрос к серверу, на котором расположена БД, на структурном языке запросов SQL. Удаленный сервер принимает запрос и переадресует его SQL-серверу БД. SQL-сервер – специальная программа, управляющая удаленной БД. SQL-сервер обеспечивает выполнение запроса в базе данных, формирование результата выполнения запроса и выдачу его приложению-клиенту. Клиентский компьютер лишь отсылает запрос к серверной БД и получает результат, после чего интерпретирует его необходимым образом и представляет пользователю. Т.к. клиентскому приложению посылается результат выполнения запроса, по сети "путешествуют" только те данные, которые необходимы клиенту. В итоге снижается нагрузка на сеть. Поскольку выполнение запроса происходит там же, где хранятся данные (на сервере), нет необходимости в пересылке больших пакетов данных. SQL-сервер оптимизирует полученный запрос таким образом, чтобы он был выполнен в минимальное время с наименьшими накладными расходами. Архитектура системы представлена на рис. 4.4.
Все это повышает быстродействие системы и снижает время ожидания результата запроса. При выполнении запросов сервером существенно повышается степень безопасности данных, поскольку правила целостности данных определяются в базе данных на сервере и являются едиными для всех приложений, использующих эту БД. Таким образом, исключается возможность определения противоречивых правил поддержания целостности.
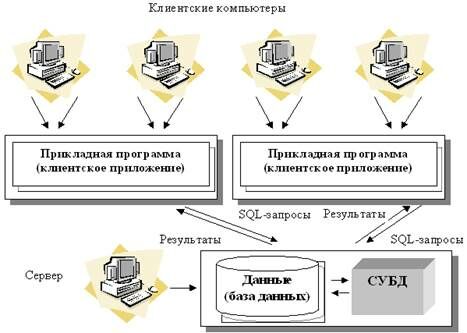
Рисунок 4.4. Архитектура "клиент – сервер".
Итак, в результате работа построена следующим образом:
БД в виде набора файлов находится на жестком диске специально выделенного компьютера (сервера сети).
СУБД располагается также на сервере сети.
Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлено клиентское приложение для работы с БД.
На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к СУБД, расположенной на сервере, на выборку/обновление информации. Для общения используется специальный язык запросов SQL, т.е. по сети от клиента к серверу передается лишь текст запроса.
СУБД инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на сервере.
СУБД инициирует обращения к данным, находящимся на сервере, в результате которых на сервере осуществляется вся обработка данных и лишь результат выполнения запроса копируется на клиентский компьютер. Таким образом СУБД возвращает результат в приложение.
Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
Функции приложения-клиента: посылка запросов; интерпретация запросов; представление результатов.
Функции серверной части: прием запросов; обеспечение системы безопасности и разграничение доступа; управление целостностью БД; реализация стабильности многопользовательского режима работы.
В архитектуре "клиент - сервер" работают так называемые "промышленные" СУБД. Промышленными они называются из-за того, что именно СУБД этого класса могут обеспечить работу ИС масштаба среднего и крупного предприятия, организации, банка (MS SQL Server, Oracle, InterBase и т.д.).
SQL-сервер обслуживается отдельным сотрудником или группой сотрудников. Они управляют физическими характеристиками БД, производят оптимизацию, настройку и переопределение различных компонентов БД, создают новые БД, изменяют существующие и т.д.
Рассмотрим основные достоинства данной архитектуры по сравнению с архитектурой "файл-сервер":
Существенно уменьшается сетевой трафик.
Уменьшается сложность клиентских приложений (большая часть нагрузки ложится на серверную часть), а, следовательно, снижаются требования к аппаратным мощностям клиентских компьютеров.
Наличие специального программного средства – SQL-сервера – приводит к тому, что существенная часть проектных и программистских задач становится уже решенной.
Существенно повышается целостность и безопасность БД.
К числу недостатков можно отнести более высокие финансовые затраты на аппаратное и программное обеспечение, а также определенные трудности со своевременным обновлением клиентских приложений на всех компьютерах-клиентах.
Трехзвенная (многозвенная) архитектура "клиент – сервер".
Трехзвенная (в некоторых случаях многозвенная) архитектура представляет собой дальнейшее совершенствование технологии "клиент - сервер". Рассмотрев архитектуру "клиент - сервер", можно заключить, что она является 2-звенной: первое звено – клиентское приложение, второе звено – сервер БД + сама БД. В трехзвенной архитектуре вся бизнес-логика (деловая логика), ранее входившая в клиентские приложения, выделяется в отдельное звено, называемое сервером приложений. При этом клиентским приложениям остается лишь пользовательский интерфейс. Так, в качестве клиентского приложения в описанном выше примере выступает Web-браузер.Теперь при изменении бизнес-логики более нет необходимости изменять клиентские приложения и обновлять их у всех пользователей. Кроме того, максимально снижаются требования к аппаратуре пользователей.
Итак, в результате работа построена следующим образом:
БД в виде набора файлов находящихся на жестком диске специально выделенного компьютера(сервера сети).
СУБД располагается также на сервере сети.
Существует специально выделенный сервер приложений, на котором располагается программное обеспечение (ПО) делового анализа (бизнес-логика).
Существует множество клиентских компьютеров, на каждом из которых установлен так называемый "тонкий клиент" – клиентское приложение, реализующее интерфейс пользователя.
Если Вам понравилась эта лекция, то понравится и эта - Назначения запорной арматуры.
На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение – тонкий клиент. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к ПО делового анализа, расположенному на сервере приложений.
Сервер приложений анализирует требования пользователя и формирует запросы к БД. Для общения используется специальный язык запросов SQL, т.е. по сети от сервера приложений к серверу БД передается лишь текст запроса.
СУБД инкапсулирует внутри себя все сведения о физической структуре БД.
СУБД инициирует обращения к данным, находящимся на сервере, в результате которых результат выполнения запроса копируется на сервер приложений.
Сервер приложений возвращает результат в клиентское приложение (пользователю).
Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.



















