
Проектирование баз данных
ТЕМА 3 ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ
Изучаемые вопросы:
1. Трехуровневая архитектура ANSI/SPARC.
2. Жизненный цикл БД.
3. Типы моделей данных в БД.
Литература: [2] глава 5, [7] глава 2, [11] глава 3.
1. Трехуровневая архитектура ANSI/SPARC
Трехуровневая архитектура была впервые предложена в 1975 году Комитетом планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) национального Института Стандартизации США (American National Standard Institute – ANSI). Поэтому модель стала называться ANSI/SPARC.
Рекомендуемые материалы
Цель трехуровневой архитектуры заключается в отделении пользовательского представления БД от ее физического представления.
Причины, по которым необходимо выполнить такое разделение:
1) Каждый пользователь должен иметь возможность обращаться к одним и тем же данным, используя свое собственное представление о них. Каждый пользователь должен иметь возможность изменять свое представление о данных, причем это изменение не должно оказывать влияния на других пользователей.
2) Взаимодействие пользователя с БД не должно зависеть от особенностей хранения в ней данных.
3) Администратор БД должен иметь возможность изменять структуру хранения данных в БД, не оказывая влияния на пользовательские представления.
4) Логическая структура БД не должна зависеть от таких изменений физических аспектов хранения информации, как переключение на новое устройство хранения.
5) Администратор БД должен иметь возможность изменять концептуальную или логическую структуру БД без какого-либо влияния на всех пользователей.
Таким образом, в модели ANSI/SPARC отражение предметной области представлено моделями данных трех архитектурных уровней: внешнего, концептуального, внутреннего.
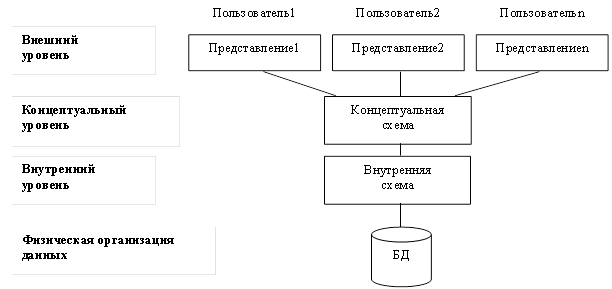
Рисунок 3.1 – Трехуровневая архитектура БД
Внешний уровень описывает ту часть БД, которая относится к каждому пользователю. Внешний уровень состоит из нескольких различных внешних представлений БД. Каждый пользователь имеет дело с представлением реального мира, выраженным в наиболее удобной для него форме. Внешнее представление содержит только те сущности, атрибуты и связи реального мира, которые интересны пользователю. Другие сущности, атрибуты и связи, которые ему неинтересны, также могут быть представлены в БД, но пользователь может даже не подозревать об их существовании.
На внешнем уровне имеется несколько внешних схем или подсхем, которые соответствуют разным представлениям данных.
Концептуальный уровень представляет обобщающее представление БД. Этот уровень описывает то, какие данные хранятся в БД, а также связи, существующие между ними.
Концептуальный уровень является промежуточным. Этот уровень содержит логическую структуру всей БД (с точки зрения АБД). Однако этот уровень не содержит никаких сведений о методах хранения данных.
Внутренний уровень содержит физическое представление БД в компьютере. Этот уровень описывает, как информация хранится в БД.
Внутренний уровень описывает физическую реализацию БД и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства.
Ниже внутреннего уровня находится физический уровень, который контролируется ОС, но под руководством СУБД.
Трехуровневая архитектура СУБД ANSI-SPARC, включающая внешний, концептуальный и внутренний уровни, позволяет обеспечить независимость хранимых данных от использующих их программ: внешний уровень экранирован от приложений системой управления БД, физический уровень экранирован от СУБД операционной системой (ОС) – в согласии с принципом независимости БД как «сверху» (от прикладных программ), так и «снизу» (от вычислительной аппаратуры).
Информационные данные любого пользователя в БД должны быть независимы от всех других пользователей. Однако, т. к. информационная модель рассчитана на развитие концептуальной модели, то вносимые в нее изменения не должны оказывать влияния на существующие внешние модели. Это первый уровень независимости данных - логическая независимость.
С другой стороны, внешние модели пользователей никак не связаны с типом физической памяти, в которой будут храниться данные, и с физическими методами доступа к этим данным. Это положение отражает второй уровень независимости данных - физическая независимость.
2. Жизненный цикл БД
БД является фундаментальным компонентом более широкого понятия - информационной системы (ИС). Следовательно, жизненный цикл приложений БД неразрывно связан с жизненным циклом ИС. Этапы жизненного цикла БД показаны на рис. 7.
Рассмотрим основные действия, выполняемые на каждом этапе жизненного цикла:
1) Планирование разработки БД. Этап разработки начинается с маркетинга, т. е. исследования рынка программного обеспечения, поиска аналогов, выяснения потребности в БД.
Планирование разработки БД состоит в определении трех основных компонентов:
- требуемого объема работы;
- необходимых ресурсов;
- общей стоимости проекта.
Планирование разработки БД также должно включать разработку стандартов, которые определяют, как будет осуществляться сбор данных, каким будет их формат, какая потребуется документация и как будет выполняться проектирование и реализация приложений.
2) Определение требований к системе. Определение диапазона действия и границ приложения БД, состав его пользователей и областей применения.
3) Сбор и анализ требований пользователей.
Необходимая для проектирования БД информация может быть собрана следующими способами:
- посредством опроса отдельных пользователей предметной области;
- с помощью наблюдений за деятельностью предметной области;
- посредством изучения документов, которые используются для сбора или представления информации;
- с помощью анкет, предназначенных для сбора информации у широкого круга пользователей;
- за счет использования опыта проектирования других подобных систем.
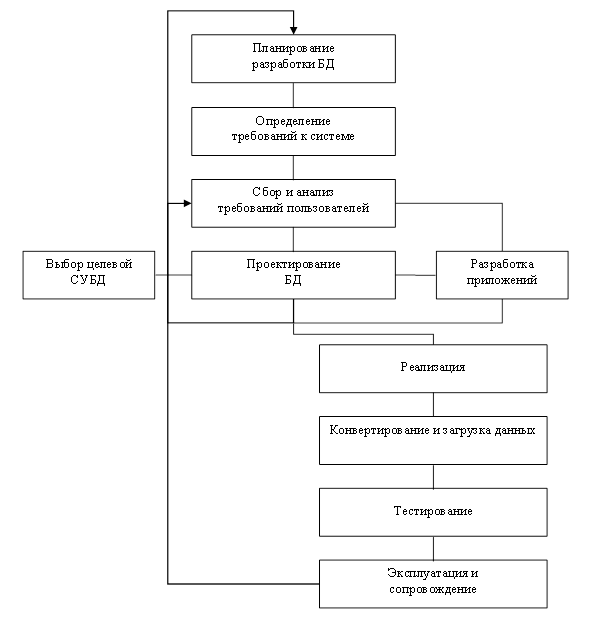
Рисунок 3.2 - Жизненный цикл БД
Собранная на этом этапе информация может быть плохо структурирована и включать некоторые неформальные заявления пользователей, которые впоследствии потребуется преобразовать и представить в виде более четко сформулированных требований.
4) Проектирование БД. Полный цикл разработки включает концептуальное, логическое и физическое проектирование БД.
Существует два основных подхода к проектированию систем БД: «нисходящий » и «восходящий ».
При восходящем подходе работа начинается с самого нижнего уровня – уровня определения атрибутов (т. е. свойств сущностей), которые на основе анализа существующих между ними связей группируются в отношения, представляющие типы сущностей и связи между ними. Восходящий подход лучше всего подходит для проектирования простых БД с относительно небольшим количеством атрибутов. Однако использование этого подхода существенно усложняется при проектировании БД с большим количеством атрибутов, установить среди которых все существующие функциональные зависимости довольно затруднительно.
Более подходящей стратегией проектирования сложных БД является использование нисходящего подхода. Начинается этот подход с разработки моделей данных, которые содержат несколько высокоуровневых сущностей и связей, затем работа продолжается в виде серии нисходящих уточнений низкоуровневых сущностей, связей и относящихся к ним атрибутов.
5) Выбор целевой СУБД (необязательно). На этом этапе выполняется выбор наиболее подходящей СУБД для приложения БД.
6) Разработка приложений. Определение пользовательского интерфейса и прикладных программ, которые используют и обрабатывают БД.
7) Реализация. Реализация БД начинается с ее распространения для коммерческих и свободных продуктов или внедрения для собственных разработок и заказных программ. В обоих случаях различают БД, которые не требуют вмешательства специалиста для начала эксплуатации, и БД, нуждающиеся в начальной настройке. Внедрение БД обычно производится с участием разработчиков.
8) Конвертирование и загрузка данных. Перенос любых существующих данных в новую БД и модификация любых существующих приложений с целью организации совместной работы с новой БД (выполняется в том случае, если новая БД заменяет старую).
9) Тестирование. Приложение БД тестируется с целью обнаружения ошибок, а также его проверки на соответствие всем требованиям, выдвинутым пользователями.
Пользователи должны быть вовлечены в процесс тестирования. По завершении тестирования процесс создания прикладной системы считается законченным, и она может быть передана пользователям в промышленную эксплуатацию.
10) Эксплуатация и сопровождение. На этом этапе приложение БД считается полностью разработанным и реализованным. Впредь вся система будет находиться под постоянным наблюдением и соответствующим образом поддерживаться. В случае необходимости в функционирующее приложение могут вноситься изменения, отвечающие новым требованиям. Реализация этих изменений проводится посредством повторного выполнения некоторых из перечисленных выше этапов жизненного цикла.
Жизненный цикл БД заканчивается вместе с прекращением ее распространения и сопровождения. Обычно это происходит при моральном устаревании БД.
БД всегда сопровождается документацией, которая содержит следующую информацию:
- характеристика БД (условия предоставления услуг, характер обработки информации, форма собственности, степень доступности, форма представления информации, тип используемой модели данных, характер организации хранения данных, а также предметная область, автор, версия и др.);
- руководство программиста - описание способов настройки БД для решения конкретных задач (в некоторых случаях может отсутствовать);
- руководство пользователя - описание интерфейса пользователя, возможностей БД и процесса ее установки, способов разрешения конфликтных ситуаций.
Обычно документация представляется в бумажной форме или в электронном виде на компакт-диске. Часть документации дублируется во встроенной в программу справочной системе.
3. Модели данных
Ядром любой БД является модель данных. Модель данных – интегрированный набор понятий для описания данных, связей между ними и ограничений, накладываемых на данные. Модель данных – средство абстракции, позволяющее видеть информационное содержание (обобщенную структуру), а не их конкретные значения.
Классические модели: иерархическая, сетевая, реляционная.
Современные: постреляционная, многомерная, объектно-ориентированная.
3.1. Иерархическая модель данных
Деревья. Дерево представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел – корень, являющийся входом в структуру. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемым исходным узлом для данного узла. Каждый элемент имеет только один исходный. Каждый элемент может быть связан с одним или несколькими элементами на более низком уровне, которые называются подчиненными. Между исходным узлом и подчиненными узлами имеется отношение «один – ко – многим». Между двумя узлами может быть только одна связь.
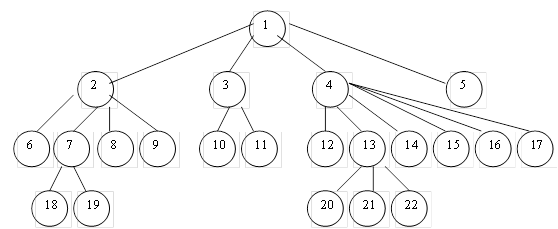
Рисунок 4.1 – Иерархическая модель представления данных
Иерархические БД используют древовидную структуру для работы с данными. Доступ к данным начинается с поиска по общим категориям и идет по пути дальнейшей детализации категорий, пока не будет получена необходимая информация.
Важной особенностью иерархической структуры является то, что в ней подчиненные экземпляры не могут существовать без наличия исходных экземпляров. Для доступа к отдельным данным в иерархической системе необходимо пройти последовательный перебор элементов, начиная с корневого узла.
Преимущество - целостность на уровне ссылок обеспечивается автоматически, потому что узлы полностью зависят от других узлов.
Недостатки:
1) Невозможность хранения узлов, которые не имеют родительских, т. е. подобная структура не позволяет достаточно просто моделировать характер экземпляров данных из реального мира.
2) Трудность моделирования связей типа «многие – ко – многим». Включение связей такого типа приводит к необходимости дублирования данных.
На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.
3.2. Сетевые модели данных
В сетевой структуре любой элемент может быть связан с любым другим элементом, и каждый из элементов может являться входом в структуру. Данные в сетевой модели представлены в виде совокупностей записей, а связи – в виде наборов. Сетевая модель является обобщением иерархической модели.
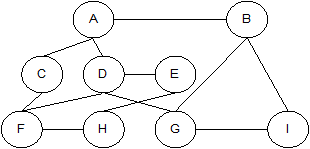
Рисунок 4.2 – Сетевая модель представления данных
Сетевую структуру также можно описать с помощью исходных и подчиненных элементов: каждый элемент может иметь как несколько подчиненных, так и несколько исходных элементов. В ней подчиненные элементы располагаются ниже исходных. В простых сетевых структурах между парой элементов поддерживается отношение «один – ко – многим».
В сетевых БД все данные считаются потенциально взаимосвязанными. Примером может служить Служба поиска информации, где могут быть вызваны документы, относящиеся к какому-либо делу или имеющие определенную ссылку. Существует функция ключевого слова, позволяющая «помечать» некоторые слова в тексте, как ключевые. Операция вызова выведет названия тех документов, в которых присутствуют эти слова.
Недостатки:
1) Обладает ограниченной гибкостью по отношению к изменению требований к данным и методам доступа.
2) Доступ к данным осуществляется путем перемещения (навигации) по структуре.
3) При работе с сетевыми БД прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру БД для осуществления навигации среди различных экземпляров, наборов, записей и т.п. «Сетевая БД – это самый верный способ потерять данные».
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
Иерархическая и сетевая модели считаются моделями БД первого поколения. Помимо перечисленных выше их недостатков этим двум моделям присущи общие недостатки:
1) Даже для выполнения простых запросов с использованием переходов и доступом к определенным записям необходимо создавать достаточно сложные программы.
2) Независимость от данных существует лишь в минимальной степени.
3) Отсутствие общепризнанных теоретических основ.
3.3. Реляционная модель данных
В математических дисциплинах существует понятие «отношение » (relation), физическим представлением которого является таблица. Отсюда и произошло название модели – реляционная.
Применительно к БД понятия «реляционная БД» и «табличная БД» являются синонимами. Реляционные базы получили наибольшее распространение в мире. Почти все продукты БД, созданные с конца 70-х годов, являются реляционными.
Реляционные СУБД относятся к СУБД второго поколения.
Цели создания реляционной модели данных:
1) Обеспечение более высокой степени независимости от данных.
2) Создание прочного фундамента для решения проблем непротиворечивости и избыточности данных.
3) Расширение языков управления данными за счет включения операций над множествами.
Реляционная модель является удобной и наиболее привычной формой представления данных в виде таблицы (отношения). Каждое отношение имеет имя и состоит из поименованных атрибутов (столбцов) данных. Одним из основных преимуществ реляционной модели является ее однородность. Все данные хранятся в таблицах, в которых каждая строка имеет один и тот же формат. Каждая строка в таблице представляет некоторый объект реального мира или соотношение между объектами.
Основные понятия:
1) реляционная БД – набор нормализованных отношений;
2) отношение – файл, плоская таблица, состоящая из столбцов и строк; таблица, в которой каждое поле является атомарным;
3) домен – совокупность допустимых значений, из которой берутся значения соответствующих атрибутов определенного отношения. С точки зрения программирования, домен – это тип данных;
4) кортеж – запись, строка таблицы;
5) кардинальность - количество строк в таблице;
6) атрибуты – поименованные поля, столбцы таблицы;
7) степень отношения - количество полей (столбцов);
8) первичный ключ – уникальный идентификатор с неповторяющимися записями – столбец или некоторое подмножество столбцов, которые единственным образом определяют строки.
Первичный ключ, который включает более одного столбца, называется множественным, или комбинированным, или составным, или суперключом.
Правило целостности объектов утверждает, что первичный ключ не может быть полностью или частично пустым.

|
| ФИО | Год рожд. | Должность | Кафедра |
| 1. | Иванов И. И. | 1958 | Зав. каф. | 22 |
| 2. | Сидоров С. С. | 1963 | Проф. | 22 |
| 3. | Андреева Г. Г. | 1955 | Проф. | 22 |
| 4. | Цветкова С. С. | 1960 | Доцент | 22 |
| 5. | Козлов К. К. | 1959 | Доцент | 22 |
| 6. | Петров П. П. | 1960 | Ст. преп. | 22 |
 №
№Рисунок 4.3 – Реляционная модель
9) внешний ключ – это столбец или подмножество столбцов одной таблицы, которые могут служить в качестве первичного ключа для другой таблицы. Внешний ключ таблицы является ссылкой на первичный ключ другой таблицы. Поскольку целью построения БД является хранение всех данных, по возможности, в одном экземпляре, то если некий атрибут присутствует в нескольких отношениях, то его наличие обычно отражает определенную связь между строками этих отношений.
Правило ссылочной целостности гласит: внешний ключ может быть либо пустым, либо соответствовать значению первичного ключа, на который он ссылается. Внешние ключи реализуют связи между таблицами БД.
Внешний ключ, как и первичный ключ, может представлять собой комбинацию столбцов. На практике внешний ключ всегда будет составным, если он ссылается на составной первичный ключ другой таблицы. Количество столбцов и их типы данных в первичном и внешнем ключах должны совпадать.
Если таблица связана с несколькими другими таблицами, она может иметь несколько внешних ключей.
Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы.
Пример реляционной модели, построенной на основе отношений: СТУДЕНТ, СЕССИЯ, СТИПЕНДИЯ.
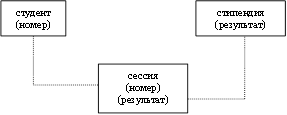 |
Таблицы Студент и Сессия имеют совпадающие ключи (номер), что дает возможность легко организовать связи между ними. Таблица Сессия имеет первичный ключ Номер и содержит внешний ключ Результат, который обеспечивает ее связь с таблицей Стипендия.
Операции над отношениями (таблицами)
А) объединение
Объединением 2-х отношений называется отношение, содержащее множество записей, принадлежащих либо первому, либо 2-му отношениям, либо обоим отношениям одновременно.
Пример: отношения П1 и П2 содержать перечень предметов, изучаемых на 1 и 2 курсах соответственно. Отношение П3 содержит общий перечень предметов.
П1 П2 П3
| Код предмета | Название | Код предмета | Название | Код предмета | Название | ||
| 110 | История | 015 | Математика | 001 | История | ||
| 015 | Математика | 021 | Информатика | 015 | Математика | ||
| 021 | Информатика | 030 | Экономика | 021 | Информатика | ||
| 011 | Философия | 017 | Финансы | 011 | Философия | ||
| 003 | Физ-ра | 003 | Физ-ра | 017 | Финансы | ||
| 003 | Физ-ра | ||||||
| 030 | экономика |
Б) Пересечение
Это отношение, которое содержит множество записей, принадлежащих одновременно и 1 и 2-му отношениям.
Результат пересечения П1 и П2 – П4.
| Код предмета | Название |
| 015 | Математика |
| 021 | Информатика |
| 003 | Физ-ра |
В) Разность
Это отношение, содержащее множество записей, принадлежащих П1 и не принадлежащих П2.
Г) Расширенное произведение
Это отношение, полученное сцеплением каждой записи отношения Т1 с каждой записью отношения Т2.
Т1 – предметы на сессию для всех групп;
Т2 – перечень всех групп;
Т3 – результат произведения.
Т1 Т2 Т3
| Код предмета | Название | Группа | Код предмета | Название | Группа | ||
| 015 | Математика | 25 | 015 | Математика | 25 | ||
| 021 | Информатика | 26 | 021 | Информатика | 25 | ||
| 001 | история | 001 | история | 25 | |||
| 015 | Математика | 26 | |||||
| 021 | Информатика | 26 | |||||
| 001 | история | 26 |
Каждая реляционная таблица обладает следующими свойствами:
¾имеет имя, которое отличается от имен всех других таблиц;
¾данные в ячейках таблицы должны быть структурно неделимыми. Недопустимо, чтобы в ячейке таблицы содержалось более одной порции информации. Например, номер и серия паспорта должны располагаться в разных столбцах таблицы;
¾все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
¾каждый столбец имеет уникальное имя;
¾одинаковые строки в таблице отсутствуют;
¾порядок следования строк и столбцов может быть произвольным, независимо от их переупорядочивания отношение будет оставаться одним и тем же, а потому иметь тот же смысл.
Концепция реляционной модели определяется следующими 12 правилами
Кодда:
1) Правило информации. Вся информация в БД должна быть предоставлена на логическом уровне и только одним способом – в виде значений, содержащихся в таблицах.
2) Правило гарантированного доступа. Логический доступ ко всем и каждому элементу данных (атомарному значению) в РБД должен обеспечиваться путем использования комбинации имени таблицы, первичного ключа и имени столбца.
3) Правило поддержки недействительных значений. В РБД должна быть реализована поддержка недействительных значений (NULL), которые отличаются от строки символов нулевой длины, строки пробельных символов, от нуля или любого другого числа и используются для представления отсутствующих данных независимо от типа этих данных.
4) Правило динамического каталога, основанного на реляционной модели. Описание БД на логическом уровне должно быть представлено в том же виде, что и основные данные, чтобы пользователи, обладающие соответствующими правами, могли работать с ним с помощью того же реляционного языка, который они применяют для работы с основными данными. Т. е. БД должна содержать набор системных таблиц, описывающих структуру самой БД.
5) Правило исчерпывающего подъязыка данных. Реляционная система может поддерживать различные языки и режимы взаимодействия с пользователем. Однако должен существовать по крайней мере один язык (например, SQL), операторы которого можно представить в виде строк символов в соответствии с некоторым четко определенным синтаксисом и который поддерживает следующие элементы:
¾определение данных;
¾определение представлений;
¾обработку данных;
¾условия целостности;
¾идентификацию прав доступа;
¾границы транзакций (начало, завершение и отмена).
6) Правило обновления представлений. Все представления, которые теоретически можно обновить, должны быть доступны для обновления. Речь идет о виртуальных таблицах, которые позволяют показывать различным пользователям различные фрагменты структуры БД. Это правило сложнее всего реализовать на практике.
7) Правило добавления, обновления и удаления. Возможность работать с отношением как с одним операндом должна существовать не только при чтении данных, но и при добавлении, обновлении и удалении данных.
8) Правило независимости физических данных. Прикладные программы для работы с данными должны на логическом уровне оставаться нетронутыми при любых изменениях способов хранения данных или методов доступа к ним.
9) Правило независимости логических данных. Прикладные программы для работы с данными должны на логическом уровне оставаться нетронутыми при внесении в базовые таблицы любых изменений, которые позволяют сохранить нетронутыми содержащиеся в этих таблицах данные.
10) Правило независимости условий целостности. Должна существовать возможность определять условия целостности, специфические для конкретной РБД, на подъязыке РБД и хранить их в каталоге, а не в прикладной программе.
11) Правило независимости распространения. Реляционная СУБД не должна зависеть от потребностей конкретного клиента. Т. е. язык БД должен обеспечить возможность работы с распределенными данными, расположенными на других компьютерах.
12) Правило единственности. Если в реляционной системе есть низкоуровневый язык, обрабатывающий одну запись за один раз, то должна отсутствовать возможность использования его для того, чтобы обойти правила и условия целостности, выраженные на реляционном языке высокого уровня, обрабатывающем несколько записей за один раз. Т. е. с БД необходимо работать только с помощью языка БД, поскольку это может нарушить ее целостность.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBaseIY, DB2, Paradox и dBase for Windows, Visual FoxPro и Access, Clarion, Ingres и Oracle.
1)
2) 3.4. Многомерная модель данных
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия:
Агрегируемость данных означает рассмотрение информации на различных уровнях ее общения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь – оператор, управляющий, руководитель.
Историчность данных предполагает обеспечение высокого уровня статичности (неизменяемости) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.
Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.
Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
По сравнению с реляционной моделью многомерная модель обладает более высокой наглядностью и информативностью. Информацию представляют в виде многомерных объектов (трех, четырех и более мерных гиперкубов).
Таблица 4.1 – Реляционная таблица Таблица 4.2 – Многомерная таблица
| Наименование | Месяц | Объем | Модель | Июнь | Июль | Август | |
| Ручки | Июнь | 12 | Ручки | 12 | 24 | 4 | |
| Ручки | Июль | 24 | Папки | 2 | 18 | ||
| Папки | Август | 5 | Бумага | 19 | |||
| Папки | Июнь | 2 | |||||
| Бумага | июль | 18 | |||||
Достоинства: удобство и эффективность аналитической обработки больших объемов данных, связанных со временем.
Недостатки: громоздкость для решения простейших задач обычной оперативной обработки данных.
3.5. Постреляционная модель
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях таблиц. Постреляционная модель – это расширенная реляционная модель, снимающая ограничения неделимости данных. Эта модель допускает многозначные поля – поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. В такой модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц.
Таблица 4.3 - Постреляционная таблица
| № накладной | № покупателя | Название товара | Кол-во |
| 110 | 10000 | сок | 5 |
| Молоко | 3 | ||
| 150 | 1050 | сыр | 10 |
| Чай | 7 | ||
| 250 | 10000 | Кофе | 1 |
Таблица 4.4 - Реляционная таблица Таблица 4.5 - Реляционная таблица
| № накладной | № покупателя | № накладной | Название | Кол-во | |
| 110 | 10000 | 110 | Сок | 5 | |
| 150 | 1050 | 110 | Молоко | 3 | |
| 250 | 10000 | 150 | сыр | 10 | |
| 150 | Чай | 7 | |||
| 250 | Вам также может быть полезна лекция "Содержание". кофе | 1 |
Достоинства: возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей, высокая наглядность представления информации и повышение эффективности ее обработки.
Недостатки: проблема обеспечения целостности и непротиворечивости хранимых данных.
Реляционная и иерархическая модели данных реализуют только линейную структуру таблиц, тогда как сетевая и объектно-ориентированная модели позволяют использовать и нелинейную структуру.
При использовании иерархической и сетевой моделей от пользователя требуется знание физической организации БД, к которой он должен осуществлять доступ, в то время как при работе с реляционной моделью независимость от данных обеспечивается в значительно большей степени. Следовательно, если в реляционных системах для обработки информации в БД принят декларативный подход (т. е. они указывают, какие данные следует извлечь), то в сетевых и иерархических системах – навигационный подход (т. е. они указывают, как их следует извлечь).




















