
Устройство и принцип работы современного МП
8. Устройство и принцип работы современного МП
8.1. Общая организация современного IA-32 микропроцессора
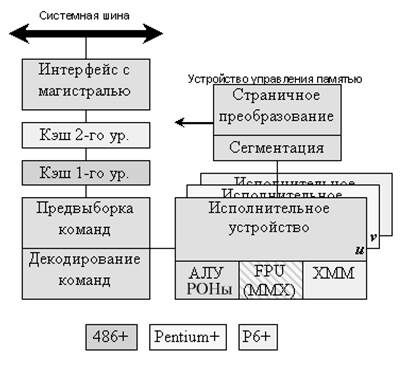
Рис. 8.1. Структурная схема IA-32 процессора
В своей основе МП IA-32 (Рис. 8.1) состоит из шести блоков, работающих параллельно: блок интерфейса с магистралью, блок предварительной выборки команд, блок декодирования команд, исполнительный блок, блок управления сегментами и блок страничной трансляции.
Блок интерфейса с магистралью обеспечивает интерфейс между микропроцессором и его окружением. Он принимает внутренние запросы для выборки команд от блока предварительной выборки команд и для обмена данными с исполнительным блоком и устанавливает приоритет этих запросов. Также этот блок управляет интерфейсом с внешними задатчиками магистрали и сопроцессорами.
Для того чтобы заранее получать команды или данные перед их фактическим использованием, существует функция опережающего просмотра программы, которую в МП выполняет блок предвыборки команд. Когда блок интерфейса с магистралью не занимает цикла магистрали для исполнения команды, блок предвыборки команд использует его для последовательной выборки из памяти байтов команд. Эти команды хранятся в очереди команд в ожидании обработки блоком декодирования команд.
Блок декодирования команд преобразует байты команды из этой очереди в микрокод. Декодированные команды в ожидании обработки исполнительным блоком хранятся в очереди команд, работающей по принципу FIFO (first in first out). Размер этой очереди зависит от поколения МП, в 80386 эта очередь имеет размер 3 команды, а в МП 80486 - уже 5 команд, что позволяет ему при некоторых условиях выполнять по одной команде за цикл. Непосредственные данные и относительные адреса в коде операции также берутся из очереди команд.
Исполнительный блок выполняет команды из очереди команд и взаимодействует со всеми другими блоками, требуемыми для завершения выполнения команды. Для ускорения выполнения команд с обращением к памяти исполнительный блок приступает к их исполнению до завершения выполнения предыдущей команды. Так как команды с обращением к памяти встречаются очень часто, то благодаря такому перекрытию по времени производительность повышается. В микропроцессорах Pentium исполнительный блок реализован в виде двух параллельных конвейеров (u и v), что позволяет ему выполнять до двух команд за такт. Это архитектурное решение названо суперскалярностью. Оно получило дальнейшее развитие в процессорах подсемейства P6 (Pentium Pro, Pentium II, Pentium III), где исполнительный блок представлен уже тремя конвейерами (и Р8 – где конвейеров 4). Особенностью конвейеров является динамическое выполнение (предсказание ветвлений, спекулятивное выполнение, изменение последовательности команд).
Рекомендуемые материалы
Регистры общего назначения (РОН) встроенного типа используют для таких операций, как двоичное сложение или вычисление и модификация адресов. Исполнительный блок содержит восемь 32-разрядных РОНов, применяемых как для вычисления адресов, так и для операций с данными. Этот блок содержит также 64-разрядный регистр, применяемый для ускорения операций сдвига, циклического сдвига, умножения и деления.
Интеграция в процессоры начиная с i486DX блока вычислений с плавающей точкой (Floating Point Unit) резко повысила производительность вещественной арифметики. В процессорах Pentium MMX был добавлен набор команд, позволяющий использовать регистры блока FPU для параллельной обработки пакета целочисленных данных: SIMD - "одна инструкция - несколько операндов". В процессорах Pentium III эта технология была расширена, добавлением блока XMM, позволяющего параллельно обрабатывать пакет вещественных данных: SSE - потоковое расширение SIMD.
Блоки управления сегментами и страничной трансляции образуют устройство управления памятью.
Блок управления сегментами преобразует логические адреса в линейные по запросу исполнительного блока. Для ускорения этого преобразования текущие дескрипторы сегментов помещаются во встроенную кэш-память. Во время трансляции адресов блок управления сегментами проверяет, нет ли нарушения сегментации. Эти проверки выполняются отдельно от проверок нарушений статической сегментации, осуществляемых механизмом проверки защиты. Блок сегментации обеспечивает четыре уровня (от 0 до 3) защиты с целью изоляции и защиты друг от друга прикладных программ и операционной системы. Этот компонент также позволяет легко создавать перемещаемые программы и данные и обеспечивает их совместное использование. Полученный линейный адрес направляется в блок страничной трансляции.
Если механизм страничного преобразования включен, то для получения физических адресов по линейным используется блок страничной трансляции. Если же этот механизм выключен, то это означает, что физический адрес совпадает с линейным, и трансляция не нужна. Для ускорения трансляции адресов в кэш-память дескрипторов страниц помещаются каталог недавно использованных страниц, а также информация о входах в таблицу страниц в буфере трансляции адресов. Затем блок страничной трансляции пересылает физические адреса в блок интерфейса с магистралью для выполнения цикла обращения к памяти или устройствам ввода-вывода. Микропроцессор 80386 использует 32-разрядные регистры и шины данных для поддержки адресов и типов данных такой же разрядности.
Блок страничной трансляции позволяет прозрачно управлять пространством физических адресов независимо от управления сегментами. Каждый сегмент отображается в пространство линейных адресов, которое в свою очередь отображается в одну или несколько страниц объемом 4 Кбайта.
8.2. Кэш. Общее описание и принцип действия
Во всех современных процессорах есть кэш (по-английски — cache). Кэш — это некая особенная разновидность памяти (основная особенность, кардинально отличающая кэш от ОЗУ — скорость работы), которая является «буфером» между контроллером памяти и процессором, служащим для увеличения скорости работы с ОЗУ.
Процесс обработки информации таков, что в один момент программа работает не со всей памятью целиком, а, как правило, с относительно маленьким её фрагментом. Можно загрузить этот фрагмент в «быструю» память, обработать его там, а потом уже записать обратно в «медленную» (или просто удалить из кэша, если данные не изменялись). Скорость обмена данными процессора Pentium 4 со своим кэшам более чем в 10 раз (!) превосходит скорость его работы с памятью.
В общем случае, именно так и работает процессорный кэш: любая считываемая из памяти информация попадает не только в процессор, но и в кэш. И если эта же информация (тот же адрес в памяти) нужна снова, сначала процессор проверяет: а нет ли её в кэше? Если есть — информация берётся оттуда, и обращения к памяти не происходит вовсе. Аналогично с записью: информация, если её объём влезает в кэш — пишется именно туда, и только потом, когда процессор закончил операцию записи, и занялся выполнением других команд, данные, записанные в кэш, параллельно с работой процессорного ядра «потихоньку выгружаются» в ОЗУ.
Замена данных на более актуальные, производится периодически и удалению подлежат данные, к обращение к которым производилось наиболее давно. Многоуровневое кэширование
Специфика конструирования современных процессорных ядер привела к тому, что систему кэширования в подавляющем большинстве CPU приходится делать многоуровневой. Кэш первого уровня (самый «близкий» к ядру) традиционно разделяется на две (как правило, равные) половины: кэш инструкций (L1I) и кэш данных (L1D). Это разделение предусматривается так называемой «гарвардской архитектурой» процессора, которая по состоянию на сегодня является самой популярной теоретической разработкой для построения современных CPU.
В L1I, соответственно, аккумулируются только команды (с ним работает декодер, см. ниже), а в L1D — только данные (они впоследствии, как правило, попадают во внутренние регистры процессора). «Над L1» стоит кэш второго уровня — L2. Он, как правило, больше по объёму, и является уже «смешанным» — там располагаются и команды, и данные. L3 (кэш третьего уровня), как правило, полностью повторяет структуру L2, и в современных x86 CPU встречается редко. Тем не менее, алгоритм работы с многоуровневым кэшем в общих чертах не отличается от алгоритма работы с одноуровневым, просто добавляются лишние итерации: сначала информация ищется в L1, если её там нет — в L2, потом — в L3, и уже потом, если ни на одном уровне кэша она не найдена — идёт обращение к основной памяти (ОЗУ).
8.3. Суперскалярность и внеочередное исполнение команд
Основная черта всех современных процессоров состоит в том, что они способны запускать на исполнение не только ту команду, которую (согласно коду программы) следует исполнить в данный момент времени, но и другие, следующие после неё. Приведём простой (канонический) пример. Пусть нам следует исполнить следующую последовательность команд:
1) A = B + C
2) K = A + Z
3) Z = X + Y
Легко заметить, что команды (1) и (3) совершенно независимы друг от друга — они не пересекаются ни по исходным данным (переменные B и C в первом случае, X и Y во втором), ни по месту размещения результата (переменная A в первом случае и Z во втором). Стало быть, если на данный момент у нас есть свободные исполняющие блоки в количестве более одного, данные команды можно распределить по ним, и выполнить одновременно, а не последовательно. Таким образом, если принять время исполнения каждой команды равным N тактов процессора, то в классическом случае исполнение всей последовательности заняло бы N*3 тактов, а в случае с параллельным исполнением — всего N*2 тактов (так как команду (2) нельзя выполнить, не дождавшись результата исполнения двух предыдущих). Данный механизм называется «внеочередным исполнением команд» (Out-of-Order Execution, или сокращённо «OoO»): в тех случаях, когда очерёдность выполнения никак не может сказаться на результате, команды отправляются на исполнение не в той последовательности, в которой они располагаются в коде программы, а в той, которая позволяет достичь максимального быстродействия.
Процессоры, оснащённые механизмом параллельного исполнения нескольких подряд идущих команд, принято называть «суперскалярными».
8.4. Предварительное (опережающее) декодирование и кэширование. Предсказание ветвлений
В любой программе чаще всего присутствуют команды условного перехода: «Если некое условие истинно — перейти к исполнению одного участка кода, если нет — другого». С точки зрения скорости выполнения кода программы современным процессором, любая команда условного перехода — представляет проблему. Так как, пока не станет известно, какой участок кода после условного перехода окажется «актуальным» — его невозможно начать декодировать и исполнять (см. внеочередное исполнение). Для того чтобы преодолеть эту проблему, создан специальный блок: блок предсказания ветвлений.
Данный блок пытается предсказать, на какой участок кода укажет команда условного перехода, ещё до того, как она будет исполнена. В соответствии с его указаниями, процессором производятся загрузка в кэш предсказанного участка кода, начинается декодирование и выполнение его команд. Причём среди выполняемых команд также могут содержаться инструкции условного перехода, и их результаты тоже предсказываются, что порождает целую цепочку из пока не проверенных предсказаний. Если блок предсказания ветвлений ошибся, вся проделанная в соответствии с его предсказаниями работа просто аннулируется.
Алгоритмы работы блока предсказаний зачастую элементарны. Можно привести такой пример:
Чаще всего команда условного перехода встречается в циклах: некий счётчик принимает значение X, и после каждого прохождения цикла значение счётчика уменьшается на единицу. Соответственно, до тех пор, пока значение счётчика больше нуля — осуществляется переход на начало цикла, а после того, как он становится равным нулю — исполнение продолжается дальше. Блок предсказания ветвлений просто анализирует результат выполнения команды условного перехода, и считает, что если N раз подряд результатом стал переход на определённый адрес — то и в N+1 случае будет осуществлён переход туда же.
Несмотря на это, вероятность правильного предсказания в современных МП достигает 95 %.
8.5. Предвыборка данных
Блок предвыборки данных (Prefetch) очень похож по принципу своего действия на блок предсказания ветвлений — но в данном случае речь идёт не о коде, а о данных. Общий принцип действия такой же: если встроенная схема анализа доступа к данным в ОЗУ решает, что к некоему участку памяти, ещё не загруженному в кэш, скоро будет осуществлён доступ — она даёт команду на загрузку данного участка памяти в кэш ещё до того, как он понадобится исполняемой программе.
Однако, также как и в предсказании ветвлений, в случае ошибки блока предвыборки данных, неизбежны негативные последствия: загружая де-факто «ненужные» данные в кэш, Prefetch вытесняет из него другие (быть может, как раз нужные). Кроме того, за счёт «предвосхищения» операции считывания, создаётся дополнительная нагрузка на контроллер памяти.
Алгоритмы предсказания данных так же крайне просты:
Как правило, данный блок стремится отследить, не считывается ли информация из памяти с определённым «шагом» (по адресам), и на основании этого анализа пытается предсказать, с какого адреса будут считываться данные в процессе дальнейшей работы программы. Впрочем, как и в случае с блоком предсказания ветвлений, простота алгоритма вовсе не означает низкую эффективность: в среднем, блок предвыборки данных оказывается прав в 80-90%.
Важной особенностью современных процессоров является также предварительное преобразование машинных инструкций в промежуточные операции (микрооперации), более удобные для обработки и исполнения.
Более подробно архитектура и работа вышеперечисленных устройств, рассмотрена в специализированной литературе, а также на http://www.ixbt.com/cpu/cpu-microarchitecture-part-1.shtml, и здесь не приводится.
8.6. Режимы работы микропроцессора
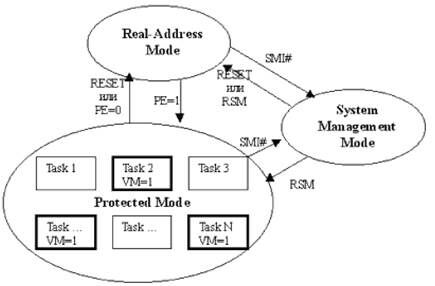
Рис. 8.2. Режимы работы микропроцессора
Впервые о различных режимах работы процессоров Intel x86 стали говорить с появлением процессора 80286. Это был первый представитель данного семейства процессоров, в котором были реализованы многозадачность и защищенная архитектура.
Реальный режим (Real Mode)
В реальном режиме микропроцессор работает как очень быстрый 8086 с возможностью использования 32-битных расширений. Механизм адресации, размеры памяти и обработка прерываний (с их последовательными ограничениями) МП 8086 полностью совпадают
В новых поколениях процессоров Intel появился еще один режим работы - режим системного управления. Впервые он был реализован в процессорах 80386SL и i486SL. Начиная с расширенных моделей 486х процессоров, этот режим стал обязательным элементом архитектуры IA-32. С его помощью прозрачно даже для операционной системы на уровне BIOS реализуются функции энергосбережения или функции безопасности и контроля доступа.
Режим системного управления (System Management Mode)
Режим системного управления предназначен для выполнения некоторых действий с возможностью их полной изоляции от прикладного программного обеспечения и даже операционной системы. Переход в этот режим возможен только аппаратно.
Защищенный режим (Protected Mode)
Основным режимом работы микропроцессора является защищенный режим. Ключевыми особенностями защищенного режима являются: виртуальное адресное пространство, защита и многозадачность.
В защищенном режиме программа оперирует с адресами, которые могут относиться к физически отсутствующим ячейкам памяти, такое адресное пространство называется виртуальным. Размер виртуального адресного пространства программы может превышать емкость физической памяти и достигать 64Тбайт. Для адресации виртуального адресного пространства используется сегментированная модель, в которой адрес состоит из двух элементов: селектора сегмента и смещения внутри сегмента. С каждым сегментом связана особая структура, хранящая информацию о нем, - дескриптор. Кроме "виртуализации" памяти на уровне сегментов существует возможность "виртуализации" памяти при помощи страниц - страничная трансляция. Страничная трансляция предоставляет удобные средства для реализации в операционной системе функций подкачки, а кроме того в процессорах P6+ обеспечивает 36-битную физическую адресацию памяти (64Гбайт).
Применение МПС для автоматизации технологических процессов и машин
АСУТП - это автоматизированная (человеко-машинная) система для выработки и реализации управляющих воздействий на технологический объект управления в соответствии с принятым критерием управления. Под технологическим объектом управления понимается совокупность технологического оборудования и реализованного на нём в соответствии с инструкциями и регламентами технологического процесса производства.
Процесс автоматизации производства зародился вместе с самим производством и в процессе своего развития прошел целый ряд этапов: от управления при помощи простейших технических устройств, до современных АСУ, построенных на базе микропроцессорных систем.
Комплексное использование МПС при автоматизации производства позволяет создавать гибкие автоматизированные производства (ГАП).
Такие МПС предназначены для автоматического управления работой машин или ходом технологического процесса, обеспечения автоматической защиты оборудования и персонала, автоматического регулирования параметрами сырья, продукта или среды (t,p), контроля и управления основным и вспомогательным оборудованием, регистрации накопления и отображения информации о состоянии процесса или оборудования.
Характерные особенности микропроцессорных информационно-управляющих систем, предназначенных для автоматизации технологических процессов или машин:
- наличие ограниченного набора четко сформулированных задач;
- требования оптимизации структуры системы для конкретного применения;
- работа в реальном масштабе времени, т.е. обеспечение минимального времени реакции на изменение внешних условий;
- наличие развитой системы внешних устройств, их большое разнообразие;
- существенное различие функциональных задач;
- высокие требования по надежности с учетом большой продолжительности непрерывной работы;
- сложные условия эксплуатации;
- наличие режимов работы со сниженным энергопотреблением;
- обеспечение автоматического режима работы или режима с участием оператора как элемента системы;
В настоящее время широкое применение при создании АСУТП получили ПЛК фирмы SIEMENS (торговая марка SIMATIC). Сегодня под именем SIMATIC представлены системы комплексной автоматизации (Totally Integrated Automation - TIA), позволяющие создавать управляющие комплексы любой степени сложности на базе стандартных компонентов.
В основу построения таких систем положены следующие принципы:
- Единые способы хранения и обработки данных. Все данные вводятся один раз и хранятся в единой базе данных проекта. База данных проекта доступна на всех уровнях управления любым инструментальным средствам SIMATIC.
- Единые способы конфигурирования и программирования, диагностики и отладки. Все компоненты и системы конфигурируются, программируются, запускаются, тестируются и обслуживаются с использованием простых стандартных блоков, встроенных в систему разработки. Все операции выполняются с использованием единого интерфейса и единых инструментальных средств.
- Единые способы организации промышленной связи. Вопрос "кто будет связываться и с кем" решается простым использованием таблиц соединений. Соединения могут быть легко модифицированы в любое время в любом месте. Различные сетевые решения конфигурируются просто и единообразно.
Линейка аппаратуры фирмы SIEMENS чрезвычайно широка и постоянно пополняется новыми представителями, ориентированными на решение самого широкого круга задач.
Для конфигурирования и программирования контроллеров SIEMENS используется программное обеспечение Simatic Step 7. Общая структура системы, работающей под управлением STEP 7, показана на рисунке.
|
|
| Рис. 1. Структура системы автоматизации |
ПО Simatic Step 7 позволяет осуществить комплексный подход к проектированию систем автоматизации на основе контроллеров. Объединяет в себе средства создания конфигурации оборудования, программирования, отладки программы, on-line диагностики работы, документирование и архивирование данных проекта. Подобная интеграция и использование единого программного обеспечения значительно повышает удобство и эффективность работы.
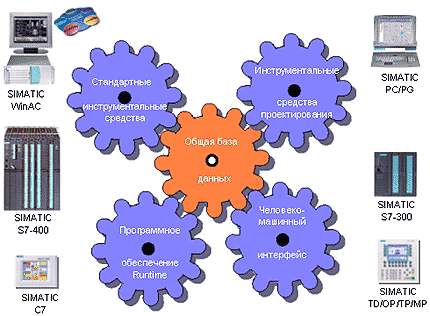
Унификация промышленного программного обеспечения SIMATIC базируется на трех основных принципах:
- Общее управление данными: все данные проекта (например, символьные переменные, параметры конфигурирования и настройки) хранятся в единой базе данных и доступны всем инструментальным средствам. Это позволяет экономить время и исключать возникновение ошибок из-за многократного ввода одних и тех же данных.
- Согласованная система инструментальных средств: для каждой фазы выполнения проекта могут использоваться свои, наиболее удобные для выполнения этих задач, инструментальные средства.
- Открытость: системная платформа промышленного программного обеспечения SIMATIC открыта для интеграции в офисную среду управления производством.
Высокая производительность работы с промышленным ПО SIMATIC обеспечивается за счет:
- Проблемно-ориентированных инструментальных средств, обеспечивающих простоту решения широкого круга задач автоматизации. Они позволяют проектировщику сосредоточиться на решении поставленной задачи и решать ее в наиболее удобной форме,
включают в свой состав: Языки программирования высокого уровня; Графические языки для специалистов в области технологии; Сопутствующее программное обеспечение для диагностирования, имитации, дистанционного обслуживания, разработки заводской документации и т.д. - Многократное использование секций программы. Написанные ранее секции программ могут сохраняться в виде библиотек и легко копироваться в новые проекты.
- Параллельная разработка отдельных частей проекта несколькими проектировщиками.
- Встроенные диагностические функции, существенно снижающие время отладки любой программы.
Это программное обеспечение ломает барьер между специалистами в области технологии и программистами. Каждый специалист может выбрать для себя наиболее удобное средство решения своих задач.
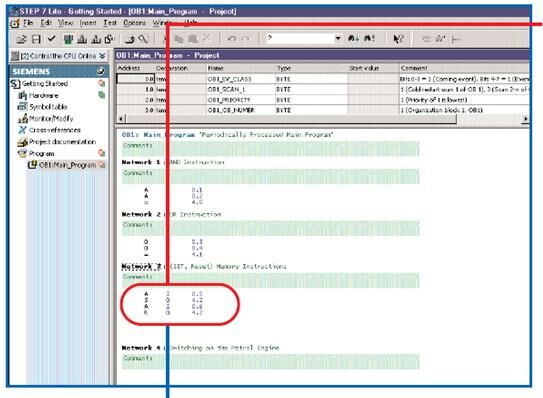
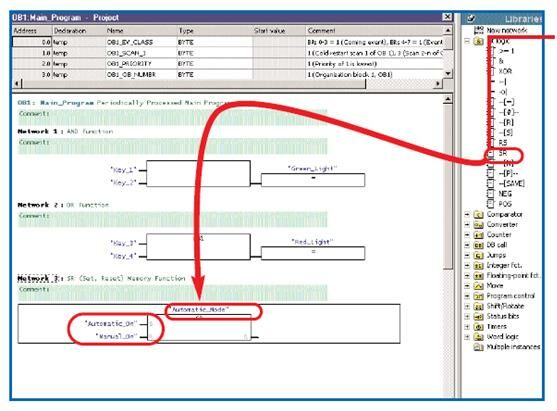
LAD
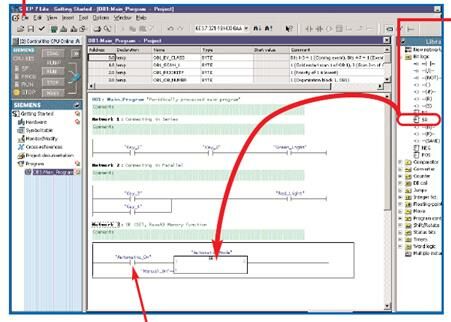
STL
Лекция "14. Создание форм средствами MS Access" также может быть Вам полезна.
FBD
Промышленное ПО SIEMENS служит основой для построения SCADA систем. SCADA (Supervisory Control and Data Acquisition - централизованный контроль и сбор данных).
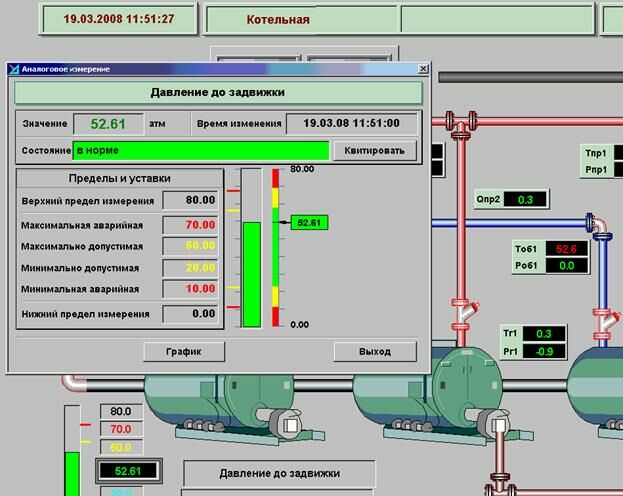
Например, SIMATIC WinCC (Windows Control Center) - это компьютерная система человеко-машинного интерфейса предоставляющая широкие функциональные возможности для построения систем управления различного назначения:
- Простое построение конфигураций клиент-сервер.
- Поддержка резервированных структур систем автоматизации.
- Неограниченное расширение функциональных возможностей благодаря использованию ActiveX элементов.
- Открытый OPC-интерфейс (OLE for Process Control) интерфейс для реализации функций обмена данными.
- Простое и быстрое конфигурирование системы в сочетании с пакетом STEP 7.
WinCC легко интегрируется во внутреннюю информационную сеть компании. Это не только снижает затраты на ее внедрение, но и повышает гибкость информационной системы.

















