
Интерфейс файловой системы
6.2. Интерфейс файловой системы
Интерфейс файловой системы
В соответствии со своим предназначением файловая система должна организовать эффективную работу с данными, хранящимися во внешней памяти и предоставить пользователю возможности для запоминания и выборки данных в ней.
Для организации хранения информации на диске пользователь вначале обычно выполняет его форматирование, выделяя на нем место для структур данных, которые описывают состояние файловой системы в целом. Затем создает нужную ему структуру каталогов (директорий), которые по существу являются списками вложенных каталогов и собственно файлов. И, наконец, заполняет дисковое пространство файлами, приписывая их тому или иному каталогу. Таким образом, ОС должна предоставить в распоряжение пользователя совокупность сервисов, традиционно реализованных через системные вызовы, которые обеспечивают:
· создание файловой системы на диске;
· необходимые операции для работы с каталогами;
· необходимые операции для работы с файлами.
Кроме того, файловые службы могут решать проблемы проверки и сохранения целостности файловой системы, проблемы повышения производительности и ряд других.
Прежде чем приступить к описанию работы отдельных файловых операций, необходимо рассмотреть ключевые алгоритмы и структуры данных, которые обеспечивают функционирование файловой системы.
Рекомендуемые материалы

6.2.2. Функциональная схема организации файловой системы
Функциональная схема организации файловой системы
Система хранения данных на дисках может быть представлена в виде функциональной схемы (рис. 37). Рассмотрим ее подробнее.
Нижний уровень – оборудование. Это в первую очередь, магнитные диски с подвижными головками, особенности физической организации которых рассмотрены в п. 5.1.
Непосредственно с устройствами (дисками) взаимодействует часть ОС, называемая системой ввода-вывода. Система ввода-вывода (она состоит из драйверов устройств и обработчиков прерываний для передачи информации между памятью и дисковой системой) предоставляет в распоряжение более высокоуровневого компонента ОС – файловой системы используемое дисковое пространство в виде непрерывной последовательности блоков фиксированного размера. Система ввода-вывода имеет дело с физическими блоками диска, которые характеризуются адресом – номерами диска, цилиндра и сектора. Файловая система имеет дело с логическими блоками, каждый из которых имеет номер (от 0 или 1 до N). Размер этих логических блоков файла совпадает или кратен размеру физического блока диска и может быть задан равным размеру страницы виртуальной памяти, поддерживаемой аппаратурой компьютера совместно с ОС.
В структуре системы управления файлами можно выделить базисную подсистему, которая отвечает за выделение дискового пространства конкретным файлам, и более высокоуровневую логическую подсистему, которая использует структуру дерева директорий для предоставления модулю базисной подсистемы необходимой ей информации исходя из символического имени файла. Она также ответственна за авторизацию доступа к файлам.
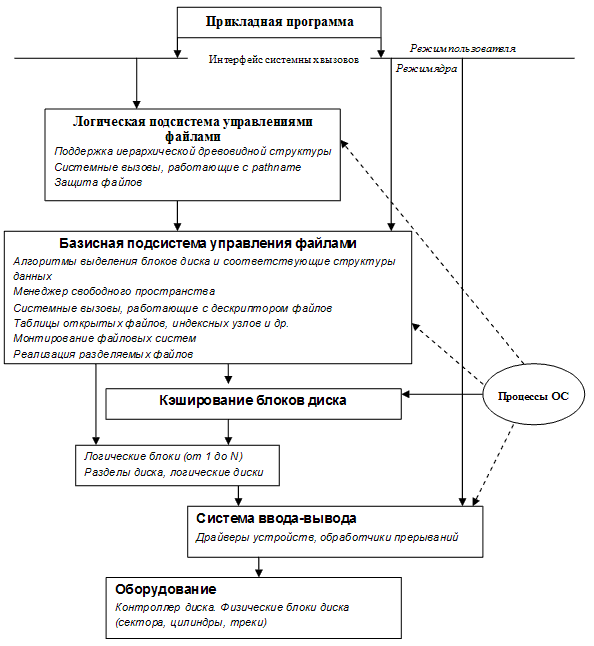
Рисунок 37 – Функциональная схема организации файловой системы
Информация на диске организована в виде иерархической древовидной структуры, состоящей из набора файлов, каждый из которых является хранилищем данных пользователя, и каталогов или директорий, которые необходимы для хранения информации о файлах системы.
Взаимодействие прикладной программы с файлом происходит следующим образом. От прикладной программы к логической подсистеме поступает запрос на открытие или создание файла. Логическая подсистема, используя структуру директорий, проверяет права доступа и вызывает базовую подсистему для получения доступа к блокам файла. После этого файл считается открытым, содержится в таблице открытых файлов, прикладная программа получает в свое распоряжение дескриптор (в системах Microsoft – handle) этого файла. Дескриптор файла является ссылкой на файл в таблице открытых файлов и используется в запросах прикладной программы на чтение-запись из этого файла. Запись в таблице открытых файлов указывает через систему кэширования блоков диска на блоки данного файла. Если к моменту открытия файл уже используется другим процессом, то есть содержится в таблице открытых файлов, то после проверки прав доступа к файлу может быть организован совместный доступ. При этом новому процессу также возвращается дескриптор файла.
Прежде чем рассмотреть структуру данных файловой системы на диске следует рассмотреть алгоритмы выделения дискового пространства и способы учета свободной и занятой дисковой памяти.
6.2.3. Типовая структура файловой системы на диске
Типовая структура файловой системы на диске
Обзор способов работы с дисковым пространством дает общее представление о совокупности служебных данных, необходимых для описания файловой системы. Структуры данных типовой файловой системы, например Unix, на одном из разделов диска, может состоять из 4-х основных частей (рис. 38)
| Суперблок | Структуры данных, описывающие свободное дисковое пространство и свободные индексные узлы | Массив индексных узлов | Блоки диска данных файлов |
Рисунок 38 – Пример структуры файловой системы на диске
В начале раздела находится суперблок, содержащий общее описание файловой системы, например:
· тип файловой системы;
· размер файловой системы в блоках;
· размер массива индексных узлов;
· размер логического блока;
· и т.д.
В файловых системах современных ОС для повышения устойчивости поддерживается несколько копий суперблока. В некоторых версиях ОС Unix суперблок включал также и структуры данных, управляющие распределением дискового пространства, в результате чего суперблок непрерывно подвергался модификации, что снижало надежность файловой системы в целом. Выделение структур данных, описывающих дисковое пространство, в отдельную часть является более правильным решением.
Описанные структуры данных создаются на диске в результате его форматирования специализированными утилитами ОС. Их наличие позволяет обращаться к данным на диске как к файловой системе, а не как к обычной последовательности блоков.
Массив индексных узлов (англ. ilist) содержит список индексов, соответствующих файлам данной файловой системы. Размер массива индексных узлов определяется администратором при установке системы. Максимальное число файлов, которые могут быть созданы в файловой системе, определяется числом доступных индексных узлов.
В блоках данных хранятся реальные данные файлов. Размер логического блока данных может задаваться при форматировании файловой системы. Заполнение диска содержательной информацией предполагает использование блоков хранения данных для файлов директорий и обычных файлов и имеет следствием модификацию массива индексных узлов и данных, описывающих пространство диска. Отдельно взятый блок данных может принадлежать одному и только одному файлу в файловой системе.
6.2.4. Способы выделения дискового пространства
Способы выделения дискового пространства
Ключевой вопрос реализации файловой системы – способ связывания файлов с блоками диска. В ОС используется несколько способов выделения файлу дискового пространства, для каждого из которых сведения о локализации блоков данных файла можно извлечь из записи в директории, соответствующей символьному имени файла.
Выделение непрерывной последовательностью блоков. Простейший способ – хранить каждый файл, как непрерывную последовательность блоков диска. При непрерывном расположении файл характеризуется адресом и длиной (в блоках). Файл, стартующий с блока b, занимает затем блоки b + 1, b + 2, ... b + n – 1. Этот способ имеет два преимущества:
· легкая реализация, так как выяснение местонахождения файла сводится к вопросу, где находится первый блок;
· обеспечивает хорошую производительность, потому что целый файл может быть считан за одну дисковую операцию.
Например, непрерывное выделение использовано в ОС IBM/CMS, RSX-11 (для исполняемых файлов).
Основная проблема, в связи с которой этот способ мало распространен – трудности в поиске места для нового файла. В процессе эксплуатации диск представляет собой некоторую совокупность свободных и занятых фрагментов. Проблема непрерывного расположения может рассматриваться как частный случай более общей проблемы выделения n блоков из списка свободных фрагментов. Наиболее распространенные стратегии решения этой проблемы – выбор первого подходящего по размеру блока (англ. first fit), наиболее подходящего, т.е. того, при размещении в котором наиболее тесно (англ. best fit), и наименее подходящего, т.е. выбирается наибольший блок (англ. worst fit).
Способ характеризуется наличием существенной внешней фрагментации (в большей или меньшей степени – в зависимости от размера диска и среднего размера файла). Кроме того, непрерывное распределение внешней памяти не применимо до тех пор, пока не известен максимальный размер файла. Иногда размер выходного файла оценить легко (при копировании), но чаще – трудно. Если места не достаточно, то пользовательская программа может быть приостановлена, предполагая выделение дополнительного места для файла при последующем перезапуске. Некоторые ОС используют модифицированный вариант непрерывного выделения: «основные блоки файла» + «резервные блоки». Однако с выделением блоков из резерва возникают те же проблемы, так как возникает задача выделения непрерывной последовательности блоков диска теперь уже из совокупности резервных блоков.
Выделение связным списком. Метод распределения блоков в виде связного списка решает основную проблему непрерывного выделения, то есть устраняет внешнюю фрагментацию (рис. 39). Каждый файл – связный список блоков диска. Запись в директории содержит указатель на первый и последний блоки файла. Каждый блок содержит указатель на следующий блок.
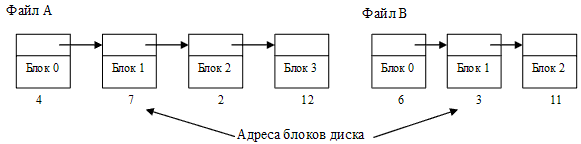
Рисунок 39 – Хранение файлов в связных списках дисковых блоков
Внешняя фрагментация для данного метода отсутствует. Любой свободный блок может быть использован для удовлетворения запроса. Отметим, что нет необходимости декларировать размер файла в момент создания и, поэтому, файл может неограниченно расти. Связное выделение имеет несколько существенных недостатков:
· при прямом доступе к файлу для поиска i-го блока нужно осуществить несколько обращений к диску, последовательно считывая блоки от 1 до i – 1, то есть выборка логически смежных записей, которые занимают физически несмежные секторы, может требовать много времени;
· прямым следствием этого является низкая надежность – наличие дефектного блока в списке приводит к потере информации в остаточной части файла и, потенциально, к потере дискового пространства отведенного под этот файл;
· для указателя на следующий блок внутри блока нужно выделить место размером, традиционно определяемым степенью двойки (многие программы читают и записывают блоками по степеням двойки), который перестает быть таковым, так как указатель отбирает несколько байтов.
В связи с вышеизложенным, метод связного списка обычно не используется в чистом виде.
Распределение связным списком с использованием индекса. Недостатки предыдущего способа могут быть устранены путем изъятия указателя из каждого дискового блока и помещения его в индексную таблицу в памяти, которая называется таблицей размещения файлов (англ. file allocation table – FAT). Этой схемы придерживаются многие ОС (MS-DOS, OS/2, MS Windows и др.).
По-прежнему существенно, что запись в директории содержит только ссылку на первый блок. Далее при помощи таблицы FAT можно локализовать блоки файла независимо от его размера (значение равно адресу следующего блока этого файла). В тех строках таблицы, которые соответствуют последним блокам файлов, обычно записывается некоторое граничное значение, например EOF (рис. 40).
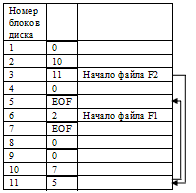
Рисунок 40 – Способ выделения памяти с использованием связного списка в ОП
Главное достоинство данного подхода состоит в том, что по таблице отображения можно судить о физическом соседстве блоков, располагающихся на диске, и при выделении нового блока можно легко найти свободный блок диска, находящийся поблизости от других блоков данного файла. Минусом данной схемы может быть необходимость хранения в памяти этой довольно большой таблицы. Более подробно особенности использования таблицы размещения файлов рассмотрены в п. 5.5.1 при описании файловой системы FAT.
Индексные узлы. Четвертый и последний способ «выяснения принадлежности» блока к файлу – связать с каждым файлом маленькую таблицу, называемую индексным узлом (i-node), которая перечисляет атрибуты и дисковые адреса блоков файла (рис. 41). Каждый файл имеет свой собственный индексный блок, который содержит адреса блоков данных. Запись в директории, относящаяся к файлу, содержит адрес индексного блока. По мере заполнения файла указатели на блоки диска в индексном узле принимают осмысленные значения. Индексирование поддерживает прямой доступ к файлу, без ущерба от внешней фрагментации.
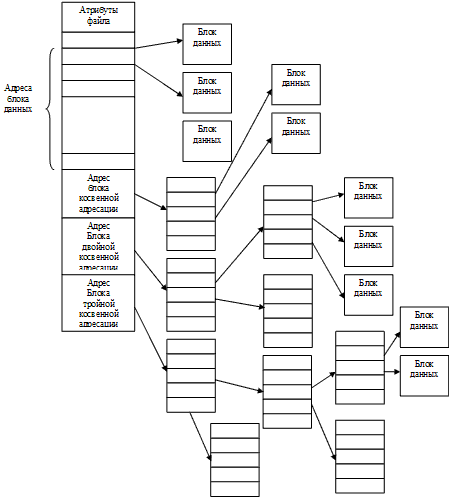
Рисунок 41 – Структура индексного узла
Первые несколько адресов блоков файла хранятся непосредственно в индексном узле, поэтому для маленьких файлов индексный узел хранит всю необходимую информацию, которая копируется с диска в память, в момент открытия файла. Для больших файлов один из адресов индексного узла указывает на блок косвенной адресации. Этот блок содержит адреса дополнительных блоков диска. Если этого недостаточно, используется блок двойной косвенной адресации, который содержит адреса блоков косвенной адресации. Если и этого недостаточно используют блок тройной косвенной адресации.
Эту схему распределения внешней памяти использует ОС Unix, а также файловые системы HPFS, NTFS и др. Такой подход позволяет при фиксированном, относительно небольшом размере индексного узла, поддерживать работу с файлами, размер которых может меняться от нескольких байт до нескольких гигабайт. Существенно то, что для маленьких файлов используется только прямая адресация, обеспечивающая высокую производительность.
6.2.5. Управление дисковым пространством
Управление дисковым пространством
Одной из основных функций файловых систем является управление свободным и занятым пространством внешней памяти, включая учет используемого места на диске. Выделяют несколько способов такого учета. Рассмотрим наиболее распространенные из них.
Учет при помощи организации битового вектора. Часто список свободных блоков диска реализован в виде битового вектора (bit map или bit vector). Каждый блок представлен одним битом, принимающим значение 0 или 1, в зависимости от того занят он или свободен. Например, 00111100111100011000001... .
Главное преимущество этого подхода – относительная простота и эффективность при нахождении первого свободного блока или n последовательных блоков на диске. Многие компьютеры (например, Intel и Motorola) имеют специальные инструкции манипулирования битами, при помощи которых можно легко локализовать первый единичный бит в слове.
Описываемый способ учета свободных блоков используется в Apple Macintosh. К сожалению, он эффективен только если битовый вектор помещается в памяти целиком, что возможно только для относительно небольших дисков.
Учет при помощи организации связного списка. Другой подход – связать в список все свободные блоки, поддерживая указатель на первый свободный блок в специальном месте диска, попутно кэшируя в памяти эту информацию. Обычно необходим только первый свободный блок, но если это не так, то схема не будет эффективна, так как для трассирования списка нужно сделать достаточно много обращений к диску. Иногда прибегают к модификации подхода связного списка, организуя хранение адресов n свободных блоков в первом свободном блоке: первые n – 1 этих блоков используются для хранения данных, а последний – содержит адреса других n блоков, и т.д.
Вам также может быть полезна лекция "5.2. Уравнение Бернулли".
6.2.6. Размер логического блока
Размер логического блока
Размер логического блока является одним из ключевых параметров, влияющих на эффективность работы файловой системы в целом. В некоторых системах (например, Unix) он может быть задан при форматировании. Следует помнить, что небольшой размер блока приводит к тому, что каждый файл будет содержать много блоков. Чтение блока осуществляется с задержками на поиск и вращение, поэтому файл, содержащийся в многих блоках, будет считываться относительно медленно. Большие блоки обеспечивают более высокую скорость обмена с диском, но вследствие внутренней фрагментации (каждый файл занимает целое число блоков и в среднем половина последнего блока пропадает) снижается процент полезного дискового пространства.
Проведенные исследования показали, что большинство файлов имеет небольшой размер (в Unix приблизительно 85% файлов имеют размер менее 8 Кб и 48% – менее 1 Кб). На рис. 42 изображены две зависимости от размера блока: одна показывает убывающую степень утилизации (использования) диска, а вторая – возрастающую скорость обмена данных с диском. Зависимости имеют общую точку при размере блока 3 Кб. Обычный компромисс – выбор блока размером 512 б, 1 Кб, 2 Кб.
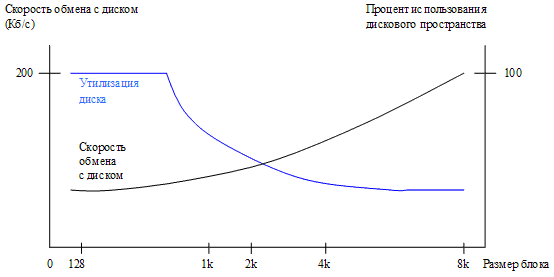
Рисунок 42 – Результаты исследований при определении оптимального размера блока



















