
Классификационный анализ
Глава 5. Классификационный анализ
Цель классификационного анализа — классификация респондентов и/или переменных по определенным целевым группам. Наиболее распространенными примерами использования классификационного анализа в маркетинговых исследованиях являются:
■ сегментирование респондентов по заранее известным (логистическая регрессия и дискриминантный анализ) или не известным (факторный и кластерный анализ) целевым группам;
■ классификация переменных по макрокатегориям, то есть сокращение их числа до нескольких значимых групп (факторный и кластерный анализ).
Далее в разделе мы рассмотрим эти статистические методики в указанном порядке, а также приведем примеры задач из практики маркетинговых исследований, решаемых с помощью классификационного анализа.
5.1. Логистическая регрессия и дискриминантный анализ
Рекомендуемые материалы
Логистическая регрессия и дискриминантный анализ применяются в том случае, когда необходимо классифицировать (сегментировать) респондентов по целевым группам, которые, в свою очередь, представлены уровнями (вариантами ответа) одной одновариантной переменной.
Примером задачи, решаемой при помощи этих статистических методов, может служить задача классифицировать респондентов по двум группам — покупающие горчицу и не покупающие горчицу — на основании их социально-демографических характеристик (пол, возраст, доход, количество членов семьи и т. п.). Как вы видите, в процедурах логистической регрессии и дискриминантного анализа присутствуют переменные — критерии сегментирования и одна переменная, кодирующая целевые группы, на которые следует разделить респондентов на основании критериев сегментирования.
Необходимо отметить, что спектр возможностей применения логистической регрессии уже, чем для дискриминантного анализа, поэтому использование дискриминантного анализа в качестве универсального метода предпочтительнее. Боле того, рекомендуется всегда начинать классификационное исследование именно с дискриминантного анализа, а не с логистической регрессии, — и применять последнюю в случае неуверенности в результатах дискриминантного анализа. Это связано, в частности, с тем, что при применении методов логистической регрессии еле дует четко представлять, какой тип имеют зависимая и независимые переменные и, исходя из этого, выбирать одну из трех возможных процедур логистической регрессии: бинарную, мультиномиальную или порядковую. При дискриминантном анализе мы всегда имеем дело только с одной статистической процедурой, в которой принимают участие одна категориальная зависимая переменная и несколько независимых переменных с любым типом шкалы. Таким образом, дискриминантный анализ является более универсальной методикой (что особенно важно для исследователей, имеющих незначительный опыт в статистическом анализе данных).
В разделах 5.1.1 и 5.1.2 мы на конкретных примерах покажем, как молено использовать процедуры логистической регрессии и дискриминантного анализа в маркетинговых исследованиях. При этом мы увидим, что, несмотря на преимущества универсального дискриминантного анализа, логистическая регрессия в некоторых случаях дает наивысшую четкость классификации.
5.1.1. Бинарная и мультиномиальная логистические регрессии
В настоящем разделе мы рассмотрим два основных типа логистической регрессии — бинарную и мультиномиальную, а также дадим общий обзор порядковой логистической регрессии. Цель статистического анализа при применении методов логистической регрессии — определить вероятность того, что тот или иной респондент (на основании определенных характеристик) попадет в ту или иную целевую группу. На практике описываемые методы, согласно значениям одной или нескольких независимых переменных (факторов), позволяют классифицировать респондентов по двум (бинарная) или более (мультиномиальная) группам, которые выражаются уровнями (вариантами ответа) какой-либо одной переменной.
Например, имеются ответы респондентов на вопрос Интересно ли Вам предложение о покупке земельного участка недалеко от Москвы? с вариантами ответа Да и Нет. Требуется выяснить, какие факторы в наибольшей степени определяют решение потенциальных покупателей о приобретении земельного участка. Для этого респондентам задается ряд вопросов с просьбой указать, какие элементы инфраструктуры им необходимы на данном участке, какое расстояние от Москвы является для них оптимальным, каков должен быть размер данного участка, должен ли на участке быть дом и т. п. Используя в данном случае метод бинарной логистической регрессии, можно классифицировать всех респондентов по двум целевым группам: заинтересованные в покупке земельного участка (потенциальные покупатели) и не заинтересованные. Также для каждого респондента в выборке будет рассчитана вероятность попадания в ту или иную группу.
Различие между рассматриваемыми двумя методами логистической регрессии заключаются в количестве категорий и типе зависимой переменной, а также типе независимых переменных. Так, в случае бинарной логистической регрессии исследуется зависимость дихотомической переменной от одной или нескольких независимых переменных, имеющих любой тип шкалы. Мультиномиальная логистическая регрессия является разновидностью бинарной, в которой зависимая переменная имеет более двух категорий. Независимые переменные должны относиться либо к номинальной, либо к порядковой шкале.
Еще в версии SPSS 11-12 был введен новый метод логистической регрессии: порядковая. Он используется в том случае, когда зависимая переменная относится к порядковой шкале. Причем независимые переменные должны быть либо номинальными, либо порядковыми. Мультиномиальный логистический регрессионный анализ является наиболее универсальным и, в целом, способен заменить собой два других метода. Однако наиболее качественное приближение статистических моделей может быть достигнуто только при использовании именно трех описываемых методов: для каждого случая — свой. В табл. 5.1 систематизированы основные характеристики переменных, участвующих в рассматриваемых трех типах логистического регрессионного анализа.
Таблица 5.1. Основные характеристики переменных, участвующих в анализе
| Бинарная логистическая регрессия | ||||
| Зависимые переменные | Независимые переменные | |||
| Количество | Тип | Количество | Тип | |
| Она | Дихотомическая | Любое | Любой | |
| Мультиноминальная логическая регрессия | ||||
| Зависимые переменные | Независимые переменные | |||
| Количество | Тип | Количество | Тип | |
| Одна | Номинальная Порядковая | Любое | Номинальная Порядковая | |
| Порядковая логистическая регрессия | ||||
| Зависимые переменные | Независимые переменные | |||
| Количество | Тип | Количество | Тип | |
| Одна | Порядковая | Любое | Номинальная Порядковая | |
Необходимо отметить, что ранее в SPSS отсутствовала стандартная возможность проведения специализированного логистического регрессионного анализа для зависимых переменных с порядковой шкалой. Для любых переменных с числом категорий больше двух применялся мультиномиальный регрессионный анализ. Дело в том, что недавно введенная в практику анализа порядковая логистическая регрессия имеет некоторые особенности, учитывающие именно специфику порядковой шкалы (связанных упорядоченных категорий). Однако в настоящем пособии порядковая логистическая регрессия не рассматривается отдельно — в первую, очередь из-за того, что она не обладает какими-либо существенными преимуществами над мультиномиальным методом. Вы можете спокойно применять мультиномиальную регрессию и в случае номинальной, и в случае порядковой зависимой переменной. Если вы все же решите провести порядковый логистический регрессионный анализ, вы без труда в нем разберетесь, так как данный процесс практически не отличается от построения мультиномиальной логистической регрессии.
Далее мы рассмотрим примеры проведения статистического анализа с использованием логистической регрессии отдельно для бинарной и мультиномиальной логистической регрессии.
Начнем с наиболее простого случая — бинарной логистической регрессии. Предположим, в ходе маркетингового исследования проводится оценка востребованности выпускников одного из московских вузов. В анкете респондентам в числе прочих задаются три вопроса:
■ Работаете ли вы? (ql);
■ В каком году Вы окончили вуз? (q21);
■ Каков был Ваш средний балл при выпуске из вуза? (aver), а также уточняется пол опрошенных (q22).
В ходе логистического анализа мы оценим влияние независимых переменных q21, q22 и aver на зависимую переменную ql. Другими словами, мы попытаемся предсказать трудоустройство выпускников вуза на основании пола, года окончания вуза и среднего балла, полученного за годы обучения.
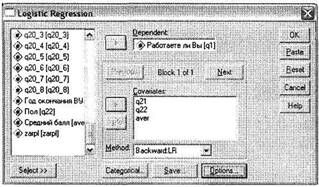
Для того чтобы задать параметры построения регрессионной модели при помощи бинарного логистического метода, воспользуемся меню Analyze ► Regression ► Binary Logistic. В открывшемся диалоговом окне Logistic Regression (рис. 5.1) выберите в левом списке всех доступных переменных зависимую (в нашем случае ql) и поместите ее в поле Dependent. Затем в область Covariates поместите исследуемые независимые переменные (q21, q22, aver) и выберите метод их включения в регрессионный анализ. При числе независимых переменных больше двух следует выбрать не установленный по умолчанию метод одновременного включения всех переменных (Enter), а один из пошаговых. Наиболее часто используемым пошаговым методом является Backward:LR. Кнопка Select позволяет включить в анализ не всех респондентов из выборочной совокупности, а только отдельную целевую группу.
 |
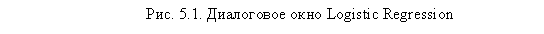 |
 |
Кнопкой Categorical следует воспользоваться, если в качестве одной из независимых переменных выступает номинальная переменная с числом категорий больше двух. В данном случае в диалоговом окне Define Categorical Variables (рис. 5.2) следует поместить в область Categorical Covariates такую переменную (в нашем случае таких переменных нет). Далее следует выбрать в раскрывающемся списке Contrast пункт Deviation и щелкнуть на кнопке Change. В результате из каждой номинальной переменной будет создано несколько дихотомических переменных (по числу категорий исходной переменной).
 |
При помощи кнопки Save в главном диалоговом окне анализа (рис. 5.3) можно задать создание новых переменных, содержащих значения, рассчитанные в ходе регрессионного анализа. Так давайте создадим две новые переменные, содержащие:
■ принадлежность к определенной группе классификации (параметр Group membership);
■ вероятность попадания респондента в каждую из двух рассматриваемых групп (параметр Probabilities).
 |
 |
Кнопка Options не предоставляет исследователю никаких важных возможностей, поэтому ее можно не использовать. После щелчка на кнопке О К в главном диалоговом окне Logistic Regression в окне SPSS Viewer будут выведены результаты бинарного логистического регрессионного анализа.
Далее мы рассмотрим наиболее существенные для маркетингового анализа результаты. В таблице Omnibus Tests of Model Coefficients отображаются результаты оценки
качества приближения статистической модели (рис. 5.4). Поскольку мы задали пошаговый метод, мы должны смотреть на результаты последнего шага (в нашем случае Step 2). Положительным результатом считается возрастание величины Chi-square при переходе на каждый следующий шаг (строка Step) при высоком уровне значимости (Sig. < 0,05). Качество всей модели оценивается на основании статистической значимости в строке Model. В нашем случае на втором шаге получена отрицательная величина Chi-square, однако она не является значимой (Sig. = 0,913), к тому же общая значимость всей модели весьма высока (Sig. < 0,001). Поэтому построенную модель следует признать значимой и практически пригодной.
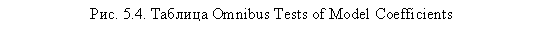 |
 |
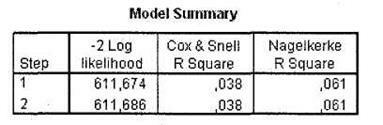
Следующая таблица Model Summary (рис. 5.5) позволяет оценить долю совокупной дисперсии, описываемой построенной моделью (величина R Square). Рекомендуется использовать величину Nagelkerke. В нашем случае эта величина мала (лишь 6 %). Положительным результатом можно считать величину Nagelkerke R Square, превышающую 0,50.
 |
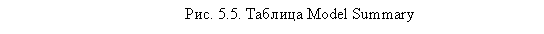 |
Далее следуют результаты классификации (таблица Classification Table, рис. 5.6), в которой реально наблюдаемые показатели принадлежности к той или иной из двух исследуемых групп сопоставляются с предсказанными на основе логистической регрессионной модели. В нашем случае из строки Overall Percentage мы видим, что построенная модель позволяет корректно классифицировать 80,4 % респондентов. Также можно сделать соответствующие выводы о корректности классификации для каждой из двух рассматриваемых групп.
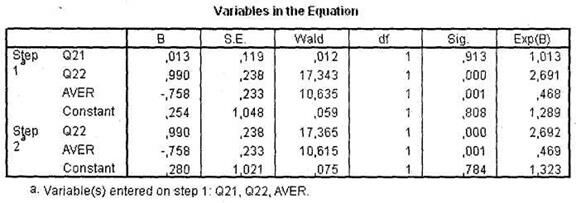
Из следующей таблицы (рис. 5.7) можно выяснить статистическую значимость независимых переменных, включенных в анализ (в нашем случае q22 и aver), а также нестандартизированные регрессионные коэффициенты, являющиеся коэффициентами регрессионной функции. На основании этих коэффициентов (включая константу Constant) вы можете спрогнозировать принадлежность к определенной группе каждого конкретного респондента в выборке. Это делается следующим образом.
 |
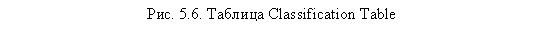 | |||
 |
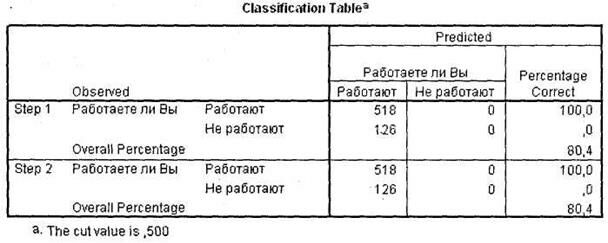
Например, выпускник вуза получил средний балл 3,3 (aver = 3,3); это женщина (q22 = 2). В таком случае уравнение регрессии будет выглядеть следующим образом:
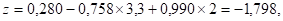
а вероятность для рассматриваемого респондента оказаться в одной из анализируемых групп классификации (это всегда группа зависимой переменной, имеющая больший код, в нашем случае 2 — Не работают) будет рассчитываться по формуле:
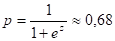
Таким образом, женщина со средним баллом 3,3 имеет достаточно высокие шансы оказаться безработной (68 %).
Теперь рассмотрим пример проведения мультиномиальной логистической регрессии. В качестве исходных данных мы будем использовать три независимые переменные из предыдущего примера, а в качестве зависимой — переменную q24 Заработная плата с пятью категориями, кодирующими интервалы зарплаты.
Откройте диалоговое окно Multinomial Logistic Regression при помощи меню Analyze ► Regression ► Multinomial Logistic (рис. 5.8). В поле для зависимой переменной поместите переменную q24, а в область для зависимых переменных — q21, q22 и aver.
Кнопка Model позволяет задать конкретный тип модели (полнофакторная, основные эффекты или пользовательская), однако для маркетинговых исследований мы советуем ничего не менять в окне Model.
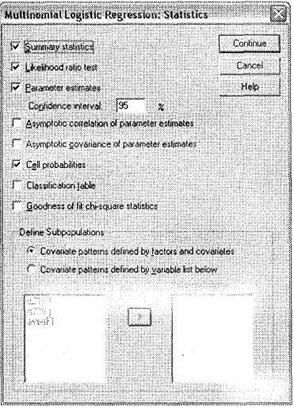
При помощи кнопки Statistics вызывается одноименное диалоговое окно (рис. 5.9). В нем следует оставить выбранные по умолчанию три параметра: Summary statistics, Likelihood ratio test и Parameter estimates, а также выбрать еще один пункт — Cell Probabilities.
 |
 |
 |
Кнопка Criteria не предоставляет маркетологам существенных для решения их задач функций, поэтому используется редко.
При помощи кнопки Save (рис. 5.10) можно задать новые переменные, содержащие принадлежность к определенной классификационной группе (параметр Predicted category) и вероятность попадания в данные категории (параметр Predicted probabilities membership).
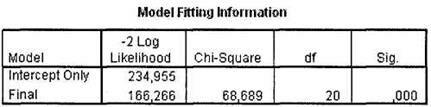
После щелчка на кнопке 0К в главном диалоговом окне Multinomial Logistic Regression в окне SPSS Viewer появятся результаты расчетов. Первая таблица, содержащая важные для нас сведения, — это Model Fitting Information, показанная на рис. 5.11. Высокая статистическая значимость построенной модели (Sig. < 0,001) свидетельствует о ее высоком качестве и пригодности для решения практических задач.
Вторая значимая таблица Pseudo R-Square предоставляет возможность оценить долю совокупной дисперсии в зависимой переменной, объясняемой выбранными для анализа независимыми переменными (по тесту Nagelkerke). В нашем случае построенная модель объясняет 15 % совокупной дисперсии (рис. 5.12).
Таблица Likelihood Ratio Tests (рис. 5.13) позволяет сделать выводы относительно статистической значимости каждой из зависимых переменных, входящих в построенную модель. В нашем случае все три исследуемые переменные оказывают весьма значимое влияние на зависимую переменную (Sig. < 0,05).
 |
 |
 |
 |
 |
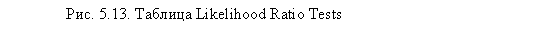 |
 |
 |
 |
 |
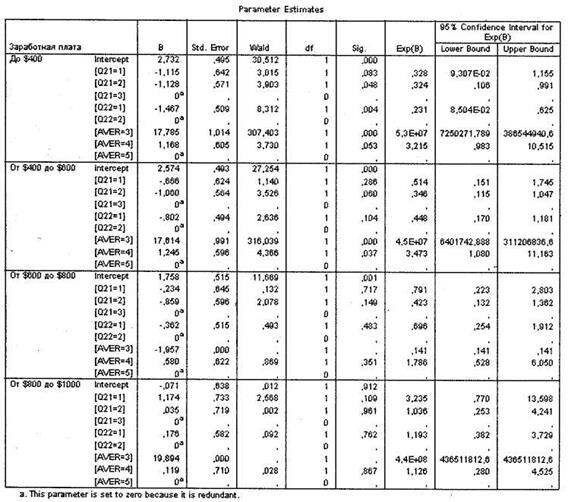
Следующая таблица, Parameter Estimates (рис. 5.14), отражает нестандартизированные регрессионные коэффициенты, на основании которых происходит построение регрессионного уравнения. Также для каждого сочетания анализируемых переменных рассчитана статистическая значимость их влияния на зависимую переменную. В дальнейшем рассчитать вероятность попадания того или иного респондента в одну из исследуемых групп зависимой переменной можно по вышеприведенной формуле (показана при обсуждении бинарной логистической регрессии).
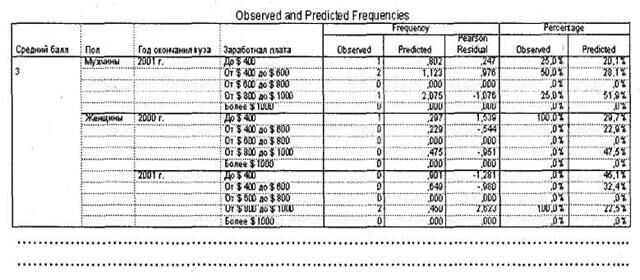
Однако в маркетинговых исследованиях чаще всего возникает необходимость классифицировать по группам не отдельных респондентов, а целые целевые группы. Для этого служит таблица Observed and Predicted Frequencies, представленная на рис. 5.15. В столбце Percentage ► Predicted показаны вероятности попадания каждой исследуемой целевой группы респондентов в ту или иную категорию зависимой переменной. Так, например, мы видим, что 20 % мужчин, окончивших ВУЗ в 2001 г. и получивших средний балл 3,0, зарабатывают до $ 400 в месяц.
 |
5.1.2. Дискриминантный анализ
Дискриминантный анализ является более универсальной статистической процедурой по сравнению с рассмотренными выше методами логистической регрессии. Основным результатом проведения дискриминантного анализа являются (также как для логистической регрессии) рассчитанные вероятности попадания каждого респондента в ту или иную группу, а также переменная, кодирующая принадлежность их к данным группам. Наряду с этой информацией по результатам дискриминантного анализа можно составить уравнение дискриминантной функции.
В табл. 5.2 приведены основные характеристики переменных, участвующих в дис-криминантном анализе.
Таблица 5.2. Основные характеристики переменных, участвующих в анализе
| Дискриминантный анализ | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| Одна | Номинальная Порядковая | Любое | Любой |
При выборе зависимой переменной для дискриминантного анализа следует помнить, что увеличение числа категорий в ней практически всегда влечет уменьшение качества статистической модели, то есть ее точности и надежности. Поэтому рекомендуется использовать в качестве зависимых переменные с малым количеством категорий (или преобразовывать существующие переменные к данному виду).
Для описания процесса проведения дискриминантного анализа применим следующие исходные данные. Проводится маркетинговое исследование потенциального спроса на услуги нового развлекательного комплекса. Респонденты в ходе опроса отвечают на вопрос Будете ли Вы посещать новый комплекс? (q26) с вариантами ответа Да и Нет. В качестве независимых переменных, характеризующих респондентов, выделены:
■ возраст (ql8);
■ род занятий (ql9);
■ среднемесячный доход (q20);
■ количество членов семьи (q21);
■ среднемесячные расходы на досуг (q22);
■ пол (q23).
В результате дискриминантного анализа мы разделим респондентов на посетителей и не посетителей нового центра на основании выделенных социально-демографических характеристик опрошенных.
 |
Откройте диалоговое окно Discriminant Analysis при помощи меню Analyze ► Classify ► Discriminant (рис. 5.16). Поместите переменную q26 в поле для зависимых переменных Grouping Variable, а анализируемые независимые переменные — в область Independents. Выберите пошаговый метод ввода независимых переменных в модель (параметр Use stepwise method).
 |
Далее щелкните на кнопке Define Range для определения границ изменения зависимой переменной q26 (рис. 5.17). В нашем случае минимальным значением (Minimum) является 1, а максимальным (Maximum) — 2.
При помощи диалогового окна Statistics, активизируемого одноименной кнопкой, следует задать вывод результатов одномерного дисперсионного анализа (параметр
 |
Univariate ANOVA), теста Box (параметр Box's M), а также нестандартизированых коэффициентов регрессии (параметр Unstandardized) (рис. 5.18).
 |
 |
 |
В следующем диалоговом окне, Stepwise Method, вызываемом при помощи кнопки Method, следует выбрать параметр Use probability of F (рис. 5.19). Активизация данного параметра позволяет проводить введение переменных в регрессионную модель более гибко по сравнению с абсолютным значением F-статистики (параметр, выбранный по умолчанию).
В следующем диалоговом окне, Classification, нас интересует только один параметр — Summary Table (рис. 5.20),
Наконец, при помощи кнопки Save можно создать в исходном файле данных новые переменные, содержащие для каждого респондента в выборке прогнозируемую принадлежность к группе (параметр Predicted group membership) и вероятность попадания каждого респондента в данные группы (параметр Probabilities of group membership; см. рис. 5.21).
После выполнения вышеописанных шагов щелкните на кнопке 0К, чтобы запустить программу дискриминантного анализа на исполнение. После окончания расчетов в окне SPSS Viewer будут выведены результаты расчетов.
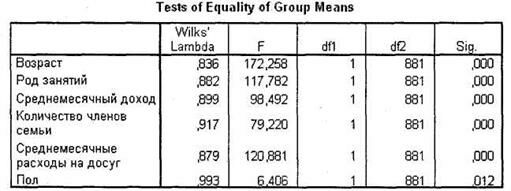
Первой важной для нас таблицей является Tests of Equality of Group Means (рис. 5.22). Она показывает, насколько значимо выбранные независимые переменные разделяют выборочную совокупность респондентов на исследуемые группы. В нашем случае получены весьма значимые результаты для всех исследуемых переменных (Sig. < 0,05). Это свидетельствует о том, что на их основании исследуемые группы зависимой переменной существенно различаются.
 |
Следующая таблица, Test Results, показывает результаты теста Box на значимость различия между категориями исследуемой зависимой переменной (рис. 5.23). В нашем случае данный тест показывает весьма высокую вероятность того, что данные различия являются статистически значимыми (Sig. < 0,001).
 |
 | |||
 |
 |

 |
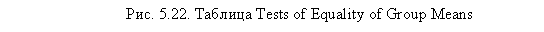 |
 |
 |
Таблица Variables in the Analysis показывает, какие независимые переменные оказались включенными в итоговую дискриминантную модель на последнем шаге анализа (напомним, что мы выбрали пошаговый метод включения переменных в модель). В нашем случае последним шагом является шаг 4. На четвертом шаге у нас остались четыре независимые переменные из шести (рис. 5.24).
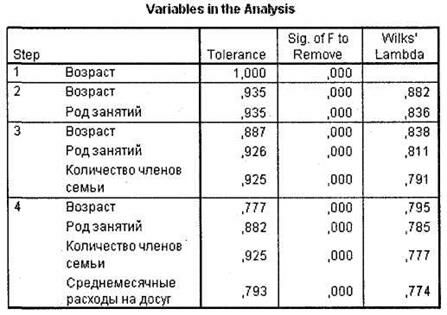 |

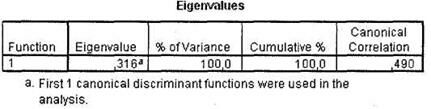
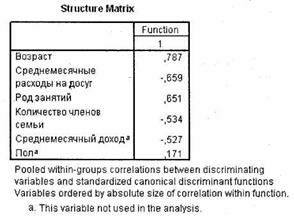
Таблица Eigenvalues позволяет оценить качество разделения респондентов на заданные группы зависимой переменной (рис. 5.25). Соответствующий вывод можно сделать исходя из корреляционного коэффициента (столбец Canonical Correlation). В нашем случае данный коэффициент примерно равен 0,5, что свидетельствует о неудовлетворительном результате.
Еще одним важным показателем в этой таблице является собственное значение дискриминантной функции (столбец Eigenvalue). В общем случае большие значения Eigenvalues указывают на высокую точность подобранной дискриминантной функции. В нашем случае рассматриваемое собственное значение весьма мало, что является негативным фактом. Необходимо отметить, что при наличии у зависимой переменной более двух категорий в ходе дискриминантного анализа строится несколько дискриминантных функций (по количеству категорий зависимой переменной минус 1).
Следующая таблица (рис. 5.26) также позволяет оценить качество приближения дискриминантной модели. В нашем случае статистическая значимость (Sig. < 0,001)
 |
указывает на существенные различия между средними значениями дискриминантных функций в двух исследуемых группах зависимой переменной.
 |
 |
 |
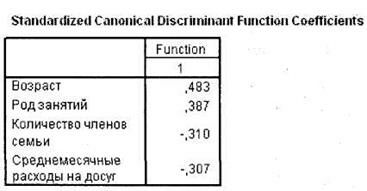
Следующие две таблицы (рис. 5.27 и 5.28) позволяют оценить, насколько отдельные независимые переменные, применяемые в дискриминантной функции, коррелируют с ее стандартизированными коэффициентами. В первой таблице приводятся стандартизированные коэффициенты, а во второй — корреляционные коэффициенты. При помощи стандартизированных коэффициентов, кроме всего прочего, можно непосредственно сравнивать относительный вклад каждой независимой переменной в различение двух исследуемых групп. Например, мы видим, что возраст респондентов влияет на их желание/нежелание посещать новый центр в 1,3 раза сильнее, чем род занятий.
Далее следуют коэффициенты дискриминантной функции (нестандартизирован-ные), на основании которых и строится дискриминантное уравнение, по форме похожее на уравнение регрессии (рис. 5.29). Это просто множители при соответствующих переменных. С учетом константы уравнение дискриминантной функции имеет вид:
Z=-0,845 + 0,207 × Возраст + 0,198 × Род_занятий - 0,289 × Кол-во_членов_семьи - 0,285 × Среднемесячные_расходы_на_досуг
Теперь на основании данного уравнения молено рассчитать вероятность, с которой та или иная социально-демографическая целевая группа респондентов будет посещать новый центр. Подставив в дискриминантное уравнение соответствующие значения, можно сделать вывод о том, что студенты в возрасте 20 лет, проживающие одни и расходующие на свой досуг $ 50 в месяц, скорее всего, будут посещать новый развлекательный центр (вероятность 79 %)'.
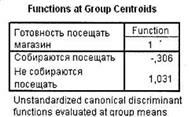
Таблица, представленная на рис. 5.30, показывает средние значения дискриминантной функции в каждой анализируемой группе зависимой переменной.
 |
 |
 |
 |
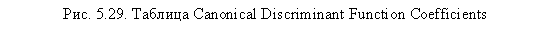 |
 |
 |
 |
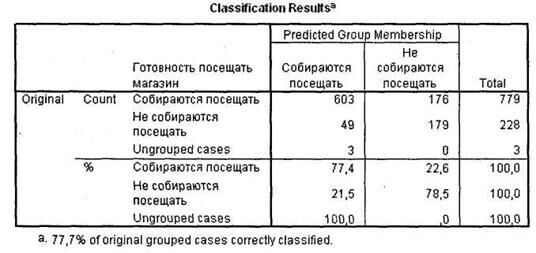 |
Завершает вывод результатов дискриминантного анализа таблица Classification Results, в последней строке которой содержится информация о точности построенной модели (рис. 5.31). В нашем случае мы видим, что 77,7 % респондентов были корректно отнесены к одной из двух исследуемых групп (77,7% of original grouped cases correctly classified). Результаты оценки корректности классификации варьируются в пределах от 50 % до 100 %, поэтому полученный нами результат — примерно 78 % — можно считать удовлетворительным.
 |
5.2. Факторный и кластерный анализ
Кластерный и факторный анализы преследуют ту же цель, что и рассмотренные в предыдущем разделе методы логистической регрессии и дискриминантного анализа: классифицировать переменные и/или категории респондентов по однородным группам (сегментам, кластерам). Однако между этими методами существует одно серьезное различие. При дискриминантном анализе и логистической регрессии у нас заранее есть некая зависимая (результирующая) переменная с двумя или более вариантами ответа (уровнями, категориями). Задача анализа в данном случае состоит в классификации имеющихся категорий респондентов (возрастных, половых и других) по этим уровням результирующей переменной. Эти два статистических метода позволяют сегментировать выборку на заранее известные целевые группы. При кластерном и факторном анализе ситуация иная: кластеры (сегменты, категории), на которые следует разделить выборку, заранее не известны. Задачей статистического анализа в данном случае будет не только формирование максимально однородных сегментов, но и выделение кластеров, по которым будет производиться сегментирование. Приведем пример релевантного задания для факторного (кластерного) анализа.
Исходные данные:
Респондентам (пассажирам международных рейсов авиакомпании X) в ходе опроса предлагалось 24 утверждения, по которыми они должны были выразить степень своего согласия либо несогласия по десятибалльной шкале — от 1 (совершенно не согласен) до 10 (абсолютно согласен). Предложенные утверждения описывают текущую конкурентную позицию рассматриваемой компании на международном рынке авиаперевозок. В результате опроса и последующих подготовительных этапов к статистическому анализу (см. раздел 3) был получен массив из 24 одновариантных переменных (ql-q24) с кодами ответов соответственно от 1 до 10 (интервальная шкала).
ql. Авиакомпания X обладает репутацией компании, превосходно обслуживающей пассажиров.
q2. Авиакомпания X может конкурировать с лучшими авиакомпаниями мира.
q3. Я верю, что у авиакомпании X есть перспективное будущее в мировой авиации.
q4. Я знаю, какой будет стратегия развития авиакомпании X в будущем.
q5. Я горжусь тем, что работаю в авиакомпании X.
q6. Внутри авиакомпании X хорошее взаимодействие между подразделениями.
q7. Каждый сотрудник авиакомпании прикладывает все усилия для того, чтобы обеспечить ее успех.
q8. Сейчас авиакомпания X быстро улучшается.
q9. Нам предстоит долгий путь, прежде чем мы сможем претендовать на то, чтобы
называться авиакомпанией мирового класса.
qlO. Авиакомпания X действительно заботится о пассажирах.
qll. Среди сотрудников авиакомпании имеет место высокая степень удовлетворенности работой.
ql2. Я верю, что менеджеры высшего звена прикладывают все усилия для достижения успеха авиакомпании.
ql3. Мне нравится, как в настоящее время авиакомпания X представлена визуально широкой общественности (в плане цветовой гаммы и фирменного стиля).
ql4. Авиакомпания X — лицо России.
ql5. Мы выглядим «вчерашним днем» по сравнению с другими авиакомпаниями.
ql6. Обслуживание авиакомпании Х является последовательным и узнаваемым во всем мире.
ql7. Я бы не хотел, чтобы авиакомпания X менялась.
ql8. Авиакомпании X необходимо меняться для того, чтобы использовать в полной мере имеющийся потенциал.
ql9. Я думаю, что авиакомпании X необходимо представить себя в визуальном плане более современно.
q20. Изменения в авиакомпании X будут позитивным моментом. q21. Авиакомпания X — эффективная авиакомпания.
q22. Я бы хотел, чтобы имидж авиакомпании X улучшился с точки зрения иностранных пассажиров.
q23. Авиакомпания X — лучше, чем многие о ней думают.
q24. Важно, чтобы люди во всем мире знали, что мы — российская авиакомпания. Требуется:
Выявить схожие (то есть тесно коррелирующие между собой) утверждения и разделить их на несколько однородных групп, описывающих различные аспекты (макропараметры)
конкурентной позиции авиакомпании X на рынке. Другими словами, выделить группы схожих по значению параметров авиакомпании, характеризующих ее состояние на рынке с различных сторон.
Данную задачу невозможно решить методами логистической регрессии или дискриминантного анализа, так как у нас нет зависимой (результирующей) переменной: есть только массив, на первый взгляд, независимых равнозначных параметров. Поставленную цель можно достичь при помощи либо факторного анализа, либо кластерного. Однако прежде, чем мы приступим к решению, следует сказать несколько слов об основных характерных чертах и различиях между этими двумя статистическими методами, предназначенными для решения схожих задач.
Факторный анализ позволяет разделить массив переменных на малое число групп, которые называются факторами. Классификация производится на основании критерия корреляции между переменными. В один фактор объединяются несколько переменных, тесно коррелирующих между собой и не коррелирующих или слабо коррелирующих с другими переменными, составляющими другие факторы. Таким образом, в результате факторного анализа мы получаем из несистематизированного массива данных несколько макропеременных, описывающих различные характеристики продукта компании (или другого исследуемого объекта). Основная сложность при проведении факторного анализа заключается в необходимости рационально интерпретировать полученные макрокатегории с точки зрения здравого смысла (применительно к целям и специфике конкретного исследования). Данная проблема не имеет универсального решения и подлежит отдельному анализу в каждом конкретном случае. Ниже мы продемонстрируем пример интерпретации результатов факторного анализа. Именно сложность интерпретации результатов является существенным ограничением рассматриваемой статистической методики, так как из-за невозможности логического описания полученных категорий иногда приходится вообще отказаться от ее использования.
Еще одним ограничением применения факторного анализа является ситуация, когда одна и та же переменная относится сразу к двум или более факторам, то есть переменную нельзя однозначно классифицировать. В таком случае следует либо отказаться от использования факторного анализа и попытаться применить другие статистические методики (например, кластерный анализ), либо заново пересчитать факторную модель без данной переменной, а затем вручную отнести неоднозначную переменную к тому или иному фактору на основании логических соображений.
Далее приведены основные примеры использования факторного анализа в маркетинговых исследованиях.
Сегментирование рынка. Факторный анализ применяется для выявления агрегатных переменных, являющихся основанием для сегментирования потребителей. Например, потребители плавленых сыров могут характеризоваться различной степенью значимости, которую они видят в исследуемых характеристиках данного продукта (респондентов просят оценить по пятибалльной шкале важность нескольких характеристик плавленых сыров: срок хранения, калорийность, процент жирности и т. д.). Здесь факторный анализ позволит выявить целевые сегменты потребителей на основании значимости для них различных групп факторов:
■ покупатели, ориентирующиеся при выборе плавленого сыра преимущественно на ценовые факторы (стоимость, скидки);
■ покупатели, ориентирующиеся на качество исследуемого продукта (срок хранения, состав ингредиентов, вкус);
■ покупатели, выбирающие сыр в основном по внешнему виду (дизайн упаковки).
В целом следует отметить, что в настоящее время все большую популярность среди исследователей приобретают методы сегментирования потребителей на основании их психографических характеристик. Для этого в анкету включается достаточно большое количество высказываний (порядка 100-150), характеризующих различные стороны жизненного стиля респондентов. Респонденты должны выразить свое согласие или несогласие с данными высказываниями по шкале Лайкерта (согласен — скорее согласен — ни то ни другое — скорее не согласен — не согласен). В дальнейшем на основании ответов респондентов формируются однородные целевые сегменты (обычно порядка 10).
Изучение продукта и бенчмаркинг продукта. В данном случае факторный анализ помогает выявить агрегатные параметры продукта, влияющие на выбор потребителя. Например, различные марки шоколадных конфет могут быть оценены по следующим макрокатегориям: качество (ингредиенты, вкус), полезность для здоровья (наличие сахара, калорийность) и цена.
Рекламные и медиа-исследования. Факторный анализ может использоваться для выявления скрытых мотивов поведения потребителей при восприятии рекламы.
Ценообразование. Факторный анализ используется для выявления особенностей поведения потребителей, чувствительных к цене. Например, данная категория респондентов может характеризоваться повышенным вниманием к ценовым факторам при выборе продукта, низкими доходами, большой численностью семьи и т. д.
Кластерный анализ является аналогом факторного анализа в том-смысле, что он так же, как и факторный анализ, позволяет выделить факторы (кластеры), объединяющие статистически схожие переменные. Однако в данном случае переменные классифицируются не на основании степени тесноты корреляционной связи, а на основании более сложных статистических процедур (наиболее часто используется метод исследования расстояний между переменными в кластерах). Ниже мы продемонстрируем действие обеих анализируемых статистических методик на одном массиве данных (см. выше).
Несмотря на имеющуюся возможность классифицировать переменные кластерный анализ чаще всего применяется для кластеризации групп респондентов (то есть уровней или категорий переменных)1. Данная возможность позволяет, например,
провести пробное (при неизвестных целевых группах) сегментирование целевых покупателей какого-либо продукта. Сформированные в результате кластерного анализа целевые группы респондентов обладают схожим поведением (то есть взаимозависимостями) своих характеристик. В качестве примера успешной кластеризации можно привести разбиение респондентов на две группы:
■ женщины в возрасте старше 45 лет;
■ все мужчины и женщины младше 45 лет.
При использовании рассматриваемой статистической методики для кластеризации респондентов можно совмещать кластерный и факторный анализ, причем в данном случае факторный анализ будет предшествовать кластерному. Часто это делается для того, чтобы сократить количество переменных, участвующих в кластерном анализе (при большом числе этих переменных). Так, можно сначала выделить среди большого числа переменных макропараметры, а затем сегментировать респондентов уже на основании данных факторов.
Теперь у вас сложилось общее представление о методах факторного и кластерного анализа, и мы можем приступить к описанию их практического применения. Воспользуемся условием задачи про анализ текущей конкурентной позиции авиакомпании X. Эта задача поможет нам также сравнить действие данных статистических методик на одной и той же выборке. Для описания кластерного анализа, применяемого для кластеризации респондентов, мы будем использовать другой пример из практики маркетинговых исследований. Так как для классификации переменных факторный анализ все же применяется чаще, чем кластерный (это сложилось исторически и, кроме того, оправдано меньшими усилиями, затрачиваемыми на проведение факторного анализа), в разделе 5.2.2 основное внимание будет уделено описанию действия кластерного анализа для классификации респондентов (выделения целевых групп потребителей). Сравнение действия двух статистических методов при классификации переменных мы предложим уже в заключении раздела 5.2.2.
В качестве примеров практического применения кластерного анализа в маркетинговых исследованиях можно указать все те же случаи, что и при факторном анализе (если кластерный анализ используется для классификации переменных). В случае применения кластерного анализа для классификации конкретных групп респондентов он предоставляет исследователю гораздо более гибкие возможности и в большем числе областей маркетинговых исследований по сравнению с факторным анализом. Это преимущество кластерного анализа обусловлено тем, что он анализирует не переменные в целом, а конкретные категории респондентов (например, различные половозрастные, доходные и другие группы покупателей). Таким образом, можно сделать важный вывод относительно факторного и кластерного анализов. Целью факторного анализа является сокращение числа переменных, участвующих в анализе (выделение релевантных макрокатегорий переменных), а целью кластерного — классификация респондентов на целевые группы на основании их существенных характеристик.
Из всего сказанного становится понятно, почему оба типа статистического анализа иногда используются в паре: факторный анализ определяет состав макропеременных (например, для сегментирования потребителей), а кластерный на основании выделенных существенных характеристик респондентов производит формирование целевых сегментов. Применение факторного и кластерного анализов в паре оправдано в основном в тех случаях, когда изначально респонденты оцениваются по большому числу параметров и проведение кластерного анализа непосредственно над данным (большим) набором переменных представляется затруднительным или даже практически невозможным. Отметим, что для проведения факторного и кластерного анализов в паре следует сначала провести факторный анализ, сохранив полученные факторные рейтинги, а затем проводить кластерный анализ на основании полученных групп переменных. Более подробно парное использование факторного и кластерного анализов будет показано в разделе 5.2.2.
В табл. 5.3 представлены основные характеристики переменных, участвующих в факторном и кластерном анализах.
Таблица 5.3. Основные характеристики переменных, участвующих в факторном и кластерном анализах
| Факторный анализ | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| Нет | - | Любое | Любой |
| Кластерный анализ | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| Нет | - | Любое | Любой |
5.2.1. Факторный анализ
Итак, из условия представленной выше задачи следует, что у нас есть массив данных, состоящий из 24 независимых переменных (утверждений), в различных аспектах описывающих текущее состояние авиакомпании X на международном рынке авиаперевозок. Основной задачей проводимого факторного анализа является группировка схожих по смыслу утверждений в макрокатегории с целью сократить число переменных и оптимизировать структуру данных.
При помощи меню Analyze ►Data Reduction ► Factor вызовите окно Factor Analysis. Перенесите из левого списка в правый переменные для анализа (ql-q24), как показано на рис. 5.32. Поле Selection Variable позволяет выбрать переменную, в разрезе которой будет проводиться анализ (например, класс полета). В нашем случае оставьте это поле Пустым.
Щелкните на кнопке Descriptives и в открывшемся диалоговом окне (рис. 5.33) выберите пункт КМО and Barlett's test of sphericity. Это позволит определить, насколько имеющиеся данные пригодны для факторного анализа. Окно Descriptives позволяет вывести и другие необходимые описательные статистики. Однако в большинстве примеров из маркетинговых исследований эти возможности, как правило, не используются.
 |
 |
 |
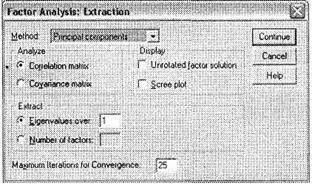
Закройте окно Descriptives, щелкнув на кнопке Continue. Далее откройте окно Extraction (рис. 5.34), щелкнув на соответствующей кнопке в главном диалоговом окне Factor Analysis. Это окно предназначено для выбора метода формирования факторной модели; выполните в нем следующие действия.
 |
 |
Во-первых, в поле Method выберите метод извлечения (формирования) факторов. Общая рекомендация по выбору метода состоит в следующем. Необходимо выбирать тот метод извлечения факторов, который позволяет однозначно классифицировать как можно больше переменных. Таким образом, основные соображения здесь — число классифицированных факторов и однозначность классификации (то есть каждая переменная должна принадлежать только одному фактору). Как вы увидите ниже, установленный по умолчанию в SPSS метод Principal components в нашем случае позволяет однозначно классифицировать 22 переменные из 24 имеющихся (92 %), что является весьма хорошим показателем. На основании имеющегося опыта автор может утверждать, что хорошим результатом факторного анализа является доля однозначно классифицированных переменных не менее 90 %. Выберите метод Principal components. Данный метод является наиболее подходящим для решения большинства задач маркетинговых исследований при помощи факторного анализа.
Во-вторых, укажите количество образуемых факторов (группа Extract). По умолчанию установлен метод определения количества извлекаемых факторов на основании значений характеристических чисел (Eigenvalues over). He вдаваясь в статистические тонкости, отметим, что характеристические числа используются SPSS для определения количественного и качественного состава извлекаемых факторов. При предустановленном значении данного показателя , равном 1, количество образуемых факторов будет равно количеству переменных, значение характеристических чисел для которых больше или равно 1.
Также существует возможность вручную указать программе, сколько факторов необходимо извлекать (Number of factors). Эта возможность предусмотрена в SPSS для того, чтобы при слишком большом количестве переменных с характеристическим числом больше 1 вручную сократить число факторов. Большое число факторов трудно интерпретировать, поэтому если методом характеристических чисел не удается извлечь приемлемое для интерпретации число факторов (чем меньше, тем лучше), следует самостоятельно указать программе число факторов. Эта задача решается аналитиком в каждом конкретном случае индивидуально. В качестве одного из вариантов решения можно рекомендовать увеличить число eigenvalue с предустановленного значения 1, скажем, до 1,5 или более. Это поможет, если получено большое число факторов с характеристическим числом, приблизительно равным 1, и несколько (2-3 и более) факторов — с характеристическим числом более 1,5 или другого значения. Также при ручном определении количества факторов аналитик может принять релевантное решение, основываясь на своем опыте или на каких-либо иных предположениях. И наконец, необходимо отметить, что при ручном указании числа извлекаемых факторов иногда количество однозначно классифицированных переменных оказывается меньше, чем при методе экстракции по величине характеристических чисел. Однако данный негативный момент нивелируется возросшей наглядностью результатов факторного анализа — ведь это позволяет освободиться от факторов, в которых нет переменных со значимым коэффициентом корреляции (в нашем случае 0,5).
Закройте диалоговое окно Extraction, щелкнув на кнопке Continue. Выберите тип ротации матрицы коэффициентов (кнопка Rotation в главном диалоговом окне Factor Analysis). Ротация коэффициентной матрицы производится для того, чтобы максимально приблизить факторную модель к идеалу: возможности однозначно классифицировать все переменные. В диалоговом окне Rotation (рис. 5.35) выберите конкретный метод ротации. В большинстве случаев наиболее приемлемым вариантом является метод Varimax. Он облегчает интерпретацию факторов, минимизируя количество переменных с высокими факторными нагрузками. Выберите этот тип ротации и закройте диалоговое окно, щелкнув на кнопке Continue.
 |
 |
Далее откройте диалоговое окно Factor Scores (рис. 5.36), щелкнув на кнопке Scores. Это окно служит для создания в исходном файле данных новых переменных, которые в дальнейшем позволят отнести каждого респондента к определенной группе (фактору). Число вновь создаваемых переменных равно числу извлеченных факторов. Ниже мы покажем, каким образом использовать данные переменные. Выберите в диалоговом окне Factor Scores параметр Save as variables, а в качестве метода определения значений для этих новых переменных — регрессионную модель Regression. После этого закройте диалоговое окно, щелкнув на кнопке Continue.
 |
 |
Последним этапом перед запуском процедуры факторного анализа является выбор некоторых дополнительных параметров (кнопка Options). В открывшемся диалоговом окне (рис. 5.37) выберите два пункта: Sorted by size и Suppress absolute values less than. Первая опция позволяет вывести переменные, входящие в каждый фактор, в порядке убывания их факторных коэффициентов (величины вклада переменной в формирование фактора). Вторая оказывается весьма полезна, так как облегчает задачу однозначной интерпретации полученных факторов. Указанное в соответствующем поле значение данного параметра (в нашем случае 0,5) отсекает переменные с факторными коэффициентами менее данного значения. Это позволяет упростить ротированную матрицу факторов, поскольку из нее исчезают незначимые переменные, входящие в каждый извлеченный фактор. Если вы не задействуете данный параметр, для каждой переменной будет отображен факторный коэффициент по каждому фактору, что излишне перегрузит факторную модель и затруднит ее восприятие исследователями.
Параметр Suppress absolute values less than вводится, чтобы облегчить практическую интерпретацию результатов факторного анализа. Так как факторные коэффициенты в результирующей ротированной матрице коэффициентов являются коэффициентами корреляции между соответствующими переменными и факторами, в большинстве практических случаев целесообразно устанавливать начальное значение отсечения незначимых переменных на уровне 0,5. Если в результате факторного анализа окажется, что число классифицированных переменных менее приемлемого (например, если структура данных не вполне подходит для факторного анализа; см. ниже), можно пересчитать факторную модель с меньшим значением отсечения (например, 0,4). В обратной ситуации, если переменная входит в несколько факторов, можно предложить повысить уровень экстракции с 0,5 до 0,6. Это позволит устранить переменные, входящие сразу в несколько факторов, увеличив практическую пригодность результатов факторного анализа.
Итак, указав все необходимые параметры в окне Options, закройте его (кнопка Continue) и запустите процедуру факторного анализа при помощи щелчка на кнопке 0К в главном диалоговом окне Factor Analysis.
 |
 |
После того как программа произведет все необходимые расчеты, откроется окно SPSS Viewer с результатами построения факторной модели. Первое, что нас интересует, — это пригодность имеющихся данных для факторного анализа в целом. Посмотрим на таблицу КМО and Barlett's Test (рис. 5.38). В ней есть два интересующих нас показателя: тест КМО и значимость теста Barlett. Результаты теста КМО позволяют сделать вывод относительно общей пригодности имеющихся данных для факторного анализа, то есть насколько хорошо построенная факторная модель описывает структуру ответов респондентов на анализируемые вопросы. Результаты данного теста варьируются в интервале от 0 (факторная модель абсолютно неприменима) до 1 (факторная модель идеально описывает структуру данных). Факторный анализ следует считать пригодным, если КМО находится в пределах от 0,5 до 1. В нашем случае этот показатель равен 0,9, что является весьма хорошим результатом.
Barlett's test of sphericity проверяет гипотезу о том, что переменные, участвующие в факторном анализе, некоррелированы между собой. Если данный тест дает положительный результат (переменные некоррелированы), факторный анализ следует признать непригодным использовать другие статистические методы (например, кластерный анализ). Статистикой, определяющей пригодность факторного анализа по тесту Barlett, является значимость (строка Sig.). При приемлемом уровне
значимости (ниже 0,05) факторный анализ считается пригодным для анализа исследуемой выборочной совокупности. В нашем случае рассматриваемый тест показывает весьма низкую значимость (менее 0,001), из чего следует вывод о применимости факторного анализа.
Итак, на основании тестов КМО и Barlett мы пришли к выводу, что имеющиеся у нас данные практически идеально подходят для исследования при помощи факторного анализа.
 |
 |
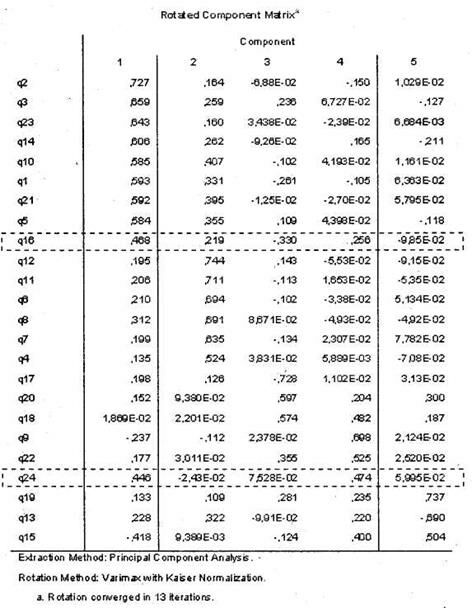
Следующим шагом в интерпретации результатов факторного анализа является рассмотрение результирующей ротированной матрицы факторных коэффициентов: таблицы Rotated Component Matrix (рис. 5.39). Данная таблица является основным результатом факторного анализа. В ней отражаются результаты классификации переменных по факторам. В нашем случае при помощи автоматического метода определения количества факторов (на основании характеристических чисел больше 1) была построена практически приемлемая факторная модель, в которой 22 из 24 переменных удалось однозначно классифицировать по небольшому числу факторов (5). Данный результат может считаться хорошим.
С неклассифицированными переменными можно поступить следующим образом. Необходимо просто пересчитать факторную модель, удалив в диалоговом окне Options ранее установленное значение отсечения 0,5. Далее будет построена факторная матрица (рис. 5.40), в которой аналитику предстоит самостоятельно определить принадлежность неклассифицированных переменных к тому или иному фактору на основании критерия наибольшего коэффициента корреляции между переменными и пятью факторами. В нашем случае вы видите, что переменная ql6 в наибольшей степени коррелирует с фактором 1 (факторный коэффициент 0,468) и, следовательно, должна быть отнесена к данному фактору, а переменная q24 — с фактором 4 (0,474).
После того как мы однозначно классифицировали все переменные, вернемся к таблице на рис. 5.40. Мы получили пять групп переменных (факторов), описывающих текущую конкурентную позицию авиакомпании X с пяти различных сторон. Вот эти группы.
Фактор 1
q2. Авиакомпания X может конкурировать с лучшими авиакомпаниями мира. q3. Я верю, что у авиакомпании X есть перспективное будущее в мировой авиации. q23. Авиакомпания X — лучше, чем многие о ней думают. q!4. Авиакомпания X — лицо России.

 |
qlO. Авиакомпания Х действительно заботится о пассажирах.
ql. Авиакомпания X обладает репутацией компаний, превосходно обслуживающей пассажиров.
q21. Авиакомпания X — эффективная авиакомпания. q5. Я горжусь тем, что работаю в авиакомпании X.
ql6. Обслуживание авиакомпании X является последовательным и узнаваемым во всем мире.
Фактор 2
ql2. Я верю, что менеджеры высшего звена прикладывают все усилия для достижения успеха авиакомпании.
qll. Среди сотрудников авиакомпании имеет место высокая степень удовлетворенности работой.
q6. Внутри авиакомпании X хорошее взаимодействие между подразделениями.
 |
 |
q8. Сейчас авиакомпания X быстро улучшается.
q7. Каждый сотрудник авиакомпании прикладывает все усилия для того, чтобы обеспечить ее успех.
q4. Я знаю, какой будет стратегия развития авиакомпании X в будущем.
Фактор 3
ql7. Я бы не хотел, чтобы авиакомпания X менялась.
q20. Изменения в авиакомпании X будут позитивным моментом.
ql8. Авиакомпании X необходимо меняться для того, чтобы использовать в полной мере имеющийся потенциал.
Фактор 4
q9. Нам предстоит долгий путь, прежде чем мы сможем претендовать на то, чтобы называться авиакомпанией мирового класса.
q22. Я бы хотел, чтобы имидж авиакомпании X улучшился с точки зрения иностранных пассажиров.
q24. Важно, чтобы люди во всем мире знали, что мы — российская авиакомпания.
Фактор 5
ql9. Я думаю, что авиакомпании X необходимо представить себя в визуальном плане более современно.
ql3. Мне нравится, как в настоящее время авиакомпания X представлена визуально широкой общественности (в плане цветовой гаммы и фирменного стиля).
ql5. Мы выглядим «вчерашним днем» по сравнению с другими авиакомпаниями.
Наиболее сложной задачей при проведении факторного анализа является интерпретация полученных факторов. Здесь не существует какого-либо универсального решения: в каждом конкретном случае, аналитик использует имеющийся практический опыт для того, чтобы понять, почему факторная модель относит ту или иную переменную к данному конкретному фактору. Бывают случаи (особенно при малом числе хорошо формализованных переменных), когда образованные факторы являются очевидными и различия между переменными видны невооруженным глазом. В такой ситуации можно обойтись без факторного анализа и разбить переменные на группы вручную. Однако эффективность и мощь факторного анализа проявляются в сложных и нетривиальных случаях, когда переменные нельзя заранее классифицировать, а их формулировки запутаны. Тогда большой исследовательский интерес будет вызывать классификация переменных именно на основании мнений респондентов, что позволит выявить то, как сами опрошенные поняли тот или иной вопрос.
Приводим рекомендации, которые помогут вам при затруднении интерпретировать результаты факторного анализа.
Когда это возможно и приемлемо для целей исследования, следует формализовать переменные до проведения факторного анализа. Это позволит аналитику заранее сделать предположения о разделении совокупности имеющихся переменных на группы. Задача исследователя при интерпретации результатов факторной матрицы в данном случае упростится, так как он уже не будет начинать «с чистого листа». Его задача сведется к проверке ранее выдвинутых гипотез о принадлежности той или иной переменной к конкретной группе.
Иногда возникают случаи, когда переменная, отнесенная SPSS к конкретному фактору, логически никак не связана с остальными переменными, составляющими тот же фактор. Можно пересчитать факторную модель без отсечения незначимых коэффициентов (как в примере на рис. 5.40) и посмотреть, с каким еще фактором данная нелогичная переменная коррелирует практически с той же силой, как с фактором, к которому она была отнесена автоматически. Например, переменная Z имеет коэффициент корреляции с фактором 1, равный 0,505, а с фактором 2 она коррелирует с коэффициентом 0,491. SPSS автоматически относит данную переменную к тому фактору, с которым выявлена наибольшая корреляция, не учитывая при этом, что с другим фактором данная переменная коррелирует практически с той же силой. Именно в такой ситуации (при небольшой разнице в коэффициентах корреляции) можно попробовать отнести переменную Z к фактору 2, и если это окажется логичным, рассматривать ее в группе переменных из второго фактора.
Можно вручную сократить число извлекаемых факторов, что облегчит задачу исследователя при интерпретации результатов факторного анализа. Однако необходимо иметь в виду, что такое сокращение снизит гибкость факторной модели и даже может привести к ситуации, когда переменные будут ложно разделены на неверные, с практической точки зрения, группы. Также снижение числа извлекаемых факторов неизбежно снизит и долю однозначно классифицированных факторов.
В качестве варианта предыдущего решения можно предложить объединить два или более факторов с небольшими количествами входящих в них переменных. Такая группировка, с одной стороны, позволит снизить число интерпретируемых факторов, а с другой — облегчит понимание малочисленных факторов.
Если исследователь зашел в тупик и никакие средства не помогают объяснить принадлежность той или иной переменной к конкретному фактору, остается применить другую статистическую процедуру (например, кластерный анализ).
Вернемся к нашим пяти факторам. Задача их описания и объяснения представляется не очень сложной. Так, можно заметить, что утверждения, входящие в первый фактор (q2, q3, q23, ql4, qlO, ql, q21, q5 и ql6), являются общими, то есть касаются всей авиакомпании и описывают отношение к ней со стороны авиапассажиров. Единственное исключение составила переменная q5, имеющая отношение скорее ко второму фактору. Коэффициент корреляции с фактором 2 — 0,355 (см. рис. 5.40), что позволяет отнести его в данную группу из соображений логики. Фактор 2 (ql2, qll, q6, q8, q7 и q4) описывает отношение к авиакомпании X со стороны сотрудников. Третий фактор (ql7, q20 и ql8) описывает отношение респондентов к изменениям в авиакомпании (в него попали все утверждения, имеющие корень «мен» — от слова «изменение»). Четвертый фактор (q9, q22 и q24) описывает отношение респондентов к имиджу авиакомпании. Наконец, пятый фактор (ql9, ql3 и ql5) объединяет утверждения, характеризующие отношение респондентов к визуальному образу авиакомпании X.
Таким образом, мы получили пять групп утверждений, описывающих текущую конкурентную позицию компании X на международном рынке авиаперевозок. На основании проведенного интерпретационного (семантического) анализа можно присвоить данным группам (факторам) следующие определения.
■ Фактор 1 характеризует общее положение авиакомпании X в глазах ее клиентов.
■ Фактор 2 характеризует внутреннее состояние авиакомпании X с точки зрения ее сотрудников.
■ Фактор 3 характеризует изменения, происходящие в авиакомпании X.
■ Фактор 4 характеризует имидж авиакомпании X.
■ Фактор 5 характеризует визуальный образ авиакомпании X.
После того как мы успешно интерпретировали все полученные факторы, можно считать факторный анализ завершенным и удавшимся. Далее мы покажем, как можно использовать результаты факторного анализа для построения разрезов.
Вспомним о том, что мы сохранили факторные рейтинги (то есть принадлежность каждого респондента к определенному фактору) в исходном файле данных в виде новых переменных. Эти переменные имеют имена типа: facX_Y, где X — это номер фактора, a Y — порядковый номер факторной модели. Если мы строили факторную модель дважды и в результате в первый раз было извлечено три фактора, а во второй — два, имена переменных будут следующими:
■ facl_l, fac2_l, fac3_l (для трех факторов из первой построенной модели);
■ facl_2, fac2_2 (для двух факторов из второй модели).
В нашем случае будет создано пять новых переменных (по числу извлеченных факторов). Эти факторные рейтинги в дальнейшем могут использоваться, например, для построения разрезов. Так, если необходимо выяснить, каким образом респонденты — мужчины и женщины — оценивают различные стороны деятельности авиакомпании X, это можно сделать при помощи анализа факторных рейтингов.
Наиболее частый способ использования факторных рейтингов в дальнейших расчетах — это ранжирование и последующее разделение вновь созданных переменных, обозначающих извлеченные факторы, на четыре квартиля (25%-проценти-ля). Такой подход позволяет создать новые переменные с порядковой шкалой, описывающие четыре уровня каждого фактора. В нашем случае для утверждений, составляющих фактор 2, такими уровнями будут: не согласен (состояние внутренних дел компании не удовлетворяет сотрудников), скорее не согласен (оценка внутренней ситуации в компании ниже среднего), скорее согласен (оценка выше среднего), согласен (оценка отлично).
Чтобы создать переменные, по которым далее будут группироваться респонденты, вызовите меню Transform ► Rank Cases. В открывшемся диалоговом окне (рис. 5.41) из левого списка выберите переменную, содержащую факторные рейтинги для фактора 2 (fac2_l), и поместите ее в поле Variables. Далее в области Assign Rank I to выберите пункт Smallest value, в нашем случае это означает, что первую группу (не согласен) составят респонденты, оценивающие состояние внутренних дел авиакомпании как плохое. Соответственно группы 2, 3 и 4 будут определены для категорий скорее не согласен, скорее
 |
согласен и согласен соответственно.
 |
Щелкните на Rank Types ► Types, отмените установленный по умолчанию параметр Rank и вместо него выберите Ntiles с предустановленным числом групп, равным 4 (рис. 5.42). Щелкните на кнопке Continue и затем в главном диалоговом окне на ОК. Данная процедура создаст в файле данных новую переменную nfac2_l (2 означает второй фактор), распределяющую респондентов на четыре группы.
 |
 |
Все респонденты в выборке характеризуются положительным, скорее положительным, скорее отрицательным или отрицательным отношением к текущему состоянию дел в авиакомпании X. Для повышения наглядности рекомендуется присвоить метки каждому из выделенных четырех уровней; можно переименовать и саму переменную. Теперь вы можете проводить перекрестный анализ при помощи новой порядковой переменной, а также строить другие статистические модели, предусмотренные в SPSS. Ниже будет показано, как использовать результаты построения факторной модели в кластерном анализе.
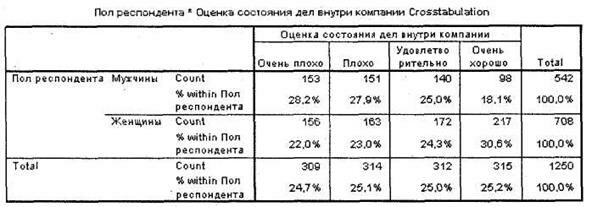
Для иллюстрации возможностей практического использования новой переменной проведем перекрестный анализ влияния пола респондентов на их оценку текущего состояния дел в авиакомпании X (рис. 5.43). Как следует из представленной таблицы, респонденты-мужчины в целом склонны ставить более низкие оценки рассматриваемому параметру авиакомпании по сравнению с женщинами. Так, в структуре оценок очень плохо, плохо и удовлетворительно доля мужчин преобладает; в оценках очень хорошо, напротив, преобладают женщины. При переходе в каждую следующую (более высокую) категорию оценок доля мужчин равномерно убывает, а доля женщин, соответственно, возрастает. Тест %2 показывает, что выявленная зависимость является статистически значимой.
 |
 |
5.2.2. Иерархический кластерный анализ
В статистике существует два основных типа кластерного анализа (оба представлены в SPSS): иерархический и осуществляемый методом k-средних. В первом случае автоматизированная статистическая процедура самостоятельно определяет оптимальное число кластеров и ряд других параметров, необходимых для кластерного
анализа. Второй тип анализа имеет существенные ограничения по практической применимости — для него необходимо самостоятельно определять и точное количество выделяемых кластеров, и начальные значения центров каждого кластера (центроиды), и некоторые другие статистики. При анализе методом k-средних данные проблемы решаются предварительным проведением иерархического кластерного анализа и затем на основании его результатов расчетом кластерной модели по методу k-средних, что в большинстве случаев не только не упрощает, а наоборот, усложняет работу исследователя (в особенности неподготовленного).
В целом можно сказать, что в связи с тем, что иерархический кластерный анализ весьма требователен к аппаратным ресурсам компьютера, кластерный анализ по методу k-средних введен в SPSS для обработки очень больших массивов данных, состоящих из многих тысяч наблюдений (респондентов), в условиях недостаточной мощности компьютерного оборудования1. Размеры выборок, используемых в маркетинговых исследованиях, в большинстве случаев не превышают четыре тысячи респондентов. Практика маркетинговых исследований показывает, что именно первый тип кластерного анализа — иерархический — рекомендуется для использования во всех случаях как наиболее релевантный, универсальный и точный. Вместе с тем необходимо подчеркнуть, что при проведении кластерного анализа важным является отбор релевантных переменных. Данное замечание очень существенно, так как включение в анализ нескольких или даже одной нерелевантной переменной способно привести к неудаче всей статистической процедуры.
Описание методики проведения кластерного анализа мы проведем на следующем примере из практики маркетинговых исследований.
Исходные данные:
В ходе исследования было опрошено 745 авиапассажиров, летавших одной из 22 российских и зарубежных авиакомпаний. Авиапассажиров просили оценить по пятибалльной шкале — от 1 (очень плохо) до 5 (отлично) — семь параметров работы наземного персонала авиакомпаний в процессе регистрации пассажиров на рейс: вежливость, профессионализм, оперативность, готовность помочь, регулирование очереди, внешний вид, работа персонала в целом.
Требуется:
Сегментировать исследуемые авиакомпании по уровню воспринимаемого авиапассажирами качества работы наземного персонала.
Итак, у нас есть файл данных, который состоит из семи интервальных переменных, обозначающих оценки качества работы наземного персонала различных авиакомпаний (ql3-ql9), представленные в единой пятибалльной шкале. Файл данных содержит одновариантную переменную q4, указывающую выбранные респондентами авиакомпании (всего 22 наименования). Проведем кластерный анализ и определим, на какие целевые группы можно разделить данные авиакомпании.
Иерархический кластерный анализ проводится в два этапа. Результат первого этапа — число кластеров (целевых сегментов), на которые следует разделить исследуемую выборку респондентов. Процедура кластерного анализа как таковая не
может самостоятельно определить оптимальное число кластеров. Она может только подсказать искомое число. Поскольку задача определения оптимального числа сегментов является ключевой, она обычно решается на отдельном этапе анализа. На втором этапе производится собственно кластеризация наблюдений по тому числу кластеров, которое было определено в ходе первого этапа анализа. Теперь рассмотрим эти шаги кластерного анализа по порядку.
 |
Процедура кластерного анализа запускается при помощи меню Analyze ► Classify ► Hierarchical Cluster. В открывшемся диалоговом окне из левого списка всех имеющихся в файле данных переменных выберите переменные, являющиеся критериями сегментирования. В нашем случае их семь, и обозначают они оценки параметров работы наземного персонала ql3-ql9 (рис. 5.44). В принципе указания совокупности критериев сегментирования будет вполне достаточно для выполнения первого этапа кластерного анализа.
 |
По умолчанию кроме таблицы с результатами формирования кластеров, на основании которой мы определим их оптимальное число, SPSS выводит также специальную перевернутую гистограмму icicle, помогающую, по замыслу создателей программы, определить оптимальное количество кластеров; вывод диаграмм осуществляется кнопкой Plots (рис. 5.45). Однако если оставить данный параметр установленным, мы потратим много времени на обработку даже сравнительно небольшого файла данных. Кроме icicle в окне Plots можно выбрать более быструю линейчатую диаграмму Dendogram. Она представляет собой горизонтальные столбики, отражающие процесс формирования кластеров. Теоретически при небольшом (до 50-100) количестве респондентов данная диаграмма действительно помогает выбрать оптимальное решение относительно требуемого числа кластеров. Однако практически во всех примерах из маркетинговых исследований размер выборки превышает это значение. Дендограмма становится совершенно бесполезной, так как даже при относительно небольшом числе наблюдений представляет собой очень длинную последовательность номеров строк исходного файла данных, соединенных между собой горизонтальными и вертикальными линиями. Большинство учебников по SPSS содержат примеры кластерного анализа именно на таких искусственных, малых выборках. В настоящем пособии мы показываем, как наиболее эффективно работать с SPSS в практических условиях и на примере реальных маркетинговых исследований.
 |
 |
Как мы установили, для практических целей ни Icicle, ни Dendogram не пригодны. Поэтому в главном диалоговом окне Hierarchical Cluster Analysis рекомендуется не выводить диаграммы, отменив выбранный по умолчанию параметр Plots в области Display, как показано на рис. 5.44. Теперь все готово для выполнения первого этапа кластерного анализа. Запустите процедуру, щелкнув на кнопке ОК.
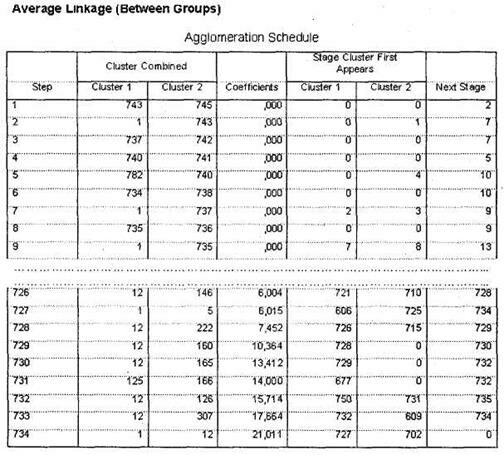
Через некоторое время в окне SPSS Viewer появятся результаты. Как было сказано выше, единственным значимым для нас итогом первого этапа анализа будет таблица Average Linkage (Between Groups), представленная на рис. 5.46. На основании этой таблицы мы должны определить оптимальное число кластеров. Необходимо заметить, что единого универсального метода определения оптимального числа кластеров не существует. В каждом конкретном случае исследователь должен сам определить это число.
Исходя из имеющегося опыта, автор предлагает следующую схему данного процесса. Прежде всего, попробуем применить наиболее распространенный стандартный метод для определения числа кластеров. По таблице Average Linkage (Between Groups) следует определить, на каком шаге процесса формирования кластеров (колонка Stage) происходит первый сравнительно большой скачок коэффициента агломерации (колонка Coefficients). Данный скачок означает, что до него в кластеры объединялись наблюдения, находящиеся на достаточно малых расстояниях друг от друга (в нашем случае респонденты со схожим уровнем оценок по анализируемым параметрам), а начиная с этого этапа происходит объединение более далеких наблюдений.
В нашем случае коэффициенты плавно возрастают от 0 до 7,452, то есть разница между коэффициентами на шагах с первого по 728 была мала (например, между 728 и 727 шагами — 0,534). Начиная с 729 шага происходит первый существенный скачок коэффициента: с 7,452 до 10,364 (на 2,912). Шаг, на котором происходит первый скачок коэффициента, — 729. Теперь, чтобы определить оптимальное ко-
личество кластеров, необходимо вычесть полученное значение из общего числа наблюдений (размера выборки). Общий размер выборки в нашем случае составляет 745 человек; следовательно, оптимальное количество кластеров составляет 745-729 = 16.
 |
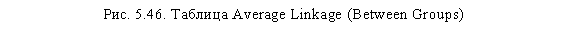 |
Мы получили достаточно большое число кластеров, которое в дальнейшем будет сложно интерпретировать. Поэтому теперь следует исследовать полученные кластеры и определить, какие из них являются значимыми, а какие нужно попытаться сократить. Данная задача решается на втором этапе кластерного анализа.
Откройте главное диалоговое окно процедуры кластерного анализа (меню Analyze ► Classify ► Hierarchical Cluster). В поле для анализируемых переменных у нас уже есть семь параметров. Щелкните на кнопке Save. Открывшееся диалоговое окно (рис. 5.47) позволяет создать в исходном файле данных новую переменную, распределяющую респондентов на целевые группы. Выберите параметр Single Solution и укажите в соответствующем поле необходимое количество кластеров — 16 (определено на первом этапе кластерного анализа). Щелкнув на кнопке Continue, вернитесь в главное диалоговое окно, в котором щелкните на кнопке ОК, чтобы запустить процедуру кластерного анализа.
Прежде чем продолжить описание процесса кластерного анализа, необходимо привести краткое описание других параметров. Среди них есть как полезные возможности, так и фактически лишние (с точки зрения практических маркетинговых исследований). Так, например, главное диалоговое окно Hierarchial Cluster Analysis содержит поле Label Cases by, в которое при желании можно поместить текстовую переменную, идентифицирующую респондентов. В нашем случае для этих целей может служить переменная q4, кодирующая выбранные респондентами авиакомпании. На практике сложно придумать рациональное объяснение использованию поля Label Cases by, поэтому можно спокойно всегда оставлять его пустым.
 |
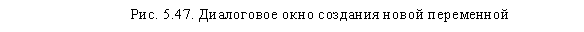
Нечасто при проведении кластерного анализа используется диалоговое окно Statistics, вызываемое одноименной кнопкой в главном диалоговом окне. Оно позволяет организовать вывод в окне SPSS Viewer таблицы Cluster Membership, в которой каждому респонденту в исходном файле данных сопоставляется номер кластера. Данная таблица при достаточно большом количестве респондентов (практически во всех примерах маркетинговых исследований) становится совершенно бесполезной, так как представляет собой длинную последовательность пар значений «номер респондента/номер кластера», в таком виде не поддающуюся интерпретации. Технически цель кластерного анализа всегда состоит в образовании в файле данных дополнительной переменной, отражающей разделение респондентов на целевые группы (при помощи щелчка на кнопке Save в главном диалоговом окне кластерного анализа). Эта переменная в совокупности с номерами респондентов и есть таблица Cluster Membership. Единственный практически полезный параметр в окне Statistics — вывод таблицы Average Linkage (Between Groups), однако он уже установлен по умолчанию. Таким образом, использование кнопки Statistics и вывод отдельной таблицы Cluster Membership в окне SPSS Viewer является нецелесообразным.
Про кнопку Plots уже было сказано выше: ее следует дезактивизировать, отменив параметр Plots в главном диалоговом окне кластерного анализа.
Кроме этих редко используемых возможностей процедуры кластерного анализа, SPSS предлагает и весьма полезные параметры. Среди них прежде всего кнопка Save, позволяющая создать в исходном файле данных новую переменную, распределяющую респондентов по кластерам. Также в главном диалоговом окне существует область для выбора объекта кластеризации: респондентов или переменных. Об этой возможности говорилось выше в разделе 5.4. В первом случае кластерный анализ используется в основном для сегментирования респондентов по некоторым критериям; во втором цель проведения кластерного анализа аналогична факторному анализу: классификация (сокращение числа) переменных.
Как видно из рис. 5.44, единственной не рассмотренной возможностью кластерного анализа является кнопка выбора метода проведения статистической процедуры Method. Эксперименты с данным Параметром позволяют добиться большей точности при определении оптимального числа кластеров. Общий вид этого диалогового окна с параметрами, установленными по умолчанию, представлен на рис. 5.48.

 |
Первое, что устанавливается в данном окне, — это метод формирования кластеров (то есть объединения наблюдений). Среди всех возможных вариантов статистических методик, предлагаемых SPSS, следует выбирать либо установленный по умолчанию метод Between-groups linkage, либо процедуру Ward (Ward's method). Первый метод используется чаще ввиду его универсальности и относительной простоты статистической процедуры, на которой он основан. При использовании этого метода расстояние между кластерами вычисляется как среднее значение расстояний между всеми возможными парами наблюдений, причем в каждой итерации принимает участие одно наблюдение из одного кластера, а второе — из другого. Информация, необходимая для расчетов расстояния между наблюдениями, находится на основании всех теоретически возможных пар наблюдений. Метод Ward более сложен для понимания и используется реже. Он состоит из множества этапов и основан на усреднении значений всех переменных для каждого наблюдения и последующем суммировании квадратов расстояний от вычисленных средних до каждого наблюдения. Для решения практических задач маркетинговых исследований мы рекомендуем всегда использовать метод Between-groups linkage, установленный по умолчанию.
После выбора статистической процедуры кластеризации следует выбрать метод для вычисления расстояний между наблюдениями (область Measure в диалоговом окне Method). Существуют различные методы определения расстояний для трех типов переменных, участвующих в кластерном анализе (критериев сегментирования). Эти переменные могут иметь интервальную (Interval), номинальную (Counts) или дихотомическую (Binary) шкалу. Дихотомическая шкала (Binary) подразумевает только переменные, отражающие наступление/ненаступление какого-либо события (купил/не купил, да/нет и т. д.). Другие типы дихотомических переменных (например, мужчина/женщина) следует рассматривать и анализировать как номинальные (Counts).
Наиболее часто используемым методом определения расстояний для интервальных переменных является квадрат евклидова расстояния (Squared Euclidean Distance), устанавливаемый по умолчанию. Именно этот метод зарекомендовал себя в маркетинговых исследованиях как наиболее точный и универсальный. Однако для дихотомических переменных, где наблюдения представлены только двумя значениями (например, 0 и 1), данный метод не подходит. Дело в том, что он учитывает только взаимодействия между наблюдениями типа: X = 1,Y = 0 и X = 0, Y=l (где X и Y — переменные) и не учитывает другие типы взаимодействий. Наиболее комплексной мерой расстояния, учитывающей все важные типы взаимодействий между двумя дихотомическими переменными, является метод Лямбда (Lambda). Мы рекомендуем применять именно данный метод ввиду его универсальности. Однако существуют и другие методы, например Shape, Hamann или Anderbergs's D.
При указании метода определения расстояний для дихотомических переменных в соответствующем поле необходимо указать конкретные значения, которые могут принимать исследуемые дихотомические переменные: в поле Present — кодировку ответа Да, а в поле Absent — Нет. Названия полей присутствует и отсутствует ассоциированы с тем, что в группе методов Binary предполагается использовать только дихотомические переменные, отражающие наступление/ненаступление какого-либо события. Для двух типов переменных Interval и Binary существует несколько методов определения расстояния. Для переменных с номинальным типом шкалы SPSS предлагает всего два метода:  (Chi-square measure) и
(Chi-square measure) и  (Phi-square measure). Мы рекомендуем использовать первый метод как наиболее распространенный.
(Phi-square measure). Мы рекомендуем использовать первый метод как наиболее распространенный.
В диалоговом окне Method есть область Transform Values, в которой находится поле Standardize. Данное поле применяется в том случае, когда в кластерном анализе принимают участие переменные с различным типом шкалы (например, интервальные и номинальные). Для того чтобы использовать эти переменные в кластерном анализе, следует провести стандартизацию, приводящую их к единому типу шкалы — интервальному. Самым распространенным методом стандартизации переменных является 2-стандартизация (Zscores): все переменные приводятся к единому диапазону значений от -3 до +3 и после преобразования являются интервальными.
Так как все оптимальные методы (кластеризации и определения расстояний) установлены по умолчанию, целесообразно использовать диалоговое окно Method только для указания типа анализируемых переменных, а также для указания необходимости произвести 2-стандартизацию переменных.
Итак, мы описали все основные возможности, предоставляемые SPSS для проведения кластерного анализа. Вернемся к описанию кластерного анализа, проводимого с целью сегментирования авиакомпаний. Напомним, что мы остановились на шестнадцатикластерном решении и создали в исходном файле данных новую переменную clul6_l, распределяющую все анализируемые авиакомпании по кластерам.
Чтобы установить, насколько верно мы определили оптимальное число кластеров, построим линейное распределение переменной clul6_l (меню Analyze ► Descriptive Statistics ► Frequencies). Как видно на рис. 5.49, в кластерах с номерами 5-16 число респондентов составляет от 1 до 7. Наряду с вышеописанным универсальным методом определения оптимального количества кластеров (на основании разности между общим числом респондентов и первым скачком коэффициента агломерации) существует также дополнительная рекомендация: размер кластеров должен быть статистически значимым и практически приемлемым. При нашем размере выборки такое критическое значение можно установить хотя бы на уровне 10. Мы видим, что под данное условие попадают лишь кластеры с номерами 1-4. Поэтому
теперь необходимо пересчитать процедуру кластерного анализа с выводом четы-рехкластерного решения (будет создана новая переменная du4_l).

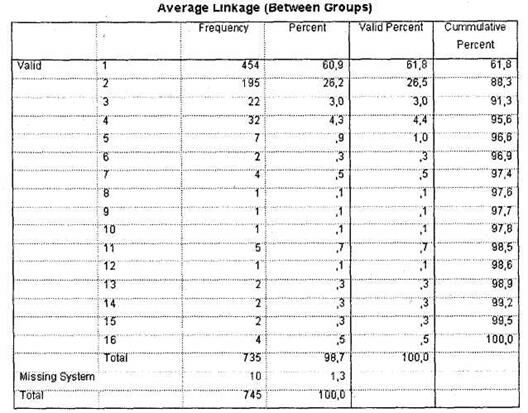 |
Построив линейное распределение по вновь созданной переменной du4_l, мы увидим, что только в двух кластерах (1 и 2) число респондентов является практически значимым. Нам необходимо снова перестроить кластерную модель — теперь для двухкластерного решения. После этого построим распределение по переменной du2_l (рис. 5.50). Как вы видите из таблицы, двухкластерное решение имеет статистически и практически значимое число респондентов в каждом из двух сформированных кластеров: в кластере 1 — 695 респондентов; в кластере 2 — 40. Итак, мы определили оптимальное число кластеров для нашей задачи и провели собственно сегментирование респондентов по семи избранным критериям. Теперь можно считать основную цель нашей задачи достигнутой и приступать к завершающему этапу кластерного анализа — интерпретации полученных целевых групп (сегментов).
 |
 |
Полученное решение несколько отличается от тех, которые вы, может быть, видели в учебных пособиях по SPSS. Даже в наиболее практически ориентированных учебниках приведены искусственные примеры, где в результате кластеризации получаются идеальные целевые группы респондентов. В некоторых случаях (5) авторы даже прямо указывают на искусственное происхождение примеров. В настоящем пособии мы применим в качестве иллюстрации действия кластерного анализа реальный пример из практического маркетингового исследования, не отличающийся идеальными пропорциями. Это позволит нам показать наиболее распространенные трудности проведения кластерного анализа, а также оптимальные методы их устранения.
Перед тем как приступить к интерпретации полученных кластеров, давайте подведем итоги. У нас получилась следующая схема определения оптимального числа кластеров.
■ На этапе 1 мы определяем количество кластеров на основании математического метода, основанного на коэффициенте агломерации.
■ На этапе 2 мы проводим кластеризацию респондентов по полученному числу кластеров и затем строим линейное распределение по образованной новой переменной (clul6_l). Здесь также следует определить, сколько кластеров состоят из статистически значимого количества респондентов. В общем случае рекомендуется устанавливать минимально значимую численность кластеров на уровне не менее 10 респондентов.
■ Если все кластеры удовлетворяют данному критерию, переходим к завершающему этапу кластерного анализа: интерпретации кластеров. Если есть кластеры с незначимым числом составляющих их наблюдений, устанавливаем, сколько кластеров состоят из значимого количества респондентов.
■ Пересчитываем процедуру кластерного анализа, указав в диалоговом окне Save число кластеров, состоящих из значимого количества наблюдений.
■ Строим линейное распределение по новой переменной.
Такая последовательность действий повторяется до тех пор, пока не будет найдено решение, в котором все кластеры будут состоять из статистически значимого числа респондентов. После этого можно переходить к завершающему этапу кластерного анализа — интерпретации кластеров.
Необходимо особо отметить, что критерий практической и статистической значимости численности кластеров не является единственным критерием, по которому можно определить оптимальное число кластеров. Исследователь может самостоятельно, на основании имеющегося у него опыта предложить число кластеров (условие значимости должно удовлетворяться). Другим вариантом является довольно распространенная ситуация, когда в целях исследования заранее ставится условие сегментировать респондентов по заданному числу целевых групп. В этом случае необходимо просто один раз провести иерархический кластерный анализ с сохранением требуемого числа кластеров и затем пытаться интерпретировать то, что получится.
Для того чтобы описать полученные целевые сегменты, следует воспользоваться процедурой сравнения средних значений исследуемых переменных (кластерных центроидов). Мы сравним средние значения семи рассматриваемых критериев сегментирования в каждом из двух полученных кластеров.
Процедура сравнения средних значений вызывается при помощи меню Analyze ► Compare Means ► Means. В открывшемся диалоговом окне (рис. 5.51) из левого списка выберите семь переменных, избранных в качестве критериев сегментирования (ql3-ql9), и перенесите их в поле для зависимых переменных Dependent List. Затем переменную сШ2_1, отражающую разделение респондентов на кластеры при окончательном (двухкластерном) решении задачи, переместите из левого списка в поле для независимых переменных Independent List. После этого щелкните на кнопке Options.

 |
 |
Откроется диалоговое окно Options, выберите в нем необходимые статистики для сравнения кластеров (рис. 5.52). Для этого в поле Cell Statistics оставьте только вывод средних значений Mean, удалив из него другие установленные по умолчанию статистики. Закройте диалоговое окно Options щелчком на кнопке Continue. Наконец, из главного диалогового окна Means запустите процедуру сравнения средних значений (кнопка ОК).
 |
В открывшемся окне SPSS Viewer появятся результаты работы статистической процедуры сравнения средних значений. Нас интересует таблица Report (рис. 5.53). Из нее можно увидеть, на каком основании SPSS разделила респондентов на два кластера. Таким критерием в нашем случае служит уровень оценок по анализируемым параметрам. Кластер 1 состоит из респондентов, для которых средние оценки по всем критериям сегментирования находятся на сравнительно высоком уровне (4,40 балла и выше). Кластер 2 включает респондентов, оценивших рассматриваемые критерии сегментирования достаточно низко (3,35 балла и ниже). Таким образом, можно сделать вывод о том, что 93,3 % респондентов, сформировавшие кластер 1, оценили анализируемые авиакомпании по всем параметрам в целом хорошо; 5,4 % — достаточно низко; 1,3 % — затруднились ответить (см. рис. 5.50). Из рис. 5.53 можно также сделать вывод о том, какой уровень оценок для каждого из рассматриваемых параметров в отдельности является высоким, а какой — низким (причем данный вывод будет сделан со стороны респондентов, что позволяет добиться высокой точности классификации). Из таблицы Report можно видеть, что для переменной Регулирование очереди высоким считается уровень средней оценки 4,40, а для параметра Внешний вид — 4.72.
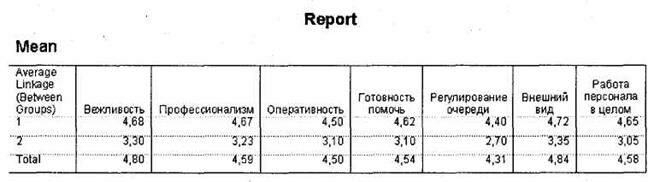
 |
Может оказаться, что в аналогичном случае по параметру X высокой оценкой считается 4,5, а по параметру Y — только 3,9. Это не будет ошибкой кластеризации, а напротив, позволит сделать важный вывод относительно значимости для респондентов рассматриваемых параметров. Так, для параметра Y уже 3,9 балла является хорошей оценкой, тогда как к параметру X респонденты предъявляют более строгие требования.
Мы идентифицировали два значимых кластера, различающиеся по уровню средних оценок по критериям сегментирования. Теперь можно присвоить метки полученным кластерам: для 1 — Авиакомпании, удовлетворяющие требованиям респондентов (по семи анализируемым критериям); для 2 — Авиакомпании, не удовлетворяющие требованиям респондентов. Теперь можно посмотреть, какие конкретно авиакомпании (закодированные в переменной q4) удовлетворяют требованиям респондентов, а какие — нет по критериям сегментирования. Для этого следует построить перекрестное распределение переменной q4 (анализируемые авиакомпании) в зависимости от кластеризующей переменной clu2_l. Результаты такого перекрестного анализа представлены на рис. 5.54.

 |
По этой таблице можно сделать следующие выводы относительно членства исследуемых авиакомпаний в выделенных целевых сегментах.
1. Авиакомпании, полностью удовлетворяющие требованиям всех клиентов по параметру работы наземного персонала (входят только в один первый кластер):
■ Внуковские авиалинии;
■ American Airlines;
■ Continental;
■ Delta Airlines;
■ Air France;
■ Alitalia;
■ Austrian Airlines;
■ British Airways;
■ Swiss Air;
■ KLM;
■ Lufthansa;
■ SAS;
■ Korean Airlines;
■ Japan Airlines.
2. Авиакомпании, удовлетворяющие требованиям большинства своих клиентов по параметру работы наземного персонала (большая часть респондентов, летающих данными авиакомпаниями, удовлетворены работой наземного персонала):
■ Трансаэро.
3. Авиакомпании, не удовлетворяющие требованиям большинства своих клиентов по параметру работы наземного персонала (большая часть респондентов, летающих данными авиакомпаниями, не удовлетворены работой наземного персонала):
■ Домодедовские авиалинии;
■ Пулково;
■ Сибирь;
■ Уральские авиалинии;
■ Самарские авиалинии;
■ KrasAir;
■ Finnair.
Таким образом, получено три целевых сегмента авиакомпаний по уровню средних оценок, характеризующиеся различной степенью удовлетворенности респондентов работой наземного персонала:
1. наиболее привлекательные для пассажиров авиакомпании по уровню работы наземного персонала (14);
2. скорее привлекательные авиакомпании (1);
3. скорее непривлекательные авиакомпании (7).
Мы успешно завершили все этапы кластерного анализа и сегментировали авиакомпании по семи выделенным критериям.
Теперь приведем описание методики кластерного анализа в паре с факторным. Используем условие задачи из раздела 5.2.1 (факторный анализ). Как уже было сказано, в задачах сегментирования при большом числе переменных целесообразно предварять кластерный анализ факторным. Это делается для сокращения количества критериев сегментирования до наиболее значимых. В нашем случае в исходном файле данных у нас есть 24 переменные. В результате факторного анализа нам удалось сократить их число до 5. Теперь это число факторов может эффективно применяться для кластерного анализа, а сами факторы — использоваться в качестве критериев сегментирования.
Если перед нами стоит задача сегментировать респондентов по их оценке различных аспектов текущей конкурентной позиции авиакомпании X, можно провести иерархический кластерный анализ по выделенным пяти критериям (переменные nfacl_l-nfac5_l). В нашем случае переменные оценивались по разным шкалам. Например, оценка 1 для утверждения Я бы не хотел, чтобы авиакомпания менялась и такая же оценка утверждению Изменения в авиакомпании будут позитивным моментом диаметрально противоположны по смыслу. В первом случае 1 балл (совершенно не согласен) означает, что респондент приветствует изменения в авиакомпании; во втором случае оценка в 1 балл свидетельствует о том, что респондент отвергает изменения в авиакомпании. При интерпретации кластеров у нас неизбежно возникнут трудности, так как такие противоположные по смыслу переменные могут
попасть в один и тот же фактор. Таким образом, для целей сегментирования рекомендуется сначала привести в соответствие шкалы исследуемых переменных, а затем пересчитать факторную модель. И уже далее проводить кластерный анализ над полученными в результате факторного анализа переменными-факторами. Мы не будем снова подробно описывать процедуры факторного и кластерного анализа (это было сделано выше в соответствующих разделах). Отметим лишь, что при такой методике в результате у нас получилось три целевые группы авиапассажиров, различающихся по уровню оценок выделенным факторам (то есть группам переменных): низшая, средняя и высшая.
Весьма полезным применением кластерного анализа является разделение на группы частотных таблиц. Предположим, у нас есть линейное распределение ответов на вопрос Какие марки антивирусов установлены в Вашей организации?. Для формирования выводов по данному распределению необходимо разделить марки антивирусов на несколько групп (обычно 2-3). Чтобы разделить все марки на три группы (наиболее популярные марки, средняя популярность и непопулярные марки), лучше всего воспользоваться кластерным анализом, хотя, как правило, исследователи разделяют элементы частотных таблиц на глаз, основываясь на субъективных соображениях. В противоположность такому подходу кластерный анализ позволяет научно обосновать выполненную группировку. Для этого следует ввести значения каждого параметра в SPSS (эти значения целесообразно выражать в процентах) и затем выполнить кластерный анализ для этих данных. Сохранив кластерное решение для необходимого количества групп (в нашем случае 3) в виде новой переменной, мы получим статистически обоснованную группировку.
Заключительную часть этого раздела мы посвятим описанию применения кластерного анализа для классификации переменных и сравнения его результатов с результатами факторного анализа, проведенного в разделе 5.2.1. Для этого мы вновь воспользуемся условием задачи про оценку текущей позиции авиакомпании X на рынке авиаперевозок. Методика проведения кластерного анализа практически полностью повторяет описанную выше (когда сегментировались респонденты).
Итак, в исходном файле данных у нас есть 24 переменные, описывающие отношение респондентов к различным аспектам текущей конкурентной позиции авиакомпании X. Откройте главное диалоговое окно Hierarchical Cluster Analysis и поместите 24 переменные (ql-q24) в поле Variable(s), рис. 5.55. В области Cluster укажите, что вы классифицируете переменные (отметьте параметр Variables). Вы увидите, что кнопка Save стала недоступна — в отличие от факторного, в кластерном анализе нельзя сохранить факторные рейтинги для всех респондентов. Откажитесь от вывода диаграмм, дезактивизировав параметр Plots. На первом этапе вам не нужны другие параметры, поэтому просто щелкните на кнопке О К, чтобы запустить процедуру кластерного анализа.
В окне SPSS Viewer появилась таблица Agglomeration Schedule, по которой мы определили оптимальное число кластеров описанным выше методом (рис. 5.56). Первый скачок коэффициента агломерации наблюдается на 20 шаге (с 18834,000 до 21980,967). Исходя из общего числа анализируемых переменных, равного 24, можно вычислить оптимальное число кластеров: 24 - 20 = 4.
 |
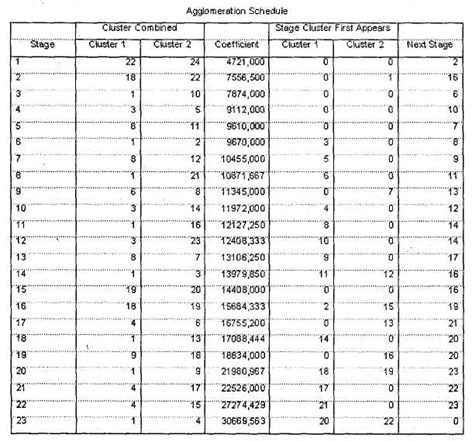 |
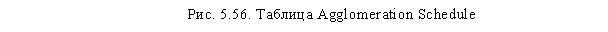 |
При классификации переменных практически и статистически значимым является кластер, состоящий всего из одной переменной. Поэтому, поскольку мы получили приемлемое число кластеров математическим методом, проведение дальнейших проверок не требуется. Вместо этого снова откройте главное диалоговое окно кластерного анализа (все данные, использованные на предыдущем этапе, сохранились) и щелкните на кнопке Statistics, чтобы организовать вывод классификационной таблицы. Вы увидите одноименное диалоговое окно, где необходимо указать число кластеров, на которое необходимо разделить 24 переменные (рис. 5.57). Для этого выберите параметр Single solution и в соответствующем поле укажите требуемое число кластеров: 4. Теперь закройте диалоговое окно Statistics щелчком на кнопке Continue и из главного окна кластерного анализа запустите
 |
процедуру на выполнение.
 |
В результате в окне SPSS Viewer появится таблица Cluster Membership, распределяющая анализируемые переменные на четыре кластера (рис. 5.58).

 |
По данной таблице можно отнести каждую рассматриваемую переменную в определенный кластер следующим образом.
Кластер 1
ql. Авиакомпания X обладает репутацией компании, превосходно обслуживающей пассажиров.
q2. Авиакомпания X может конкурировать с лучшими авиакомпаниями мира.
q3. Я верю, что у авиакомпании X есть перспективное будущее в мировой авиации.
q5. Я горжусь тем, что работаю в авиакомпании X.
q9. Нам предстоит долгий путь, прежде чем мы сможем претендовать на то, чтобы называться авиакомпанией мирового класса.
qlO. Авиакомпания X действительно заботится о пассажирах.
ql3. Мне нравится, как в настоящее время авиакомпания X представлена визуально широкой общественности (в плане цветовой гаммы и фирменного стиля).
ql4. Авиакомпания X — лицо России.
ql6. Обслуживание авиакомпании X является последовательным и узнаваемым во всем
мире.
ql8. Авиакомпании X необходимо меняться для того, чтобы использовать в полной мере имеющийся потенциал.
ql9. Я думаю, что авиакомпании X необходимо представить себя в визуальном плане более современно.
q20. Изменения в авиакомпании X будут позитивным моментом. q21. Авиакомпания X — эффективная авиакомпания.
q22. Я бы хотел, чтобы имидж авиакомпании X улучшился с точки зрения иностранных пассажиров.
q23. Авиакомпания X — лучше, чем многие о ней думают.
q24. Важно, чтобы люди во всем мире знали, что мы — российская авиакомпания.
Кластер 2
q4. Я знаю, какой будет стратегия развития авиакомпании X в будущем.
q6. В авиакомпании X хорошее взаимодействие между подразделениями.
q7. Каждый сотрудник авиакомпании прикладывает все усилия для того, чтобы обеспечить ее успех.
q8. Сейчас авиакомпания X быстро улучшается.
qll. Среди сотрудников авиакомпании имеет место высокая степень удовлетворенности работой.
ql2. Я верю, что менеджеры высшего звена прикладывают все усилия для достижения успеха авиакомпании.
Кластер 3
Лекция "6 Открытие наследства" также может быть Вам полезна.
ql5. Мы выглядим «вчерашним днем» по сравнению с другими авиакомпаниями.
Кластер 4
ql7. Я бы не хотел, чтобы авиакомпания X менялась.
Сравнив результаты факторного (раздел 5.2.1) и кластерного анализов, вы увидите, что они существенно различаются. Кластерный анализ не только предоставляет существенно меньшие возможности для кластеризации переменных (например, отсутствие возможности сохранять групповые рейтинги) по сравнению с факторным анализом, но и выдает гораздо менее наглядные результаты. В нашем случае, если кластеры 2, 3 и 4 еще поддаются логической интерпретации1, то кластер 1 содержит совершенно разные по смыслу утверждения. В данной ситуации можно либо попытаться описать кластер 1 как есть, либо перестроить статистическую модель с другим числом кластеров. В последнем случае для поиска оптимального числа кластеров, поддающихся логическому описанию, можно воспользоваться параметром Range of solutions в диалоговом окне Statistics (см. рис. 5.57), указав в соответствующих полях минимальное и максимальное число кластеров (в нашем случае 4 и 6 соответственно). В такой ситуации SPSS перестроит таблицу Cluster Membership для каждого числа кластеров. Задача аналитика в данном случае — попытаться подобрать такую классификационную модель, при которой все кластеры будут интерпретироваться однозначно. С целью демонстрации возможностей процедуры кластерного анализа для кластеризации переменных мы не будем перестраивать кластерную модель, а ограничимся лишь сказанным выше.
Необходимо отметить, что, несмотря на кажущуюся простоту проведения кластерного анализа по сравнению с факторным, практически во всех случаях из маркетинговых исследований факторный анализ оказывается быстрее и эффективнее кластерного. Поэтому для классификации (сокращения) переменных мы настоятельно рекомендуем использовать именно факторный анализ и оставить применение кластерного анализа для классификации респондентов.
Классификационный анализ является, пожалуй, одним из наиболее сложных, с точки зрения неподготовленного пользователя, статистических инструментов. С этим связана его весьма малая распространенность в маркетинговых компаниях. Вместе с тем именно данная группа статистических методов является и одной из наиболее полезных для практиков в области маркетинговых исследований.


















