
Теория статистических решений
Тема 9. Теория статистических решений
1. Теория статистических решений
Теория статистических решений - это математическая теория принятия решений в условиях неопределённости в тех случаях, когда характер неопределённости может быть описан вероятностной моделью. Часто к теории статистических решений относят лишь динамические модели. Если распределение вероятностей исходных данных полностью известно, теория статистических решений, по существу, смыкается с теорией стохастической оптимизации. Специфические и глубокие проблемы возникают в ситуациях, когда указанное распределение вероятностей известно не полностью, например, задано с точностью до неизвестного параметра, вообще говоря, произвольной природы. Формальная схема восходит к работе американского математика А. Вальда и состоит из следующих элементов.
1. Конечный или бесконечный случайный вектор наблюдений Х= (Х,,Х2,...). (Более строго, X - измеримое отображение, определенное на некотором исходном измеримом пространстве элементарных событий.)
2. Семейство  возможных распределений вероятностей вектора наблюдений X. Как правило, полагают
возможных распределений вероятностей вектора наблюдений X. Как правило, полагают  , где
, где  - неизвестный параметр, вообще говоря, произвольной природы;
- неизвестный параметр, вообще говоря, произвольной природы;  - множеству возможных значений параметра.
- множеству возможных значений параметра.
3. Пространство возможных решений D = {d). Так, если = {0,1} (неизвестный параметр = 0 или 1), и задача состоит в различении двух гипотез:  ={истинное значение = 0} и
={истинное значение = 0} и  = {истинное значение = 1}, то естественно положить D = {0, 1}, считая, что решение d = 0 (1) соответствует принятию ().
= {истинное значение = 1}, то естественно положить D = {0, 1}, считая, что решение d = 0 (1) соответствует принятию ().
4. Решающая функция или статистика  , принимающая значения в пространстве решений
, принимающая значения в пространстве решений  , т. е. правило соответствия между значением вектора наблюдений и принимаемым решением.
, т. е. правило соответствия между значением вектора наблюдений и принимаемым решением.
Задача состоит в определении понятия «хорошей» решающей функции и её поиске. Как правило, для этого вводится дополнительный элемент схемы:
5) Функция потерь  - потери при решении
- потери при решении  и истинном значении неизвестного параметра . Единица измерения потерь и сама функция
и истинном значении неизвестного параметра . Единица измерения потерь и сама функция  определяются спецификой конкретной задачи. Например, в задаче оценивания одномерного параметра , когда решение d суть оценка , часто полагают
определяются спецификой конкретной задачи. Например, в задаче оценивания одномерного параметра , когда решение d суть оценка , часто полагают  (квадратичные потери). Могут быть задачи, где вместо потерь рассматривается «доход», возможны обобщения понятия потерь - вектор потерь и т. п.
(квадратичные потери). Могут быть задачи, где вместо потерь рассматривается «доход», возможны обобщения понятия потерь - вектор потерь и т. п.
Рекомендуемые материалы
Если принимаемое решение  , то потери суть случайная величина
, то потери суть случайная величина  , и нужно выбрать решающую функцию Т, порождающую наиболее «устраивающее» распределение вероятностей случайной величины . Иначе, мы должны установить отношение предпочтения на множестве возможных распределений указанной случайной величины. Наиболее распространённый путь - минимизировать средние потери
, и нужно выбрать решающую функцию Т, порождающую наиболее «устраивающее» распределение вероятностей случайной величины . Иначе, мы должны установить отношение предпочтения на множестве возможных распределений указанной случайной величины. Наиболее распространённый путь - минимизировать средние потери  , где
, где  - операция вычисления математического ожидания в случае, когда неизвестный параметр равен . Например, при различении двух гипотез, как правило, считают
- операция вычисления математического ожидания в случае, когда неизвестный параметр равен . Например, при различении двух гипотез, как правило, считают  , если
, если  , и
, и  , если
, если  . В этом случае
. В этом случае  , то есть вероятности принять неверное решение. Называемая функцией риска или просто риском характеристика
, то есть вероятности принять неверное решение. Называемая функцией риска или просто риском характеристика  суть функция по отношению к и функционал по отношению к решающей функции
суть функция по отношению к и функционал по отношению к решающей функции  .
.
Особенностью теории статистических решений является тот факт, что непосредственная минимизация по Т бессмысленна, так как в нетривиальных случаях минимум достигается на решающей функции, зависящей от параметра , который неизвестен. Рассмотрим несколько вариантов преодоления указанной принципиальной трудности.
Первый состоит в уточнении и обогащении самого принципа оптимальности. Говорят, что решающая функция  (
( «лучше» ), если
«лучше» ), если  для всех , и хотя бы в одном случае неравенство строго. Решающая функция Парето - оптимальна или допустима, если не существует решающей функции лучше её. Ясно, что класс рассматриваемых решающих функций можно сузить до класса Парето - оптимальных решающих функций, но, как правило, последний ещё достаточно широк. Выбор из этого класса одного представителя должен определяться дополнительными соображениями.
для всех , и хотя бы в одном случае неравенство строго. Решающая функция Парето - оптимальна или допустима, если не существует решающей функции лучше её. Ясно, что класс рассматриваемых решающих функций можно сузить до класса Парето - оптимальных решающих функций, но, как правило, последний ещё достаточно широк. Выбор из этого класса одного представителя должен определяться дополнительными соображениями.
Один из наиболее распространённых подходов основан на принципе минимакса и состоит в минимизации максимального по отношению к риска, точнее, к минимизации  . Минимаксный подход правомерен при «равной значимости» потерь при разных значениях неизвестного параметра. В иных случаях нужны другие подходы. Так, если = {0, 1}, часто экзогенно вводится значение максимально допустимых потерь
. Минимаксный подход правомерен при «равной значимости» потерь при разных значениях неизвестного параметра. В иных случаях нужны другие подходы. Так, если = {0, 1}, часто экзогенно вводится значение максимально допустимых потерь  при
при  , т. е. вводится условие
, т. е. вводится условие  , и уже при этом условии минимизируется
, и уже при этом условии минимизируется  (подход Неймана —Пирсона). В такой постановке к потерям при = 0 «отношение более осторожное», чем при =1. Возможны и иные подходы, например, минимизация функционала
(подход Неймана —Пирсона). В такой постановке к потерям при = 0 «отношение более осторожное», чем при =1. Возможны и иные подходы, например, минимизация функционала  , где
, где  - суть веса, и т. п.
- суть веса, и т. п.
Второй путь сводится к сужению класса рассматриваемых решающих функций, т. е. к рассмотрению лишь тех из них, которые обладают дополнительными «естественными» свойствами, определяемыми спецификой конкретной задачи. Например, если в задаче оценивания - параметр сдвига, то есть наблюдения  , где случайные величины
, где случайные величины  имеют одно и то же распределение, не зависящее от , естественно использовать принцип эквивариантности, предписывающий рассматривать лишь те решающие функции , для которых
имеют одно и то же распределение, не зависящее от , естественно использовать принцип эквивариантности, предписывающий рассматривать лишь те решающие функции , для которых
 .
.
Если , минимизация риска уже осмыслена, так как минимум достигается на решающей функции, не зависящей от . То же верно, если — параметр масштаба, то есть  , и рассматриваются решающие функции , для которых
, и рассматриваются решающие функции , для которых  .
.
Третий путь основан на Байесовском подходе к оцениванию, возможном, когда параметр является случайной величиной с заданным (априорным) распределением вероятностей. В этом случае есть случайная величина, средние потери равны  , где математическое ожидание М вычисляется «относительно случайной величины », и правомерна задача минимизации
, где математическое ожидание М вычисляется «относительно случайной величины », и правомерна задача минимизации  . С математической точки зрения байесовский подход безупречен, но на практике ситуации, когда априорное распределение существует и известно, редки.
. С математической точки зрения байесовский подход безупречен, но на практике ситуации, когда априорное распределение существует и известно, редки.
Недостатком всех перечисленных подходов является то, что они привязаны к функции потерь, выбор которой часто, в той или иной мере, субъективен. Поэтому в ряде ситуаций более естественны методы, вообще не аппелирующие к понятию потери. Примером может служить предложенный Д. Фишером метод максимального правдоподобия, используемый в задачах оценивания неизвестного параметра . Пусть распределение  имеет плотность вероятностей
имеет плотность вероятностей  относительно некоторой универсальной (не зависящей от ) меры
относительно некоторой универсальной (не зависящей от ) меры  . Обсуждаемый метод основан на том соображении, что значение вектора наблюдений, как правило, попадает в «зону наиболее вероятных значений», т. е. в область, где плотность вероятностей «велика». Соответственно, во многих отношениях естественной оказывается оценка максимального правдоподобия
. Обсуждаемый метод основан на том соображении, что значение вектора наблюдений, как правило, попадает в «зону наиболее вероятных значений», т. е. в область, где плотность вероятностей «велика». Соответственно, во многих отношениях естественной оказывается оценка максимального правдоподобия
 .
.
Дальнейшее обобщение схемы связано с идеей рандомизации, когда при уже заданном значении вектора наблюдений X решение принимается не однозначно, как выше, а с помощью некоторого случайного механизма, зависящего от X. Точнее, вектору наблюдений X ставится в соответствие не решение  , а зависящее от X и определённое на D распределение вероятностей
, а зависящее от X и определённое на D распределение вероятностей  . При этом решение принимается таким образом, чтобы вероятность того, что при уже наблюдённом
. При этом решение принимается таким образом, чтобы вероятность того, что при уже наблюдённом  решение
решение  , равнялась
, равнялась  . Если распределение
. Если распределение  вырождено в некоторой точке , схема сводится к предыдущей. В случае рандомизации (случайные) потери равны
вырождено в некоторой точке , схема сводится к предыдущей. В случае рандомизации (случайные) потери равны  , где математическое ожидание берётся «относительно случайной величины d, имеющей распределение вероятностей ». Риск в этом случае равен
, где математическое ожидание берётся «относительно случайной величины d, имеющей распределение вероятностей ». Риск в этом случае равен  . Рандомизация не исключает применения всех вышеупомянутых подходов. Следует отметить, что при некоторых не слишком обременительных условиях типа выпуклости и гладкости исходных распределений рандомизация не приводит к фактическому уменьшению риска.
. Рандомизация не исключает применения всех вышеупомянутых подходов. Следует отметить, что при некоторых не слишком обременительных условиях типа выпуклости и гладкости исходных распределений рандомизация не приводит к фактическому уменьшению риска.
Динамические модели укладываются в построенную схему и обладают следующей спецификой. Компонента  вектора наблюдений
вектора наблюдений  интерпретируется как наблюдение в момент времени t=l,...,n, где или
интерпретируется как наблюдение в момент времени t=l,...,n, где или  (конечное время наблюдений), или
(конечное время наблюдений), или  (время наблюдений бесконечно). Каждому t соответствует своё пространство решений
(время наблюдений бесконечно). Каждому t соответствует своё пространство решений  . Решение в момент t определяется функцией
. Решение в момент t определяется функцией  , принимающей значения в . (В рамках предыдущей схемы сказанному соответствуют соотношения
, принимающей значения в . (В рамках предыдущей схемы сказанному соответствуют соотношения  и
и  ).) При этом предполагается, что
).) При этом предполагается, что  т. е. решение принимается лишь на основе уже наблюдённых значений вектора наблюдений. Типичным примером функции потерь в динамической ситуации может служить функция —
т. е. решение принимается лишь на основе уже наблюдённых значений вектора наблюдений. Типичным примером функции потерь в динамической ситуации может служить функция —  , где
, где  интерпретируется как потери в момент
интерпретируется как потери в момент  при наблюдении и решении , а всё выражение - как средние потери на единицу времени при общем времени
при наблюдении и решении , а всё выражение - как средние потери на единицу времени при общем времени  . (Если , можно рассматривать, скажем, верхний предел последнего выражения.) Динамическая схема принятия решений наследует все перечисленные выше подходы.
. (Если , можно рассматривать, скажем, верхний предел последнего выражения.) Динамическая схема принятия решений наследует все перечисленные выше подходы.
Одной из наиболее ярких идей, используемых при исследовании динамических моделей, является также восходящая к А. Вальду идея последовательного статистического анализа, состоящая в предложении отказаться от априорной фиксации числа наблюдений и в каждый момент времени, на основе наблюдённых значений компонент вектора наблюдений, решать вопрос: продолжать наблюдения или нет. В указанной постановке каждое из пространств содержит специфическое решение «продолжить наблюдения», а все остальные решения носят характер «окончательных» - при их принятии наблюдения заканчиваются. В этом случае число наблюдений будет уже случайной величиной, структура которой определяется выбранной последовательностью решающей функции .
Оказывается, что при прочих равных условиях применение последовательного анализа позволяет уменьшить средние потери или среднее время наблюдений. Одним из наиболее показательных в этом отношении примеров может служить последовательный критерий отношения вероятностей при различении двух гипотез - применение последовательного анализа приводит в этой задаче к существенному снижению требуемого объёма выборки при тех же вероятностях ошибок в принятии решений.
2. Имитационное моделирование и метод статистических испытаний
Экономико-математическая (преимущественно компьютерная) имитационная модель позволяет проводить исследования которой проводится экспериментальными методами. Термин введён в начале 1960-х годов, его границы довольно широки и не слишком чётко определены.
Появление имитационного моделирования связано с «новой волной» в экономико-математическом моделировании. Проблемы экономической науки и практики в сфере управления и экономического образования, с одной стороны, и рост производительности компьютеров, с другой, вызвали стремление расширить рамки «классических» экономико-математических методов. Наступило некоторое разочарование в возможностях нормативных, балансовых, оптимизационных и теоретико-игровых моделей, поначалу заслуженно привлёкших к себе тем, что они вносят во многие проблемы управления экономикой обстановку логической ясности и объективности и непосредственно приводят к «разумному» (сбалансированному, оптимальному, компромиссному и т.п.) решению. Выявился широкий класс проблем, в которых эти модели не улавливают существенных явлений реальности. Не всегда удаётся полностью осмыслить априорные цели и, тем более, формализовать критерий оптимальности и (или) ограничения на допустимые решения. Поэтому многие попытки всё же применить такие методы стали приводить к получению неприемлемых, например, нереализуемых (хотя и оптимальных) решений. Преодоление возникших трудностей пошло по пути отказа от полной формализации (как это делается в нормативных моделях) процедур принятия социально-экономических решений. Предпочтение стало отдаваться разумному синтезу интеллектуальных возможностей эксперта и информационной мощи компьютера (см. Диалоговая система). Одно течение в этом направлении — переход к «полунормативным» многокритериальным человеко-машинным моделям; второе — перенос центра тяжести с прескриптивных моделей, ориентированных на схему «условия — решение», на дескриптивные модели, дающие ответ на вопрос, «что будет, если...?» (см. Система поддержки принятия решений).
Первый признак имитационного моделирования — ориентированность на такую схему. В ходе экспериментов с имитационными моделями эксперты задают ей вопросы, модель доставляет ответы; эксперты их анализируют и формируют знания, суждения, решения. Вторая особенность имитационного моделирования — более подробное, чем в классических моделях, отображение структуры прототипа в структуру модели, использующее богатые и гибкие возможности современных средств организации и обработки данных. В этом — отличие современных имитационных моделей от дескриптивных эконометрических моделей, хотя последние можно рассматривать как частный случай имитационных моделей. Эконометрическая модель устроена как чёрный ящик и не отображает внутренних связей в прототипе. Её параметры оцениваются в результате статистической обработки наблюдений за действительностью. Может оказаться, что эти оценки верны только в условиях действующего экономического механизма, и для анализа явлений, которые могут возникнуть в условиях проектируемого экономического механизма, более или менее существенно отличающегося от действующего, модель становится непригодной. Но изучение свойств экономических механизмов, радикально отличных от прежних, особенно актуально. Если конструктор модели вынужден по такой причине отказаться от моделирования «в лоб», он пытается понять и отобразить внутренние причинно-следственные связи и механизмы и для этого представить модель в виде совокупности «атомов» — компонентов, для каждого из которых он способен построить правдоподобную модель и все существенные отношения между которыми он способен правдоподобно отобразить. Такой способ приводит к правдоподобной модели — особенно, если в качестве компонентов модели выбирать модели компонентов системы-прототипа (предприятия, цеха, банки, регионы, транспортные сети, органы управления, группы населения и т. п.). Усложнение структуры имитационной модели вызывается также стремлением использовать её в качестве средства проверки доброкачественности решений, формируемых экспертом или нормативной (т. е. более простой) моделью. Для моделирования первичных структурных единиц («атомов») иногда удаётся привлекать и классические подходы. Так, для отображения технологических процессов уместно использовать эконометрические промышленные и сельскохозяйственные производственные функции, явно не зависящие от механизма управления производством. Для построения функций спроса могут быть использованы оптимизационные модели, так как здесь критерий оптимальности и ограничения можно иногда формулировать обоснованно. Третья особенность имитационной модели состоит в том, что это, как правило, не «картинка» как, скажем, статическая модель межотраслевого баланса, в которой разновременные события «склеены» в одномоментные, а скорее, «фильм», отображающий функционирование прототипа в виде смен состояний модели в последовательные моменты и — в этой связи — появление разных способов моделирования времени. Эта особенность родилась из отмеченной выше потребности не только получить подходящие решения (роль нормативной модели на этом завершается), но и включить в модель компоненты, отображающие отклик системы на принятые решения — в виде показателей её функционирования. Классическую динамическую балансовую модель и её разновидности можно рассматривать как частный, «вырожденный» случай имитационной модели. Хотя функционирование и моделируется, но моменты производства, распределения и потребления ресурсов сводятся в один. В результате чего модель слишком жёстко описывает важные явления, связанные с разными ритмами производств поставщиков и потребителей, последствия срывов договоров поставки. В «невырожденных» имитационных моделях получает отражение то обстоятельство, что процессу потребления ресурсов предшествуют процессы производства и распределения. Четвёртая особенность имитационной модели — свободный выбор средств для моделирования процессов (в то время как классические модели используют сравнительно узкий круг математических конструкций: линейные уравнения и неравенства, оптимизация линейных или дробно-линейных функций, регрессионный анализ, методы теории массового обслуживания). Модели процессов — это машинные и человеко-машинные алгоритмы. Они:
· вычисляют значения модельного времени;
· изменяют значения переменных, представляющих состояния компонентов модели;
· генерируют по ходу моделирования новые компоненты (например, сдаваемые в эксплуатацию строящиеся промышленные предприятия или выставляемые платёжные требования);
· уничтожают компоненты (разорившиеся предприятия или оплаченные платёжки).
В алгоритмы моделирования процессов включаются иногда и процедуры, генерирующие случайные значения некоторых переменных (представляющих, например, текущие погодные условия или отклонение объёмов поставки от договорных). Пятая особенность — широкие возможности диалога экспериментатора с моделью в ходе её выполнения, в то время как с выполняемой на компьютере классической моделью экспериментатор контактирует лишь перед её запуском (задавая значения её изменяемых параметров) и после её завершения (интерпретируя полученные результаты).
Перечисленные особенности не исчерпывают, возможно, всех свойств моделей, которые разные авторы склонны называть имитационными; с другой стороны, некоторые авторы называют имитационными модели, обладающие лишь частью этих свойств; наконец, некоторыми из перечисленных свойств могут в той или иной степени обладать и классические модели, особенно их модификации.
Для представления структур и процессов имитационного моделирования используются универсальные и специализированные языки программирования, проблемно-ориентированные пакеты прикладных программ, различные универсальные и специализированные системы управления базами данных. Все эти средства позволяют моделировать разнообразные структуры и различные отношения между их компонентами: подчинённость, собственность, договорённость и т. п. Моделирование процессов может наталкиваться на методологические трудности. В первую очередь это относится к моделированию человеческого поведения, в частности процессов принятия решений. Это одна из причин, по которой модели процессов реализуются иногда в виде человеко-машинных алгоритмов: некоторые элементы человеческого поведения моделируются специально привлечёнными людьми. Такое участие людей в эксперименте с имитационными моделями приобретает иногда форму имитационной управленческой игры. Точность отображения прототипа определяется структурой модели, свойствами алгоритмов, моделирующих процессы, и реальностью числовой информации, используемой в модели. Сложность имитационных моделей и их прототипов, сложность проведения и интерпретации экспериментов с ними приводит к тому, что в данной сфере затруднительно, а иногда и принципиально невозможно применить формализованные (например, статистические) методы оценки адекватности модели, используемые в естественных науках и технике. Здесь зачастую приходится оперировать субъективными понятиями, принятыми в гуманитарных областях: доверие к модели, правдоподобие модели, убеждённость в её применимости и т. п. Имитационные модели являются подходящим инструментом для системных исследований.
Получение решений в имитационном моделировании производится с помощью метода статистических испытаний. Это численный метод решения математических задач, основанный на моделировании случайных величин или процессов и последующем построении статистических оценок для искомых величин. Другое название метода статистических испытаний - метод Монте-Карло - в большей степени относится к модификациям метода статистических испытаний. Универсальность метода статистических испытаний как метода вычислительной математики определяется возможностью его использования для решения задач, не связанных со случайностью. Это достигается построением вспомогательных вероятностных моделей, куда в качестве параметров входят подлежащие определению постоянные величины.
Простейшая схема метод статистических испытаний такова. Для определения неизвестной величины  подыскивается случайная величина , математическое ожидание которой равно . Если
подыскивается случайная величина , математическое ожидание которой равно . Если  независимы и одинаково распределены так же, как , то при достаточно большом
независимы и одинаково распределены так же, как , то при достаточно большом  по закону больших чисел средняя арифметическая этих величин
по закону больших чисел средняя арифметическая этих величин  будет приближённо равна :
будет приближённо равна :
 при
при  и
и  .
.
Этот факт указывает способ расчёта а путём моделирования случайной величины . С помощью центральной предельной теоремы можно получить оценку погрешности. Эта погрешность стремится к нулю с ростом и, например, с большой вероятностью не превосходит  , где
, где  . Таким образом, например, представляют многомерный интеграл в виде математического ожидания функционала от случайного процесса, который затем моделируется. Известны вероятностные модели для вычисления интегралов, для решения интегральных уравнений систем линейных алгебраических уравнений, краевых задач для эллиптических уравнений, для оценки собственных значений линейных операторов и т. д.
. Таким образом, например, представляют многомерный интеграл в виде математического ожидания функционала от случайного процесса, который затем моделируется. Известны вероятностные модели для вычисления интегралов, для решения интегральных уравнений систем линейных алгебраических уравнений, краевых задач для эллиптических уравнений, для оценки собственных значений линейных операторов и т. д.
Моделирование случайных величин с заданными распределениями, как правило, осуществляется путём преобразования одного или нескольких независимых значений случайной величины а, распределённой равномерно в интервале (0, 1). Последовательности «выборочных» значений обычно получают на компьютере с помощью теоретико-числовых алгоритмов; такие числа называются псевдослучайными.
Если в расчёте по методу статистических испытаний моделируются случайные величины, определяемые конкретным содержанием изучаемого явления, то такой расчёт часто бывает неэффективным. Эта неэффективность обычно проявляется в слишком большой величине погрешности (дисперсии) оценок искомых величин. Разработано много способов уменьшения дисперсии указанных оценок в рамках метода статистических испытаний. В частности, можно выбрать более подходящую вероятностную модель.
Как было отмечено, метод Монте-Карло это численный метод, использующий моделирование случайных величин и построение статистических оценок для искомых величин. Первоначально алгоритмы метода Монте-Карло применялись для:
· оценки многократных интегралов;
· решения интегральных уравнений 2-го рода.
Алгоритм для оценки многократных интегралов.
Пусть необходимо оценить интеграл  по мере Лебега в евклидовом
по мере Лебега в евклидовом  -мерном пространстве и
-мерном пространстве и  — плотность вероятности такая, что
— плотность вероятности такая, что  можно записать в виде математического ожидания следующим образом:
можно записать в виде математического ожидания следующим образом:
 ,
,
где  . Моделируя на компьютере, можно получить выборочных значений
. Моделируя на компьютере, можно получить выборочных значений  . Согласно закону больших чисел,
. Согласно закону больших чисел,
 .
.
Одновременно можно оценить среднеквадратическую погрешность  , т.е. величину
, т.е. величину  , и приближённо построить подходящий доверительный интервал для . Выбором плотности
, и приближённо построить подходящий доверительный интервал для . Выбором плотности  можно распорядиться для получения оценки с возможно меньшей дисперсией. Соответствующие алгоритмы называются существенной выборкой (выборкой по важности). Иногда полезны сочетания метода Монте-Карло с классическими квадратурами — т. н. случайные квадратурные формулы, основная идея которых состоит в том, что узлы и коэффициенты какой-либо квадратурной суммы (например, интерполяционной) выбираются случайно из распределения, обеспечивающего несмещённость получаемой оценки интеграла. При этом порядок скорости сходимости метода Монте-Карло повышается и в некоторых случаях становится максимально возможным на рассматриваемом классе задач.
можно распорядиться для получения оценки с возможно меньшей дисперсией. Соответствующие алгоритмы называются существенной выборкой (выборкой по важности). Иногда полезны сочетания метода Монте-Карло с классическими квадратурами — т. н. случайные квадратурные формулы, основная идея которых состоит в том, что узлы и коэффициенты какой-либо квадратурной суммы (например, интерполяционной) выбираются случайно из распределения, обеспечивающего несмещённость получаемой оценки интеграла. При этом порядок скорости сходимости метода Монте-Карло повышается и в некоторых случаях становится максимально возможным на рассматриваемом классе задач.
Если подинтегральная функция зависит от параметра, то целесообразно использовать метод зависимых испытаний, т. е. вычислять интегралы для различных значений параметра по одним и тем же случайным узлам. Важным свойством метода Монте-Карло является сравнительно слабая зависимость среднеквадратичной погрешности  от размерности задачи, причём порядок сходимости по числу узлов всегда один и тот же:
от размерности задачи, причём порядок сходимости по числу узлов всегда один и тот же:  . Это позволяет вычислять (после предварительных преобразований задачи) интегралы очень высокой и даже бесконечной кратности.
. Это позволяет вычислять (после предварительных преобразований задачи) интегралы очень высокой и даже бесконечной кратности.
Алгоритмы метода Монте-Карло для решения интегральных уравнений 2-го рода
Пусть необходимо вычислить линейный функционал  , где
, где  , причём для интегрального оператора
, причём для интегрального оператора  с ядром
с ядром  выполняется условие, обеспечивающее сходимость ряда Неймана:
выполняется условие, обеспечивающее сходимость ряда Неймана:  . Цепь Маркова
. Цепь Маркова  определяется начальной плотностью
определяется начальной плотностью  и переходной плотностью
и переходной плотностью  ; вероятность обрыва цепи в точке
; вероятность обрыва цепи в точке  равна
равна
 ;
;
— случайный номер последнего состояния. Далее определяется функционал от траектории цепи, математическое ожидание которого равно  . Чаще всего используется т. н. оценка по столкновениям
. Чаще всего используется т. н. оценка по столкновениям
 ,
,
где
 ,
,  .
.
Если  при
при  и
и  при
при  , то при некотором дополнительном условии
, то при некотором дополнительном условии
 .
.
Возможность достижения малой дисперсии в знакопостоянном случае показывает следующее утверждение:
если  и
и  ,
,
где  , то
, то  ,
,  .
.
Моделируя подходящую цепь Маркова на компьютере, получают статистическую оценку линейных функционалов от решения интегрального уравнения 2-го рода. Это даёт возможность и локальной оценки решения на основе представления:  , где
, где  . В методе Монте-Карло оценка первого собственного значения интегрального оператора осуществляется итерационным методом на основе соотношения
. В методе Монте-Карло оценка первого собственного значения интегрального оператора осуществляется итерационным методом на основе соотношения
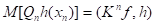
Все рассмотренные результаты почти автоматически распространяются на системы линейных алгебраических уравнений вида  .
.
Решение дифференциальных уравнений осуществляется методом Монте-Карло на базе соответствующих интегральных соотношений. Изложенное представляет собой основу для построения эффективных модификаций статистического моделирования.
Литература
Бесплатная лекция: "3 Гражданские правоотношения" также доступна.
1. Типология потребления, под ред. С.А. Айвазяна и Н.М. Римашевской, М., 1978.
2. Айвазян С.А., Бухштабер В.М., Енюков И.С, Мешалкин Л.Д., Прикладная статистика: классификация и снижение размерности, М., 1989.
3. Методы анализа данных: подход, основанный на методе динамических сгущений, пер. с франц., М., 1985
4. Жамбю М., Иерархический кластер-анализ и соответствия, пер. с франц., М., 1988.
5. Айвазян С.А., Бухштабер В.М., Епюков И.С, Мешалкин Л.Д., Прикладная статистика: классификация и снижение размерности, М., 1989
6. Tryon R.C., Cluster Analysis, Ann. Arb., Edw. Brothers, 1939.



















