
Файловые структуры
1. Файловые структуры, используемые для хранения информации в БД.
В каждой СУБД по-разному организованы хранение и доступ к данным, однако, существуют некоторые файловые структуры, которые имеют общепринятые способы организации и широко применяются практически во всех системах БД. Файлы и файловые структуры, которые используются для хранения информации во внешней памяти, можно классифицировать следующим образом:

С точки зрения пользователя файл – поименованная линейная последовательность записей, расположенных на внешних носителях. Так как файл линейная последовательность записей, то всегда можно определить текущую запись, предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла. В соответствии с методами управления доступом различают устройства внешней памяти с произвольной адресацией и устройства с последовательной адресацией. На устройствах с произвольной адресацией возможна установка головок чтения-записи в произвольное место мгновенно. Практически существует время позиционирования головки, которое мало по сравнению со временем считывания записи.
2. Файлы прямого и последовательного доступа
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа, называются файлами прямого доступа. В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи.
Каждая файловая система – система управления файлами поддерживает некоторую иерархическую файловую структуру, включающую чаще всего неограниченное количество уровней иерархии в представлении внешней памяти.
Для каждого файла в системе хранится следующая информация:
Рекомендуемые материалы
· имя файла;
· тип файла, размер записи, количество занятых физических блоков;
· базовый начальный адрес;
· ссылка на сегмент расширения;
· способ доступа (код защиты).
Для файлов с постоянной длиной записи адрес размещения записи с номером К может быть вычислен по формуле:
К=ВА+(К-1)*LZ+1,
где ВА – базовый адрес, LZ-длина записи.
Поскольку всегда можно определить адрес, на который необходимо позиционировать механизм считывания-записи, то устройства прямого доступа делают это практически мгновенно, поэтому для таких файлов чтение произвольной записи практически не зависит от ее номера. Файлы прямого доступа обеспечивают наиболее быстрый доступ к произвольным записям, и их использование считается наиболее перспективным в системах БД.
Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Они могут быть организованы двумя способами:
Конец записи отмечается специальным маркером.
| Запись 1 | * | Запись 2 | * | Запись 3 | * |
В начале каждой записи записывается ее длина.
| LZ1 | Запись 1 | LZ2 | Запись 2 | LZ3 | Запись 3 |
Файлы с прямым доступом обеспечивают наиболее быстрый доступ. Не всегда можно хранить информацию в виде файлов прямого доступа, но главное – это то, что доступ по номеру записи в базах данных весьма неэффективен. Чаще всего в БД необходим поиск по первичному или возможному ключам, иногда необходима выборка по внешним ключам, но во всех этих случаях мы знаем значение ключа, но не знаем номера записи, который соответствует этому ключу.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение функции, которая по значению ключа однозначно вычисляет адрес (номер записи файла).
NZ=F(K),
где NZ – номер записи, К – значение ключа.
Однако далеко не всегда удается найти взаимно однозначное соответствие между значениями ключа и номерами записей. Часто бывает, что значения ключей разбросаны по нескольким диапазонам. В этих случаях применяют различные методы хеширования (рандомизации) и создают специальные хэш-функции.
При организации доступа по ключу широко применяются индексные файлы.
В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (хеш-код). Преимущество хранения хеш - кода вместо значения состоит в том, что длина свертки независимо от длины исходного значения ключевого поля всегда имеет некоторую постоянную и достаточно малую величину (например, 4 байта), что существенно снижает время поисковых операций. Недостатком хеширования является необходимость выполнения операций свертки, что требует определенного времени, а также борьба с возникновением коллизий (свертка различных значений может дать одинаковый хеш-код).
Суть методов хеширования состоит в том, что мы берем значение ключа или некоторые его характеристики и используем его для начала поиска. То есть, вычисляем некоторую хеш-функцию, и полученное значение берем в качестве адреса начала поиска. При этом мы не требуем полного взаимно однозначного соответствия, но с другой стороны, для повышения скорости мы ограничиваем время этого поиска (количество дополнительных шагов) для окончательного получения адреса. Таким образом, мы допускаем, что нескольким разным ключам может соответствовать одно значение хеш-функции, то есть один адрес. Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хеш-функции называются синонимами. Поэтому при использовании хеширования как метода доступа необходимо принять 2 решения:
· выбор хеш- функции;
· выбор метода разрешения коллизий.
3. Индексные файлы
Несмотря на высокую эффективность хеш-адресации, в файловых структурах не всегда удается найти соответствующую функцию, поэтому при организации доступа по первичному ключу широко используются индексные файлы. Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно совмещение двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс.
Сначала идет индексная область, которая занимает некоторое целое число блоков, а затем идет основная область, в которой расположены все записи файла.
В зависимости от организации индексной и основной областей различают 2 типа фалов: с плотным и неплотным индексом. Файлы с плотным индексом называются также индексно-прямыми файлами, а файлы с неплотным индексом называются индексно-последовательными файлами.
4. Файлы с плотным индексом
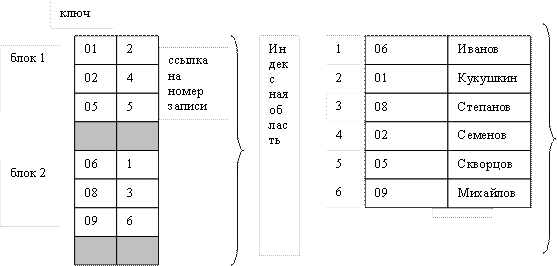
В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура индексной записи имеет следующий вид:
 |
Здесь значение ключа – это значение первичного ключа, а номер записи – это порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
В индексных файлах с плотным индексом для каждой записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном массиве. Наиболее эффективным из всех является бинарный поиск. Максимальное число шагов поиска определяется двоичным логарифмом от общего числа элементов (N).
Tn=log2N
Однако в нашем случае существенным является только число обращений к диску при поиске записи по заданному значению первичного ключа, так как обращение к диску является наиболее длительной операцией по сравнению со всеми обработками в ОП. Поиск происходит в индексной области, где применяется двоичный алгоритм поиска индексной записи, а затем путем прямой адресации мы обращаемся к основной области уже по конкретному номеру записи. Для того чтобы оценить максимальное время доступа, нам надо определить количество обращений к диску для поиска произвольной записи. На диске записи хранятся в блоках. Размер блока определяется физическими особенностями дискового контроллера и ОС. В одном блоке могут размещаться несколько записей. Поэтому нам надо определить количество индексных блоков, которое потребуется для размещения всех требуемых индексных записей, а потому максимальное число обращений к диску будет равно двоичному логарифму от этого числа блоков плюс 1 (после поиска номера записи в индексной области надо будет обратиться к основной области файла).
Рассмотрим, как осуществляются операции добавления новых записей. При операции добавления осуществляется запись в конец основной области. В индексной области необходимо произвести занесение информации в конкретное место, чтобы не нарушать упорядоченности. Поэтому вся индексная область разделяется на блоки и при первоначальном заполнении в каждом блоке остается свободная область (процент расширения). После определения блока, в который должен быть занесен индекс, этот блок копируется в оперативную память, там он модифицируется путем вставки в нужное место новой записи и, уже измененный, копируется на диск.


 | |||
 | |||
В процессе добавления новых записей процент расширения постоянно уменьшается. Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны 2 решения: перестроить индексную область или организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную индексную область записи. Для того чтобы избежать подобных проблем, важно как можно точнее определить объем хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
При удалении записи возникает следующая последовательность действий: запись в основной области помечается как удаленная (отсутствующая), в индексной области соответствующий индекс уничтожается физически, то есть записи, следующие за удаленной записью, перемещаются на ее место, и блок, в котором хранился данный индекс, заново записывается на диск. При этом количество обращений к диску для этой операции такое же, как и при добавлении новой записи.
Файлы с неплотным индексом
Неплотный индекс строится для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов имеет следующий вид:
| Значение ключа первой записи блока | Номер блока с этой записью |
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области.
Пример заполнения основной и индексной областей, если первичным ключом являются целые числа.
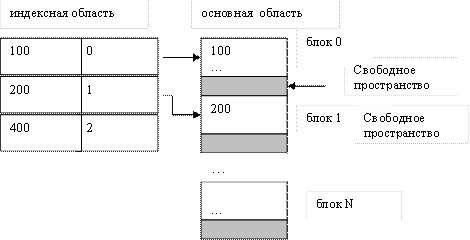 |
 |
Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше. Время доступа при использовании неплотного индекса уменьшается примерно в полтора раза. Рассмотрим процедуры добавления и удаления новой записи при неплотном индексе.
При включении новая запись должна заноситься сразу в требуемый блок на требуемое место. Поэтому сначала ищется требуемый блок основной памяти, в который надо поместить требуемую запись, а потом этот блок считывается в ОП, затем в ОП корректируется содержимое блока и он снова записывается на диск на старое место. Здесь, также как и в первом случае должен быть задан процент первоначального заполнения блоков, но только применительно к основной области. В MS SQL-Server этот процент называется Full-factor и используется при формировании кластеризованных индексов. Кластеризованными называют те индексы, в которых исходные записи физически упорядочены по значениям первичного ключа. При внесении новой записи индексная область не корректируется. Количество обращений к диску при добавлении новой записи равно количеству обращений, необходимых для поиска соответствующего блока плюс одно обращение, которое требуется для занесения измененного блока на старое место.
Tдобавления=log2N+1+1
Уничтожение записи происходит путем ее физического удаления на основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока. Поэтому количество обращений к диску такое же, как и при добавлении новой записи.
На практике для создания индекса для некоторой таблицы БД пользователь указывает поле таблицы, которое требует индексации. Ключевые поля таблицы во многих СУБД, как правило, индексируются автоматически. Индексные файлы, создаваемые по ключевым полям таблицы, часто называют файлами первичных индексов. Индексы, создаваемых для не ключевых полей, называют вторичными индексами. Введение таких индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. В некоторых СУБД, например, Access деление на первичные и вторичные индексы не производится. В этом случае используются автоматически создаваемые индексы и индексы, определяемые пользователем.
Главная причина повышения скорости выполнения различных операций состоит в том, что основная часть работы производится с небольшими индексными файлами, а не с самими таблицами. Наибольший эффект повышения производительности работы с индексированными таблицами достигается для больших по объему таблиц. Индексирование требует незначительного дополнительного места на диске и незначительных затрат процессора для изменения индексов в процессе работы. Индексы в общем случае могут изменяться перед выполнением запросов к БД, после выполнения запросов к БД, по специальным командам пользователя или программным вызовам приложений. Варианты решения проблемы организации физического доступа к информации зависят в основном от следующих факторов:
· вида содержимого в поле ключа записей индексного файла;
· типа используемых ссылок (указателей) на запись основной таблицы;
· метода поиска нужных записей.
5. Моделирование отношений 1:М на файловых структурах
Для моделирования отношений 1:М и М:М на файловых структурах используется принцип организации цепочек записей внутри файла и ссылки на номера записей для нескольких взаимосвязанных файлов.
Моделирование отношений 1:М с использованием однонаправленных указателей
В этом случае связываются 2 файла, например, Ф1 и Ф2, причем предполагается, что одна запись в файле Ф1 может быть связана с несколькими записями в файле Ф2. При этом файл Ф1 в этом комплексе условно называется основным, а файл Ф2 – подчиненным. Структура основного файла может быть представлена в виде 3 областей:
| Ключ | Запись | Ссылка-указатель на первую запись в подчиненном файле, с которой начинается цепочка записей файла Ф2, связанных с данной записью в файле Ф1 |
В подчиненном файле также к каждой записи добавляется специальный указатель, в нем хранится номер записи, которая является следующей в цепочке записей подчиненного файла, связанной с одной записью основного файла.
Таким образом, каждая запись подчиненного файла делится на 2 области: область указателя и область, содержащую собственно запись.
Структура записи подчиненного файла.
| Указатель на следующую запись в цепочке | Содержимое записи |
В качестве примера рассмотрим связь между таблицами Преподаватели и Занятия.
Преподаватели
| Ф1 | ||
| Номер записи | Ключ и остальная запись | Указатель |
| 1 | Иванов И.И. | 1 |
| 2 | Петров П.П. | 3 |
Занятия
| Ф2 | ||
| Номер записи | Указатель на следующую запись в цепочке | Содержимое записи |
| 1 | 4 | Моделирование |
| 2 | - | Вычислительные сети |
| 3 | 6 | Исследование операций |
| 4 | 5 | ЭВМ и программирование |
| 5 | - | Модели данных и СУБД |
| 6 | - |
Преподаватель Иванов ведет Моделирование, ЭВМ и программирование, Модели данных и СУБД. Запись № 5 – последняя в этой цепочке, так как она не имеет указателя на следующую записью.
Алгоритм поиска нужных записей подчиненного файла:
· Ищем запись в основном файле в соответствии с ее организацией. Если требуемая запись найдена, то переходим к шагу 2, в противном случае выводим сообщение об отсутствии записи основного файла.
· Анализируем указатель в основном файле. Если он пустой, это значит, что для этой записи нет связанной записи в подчиненном файле, выводим соответствующее сообщение. В противном случае переходим к следующему шагу.
· По ссылке-указателю в найденной записи основного файла переходим прямым методом доступа по номеру записи на первую запись в цепочке подчиненного файла, переходим к следующему шагу.
· Анализируем текущую запись на содержание. Если это искомая запись, то заканчиваем поиск, в противном случае переходим к шагу 5.
· Анализируем указатель на следующую запись в цепочке. Если он пуст, то выводим сообщение о том, что искомая запись отсутствует, и прекращаем поиск. В противном случае переходим на следующую запись в подчиненном файле и снова переходим к шагу 4.
Использование цепочек позволяет эффективно организовывать модификацию взаимосвязанных файлов.
Алгоритм удаление записи из цепочки подчиненного файла.
· Ищем удаляемую запись в соответствии с ранее рассмотренным алгоритмом. Отличием при этом является обязательное сохранение в специальной переменной номера предыдущей записи в цепочке (NP).
· Запоминаем в специальной переменной указатель на следующую запись в найденной записи, заносим его в переменную NS. Переходим к шагу 3.
· Помечаем специальным символом, например, символом «*» найденную запись, то есть в позиции указателя на следующую запись в цепочке ставим “*”. Это означает, что данная запись отсутствует, а место в файле свободно и может быть занято любой другой записью.
· Переходим к записи с номером, который хранится в NP, и заменяем в ней указатель на содержимое переменной NS.
Для того чтобы эффективно использовать дисковое пространство при включении новой записи в подчиненный файл, ищется первое свободное место, то есть запись, помеченная символом “*”, и на ее место заносится новая запись. После этого производится модификация соответствующих указателей.
6. Инвертированные списки
До сих пор рассматривались структуры данных, которые использовались для ускорения доступа по первичному ключу. Однако достаточно часто в БД требуется проводить операции доступа по вторичным ключам. Возможно существование множества записей с одинаковыми значениями вторичного ключа. Например, в случае БД «Библиотека» вторичным ключом может служить место издания, год издания. Множество книг может быть издано в одном и том же месте.
Для обеспечения ускорения доступа по вторичным ключам используются структуры, называемые инвертированными списками, которые послужили основой организации индексных файлов для доступа по вторичным ключам.
Инвертированный список - это в общем случае двухуровневая индексная структура. Здесь на первом уровне находится файл или часть файла, в котором упорядоченно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и тоже значение вторичного ключа. При этом блоки второго уровня упорядочены по значениям вторичного ключа.
И, наконец, на третьем уровне находится уже собственно файл. Механизм доступа по вторичному ключу заключается в следующем. На первом шаге ищем в области первого уровня заданное значение вторичного ключа, затем по ссылке считываем блоки второго уровня, содержащие номера записей с заданным значением вторичного ключа. Далее уже прямым доступом загружаем в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного ключа. Размер блока ограничен 5-ю записями.
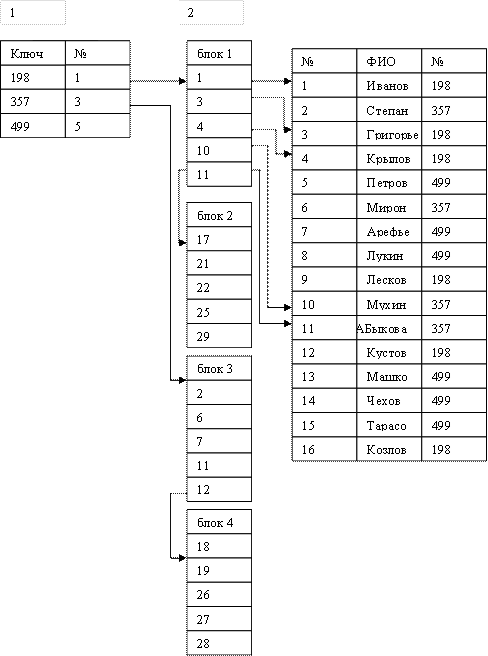 |
Пример инвертированного списка, составленного для вторичного ключа Номер группы в списке студентов некоторого учебного заведения.
7.
 |
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Какие файловые структуры используются для хранения данных во внешней памяти?
2. В чем заключаются различия между файлами прямого и последовательного доступа?
3. Что представляют собой индексные файлы? За счет чего повышается скорость обработки данных при использовании индексов?
4. Что содержится в основной и индексной области файлов с плотным индексом? Какие способы поиска применяются? Как осуществляется добавление, удаление записей?
5. Для каких файлов строится неплотный индекс? Что содержится в индексной области файлов с неплотным индексом?
6. Как выполняется включение новой записи в файл с неплотным индексом?
11. Природоохранные технологии - лекция, которая пользуется популярностью у тех, кто читал эту лекцию.
7. Как происходит удаление записи из файла с неплотным индексом?
8. Для каких областей задается процент первоначального заполнения блоков при использовании файлов с плотным и неплотным индексом?
9. Какова структура основного и подчиненного файла при использовании однонаправленных указателей для моделирования отношений 1:М?
10. Как организован поиск записей в подчиненном файле при использовании однонаправленных указателей?
11. Как происходит удаление записи из цепочки подчиненного файла?
12. Объясните принцип организации инвертированных списков и механизм поиска по вторичному ключу.



















