
Общие принципы управления памятью в однопрограммных ОС
5.2. Общие принципы управления памятью в однопрограммных ОС
Распределение памяти
Общие принципы управления памятью в однопрограммных ОС
Непрерывное распределение. Непрерывное распределение – это самая простая и распространенная схема, согласно которой вся память условно может быть разделена на три области:
· область, занимаемая ОС;
· область, в которой размещается исполняемый процесс;
· свободная область памяти.
Эта схема предполагает, что ОС не поддерживает мультипрограммирование, поэтому не возникает проблемы распределения памяти между несколькими процессами. Программные модули, необходимые для всех программ, располагаются в области самой ОС, а вся оставшаяся память может быть предоставлена исполняемому процессу. Эта область памяти получается непрерывной, что облегчает работу системы программирования. Поскольку в различных однотипных вычислительных комплексах может быть разный состав внешних устройств (и, соответственно, они содержат различное количество драйверов), для системных нужд могут быть отведены отличающиеся объемы ОП, и получается, что можно не привязывать жестко виртуальные адреса программы к физическому адресному пространству. Эта привязка осуществляется на этапе загрузки задачи (процесса) в память.
Для того чтобы отвести задачам как можно больший объем памяти, ОС строится таким образом, чтобы постоянно в ОП располагалась только самая нужная ее часть – ядро ОС. Прежде всего, в ядро ОС входят основные модули супервизора. Для однопрограммных систем понятие супервизора вырождается в модули, получающие и выполняющие первичную обработку запросов от обрабатывающих и прикладных программ, и в модули подсистемы памяти. Ведь если программа по ходу своего выполнения запрашивает некоторое множество ячеек памяти, то подсистема управления памятью должна их выделить (если они есть), а после освобождения памяти эта подсистема должна выполнить действия, связанные с возвратом памяти в систему. Остальные модули ОС, не относящиеся к ее ядру, могут быть обычными диск-резидентными (или транзитными), то есть загружаться в ОП только по необходимости, и после своего выполнения вновь освобождать память.
Рекомендуемые материалы
Такая схема распределения влечет за собой два вида потерь вычислительных ресурсов:
1. Потерю процессорного времени, потому что процессор простаивает, пока задача ожидает завершения операций ввода-вывода.
2. Потерю самой ОП, потому что далеко не каждая программа использует всю память, а режим работы в этом случае однопрограммный. В то же время это недорогая реализация, которая позволяет отказаться от многих второстепенных функций ОС. В частности, такая сложная проблема, как защита памяти, здесь практически отсутствует. Единственное, что желательно защищать – это программные модули и области памяти самой ОС.
Оверлейное распределение. Если есть необходимость создать программу, логическое адресное пространство которой должно быть больше, чем свободная область памяти, или даже больше, чем весь возможный объем ОП, то используется распределение с перекрытием, в основе которого лежит использование так называемых оверлейных структур (англ. overlay – перекрытие, расположение поверх чего-то).
Этот метод распределения предполагает, что вся программа может быть разбита на части – сегменты. Каждая оверлейная программа имеет одну главную (main) часть и несколько сегментов (segments), причем в памяти машины одновременно могут находиться только ее главная часть и один или несколько не перекрывающихся сегментов. На рис. 22 представлен пример организации некоторой программы с перекрытием, причем в представленном случае поочередно можно загружать в память ветви A-B, A-C-D и A-C-E программы.
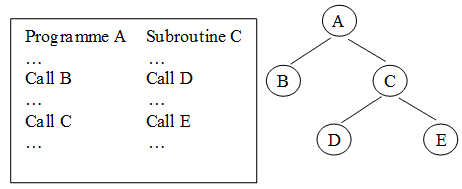
Рисунок 22 – Образное представление организации памяти с использованием структуры с перекрытием
Пока в ОП располагаются выполняющиеся сегменты, остальные находятся во внешней памяти. После того, как текущий (выполняющийся) сегмент завершит свое выполнение, возможны два варианта. Первый – сегмент сам (если данный сегмент не нужно сохранить во внешней памяти в его текущем состоянии) обращается к ОС с указанием, какой сегмент должен быть загружен в память следующим. Второй – сегмент возвращает управление главному сегменту задачи, и уже тот обращается к ОС с указанием, какой сегмент сохранить (если это нужно), а какой сегмент загрузить в ОП, и вновь отдает управление одному из сегментов, располагающихся в памяти.
Простейшие схемы сегментирования предполагают, что в памяти в каждый конкретный момент времени может располагаться только один сегмент (вместе с главным модулем). Более сложные схемы, используемые в больших вычислительных системах, позволяют располагать в памяти несколько сегментов. В некоторых вычислительных комплексах могли существовать отдельно сегменты кода и сегменты данных. Сегменты кода, как правило, не претерпевают изменений в процессе своего исполнения, поэтому при загрузке нового сегмента кода на место отработавшего последний можно не сохранять во внешней памяти, в отличие от сегментов данных, которые сохранять необходимо.
Первоначально программисты сами должны были включать в тексты своих программ соответствующие обращения к ОС (системные вызовы) и тщательно планировать, какие сегменты могут находиться в ОП одновременно, чтобы их адресные пространства не пересекались. Однако с некоторых пор такого рода обращения к ОС системы программирования стали подставлять в код программы сами, автоматически, если в том возникает необходимость.
В известной и популярной в недалеком прошлом системе программирования Turbo Pascal программист просто указывал, что данный модуль является оверлейным. При обращении к нему из основной программы модуль загружался в память и получал управление. Все адреса определялись системой программирования автоматически, обращения к DOS для загрузки оверлеев тоже генерировались системой Turbo Pascal.
Рассмотрев основные принципы работы с памятью в однопрограммных ОС, перейдем к рассмотрению особенностей распределения памяти для более распространенных сегодня мультипрограммных ОС.

5.2.2. Особенности организации управления памятью в мультипрограммных ОС
Особенности организации управления памятью в мультипрограммных ОС
Для организации мультипрограммного режима необходимо обеспечить одновременное расположение в ОП нескольких задач (целиком или частями). При решении этой задачи ОС должна учитывать целый ряд моментов:
· следует ли назначать каждому процессу одну непрерывную область физической памяти или фрагментами;
· должны ли сегменты программы, загруженные в память, находиться на одном месте в течение всего периода выполнения процесса или можно ее время от времени сдвигать;
· что следует предпринять, если сегменты программы не помещаются в имеющуюся память.
Разные ОС по-разному «отвечают» на подобные вопросы управления памятью. Рассмотрим ниже наиболее общие подходы к распределению памяти, которые были характерны для разных периодов развития ОС.
Все методы распределения памяти по критерию использования различных видов запоминающих устройств можно разделить на два класса (рис. 23):
· в которых используется перемещение сегментов процессов между ОП и диском;
· в которых внешняя память не привлекается.
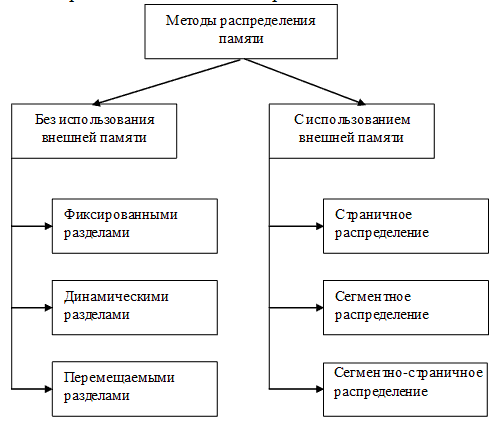
Рисунок 23 – Методы распределения памяти
Рассмотрим эти методы более подробно, начав обзор с методов распределения без использования внешней памяти.
5.2.3. Распределение фиксированными разделами
Распределение фиксированными разделами
Простейший способ управления ОП состоит в том, что память разбивается на несколько областей фиксированной величины, называемых разделами. Такое разбиение может быть выполнено вручную оператором во время старта системы или во время ее установки. После этого границы разделов не изменяются. Очередной новый процесс, поступивший на выполнение, помещается либо в общую очередь (рис. 24а), либо в очередь к некоторому разделу (рис. 24б). В каждом разделе в каждый момент времени может располагаться по одной программе (задаче), и к каждому разделу в отдельности можно применить методы, используемые при распределении памяти в однопрограммных системах.
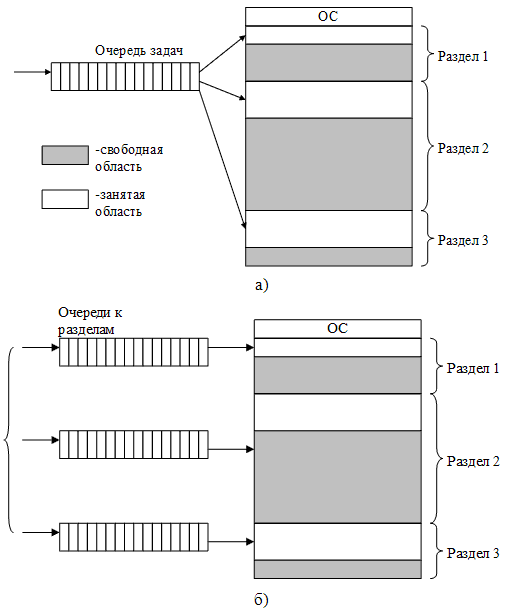
Рисунок 24 – Распределение памяти фиксированными разделами: с общей очередью (а); с отдельными очередями (б)
Подсистема управления памятью в этом случае выполняет следующие задачи:
1. Сравнивает объем памяти, требуемый для вновь поступившего процесса, с размерами свободных разделов и выбирает подходящий раздел.
2. Осуществляет загрузку программы в один из разделов и настройку адресов. Уже на этапе трансляции разработчик программы может задать раздел, в котором ее следует выполнять. Это позволяет сразу, без использования перемещающего загрузчика, получить машинный код, настроенный на конкретную область памяти.
При очевидном преимуществе как простота реализации, данный метод имеет существенный недостаток – существенные потери памяти от внутренней фрагментации. Фрагментация возникает потому, что процесс не полностью занимает выделенный ему раздел или потому, что некоторые разделы слишком малы для выполняемых пользовательских программ. Кроме того, учитывая то, что в каждом разделе может выполняться только один процесс, уровень мультипрограммирования заранее ограничен числом разделов, т.к. процесс независимо от размера будет занимать весь раздел. Так, например, в системе с тремя разделами невозможно выполнять одновременно не более трех процессов, даже если им требуется совсем мало памяти.
Такой способ управления памятью применялся в ранних мультипрограммных ОС. Однако и сейчас метод распределения памяти фиксированными разделами находит применение в ОСРВ, в основном благодаря небольшим затратам на реализацию. Детерминированность вычислительного процесса систем реального времени (заранее известен набор выполняемых задач, их требования к памяти, а иногда и моменты запуска) компенсирует недостаточную гибкость данного способа управления памятью.
5.2.4. Распределение динамическими разделами
Распределение динамическими разделами
Чтобы избавится от фрагментации, присущей распределению памяти с фиксированными разделами, целесообразно размещать в ОП задачи «плотно», одну за другой, выделяя ровно столько памяти, сколько требует процесс. Именно такой принцип лежит в основе распределения памяти разделами переменной величины (динамическими разделами). В этом случае память машины не делится заранее на разделы, и сначала вся память, отводимая для приложений, свободна. Каждому вновь поступающему на выполнение приложению на этапе создания процесса выделяется вся необходимая ему память (если достаточный объем памяти отсутствует, то приложение не принимается на выполнение и процесс для него не создается). После завершения процесса память освобождается, и на это место может быть загружен другой процесс. Таким образом, в произвольный момент времени ОП представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера. Список свободных участков памяти может быть упорядочен либо по адресам, либо по объему.
На рис. 25 показано состояние памяти в различные моменты времени при использовании динамического распределения. Так, в момент t0 в памяти находится только ОС, а к моменту t1 память разделена между 5-ю процессами, причем процесс П4, завершаясь, покидает память. На освободившееся от процесса П4 место загружается процесс П6, поступивший в момент t3.
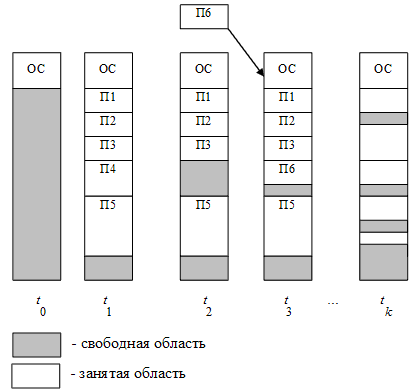
Рисунок 25 – Распределение памяти динамическими разделами
Задачами ОС при реализации данного метода распределения памяти являются:
· ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти;
· при поступлении новой задачи – анализ запроса, просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения поступившей задачи;
· загрузка задачи в выделенный ей раздел и корректировка таблиц свободных и занятых областей;
· после завершения задачи корректировка таблиц свободных и занятых областей.
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему также присущ недостаток, связанный с наличием фрагментации памяти – наличие столь большого числа несмежных участков свободной памяти сравнительно маленького размера, что диспетчер памяти не может образовать новый раздел, хотя суммарный объем свободных областей больше, чем необходимо для выполнения процесса.
5.2.5. Распределение перемещаемыми разделами
Распределение перемещаемыми разделами
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов, так, чтобы вся свободная память образовывала единую свободную область (рис. 26). В связи с этим, ОС в дополнение к функциям, которые выполняет при распределении памяти динамическими разделами, должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется сжатием.
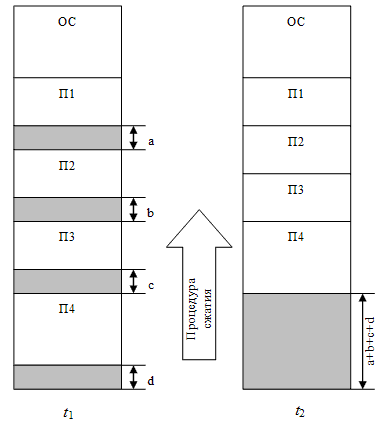
Рисунок 26 – Сжатие памяти при распределении динамическими разделами
Сжатие может выполняться:
1. При каждом завершении задачи (меньше однократной вычислительной работы).
2. В случае, когда для вновь поступившей задачи нет свободного раздела достаточного размера (процедура выполняется реже).
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может требовать значительного времени, что часто нивелирует преимущества данного метода.
В связи с тем, что программы перемещаются по ОП в ходе своего выполнения, то невозможно выполнить настройку адресов с помощью перемещающего загрузчика. Здесь более подходящим оказывается динамическое преобразование адресов.
Сжатие применяется и при использовании других методов распределения памяти, когда отдельному процессу выделяется не одна сплошная область памяти, а несколько несмежных участков памяти произвольного размера (сегментов). Такой подход был использован в ранних версиях OS/2, в которых память распределялась сегментами, а возникавшая при этом фрагментация устранялась путем периодического перемещения сегментов.
Распределение памяти динамическими разделами легло в основу подсистем управления памятью многих мультипрограммных ОС 60-70-х годов, в частности такой популярной ОС, как OS/360.
5.2.6. Сегментное распределение
Сегментное распределение
Наряду с рассмотренными в пп. 4.2.3-4.2.5 методами непрерывного распределения памяти не использующими внешнюю память, существует целый ряд разрывных методов распределения памяти, при которых задаче не предоставляется сплошная (непрерывная) область памяти, и кроме того используется внешняя память.
Идея выделять память задаче не одной сплошной областью, а фрагментами позволяет уменьшить фрагментацию памяти, однако этот подход требует для своей реализации больше ресурсов, он значительно сложнее. Если задать адрес начала текущего фрагмента программы и величину смещения относительно этого начального адреса, то можно указать необходимую нам переменную или команду. Таким образом, виртуальный адрес можно представить состоящим из двух полей. Первое поле будет указывать на ту часть программы, к которой обращается процессор, для определения местоположения этой части в памяти, а второе поле виртуального адреса позволит найти нужную нам ячейку относительно найденного адреса. Программист может либо самостоятельно разбивать программу на фрагменты, либо можно автоматизировать эту задачу, возложив ее на систему программирования.
Первым среди разрывных методов распределения памяти был сегментный. В соответствие с этим методом программу необходимо разбивать на части и уже каждой такой части выделять физическую память. Естественным способом разбиения программы на части является разбиение ее на логические элементы – так называемые сегменты. В принципе, каждый программный модуль (или их совокупность) может быть воспринят как отдельный сегмент, и вся программа тогда будет представлять собой множество сегментов.
Следует отметить, что разбиение на сегменты позволяет дифференцировать способы доступа к разным частям программы (сегментам). Например, можно запретить обращаться с операциями записи и чтения в кодовый сегмент программы, а для сегмента данных разрешить только чтение. Кроме того, разбиение программы на «осмысленные» части делает принципиально возможным разделение одного сегмента несколькими процессами. Например, если два процесса используют одну и ту же математическую подпрограмму, то в ОП может быть загружена только одна копия этой подпрограммы (рис. 27).
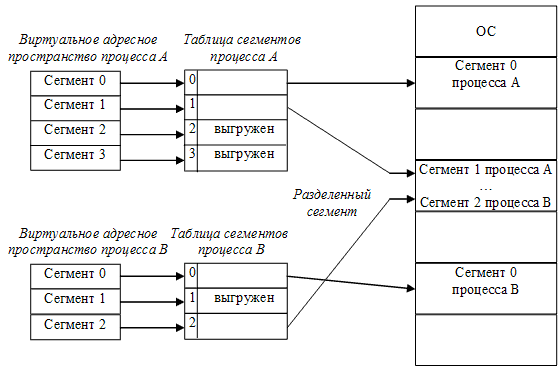
Рисунок 27 – Пример распределения памяти сегментами
Каждый сегмент размещается в памяти как до определенной степени самостоятельная единица. Логически обращение к элементам программы в этом случае будет состоять из имени сегмента и смещения относительно начала этого сегмента. Физически имя (или порядковый номер) сегмента будет соответствовать некоторому адресу, с которого этот сегмент начинается при его размещении в памяти, и смещение должно прибавляться к этому базовому адресу.
Преобразование имени сегмента в его порядковый номер осуществляет система программирования. Для каждого сегмента система программирования указывает его объем. Он должен быть известен ОС, чтобы она могла выделять ему необходимый объем памяти. Операционная система будет размещать сегменты в памяти и вести для каждого сегмента учет о местонахождении этого сегмента. Вся информация о текущем размещении сегментов задачи в памяти обычно сводится в таблицу сегментов, которую чаще называют таблицей дескрипторов сегментов задачи.
Таким образом, виртуальный адрес для этого способа будет состоять из двух полей – номера сегмента и смещения относительно начала сегмента. Соответствующая иллюстрация приведена на рис. 28 для случая обращения к ячейке, виртуальный адрес которой равен сегменту с номером 11 со смещением от начала этого сегмента, равным 612. Как видно в данном случае, ОС разместила данный сегмент в памяти, начиная с ячейки с номером 19700.
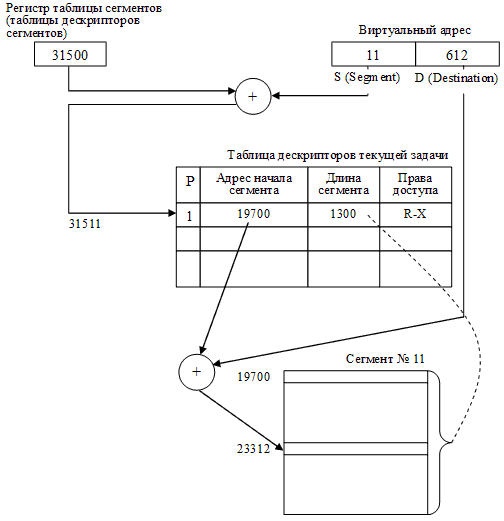
Рисунок 28 – Сегментный способ организации распределения памяти
Итак, каждый сегмент, размещаемый в памяти, имеет соответствующую информационную структуру, часто называемую дескриптором сегмента. Именно ОС строит для каждого исполняемого процесса соответствующую таблицу дескрипторов сегментов, и при размещении каждого из сегментов в оперативной или внешней памяти отмечает в дескрипторе текущее местоположение сегмента. Если сегмент задачи в данный момент находится в ОП, то об этом делается пометка в дескрипторе. Как правило, для этого используется бит присутствия Р (от англ. present). В этом случае в поле адреса диспетчер памяти записывает адрес физической памяти, с которого сегмент начинается, а в поле длины сегмента (limit) указывается количество адресуемых ячеек памяти. Это поле используется не только для того, чтобы размещать сегменты без наложения друг на друга, но и для того, чтобы контролировать, не обращается ли код исполняющейся задачи за пределы текущего сегмента. В случае превышения длины сегмента вследствие ошибок программирования можно выявить нарушения адресации и с помощью введения специальных аппаратных средств генерировать сигналы прерывания, которые позволят фиксировать (обнаруживать) ошибки такого рода.
Помимо информации о местоположении сегмента, в дескрипторе сегмента, как правило, содержатся данные о его типе (сегмент кода или сегмент данных), правах доступа к этому сегменту (можно или нельзя его модифицировать, предоставлять другой задаче), отметка об обращениях к данному сегменту (информация о том, как часто или как давно этот сегмент используется или не используется, на основании которой можно принять решение о том, чтобы предоставить место, занимаемое текущим сегментом, другому сегменту).
При передаче управления следующей задаче ОС должна занести в соответствующий регистр адрес таблицы дескрипторов сегментов этой задачи. Сама таблица дескрипторов сегментов, в свою очередь, также представляет собой сегмент данных, который обрабатывается диспетчером памяти ОС.
При таком подходе появляется возможность размещать в ОП не все сегменты задачи, а только задействованные в данный момент. Благодаря этому, с одной стороны, общий объем виртуального адресного пространства задачи может превосходить объем физической памяти компьютера, на котором эта задача будет выполняться, с другой стороны, даже если потребности в памяти не превосходят имеющуюся физическую память, можно размещать в памяти больше задач, поскольку любой задаче, как правило, все ее сегменты единовременно не нужны. Как известно, увеличение коэффициента мультипрограммирования µ позволяет увеличить загрузку системы и более эффективно использовать ресурсы вычислительной системы.
Очевидно, однако, что увеличивать количество задач можно только до определенного предела, т.к. если в памяти не будет хватать места для часто используемых сегментов, то производительность системы резко упадет. Ведь сегмент, находящийся вне ОП, для участия в вычислениях должен быть перемещен в ОП. При этом если в памяти есть свободное пространство, то необходимо всего лишь найти нужный сегмент во внешней памяти и загрузить его в ОП. Если свободного места нет, придется принять решение – на место какого из присутствующих сегментов будет загружаться требуемый. Перемещение сегментов из ОП на жесткий диск и обратно часто называют свопингом сегментов.
Итак, если требуемого сегмента в ОП нет, то возникает прерывание, и управление передается через диспетчер памяти программе загрузки сегмента. Пока происходит поиск сегмента во внешней памяти и загрузка его в оперативную, диспетчер памяти определяет подходящее для сегмента место. Возможно, что свободного места нет, и тогда принимается решение о выгрузке какого-нибудь сегмента и выполняется его перемещение во внешнюю память. Если при этом еще остается время, то процессор передается другой готовой к выполнению задаче. После загрузки необходимого сегмента процессор вновь передается задаче, вызвавшей прерывание из-за отсутствия сегмента. Всякий раз при считывании сегмента в ОП в таблице дескрипторов сегментов необходимо установить адрес начала сегмента и признак присутствия сегмента.
Если свободного фрагмента памяти достаточного объема нет, но, тем не менее, сумма этих свободных фрагментов превышает требования по памяти для нового сегмента, то в принципе может быть применено сжатие памяти, упомянутое выше в п. 4.2.5.
В идеальном случае размер сегмента должен быть достаточно малым, чтобы его можно было разместить в случайно освобождающихся фрагментах ОП, но достаточно большим, чтобы содержать логически законченную часть программы с тем, чтобы минимизировать межсегментные обращения.
Дисциплины замещения. Для решения проблемы замещения (определения того сегмента, который должен быть либо перемещен во внешнюю память, либо просто замещен новым) используются следующие дисциплины:
· FIFO (First In First Out – первый пришедший первым и выбывает);
· LRU (Least Recently Used – неиспользуемый дольше других);
· LFU (Least Frequently Used – используемый реже других);
· random – случайный выбор сегмента.
Первая и последняя дисциплины являются самыми простыми в реализации, но они не учитывают, насколько часто используется тот или иной сегмент, и, следовательно, диспетчер памяти может выгрузить или расформировать тот сегмент, к которому в самом ближайшем будущем будет обращение. Безусловно, достоверной информация о том, какой из сегментов потребуется в ближайшем будущем, в общем случае быть не может, но вероятность ошибки для этих дисциплин многократно выше, чем у второй и третьей, в которых учитывается информация об использовании сегментов.
При использовании дисциплины FIFO с каждым сегментом связывается очередность его размещения в памяти. Для замещения выбирается сегмент, первым попавший в память. Каждый вновь размещаемый в памяти сегмент добавляется в хвост этой очереди. В этом случае учитывается только время нахождения сегмента в памяти, но не учитывается фактическое использование сегментов. Например, первые загруженные сегменты программы могут содержать переменные, требующиеся на протяжении всей ее работы. Это приводит к немедленному возвращению к только что замещенному сегменту.
Для реализации дисциплин LRU и LFU необходимо, чтобы процессор имел дополнительные аппаратные средства, обеспечивающие поддержку реализации этих дисциплин. Минимальные требования – достаточно, чтобы при обращении к дескриптору сегмента для получения физического адреса, с которого сегмент начинает располагаться в памяти, соответствующий бит обращения менял свое значение (скажем, с нулевого, которое устанавливает ОС, в единичное). Тогда диспетчер памяти может время от времени просматривать таблицы дескрипторов исполняющихся задач и собирать для соответствующей обработки статистическую информацию об обращениях к сегментам. В результате можно составить список, упорядоченный либо по длительности простоя (для дисциплины LRU), либо по частоте использования (для дисциплины LFU).
Защита памяти. Важнейшей проблемой, которая возникает при организации мультипрограммного режима, является защита памяти. Для того чтобы выполняющиеся приложения не смогли испортить саму ОС и другие вычислительные процессы, необходимо, чтобы доступ к таблицам сегментов с целью их модификации был обеспечен только для кода самой ОС. Для этого код ОС должен выполняться в некотором привилегированном режиме, из которого можно осуществлять манипуляции дескрипторами сегментов, тогда как выход за пределы сегмента в обычной прикладной программе должен вызывать прерывание по защите памяти. Каждая прикладная задача должна иметь возможность обращаться только к собственным и к общим сегментам.
При сегментном способе организации виртуальной памяти появляется несколько интересных возможностей по оптимизации управления памятью.
Во-первых, при загрузке программы на исполнение можно размещать ее в памяти не целиком, а «по мере необходимости». Действительно, поскольку в подавляющем большинстве случаев алгоритм, по которому работает код программы, является разветвленным, а не линейным, то в зависимости от исходных данных некоторые части программы, расположенные в самостоятельных сегментах, могут быть не задействованы, а значит их можно и не загружать в ОП.
Во-вторых, некоторые программные модули, являющиеся сегментами, могут быть разделяемыми, поэтому относительно легко организовать доступ к таким общим сегментам. Сегмент с разделяемым кодом располагается в памяти в единственном экземпляре, а в нескольких таблицах дескрипторов сегментов исполняющихся задач будут находиться только указатели на такие разделяемые сегменты.
Однако у сегментного способа распределения памяти есть и недостатки. Согласно схеме доступа к искомой ячейке памяти, представленной на рис. 28, сначала необходимо найти и прочитать дескриптор сегмента, а уже потом, используя полученные данные о местонахождении нужного сегмента, вычислить конечный физический адрес, что требует времени. Для того чтобы уменьшить эти временные потери используется кэширование, то есть размещение в сверхоперативной памяти (специальных регистрах, размещаемых в процессоре) тех дескрипторов, с которыми идет работа в текущий момент.
Пример использования. Примером использования сегментного способа организации виртуальной памяти является ОС OS/2 первого поколения, которая была создана для персональных компьютеров на базе процессора i80286. В этой ОС в полной мере использованы аппаратные средства микропроцессора, который специально проектировался для поддержки сегментного способа распределения памяти. Система OS/2 v.l поддерживала распределение памяти, при котором выделялись сегменты программы и сегменты данных. Система позволяла работать как с именованными, так и с неименованными сегментами. Имена разделяемых сегментов данных имели ту же форму, что и имена файлов. Процессы получали доступ к именованным разделяемым сегментам, используя их имена в специальных системных вызовах. Операционная система OS/2 v.1 допускала разделение программных сегментов приложений и подсистем, а также глобальных сегментов данных подсистем. Вообще, вся концепция системы OS/2 была построена на понятии разделения памяти: процессы почти всегда разделяют сегменты с другими процессами. В этом состояло существенное отличие системы OS/2 от систем типа Unix, которые обычно разделяют только реентерабельные программные модули между процессами.
Сегменты, которые активно не использовались, могли выгружаться на жесткий диск. Система восстанавливала их, когда в этом возникала необходимость. Учитывая то, что все области памяти, используемые сегментом, должны были быть непрерывными, OS/2 перемещала в основной памяти сегменты таким образом, чтобы максимизировать объем свободной физической памяти (осуществляла уплотнение памяти). Области в младших адресах физической памяти, которые использовались для запуска DOS-программ и кода самой OS/2, в уплотнении памяти не участвовали. Кроме того, система или прикладная программа могла временно фиксировать сегмент в памяти с тем, чтобы гарантировать наличие буфера ввода-вывода в физической памяти до тех пор, пока операция ввода-вывода не завершится. Если в результате уплотнения памяти не удавалось создать необходимое свободное пространство, то супервизор выполнял операции фонового плана для перекачки достаточного количества сегментов из физической памяти, чтобы дать возможность завершиться исходному запросу.
5.2.7. Страничное распределение
Страничное распределение
Несмотря на то, что рассмотренный выше сегментный способ распределения памяти приводит к существенно меньшей фрагментации памяти, по сравнению со способами с неразрывным распределением, фрагментация все равно присутствует. Кроме того, много памяти и процессорного времени теряется на размещение и обработку дескрипторных таблиц, так как на каждую задачу необходимо иметь свою таблицу дескрипторов сегментов, а при определении физических адресов приходится выполнять достаточно затратные операции сложения.
Поэтому другим способом разрывного размещения задач в памяти стал страничный способ организации виртуальной памяти, при котором все фрагменты задачи считаются равными (одинакового размера), причем длина фрагмента в идеале должна быть кратна степени двойки, чтобы операции сложения можно было заменить операциями конкатенации.
Как уже упоминалось, при страничном способе организации виртуальной памяти все фрагменты программы, на которые она разбивается (за исключением последней ее части), получаются одинаковыми. Одинаковыми полагаются и единицы памяти, которые предоставляются для размещения фрагментов программы. Эти одинаковые части называют страницами и говорят, что ОП разбивается на физические страницы, а программа – на виртуальные страницы. Часть виртуальных страниц задачи размещается в ОП, а часть – во внешней памяти. Обычно место во внешней памяти, в качестве которой в абсолютном большинстве случаев выступают накопители на магнитных дисках (поскольку они относятся к быстродействующим устройствам с прямым доступом), называют файлом подкачки, или страничным файлом (англ. paging file). Иногда этот файл называют swap-файлом, тем самым подчеркивая, что записи этого файла – страницы – замещают друг друга в ОП. В некоторых ОС выгруженные страницы располагаются не в файле, а в специальном разделе дискового пространства.
Разбиение всей ОП на страницы одинаковой величины, причем кратной степени двойки, приводит к тому, что вместо одномерного адресного пространства памяти можно говорить о двухмерном. Первая координата адресного пространства – это номер страницы, вторая координата – номер ячейки внутри выбранной страницы (его называют индексом). Таким образом, физический адрес определяется парой (Рp, i), а виртуальный адрес – парой (Рv, i), где Рv – номер виртуальной страницы, Рp – номер физической страницы, i – индекс ячейки внутри страницы. Количество битов, отводимое под индекс, определяет размер страницы, а количество битов, отводимое под номер виртуальной страницы, – объем потенциально доступной для программы виртуальной памяти. Отображение, осуществляемое системой во время исполнения, сводится к отображению Рv в Рp и приписыванию к полученному значению битов адреса, задаваемых величиной i. При этом нет необходимости ограничивать число виртуальных страниц числом физических, то есть не поместившиеся страницы можно размещать во внешней памяти, которая в данном случае служит расширением оперативной.
Для отображения виртуального адресного пространства задачи на физическую память, как и в случае сегментного способа организации, для каждой задачи необходимо иметь таблицу страниц для трансляции адресных пространств. Для описания каждой страницы диспетчер памяти ОС заводит соответствующий дескриптор, который отличается от дескриптора сегмента прежде всего тем, что в нем нет поля длины – ведь все страницы имеют одинаковый размер. По номеру виртуальной страницы в таблице дескрипторов страниц текущей задачи находится соответствующий элемент (дескриптор). Если бит присутствия имеет единичное значение, значит данная страница размещена в оперативной, а не во внешней памяти, и в дескрипторе – номер физической страницы, отведенной под данную виртуальную. Если же бит присутствия равен нулю, то в дескрипторе – адрес виртуальной страницы, расположенной во внешней памяти. Именно таким образом осуществляется трансляция виртуального адресного пространства на физическую память. Этот механизм трансляции иллюстрирует рис. 29.
Защита страничной памяти. Защита страничной памяти, как и в случае сегментного механизма, основана на контроле уровня доступа к каждой странице. Как правило, возможны следующие уровни доступа:
· только чтение;
· чтение и запись;
· только выполнение.
Каждая страница снабжается соответствующим кодом уровня доступа. При трансформации логического адреса в физический сравнивается значение кода разрешенного уровня доступа с фактически требуемым. При их несовпадении работа программы прерывается.
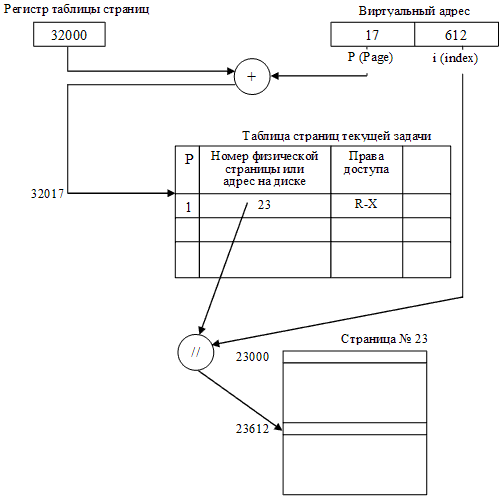
Рисунок 29 – Страничный способ организации распределения памяти
При обращении к виртуальной странице, не оказавшейся в данный момент в ОП, возникает прерывание, и управление передается диспетчеру памяти, который должен найти свободное место. Обычно предоставляется первая же свободная страница. Если свободной физической страницы нет, то диспетчер памяти по одной из вышеупомянутых дисциплин замещения (LRU, LFU, FIFO, случайный доступ) определит страницу, подлежащую расформированию или сохранению во внешней памяти. На ее месте он разместит новую виртуальную страницу, к которой было обращение из задачи, но которой не оказалось в ОП.
Напомним, что дисциплина LFU позволяет выбрать для замещения ту страницу, на которую не было ссылки на протяжении наиболее длительного периода времени. Дисциплина LRU ассоциирует с каждой страницей время ее последнего использования. Для замещения выбирается та страница, которая дольше всех не использовалась.
Для использования дисциплин LRU и LFU в процессоре должны быть соответствующие аппаратные средства. В дескрипторе страницы размещается бит обращения, который становится единичным при обращении к дескриптору.
Если объем физической памяти небольшой и даже часто требуемые страницы не удается разместить в ОП, возникает так называемая «пробуксовка» – ситуация, при которой загрузка нужной страницы вызывает перемещение во внешнюю память той страницы, с которой идет активная работа. Очевидно, что это очень плохое явление. Чтобы его не допускать, желательно увеличить объем ОП (учитывая сравнительно низкую стоимость – это, как правило, не сложно), уменьшить количество параллельно выполняемых задач или прибегнуть к более эффективным дисциплинам замещения.
На рис. 30 представлен пример страничного распределения памяти с участием двух процессов. Подпись «Nвс» в таблицах страниц означает «номер виртуальной страницы», подпись «Nфс» – «номер физической страницы».
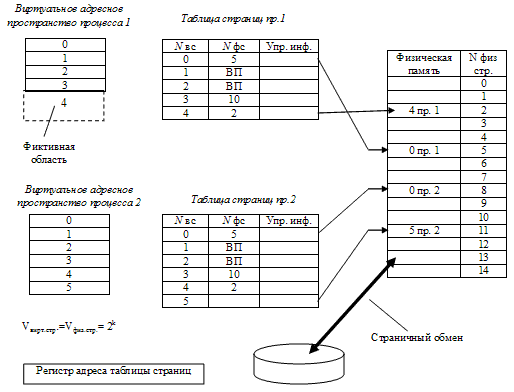
Рисунок 30 – Пример распределения памяти страницами
Примеры использования. Для абсолютного большинства современных ОС характерна дисциплина замещения страниц LRU как наиболее эффективная. Так, именно эта дисциплина использована в OS/2 и Linux. Однако в ОС Windows NT/2000/XP разработчики, желая сделать их максимально независимыми от аппаратных возможностей процессора, отказались от этой дисциплины и применили правило FIFO.
Для того чтобы компенсировать неэффективность правила FIFO, была введена «буферизация» тех страниц, которые должны быть записаны в файл подкачки на диск или просто расформированы. Принцип буферизации следующий. Прежде чем замещаемая страница действительно окажется во внешней памяти или просто расформированной, она помечается как кандидат на выгрузку, если в следующий раз произойдет обращение к странице, находящейся в таком «буфере», то страница никуда не выгружается и уходит в конец списка FIFO. В противном случае страница действительно выгружается, а на ее место в «буфер» попадает следующий «кандидат». Величина такого «буфера» не может быть большой, поэтому эффективность страничной реализации памяти в Windows NT/2000/XP намного ниже, чем в других ОС, и явление пробуксовки проявляется даже при относительно большом объеме ОП.
В ряде ОС с пакетным режимом работы для борьбы с пробуксовкой используется метод «рабочего множества». Рабочее множество – это множество «активных» страниц задачи за некоторый интервал Т, то есть тех страниц, к которым было обращение за этот интервал времени. Реально количество активных страниц задачи (за интервал Т) все время изменяется, и это естественно, но, тем не менее, для каждой задачи можно определить среднее количество ее активных страниц. Это количество и есть рабочее множество задачи. Ряд наблюдений за исполнением множества различных программ показали, что даже если интервал Т равен времени выполнения всей работы, то размер рабочего множества часто существенно меньше, чем общее число страниц программы. Таким образом, если ОС может определить рабочие множества исполняющихся задач, то для предотвращения пробуксовки достаточно планировать на выполнение только такое количество задач, чтобы сумма их рабочих множеств не превышала возможностей системы.
Как и в случае с сегментным способом организации виртуальной памяти, страничный механизм приводит к тому, что без специальных аппаратных средств он существенно замедляет работу вычислительной системы, поэтому используют различные походы к повышению эффективности использования таблиц страниц. Например, одним из примеров эффективного механизма кэширования является ассоциативный кэш. Именно такой ассоциативный кэш и создан в 32-разрядных микропроцессорах i80x86. Начиная с i80386, который поддерживает страничный способ распределения памяти, в этих микропроцессорах имеется кэш на 32 страничных дескриптора. Поскольку размер страницы в этих микропроцессорах равен 4 Кбайт, возможно быстрое обращение к памяти размером 128 Кбайт. Различные походы к повышению эффективности использования таблиц страниц рассмотренные ниже в п. 4.2.8.
Итак, основным достоинством страничного способа распределения памяти является минимальная фрагментация. Поскольку на каждую задачу может приходиться по одной незаполненной странице, очевидно, что память можно использовать достаточно эффективно. Этот метод организации виртуальной памяти был бы одним из самых лучших, если бы не два следующих обстоятельства:
1. Страничная трансляция виртуальной памяти требует существенных накладных расходов: таблицы страниц нужно также размещать в памяти и обрабатывать при помощи диспетчера памяти.
2. Программы разбиваются на страницы случайно, без учета логических взаимосвязей, имеющихся в коде. Поэтому межстраничные переходы, как правило, осуществляются чаще, нежели межсегментные, а также становится трудно организовать разделение программных модулей между выполняющимися процессами.
Для того, чтобы избежать второго недостатка, постаравшись сохранить достоинства страничного способа распределения памяти, был предложен еще один способ – сегментно-страничный, особенности реализации которого будут рассмотрены ниже в п. 4.2.9.
5.2.8. Особенности эффективного использования таблиц страниц
Особенности эффективного использования таблиц страниц
Одним из основных элементов, необходимых при страничном распределении памяти и существенно влияющих на эффективность ее использования в целом, является таблица страниц. Существуют различные варианты организации и использования таблиц страниц, направленные на повышение эффективности их функционирования, отличающиеся как структурой таблиц (многоуровневые, инвертированные), так и способом доступа к их записям (ассоциативный). Рассмотрим их более подробно.
Многоуровневые таблицы страниц. Основную проблему для эффективной реализации таблицы страниц создают большие размеры виртуальных адресных пространств современных компьютеров, которые обычно определяются разрядностью архитектуры процессора.
Например, в 32-битном адресном пространстве при размере страницы 4 Кбайт (Intel) получаем 232/212 = 220, т.е. приблизительно миллион страниц, а в 64-битном и того более. Таким образом, таблица должна иметь примерно миллион строк, а запись в строке состоит из нескольких байтов. Отметим, каждый процесс нуждается в своей таблице страниц (а в случае сегментно-страничной схемы, особенности реализации которой рассмотрены ниже в п. 4.2.9, желательно иметь по одной таблице страниц на каждый сегмент).
Понятно, что количество памяти, отводимое таблицам страниц, не может быть так велико. Для того чтобы избежать размещения в памяти огромной таблицы, ее разбивают на ряд фрагментов. В ОП хранят лишь некоторые, необходимые для конкретного момента исполнения фрагменты таблицы страниц.
В силу свойства локальности число таких фрагментов относительно невелико. Выполнить разбиение таблицы страниц на части можно по-разному. Наиболее распространенный способ разбиения – организация так называемой многоуровневой таблицы страниц.
Для примера рассмотрим двухуровневую таблицу с размером страниц 4 Кбайт, реализованную в 32-разрядной архитектуре Intel (рис. 31).
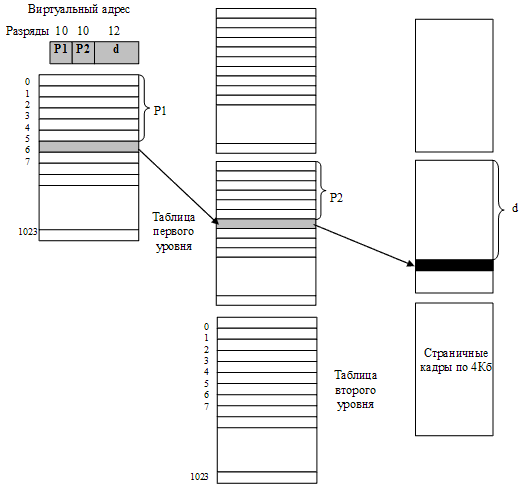
Рисунок 31 – Пример двухуровневой таблицы страниц
Таблица, состоящая из 220 строк, разбивается на 210 таблиц второго уровня по 210 строк. Эти таблицы второго уровня объединены в общую структуру при помощи одной таблицы первого уровня, состоящей из 210 строк. 32-разрядный адрес делится на 10-разрядное поле p1, 10-разрядное поле p2 и 12-разрядное смещение d. Поле p1 указывает на нужную строку в таблице первого уровня, поле p2 – второго, а поле d локализует нужный байт внутри указанного страничного кадра.
При помощи всего лишь одной таблицы второго уровня можно охватить 4 Мбайт (4 Кбайт x 1024) оперативной памяти. Таким образом, для размещения процесса с большим объемом занимаемой памяти достаточно иметь в памяти одну таблицу первого уровня и несколько таблиц второго уровня. Очевидно, что суммарное количество строк в этих таблицах будет много меньше 220.
По аналогии память может быть адресована и с использованием трех- и более уровневой таблицы. Количество уровней в таблице страниц зависит от конкретных особенностей архитектуры. Можно привести примеры реализации одноуровневого (DEC PDP-11), двухуровневого (Intel, DEC VAX), трехуровневого (Sun SPARC, DEC Alpha) пейджинга, а также пейджинга с заданным количеством уровней (Motorola). Функционирование RISC-процессора MIPS R2000 осуществляется вообще без таблицы страниц. Здесь поиск нужной страницы, если эта страница отсутствует в ассоциативной памяти, должна взять на себя ОС (так называемый zero level paging).
Ассоциативная память. Поиск номера кадра, соответствующего нужной странице, в многоуровневой таблице страниц требует нескольких обращений к основной памяти и занимает много времени. Ускорения такого поиска добиваются на уровне архитектуры компьютера. Учитывая упомянутое выше свойство локальности, большинство обращений к памяти в течение некоторого промежутка времени осуществляется к небольшому количеству страниц. Поэтому, естественным решением проблемы ускорения – снабдить компьютер аппаратным устройством для отображения виртуальных страниц в физические без обращения к таблице страниц с использованием небольшой и быстрой кэш-памяти, хранящей необходимую на данный момент часть таблицы страниц (рис. 32). Такое устройство называют ассоциативной памятью или буфером поиска трансляции (англ. translation lookaside buffer – TLB).
Одна запись таблицы в ассоциативной памяти (один вход) содержит информацию об одной виртуальной странице: ее атрибутах и кадре, в котором она находится. Эти поля в точности соответствуют полям в таблице страниц. Рассмотрим функционирование менеджера памяти при наличии ассоциативной памяти.
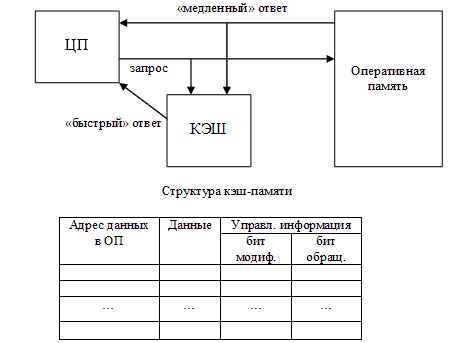
Рисунок 32 – Общие принципы функционирования кэш-памяти
В первый момент времени осуществляется поиск информации о необходимой странице в ассоциативной памяти. Если нужная запись найдена, то производится отображение этой страницы в физическую память, за исключением случаев нарушения привилегий, когда запрос на обращение к памяти отклоняется.
Если нужная запись в ассоциативной памяти отсутствует, отображение осуществляется через таблицу страниц: происходит замена одной из записей в ассоциативной памяти найденной записью из таблицы страниц. В этот момент необходимо решение проблемы замещения (определить какая запись подлежит изменению). Конструкция ассоциативной памяти должна организовывать записи таким образом, чтобы можно было принять решение о том, какая из старых записей должна быть удалена при внесении новых.
Основным параметром, влияющим на эффективность использования ассоциативной памяти, является процент попаданий в кэш (англ. hit ratio) – число удачных поисков номера страницы в ассоциативной памяти по отношению к общему числу поисков. Обращение к одним и тем же страницам повышает процент попаданий в кэш. Чем больше этот процент, тем меньше среднее время доступа к данным, находящимся в ОП. Предположим, например, что для доступа к памяти через таблицу страниц необходимо 100 нс, а для доступа через ассоциативную память – 20 нс. Если hit ratio – 90% (что соответствует значению попадания в реальных ОС), то среднее время доступа рассчитается как
0,9x20 + 0,1x100 = 28 нс.
Такая сравнительно высокая производительность современных ОС показывает эффективность использования ассоциативной памяти. Высокое значение вероятности нахождения данных в ассоциативной памяти связано с наличием у данных таких объективных свойств как пространственная и временная локальность.
Следует обратить внимание на то, что при переключении контекста процессов нужно добиться того, чтобы новый процесс «не видел» в ассоциативной памяти информацию, относящуюся к предыдущему процессу, поэтому требуется ее «очистка». Очевидно, что это ведет к дополнительным затратам на переключения контекста процесса при использовании ассоциативной памяти.
Инвертированная таблица страниц. Несмотря на многоуровневую организацию, хранение нескольких таблиц страниц большого размера по-прежнему представляют собой проблему. Особенно это актуально для 64-разрядных архитектур, где число виртуальных страниц очень велико. Одним из вариантов решения этой проблемы, позволяющей существенно уменьшить объем памяти, занятый под таблицы страниц, является применение инвертированной таблицы страниц (inverted page table). Этот подход применяется на машинах PowerPC, некоторых рабочих станциях Hewlett-Packard, IBM RT, IBM AS/400 и других.
В этой таблице содержится по одной записи на каждый страничный кадр физической памяти. Достаточно одной таблицы для всех процессов. Для хранения функции отображения требуется фиксированная часть основной памяти, независимо от разрядности архитектуры, размера и количества процессов. Например, для компьютера Pentium c 256 Мбайт оперативной памяти нужна таблица размером 64 Кбайт строк.
Несмотря на экономию ОП, применение инвертированной таблицы имеет существенный минус – записи в ней (как и в ассоциативной памяти) не отсортированы по возрастанию номеров виртуальных страниц, что усложняет трансляцию адреса. Один из способов решения данной проблемы – использование хеш-таблицы виртуальных адресов. Часть виртуального адреса, представляющая собой номер страницы, отображается в хеш-таблицу с использованием функции хеширования. Каждой странице физической памяти здесь соответствует одна запись в хеш-таблице и инвертированной таблице страниц. Виртуальные адреса, имеющие одно значение хеш-функции, сцепляются друг с другом, при этом длина цепочки обычно не превышает двух записей.
5.2.9. Сегментно-страничное распределение
Сегментно-страничное распределение
Как и в сегментном способе распределения памяти, программа разбивается на логически законченные части – сегменты – и виртуальный адрес содержит указание на номер соответствующего сегмента. Вторая составляющая виртуального адреса – смещение относительно начала сегмента – в свою очередь может быть представлена состоящей из двух полей: виртуальной страницы и индекса. Другими словами, получается, что виртуальный адрес теперь состоит из трех компонентов: сегмента, страницы и индекса. Получение физического адреса и извлечение из памяти необходимого элемента для этого способа иллюстрирует рис. 33. Очевидно, что этот способ организации доступа к памяти вносит еще большую временную задержку, т.к. необходимо сначала вычислить адрес дескриптора сегмента и прочитать его, затем определить адрес элемента таблицы страниц этого сегмента и извлечь из памяти необходимый элемент и уже только после этого можно приписать к номеру физической страницы номер ячейки в странице (индекс). Задержка доступа к искомой ячейке получается, по крайней мере, в три раза больше, чем при простой прямой адресации.
Чтобы избежать указанной неприятности вводится кэширование, причем кэш, как правило, строится по ассоциативному принципу. Другими словами, просмотры двух таблиц в памяти могут быть заменены одним обращением к ассоциативной памяти.
Напомним, что принцип действия ассоциативного запоминающего устройства предполагает, что каждой ячейке памяти такого устройства ставится в соответствие ячейка, в которой записывается некий ключ (признак, адрес), позволяющий однозначно идентифицировать содержимое ячейки памяти. Сопутствующую ячейку с информацией, позволяющей идентифицировать основные данные, обычно называют полем тега. Просмотр полей тега всех ячеек ассоциативного устройства памяти осуществляется одновременно, то есть в каждой ячейке тега есть необходимая логика, позволяющая посредством побитовой конъюнкции найти данные по их признаку за одно обращение к памяти (если они там, конечно, присутствуют). Часто поле тегов называют аргументом, а поле с данными – функцией. В данном случае в качестве аргумента при доступе к ассоциативной памяти выступают номер сегмента и номер виртуальной страницы, а в качестве функции от этих аргументов получаем номер физической страницы. Остается приписать номер ячейки в странице к полученному номеру, и получим адрес искомой команды или операнда.
Рекомендуем посмотреть лекцию "Разновидности входных величин в ИИС".
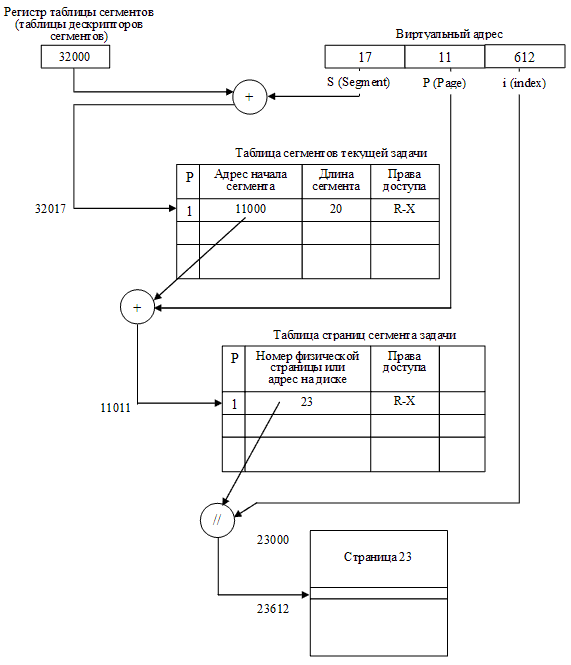
Рисунок 33 – Сегментно-страничный способ организации виртуальной памяти
Сегментно-страничный способ имеет целый ряд достоинств. Разбиение программы на сегменты позволяет размещать сегменты в памяти целиком. Сегменты разбиты на страницы, все страницы сегмента загружаются в память. Это позволяет сократить число обращений к отсутствующим страницам, поскольку вероятность выхода за пределы сегмента меньше вероятности выхода за пределы страницы. Страницы исполняемого сегмента находятся в памяти, но при этом они могут находиться не рядом друг с другом, а «россыпью», поскольку диспетчер памяти манипулирует страницами. Наличие сегментов облегчает разделение программных модулей между параллельными процессами. Возможна и динамическая компоновка задачи. А выделение памяти страницами позволяет минимизировать фрагментацию.
Как отмечалось выше, этот способ распределения памяти требует значительных затрат вычислительных ресурсов и его не так просто реализовать, поэтому используется он сравнительно редко, причем в дорогих мощных вычислительных системах.
Возможность реализовать сегментно-страничное распределение памяти заложена и в семейство микропроцессоров i80x86, однако вследствие слабой аппаратной поддержки, трудностей при создании систем программирования и операционной системы практически в персональных компьютерах эта возможность не используется.


















