


Статистические методы в пакете MS Excel
4.3. Статистические методы в пакете программ:
Microsoft Excel
В большинстве пакетов прикладных программ общего назначения статистические методы реализованы в минимальном объеме и позволяют рассчитать лишь сумму, среднее и некоторые другие простейшие функции. В текстовых редакторах “статистика” заключается в подсчете числа символов, слов и т.п., используемых в тексте. В наибольшей степени статистические методы используются в программах для работы с электронными таблицами, в частности, Microsoft Excel. Собственно, табличные процессоры и являются той основой, на которой затем были созданы специализированные программы для статистической обработки данных. При этом табличные процессоры, в том числе Excel, остаются наиболее доступными для большинства пользователей.
Программа Microsoft Excel располагает набором специальных инструментов анализа, называемым Пакетом анализа. Сюда входят средства статистического анализа, применяемые для данных различного типа, а также инструменты, специально разработанные для технических приложений.
Инструменты анализа позволяют упростить процесс разработки сценариев комплексного анализа. С помощью такого инструмента можно сформировать нужные для анализа данные и параметры, подобрать соответствующие статистические или технические функции рабочего листа, выполнить необходимые расчеты и вывести результаты на экран.
Ниже приведены типы и названия инструментов, входящих в пакет анализа.
| Тип | Название инструмента |
| Статистический | Рекомендуемые материалыВопросы и ответы из теста по 1С Платформе 8.3. Сертификация Яндекс.Директ продвинутый с прокторингом FREE Все лабораторные работы FREE Все лабы для ИУ-7 - решения и задания FREE Справочные материалы для выполнения лабораторных и контролируемых самостоятельных работ FREE Интегралы - готовая программа Однофакторный дисперсионный анализ |
| Двухфакторный дисперсионный анализ с повторением | |
| Двухфакторный дисперсионный анализ без повторения | |
| Ковариация | |
| Корреляция | |
| Описательная статистика | |
| Экспоненциальное сглаживание | |
| Двухвыборочный F- тест для дисперсий | |
| Гистограмма | |
| Скользящее среднее | |
| Генерация случайных чисел | |
| Ранг и персентиль | |
| Регрессия | |
| Парный выборочный t- тест для средних | |
| Двухвыборочный t- тест с одинаковыми дисперсиями | |
| Двухвыборочный t- тест с разными дисперсиями | |
| Двухвыборочный z- тест для средних | |
| Технический | Анализ Фурье |
| Выборка |
Помимо перечисленных инструментов анализа, Microsoft Excel предусматривает применение многих других статистических, финансовых и технических функций рабочего листа. Описание всех функций рабочего листа можно получить, щелкнув по кнопке “Мастер функций” на панели инструментов Стандартная или просмотрев встроенную Справку.
Работа с инструментом анализа данных
Прежде чем применить инструмент анализа, следует создать входной интервал. Для этого нужно ввести данные и расположить их в столбцах или строках на рабочем листе. В первую ячейку строки или столбца можно включить текстовую метку для обозначения переменных.
При применении инструмента анализа к данным во входном интервале, Microsoft Excel создает выходную таблицу результатов. Содержимое выходной таблицы зависит от того, с каким инструментом анализа выполняется работа.
Выходную таблицу можно сохранить на одном листе с входным интервалом, на отдельном листе в той же рабочей книге или же в новой книге.
Для того чтобы применить инструменты анализа, нужно выбрать в меню Сервис команду Анализ данных. В окне Инструменты анализа выделить имя нужного инструмента и задать входной и выходной интервалы, а также другие требуемые параметры.
Для получения пошаговых инструкций и сопутствующих сведений нужно нажать кнопку  , чтобы вывести на экран диалоговое окно Поиск в Справке. Ввести ключевое слово, нажать кнопку “Показать темы”, выделить тему, а затем нажать кнопку “Перейти к”.
, чтобы вывести на экран диалоговое окно Поиск в Справке. Ввести ключевое слово, нажать кнопку “Показать темы”, выделить тему, а затем нажать кнопку “Перейти к”.
Дисперсионный анализ
В общем случае дисперсионный анализ, или anova (analysis of variance), представляет собой статистическую процедуру, определяющую, совпадают ли средние значения для двух и более выборок, извлеченных из генеральных совокупностей с одинаковым средним. Этот метод применим и к тестам для двух средних, например t- тестам.
Однофакторный дисперсионный анализ
Инструмент Однофакторный дисперсионный анализ выполняет простой дисперсионный анализ, проверяющий предположение о равенстве средних нескольких выборок.
На следующем рисунке представлены группы тестовых множеств, расположенные во входном интервале в столбцах. Первая ячейка каждого столбца содержит метки.
| A | B | C | |
| 1 | Группа 1 | Группа 2 | Группа 3 |
| 2 | 75 | 58 | 61 |
| 3 | 68 | 56 | 63 |
| 4 | 71 | 61 | 65 |
| 5 | 75 | 60 | 64 |
| 6 | 66 | 62 | 61 |
| 7 | 70 | 60 | 68 |
| 8 | 68 | 59 | 63 |
| 9 | 68 | 68 | 61 |
| 10 | 69 | 60 | 64 |
| Ключевое слово | Тема |
| Дисперсионный анализ | Двухфакторный дисперсионный анализ с повторением |
| Двухфакторный дисперсионный анализ без повторения | |
| Однофакторный дисперсионный анализ | |
| Корреляция, инструмент | Корреляция |
| Ковариация, инструмент | Ковариация |
| Описательная статистика, инструмент | Описательная статистика |
| t- тесты с одинаковыми дисперсиями | t- тест: двухвыборочный с одинаковыми дисперсиями |
| Экспоненциальное сглаживание, инструмент | Экспоненциальное сглаживание |
| F- тесты | F- тест: двухвыборочный для дисперсий |
| Фурье анализ, инструмент | Анализ Фурье |
| Гистограмма, инструмент | Гистограмма |
| Скользящее среднее, инструмент | Скользящее среднее |
| Случайные числа | Генерация случайных чисел |
| Ранг и персентиль, инструмент | Ранг и персентиль |
| Регрессия, инструмент | Регрессия |
| Выборка, инструмент | Создание выборки |
| Двухвыборочные t- тесты | Т- тест: парный двухвыборочный для средних |
| Неодинаковые дисперсии, t- тесты | Т- тест: двухвыборочный с неодинаковыми дисперсиями |
| z- тесты | Z- тест: двухвыборочный для средних |
Двухфакторный дисперсионный анализ с повторением
Инструмент Двухфакторный дисперсионный анализ с повторением является расширением однофакторного анализа, позволяющим обрабатывать более чем одну выборку по каждой группе данных.
Ниже показано, как может быть организован входной интервал.
| A | B | C | D | |
| 1 | Группа 1 | Группа 2 | Группа 3 | |
| 2 | Попытка 1 | 75 | 58 | 61 |
| 3 | 68 | 56 | 63 | |
| 4 | 71 | 61 | 65 | |
| 5 | 75 | 60 | 64 | |
| 6 | Попытка 2 | 66 | 62 | 61 |
| 7 | 70 | 60 | 68 | |
| 8 | 68 | 59 | 63 | |
| 9 | 68 | 68 | 61 | |
| 10 | 69 | 60 | 64 |
Представленный выше входной интервал содержит результаты тестов, проведенных в трех различных группах респондентов. Тестирование каждой группы проводилось дважды. Полученные данные занимают по четыре строки на каждую выборку.
Двухфакторный дисперсионный анализ без повторения
Инструмент Двухфакторный дисперсионный анализ без повторения выполняет двухфакторный дисперсионный анализ данных, содержащих не более одной выборки по каждой группе.
В первом столбце находится характеристика погодных условий (температура), в 2-5 (Дата 1- Дата 4) показатели дорожно-транспортных происшествий в зимний период в течение четырех последовательных лет.
| A | B | C | D | E | |
| 1 | Темпе-ратура | Дата 1 | Дата 2 | Дата 3 | Дата 4 |
| 2 | +1 | 23 | 24,2 | 24,8 | 25,2 |
| 3 | 0 | 22,2 | 23 | 24 | 24,5 |
| 4 | -1 | 22 | 22,5 | 22,8 | 23 |
| 5 | -2 | 21,2 | 22 | 22,3 | 22,5 |
| 6 | -3 | 18,4 | 20 | 21 | 22 |
| 7 | -4 | 13,5 | 15 | 17 | 18 |
| 8 | -5 | 9,7 | 10 | 13 | 15 |
| 9 | -6 | 5,9 | 6,5 | 8 | 9 |
| 10 | -10 | 5,7 | 5,9 | 6,5 | 7 |
Ковариация и корреляция
Ниже показан интервал, который можно использовать в качестве входных данных при решении задач ковариации и корреляции. Данные здесь расположены в столбцах.
| A | B | C | |
| 1 | Выборка 1 | Выборка 2 | Выборка 3 |
| 2 | 12 | 42 | 120 |
| 3 | 25 | 87 | 40 |
| 4 | 36 | 114 | 40 |
| 5 | 28 | 91 | 130 |
| 6 | 48 | 42 | 120 |
| 7 | 18 | 66 | 20 |
| 8 | 22 | 79 | 40 |
| 9 | 51 | 122 | 40 |
| 10 |
В качестве множества данных, характеризуемых выборками 1, 2, 3, могут выступать, например, значения по отдельным видам преступности или показатели социально-экономической ситуации в стране и уровень преступности в стране.
Ковариация
Инструмент Ковариация вычисляет среднее значение произведений отклонений точек данных от их соответствующих средних. Ковариация выражает степень зависимости между двумя интервалами данных.
|
| (4.18) |
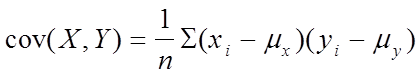
При помощи инструмента ковариации можно определить, изменяются ли два интервала данных совместно, т.е. связаны ли большие значения одного множества данных с большими значениями другого (положительная ковариация), связаны ли малые значения одного множества с большими значениями другого (отрицательная ковариация) или же значения из двух множеств данных не связаны.
Корреляция
Инструмент Корреляция измеряет зависимость между двумя множествами данных, которые масштабированы так, чтобы не зависеть от единиц измерения. Корреляция генеральной совокупности вычисляется как ковариация двух множеств данных, деленная на произведение их стандартных отклонений.
|
| (4.19) |
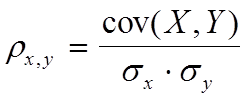
где
|
| (4.20) |
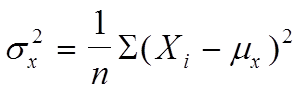
и
|
| (4.21) |
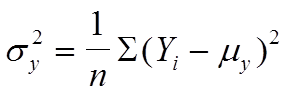
При помощи инструмента корреляции можно определить, изменяются ли два интервала данных совместно, т.е. связаны ли большие значения одного множества данных с большими значениями другого (положительная корреляция), связаны ли малые значения одного множества с большими значениями другого (отрицательная корреляция) или же значения из двух множеств данных не связаны.
Описательная статистика
Инструмент Описательная статистика создает опись одномерных статистических параметров для данных во входном интервале. При помощи этого инструмента можно получить информацию об основной тенденции и изменчивости данных. Представленные в результирующей таблице статистические параметры являются общей исходной точкой для последующего анализа и позволяют определить, какие из тестов целесообразно применить в дальнейших исследованиях.
Входные данные. Инструмент Описательная статистика генерирует, в частности, следующие выходные значения: стандартное отклонение выборки (дисперсия выборки), эксцесс и асимметричность. Эти выходные данные вычисляются с помощью тех же алгоритмов, которые используются встроенными функциями Microsoft Excel СТАНДОТКЛОН, ДИСП, ЭКСЦЕСС и СКОС соответственно.
Прогнозирование
Экспоненциальное сглаживание
Инструмент Экспоненциальное сглаживание предсказывает значение, основываясь на прогнозе для предыдущего периода с учетом ошибки в предыдущем прогнозе. В вычислениях используется константа сглаживания а, определяющая степень чувствительности прогнозов к ошибкам в предыдущем прогнозе.
|
| (4.22) |
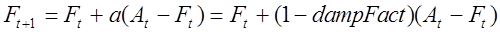
Экспоненциальное сглаживание применяется для прогнозирования тенденций, в частности, прогнозирование преступности и тех явлений, которые обуславливают ее. Прогноз преступности строится на выявленных криминологией различных взаимосвязях и взаимозависимостях между состоянием и тенденциями преступности с одной стороны, и блоком политических, экономических, межнациональных, демографических, культурных и иных процессов— с другой стороны.
Для константы сглаживания наиболее приемлемым является диапазон значений от 0,2 до 0,3. Это означает, что в текущем прогнозе учтено 20%- 30% ошибки предыдущего прогноза. Большие значения константы дают более быструю реакцию, однако прогноз может оказаться неустойчивым. Меньшие константы могут привести к длительным запаздываниям прогнозируемых значений по отношению к фактическим.
Другой метод- регрессия- состоит из ряда процедур, предсказывающих значения на основе взаимосвязей исходных данных. В линейной регрессии осуществляется поиск линейной функции, максимально приближенной к множеству данных. Метод наименьших квадратов, применяемый в линейной регрессии, находит такую зависимость, при которой минимизируется сумма квадратов отклонений точек данных от значений функции регрессии.
Задачу экспоненциального сглаживания можно представить в виде диаграммы. Вы можете воспользоваться параметром “Вывод графика” из диалогового окна Экспоненциальное сглаживание или же применить встроенные средства Microsoft Excel для построения сглаженных графиков и XY (точечных) диаграмм.
Скользящее среднее
Инструмент Скользящее среднее формирует значения на период прогноза, основываясь на средних значениях переменной на протяжении определенного числа предшествующих периодов. Каждое значение прогноза рассчитывается по следующей формуле:
|
| (4.23) |
 ,
,где N- число предшествующих периодов, учитываемых в скользящем среднем, Аt-i+1 — фактическое значение для периода t-i+1 и Ft+1 — предсказываемое значение для периода t+1. Эту процедуру можно использовать для прогнозирования качественно- количественных характеристик преступности.
Скользящее среднее, в отличие от простого среднего, рассчитанного для всех временных периодов, дает представление о тенденции изменения данных. Приведенный ниже входной интервал содержит данные о зарегистрированных квартирных кражах в Российской Федерации с 1990 по 1996 годы.
| A | B | |
| 1 | Год | Зарегистрировано квартирных краж |
| 2 | 1990 | 4242 |
| 3 | 1991 | 6933 |
| 4 | 1992 | 9422 |
| 5 | 1993 | 9632 |
| 6 | 1994 | 6510 |
| 7 | 1995 | 5813 |
| 8 | 1996 | 5040 |
Если прогнозировать ожидаемое число краж на очередной год с применением простого арифметического среднего за прошедшие семь лет, то прогноз составит величину 6798. Этот прогноз построен на одинаковой оценке всех данных и игнорирует явную тенденцию к понижению. Метод скользящего среднего основан на простом одинаковом взвешивании последних значений без учета предыдущих.
Прогнозы, построенные с применением скользящего среднего, отражают преобладающую тенденцию, но с небольшим запаздыванием. С увеличением числа периодов в интервале скользящего среднего прогнозы становятся менее чувствительными к кратковременным колебаниям и более медленно учитывают последние тенденции. На скользящее среднее, рассчитываемое по короткому временному интервалу, существенно влияют самые последние значения. Такая повышенная чувствительность особенно усиливается в случае колебаний исходных данных.
Прогнозы можно дополнить и другими расчетами. Например, можно рассчитать стандартную погрешность, измеряющую относительную точность прогнозируемых значений.
|
| (4.24) | |||
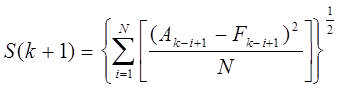
Microsoft Excel помещает значения стандартной погрешности во второй столбец.
Иной метод- прогноз на основе взвешенного скользящего среднего- предполагает использование множества данных (наблюдений) из большого интервала, на протяжении которого наблюдениям присваиваются различные неотрицательные весовые коэффициенты.
Взвешенное скользящее среднее рассчитывается по формуле:
|
| (4.25) |
 ,
,где W1, W2, …, WN- это неотрицательные коэффициенты веса, сумма которых составляет 1; Wi- коэффициент веса для периода i; At-i+1 — фактическое значение для периода t-i+1; Ft — предсказываемое значение для периода t. Взвешенное среднее можно вычислить с помощью функции СУММПРОИЗВ.
Еще один метод- регрессия- состоит из ряда процедур, предсказывающих значения на основе взаимосвязи исходных данных. В линейной регрессии осуществляется поиск линейной функции, максимально приближенной к множеству данных. Метод наименьших квадратов, применяемый в линейной регрессии, находит такую зависимость, при которой минимизируется сумма квадратов отклонений точек данных от значений функции регрессии.
Регрессия
Инструмент Регрессия выполняет линейный регрессионный анализ. В регрессии делается попытка подогнать линию к множеству наблюдений методом наименьших квадратов. Регрессия широко применяется в приближениях, когда требуется проанализировать влияние одной или более независимых переменных на единственную зависимую переменную. Например, уровень преступности в Российской Федерации в ближайшей перспективе зависит от нескольких факторов – отсутствие признаков роста производства и занятости населения, нарастание официальной и скрытой безработицы, сокращение рабочих мест в государственном секторе, географии, климата, а также факторов, характеризующих силы, средства, уровень организованности органов внутренних дел и других. Регрессия определяет степень от каждого из этих факторов на основе данных исследований. Результаты регрессионного анализа позволяют предсказывать тенденцию изменения преступности на ближнюю и отдаленную перспективу. В общем случае регрессия определяет такое уравнение, в котором учитываются все наблюдаемые факторы.
В зависимости от параметров, выбираемых при работе с инструментом Регрессия, Microsoft Excel формирует следующие результаты:
* итоговую выходную таблицу, содержащую таблицу дисперсионного анализа ANOVA, стандартную погрешность оценки y, коэффициенты, стандартную погрешность коэффициентов, значения r2 и число наблюдений;
* выходную таблицу остатков, содержащую остатки, стандартные остатки и предсказанные значения;
* график остатков, показывающий каждую независимую переменную в сравнении с остатками;
* график линейного подбора прогнозируемых значений к наблюдаемым;
* график нормального распределения;
* двухстолбцовую выходную таблицу распределения вероятностей, показывающую значения зависимой переменной и персентиля, применяемые для построения графика нормального распределения.
При выборе параметров определяют местоположение выходных таблиц посредством ввода ссылки на ячейку в левом верхнем углу для каждой из выходных таблиц. Поскольку размер выходных таблиц зависит от объема и типа входных данных, то во избежание перекрывания выходных таблиц надо придерживаться следующих правил при определении выходных интервалов:
* размещайте выходные интервалы на рабочем листе рядом, поскольку, как правило, изменяется их длина, а не ширина;
* для выходной таблицы остатков выделите не менее 4 столбцов;
* для выходной таблицы распределения данных выделите не менее 2 столбцов.
При вводе данных во входной интервал Y или во входной интервал X можно включить или исключить метки, предназначенные для отчета.
Microsoft Excel упорядочивает независимые переменные по возрастанию слева направо и присваивает им в выходной таблице имена x1, x2 и x3. Результаты, формируемые Microsoft Excel на основе указанных выше входных интервалов, зависят от параметров, выбранных в диалоговом окне Регрессия. Например, если установить флажки “Остатки”, “График остатков”, “График нормальной вероятности” и заполнить соответствующие окна выходных интервалов, Microsoft Excel сформирует следующие результаты:
* таблицу дисперсионного анализа ANOVA и итоговые данные;
* выходную таблицу остатков, показывающую остатки и предсказанные значения;
* три графика остатков;
* один график нормального распределения;
* выходную таблицу распределения данных.
Дополнительные сведения можно найти, нажав на кнопку “Мастер функций” на панели инструментов Стандартная или см. Функции ЭКСПРАСП, ПРЕДСКАЗ, РОСТ, ЛИНЕЙН, ЛГРФПРИБЛ, СУММПРОИЗВ и ТЕНДЕНЦИЯ во встроенной Справке.
Гистограмма
Инструмент Гистограмма вычисляет индивидуальные и кумулятивные частоты для интервала ячеек с данными и карманами данных. Этот инструмент также формирует сведения о количестве появлений значения в множестве данных. Например, исследуется динамика отдельных видов преступлений. Упорядоченный по алфавиту список разбивается по группам (карманам), и показатели распределяются в пределах каждого кармана. Таблица гистограммы содержит граничные буквы для каждого из карманов и число оценок в интервале между нижней и текущей границами карманов. Отдельная, наиболее часто встречающаяся оценка, - это мода интервала ячеек с данными.
Для получения подробных сведений надо нажать кнопку “Мастер функций” на панели инструментов Стандартная или см. Функции ЧАСТОТА и МОДА во встроенной Справке.
Генерация случайных чисел
Инструмент Генерация случайных чисел заполняет интервал независимыми случайными числами на основе одного или нескольких распределений. Случайные переменные широко применяются в статистическом моделировании. Описанная процедура позволяет построить генеральную совокупность, элементы которой характеризуются определенным распределением вероятностей. Например, можно применить нормальное распределение для того, чтобы охарактеризовать генеральную совокупность по показателю выработки работающих в ИТУ или применить распределение Бернулли для определения вероятности обнаружения контрабанды при выборочной проверке автотранспорта.
Распределение данных, полученных с помощью инструмента Генерация случайных чисел, можно показать с помощью инструмента Гистограмма.
Подробнее см. Функции СЛЧИС и СЛУЧМЕЖДУ во встроенной Справке.
Ранг и Персентиль
Инструмент Ранг и Персентиль формирует таблицу, содержащую порядковый и процентный ранг каждого значения множества данных. Эту процедуру можно использовать для анализа относительного положения значений в наборе данных.
Для получения подробных сведений надо нажать кнопку “Мастер функций” на панели инструментов Стандартная или см. Функции ПЕРСЕНТИЛЬ и ПРОЦЕНТРАНГ во встроенной Справке.
Тесты для дисперсий и средних
Двухвыборочный F- тест для средних
Инструмент Двухвыборочный F- тест для дисперсий выполняет двумерный F- тест, реализующий метод сравнения дисперсий двух генеральных совокупностей. Например, с помощью F- теста можно определить разницу в дисперсиях по двум выборкам, представляющим какие-либо показатели.
В следующей таблице сравниваются коэффициенты преступности по Российской Федерации и Республике Татарстан.
| A | B | С | |
| 1 | Год | РФ | РТ |
| 2 | 1992 | 1857 | 1751 |
| 3 | 1993 | 1888 | 1693 |
| 4 | 1994 | 1779 | 1655 |
| 5 | 1995 | 1862 | 1584 |
| 6 | 1996 | 1774 | 1404 |
Парный двухвыборочный t- тест для средних
Инструмент Парный двухвыборочный t- тест для средних выполняет двумерный t- тест Стьюдента. Этот вид t- теста выявляет отличия между средними выборок. При этом предполагается, что дисперсия генеральных совокупностей, из которых взяты множества данных, не равны. Применение парного теста целесообразно, когда в выборках представлены естественные пары данных наблюдения, например, если проверяемая группа тестируется дважды- до и после эксперимента. Так, одни и те же объекты могут быть проверены вторично после некоторой обработки, чтобы проверить, дает ли она какой- либо эффект. Например, обследования могут проводиться до и после мероприятий по профилактике правонарушений среди несовершеннолетних.
Поскольку тест является парным, количество точек данных двух входных интервалов должно совпадать.
Двухвыборочный t- тест с одинаковыми дисперсиями
Инструмент Двухвыборочный t- тест с одинаковыми дисперсиями выполняет двумерный t- тест Стьюдента. Этот вид t- теста основан на предположении, что средние обоих множеств данных одинаковы, и может считаться гомоскедастическим t- тестом. Т- тесты можно применять для определения равенства средних двух выборок.
Двухвыборочный t- тест с одинаковыми дисперсиями
Инструмент Двухвыборочный t- тест с одинаковыми дисперсиями выполняет двумерный t- тест Стьюдента. Этот вид теста основан на предположении, что дисперсии обоих множеств данных различны, и являются гетероскедастическим t- тестом. С его помощью можно определить равенство средних двух выборок. Этот тест применяется для исследования двух различных групп. Исследуя одну и ту же группу до и после обработки, применяйте парный тест.
Проверяемое статистическое значение t определяется по следующей формуле:
|
| (4.26) |
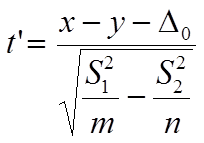
Для аппроксимации степеней свободы применяется формула, приведенная ниже. Как правило, число, возвращаемое этой формулой, не является целым. Оно округляется, и с помощью полученного целого числа можно определить критическое значение по t- таблице.
|
| (4.27) |
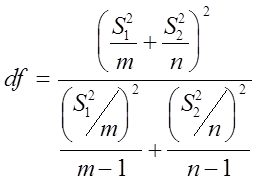
Двухвыборочный z- тест для средних
Инструмент Двухвыборочный z- тест для средних выполняет двумерный z- тест для средних выборок, дисперсии которых известны. Этот метод обычно применяется для проверки гипотезы, предполагающей, что средние двух генеральных совокупностей различны. Например, с помощью этого теста можно определить различия между характеристиками двух моделей автомобилей.
Дополнительные сведения можно найти, если щелкнуть по кнопке “Мастер функций” на панели инструментов Стандартная или см. Функции КОВАР, FРАСПОБР, ФТЕСТ, НОРМРАСП, НОРМСТРАСП, НОРМОБР, НОРМСТОБР, НОРМАЛИЗАЦИЯ, СТЬЮДРАСП, ТТЕСТ и ZТЕСТ во встроенной Справке.
Специализированные пакеты статистической обработки данных
Возможностей табличных процессоров достаточно для работы с аналитическими таблицами, используемыми в органах внутренних дел. Однако их возможности далеко выходят за рамки статистики, и это приводит к определенному неудобству в работе, особенно у начинающих, не имеющих опыта работы со статистикой сотрудников.
Особое место занимают так называемые статистические пакеты общего назначения. Отсутствие прямой ориентации на специфическую предметную область, широкий диапазон статистических методов, дружелюбный интерфейс пользователя привлекает в них не только начинающих пользователей, но и специалистов. Универсальность этих пакетов особенно полезна:
* на начальных стадиях обработки, когда речь идет о подборе статистической модели или метода анализа данных;
* когда поведение статистических данных выходит за рамки использовавшейся ранее модели;
* в процессе обучения основам статистики.
К таким пакетам относятся системы STATGRAPHICS, SPSS, SYSTAT и другие.
Для того, чтобы статистический пакет общего назначения был удобен и эффективен в работе, он должен удовлетворять многочисленным и весьма жестким требованиям. В частности, необходимо, чтобы он:
* содержал достаточно полный набор стандартных статистических методов;
* был достаточно прост для быстрого освоения и использования;
* отвечал высоким требованиям к вводу, преобразованиям и организации хранения данных, а также к обмену с широко распространенными базами данных;
* имел широкий набор средств графического представления данных и результатов обработки: картинка порой отражает суть дела лучше, чем любые статистические показатели;
* предоставлял удобные возможности для включения в отчеты таблиц исходных данных, графиков, промежуточных и окончательных результатов обработки;
* имел подробную документацию, доступную для начинающих и информативную для специалистов- статистиков.
Статистический графический пакет STATGRAPHICS, разработанный американской корпорацией MANUGISTICS (до 1 мая 1992 г. называющейся Scientific Time Sharing Corp.) для IBM-совместимых компьютеров, по признанию Infoworld, Software Digest и других авторитетных журналов, является на сегодняшний день наиболее эффективной интегрированной системой статистического анализа данных. Cтоль высокую оценку STATGRAPHICS заслужил главным образом благодаря удачному соединению научных методов обработки разнотипных данных с современной интерактивной графикой. Это альянс подкреплен широкими возможностями взаимодействия с другими программными продуктами (электронными таблицами, базами данных ) и периферийными устройствами. Дружественный интерфейс и тщательно отшлифованная документация способствует быстрому освоению пакета как специалистами в области математической статистики, так и работниками других сфер деятельности в том числе в правоохранительных органах.
В пакет включено более 250 процедур обработки данных по следующим разделам математической статистики :
· анализ вариаций (дисперсионный анализ);
· анализ временных рядов;
· дескриптивная (описательная) статистика ;
· контроль качества ;
· многомерный анализ;
· непараметрический анализ;
· планирование эксперимента;
· подбор распределений;
Вместе с этой лекцией читают "5 Системы на кристалле. Конвертация проектов".
· прогнозирование;
· разведочный анализ;
· регрессионный анализ.
В России STATGRAPHICS хорошо известен давно и интенсивно используется. Однако даже в самых свежих публикациях, как правило, фигурирует версия 3.0, созданная еще в 1988г. С тех пор пакет модернизировался почти ежегодно и в более поздних версиях претерпел значительные изменения .
В версии 4.0 пакет STATGRAPHICS введены средства автоматизации рутинных и повторяющихся процедур статистического анализа. До двадцати отдельных операций можно инициализировать с помощью “горячих” клавиш, а порядок выполнения комплексных процедур задать макросами, в которых нужно подробно описать весь процесс работы, начиная с импорта файлов и заканчивая выдачей твердой копии выходного документа. В макросы можно включать паузы, полезные подсказки (например, о необходимости выключить принтер), процедуры проверки корректности используемых данных.
Широкое распространение в настоящее время STATGRAPHICS приобрел, в частности, для обработки данных социологических исследований, проводимых в правоохранительных органах.


















