
Устройства ввода-вывода речевой информации
1.14 Устройства ввода-вывода речевой информации
Модель речи. Устройства ввода – вывода (УВв) речевой информации относятся к совмещенным периферийным устройствам.
Существуют несколько методов анализа речи. Первым был применен метод предварительной визуализации речи. При этом анализируются оптические изображения губ оператора. Этот метод построен на опыте языка общения глухонемых и тяготеет к бионике. Второй метод - метод анализа колебаний голосовых связок, снимаемых с помощью лорингофона. Он, как и первый метод, тяготеет к бионике и пригоден к работе в условиях сильных звуковых помех, например, в кабине летательного аппарата, вблизи прокатного стана. Третий метод анализа - анализ спектральных характеристик речи - энергетических, частотных, временных и амплитудных спектров. Этот метод рассмотрим подробнее в применении к распознаванию отдельных слов, например, команд управления.
Структурная схема анализатора речи. Анализаторы подразделяются на два основных класса: анализаторы сигналов и анализаторы сообщений. В анализаторах сигналов достигается сжатие (компрессия) информационного потока сигналов с микрофона (105 бит/c) за счет учета акустических и статистических характеристик речевого сигнала без обращения к его смысловой функции.
Cистемы речевого общения строятся на базе специализированных речевых процессоров. Анализатор реализуется аппаратно и представляет собой специализированное устройство, включающее в себя электронные схемы, называемые предпроцессором. Предпроцессор - программно-управляемое аналогово-цифровое устройство, которое осуществляет спектральный анализ речевого сигнала с последующим преобразованием данных в цифровую форму.
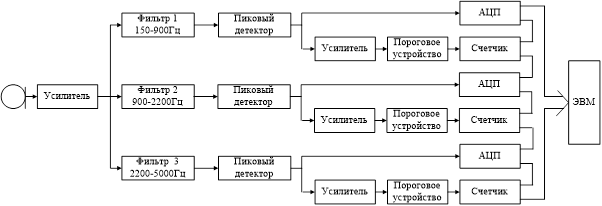
Для получения значений шести спектральных параметров звука (при анализе по методу спектральных характеристик речи) электрический сигнал, полученный с микрофона, пропускается через три полосовых фильтра (рисунок 1.66) с полосами пропускания, равными поддиапазонам речевого спектра. В каждом канале трех поддиапазонов пиковый детектор выделяет максимальное значение амплитуд сигналов за время кванта; аналого-цифровой преобразователь выдает в двоичном коде значение величины выделенной амплитуды. Для обеспечения стабильной работы в схему анализатора введены усилители, охваченные обратной связью, которые осуществляют автоматическую регулировку усиления амплитуды сигнала.
На выходе порогового устройства получаются полуволны гармонических составляющих спектра сигнала в данном поддиапазоне.
Затем программно производится объединение или разбиение квантов речи в зависимости от того, установившийся сегмент речи или переходной, параметры соседних квантов которого резко меняются. Для этого необходимо измерять сходство между параметрами двух соседних квантов, а затем и сегментов. При большом сходстве кванты объединяются, если же изменение параметров слишком велико, сегменты разбиваются. Таким образом определяются границы фонем.
Рекомендуемые материалы
Рисунок 1.66 - Структурная схема анализатора речи по
методу спектральных характеристик
Структура устройств ввода речи. Процесс ввода речи, как процесс распознавания слуховых образов, состоит из трех этапов: анализа, идентификации и ввода в ЭВМ (рисунок 1.67). Основные трудности представляет индивидуальность голоса и слитность речи, что усложняет анализ и идентификацию единиц речи - звуков, фонем, слов.

Рисунок 1.67 - 3 этапа процесса ввода речевого сообщения
В основе лежит принцип распознавания образов. Система выделяет из поступающего речевого сигнала набор некоторых признаков, составляющий его описание, затем сравнивает полученное описание с эталонными описаниями, хранящимися в библиотеке.
Все системы ввода речи делятся по следующим критериям:
− способности распознавать слитную речь или отдельно произносимые слова;
− объему словаря распознаваемых слов;
− ориентированности на одного говорящего или на произвольное число говорящих.
Если набор слов ограничен, то распознавать слова и границы между ними довольно просто (рисунок 1.68, а). В этом случае алгоритм распознавания речевых команд основан на принципе перцептрона.
Лучшие из современных программ после предварительной настройки на голос пользователя распознают дискретную речь с ошибкой, не превышающей 5%. При распознавании слитной речи (рисунок 1.68, б) число ошибок примерно в 5 раз больше. При спонтанном диалоге ошибок распознавания примерно вдвое больше, чем при чтении текста. С увеличением объема словаря разбиение на слова становится сложнее, качество распознавания падает.
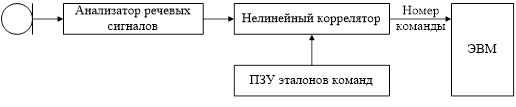
а)
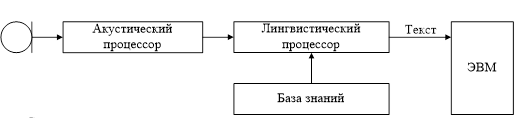
б)
а - ограниченного словаря;
б – универсальное.
Рисунки 1.68 - Структуры устройств ввода речевых сообщений
Устройства вывода речевой информации – синтезаторы. Задача вывода речевой информации сводится к преобразованию машинных кодов, в колебания звуковых частот, составляющих речевой сигнал. Устройства вывода речевых сообщений при любой реализации аппаратно и программно проще, чем устройства ввода.
Синтезаторы речевых сообщений делятся на две группы: синтезаторы ограниченного словаря – компиляторы и универсальные.
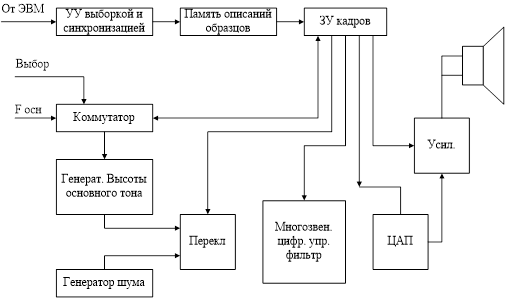
Рисунок 1.69 - Структурная схема компилятора
Системы ввода-вывода речевой информации
Способы формирования речевого сигнала делятся на 2 группы:
- формирование по образцам (компилятивный синтез);
- синтез по правилам.
Формирование речевого сообщения по образцам.
Люди также интересуются этой лекцией: Пожар: понятие, зоны, динамика и периоды развития.
Представляет собой восстановление аналогового сигнала, где выходные речевые сообщения (аналоговые сигналы) находятся в библиотеках-словарях. При необходимости вывести сообщение – производится поиск нужного сообщения в библиотеке и выводится через канал воспроизведения.
Системы формирования речевых сигналов по образцам различаются возможностями библиотек, качеством звучания восстановленной речи и сложностью аппаратной реализации.
Недостаток – медленный поиск нужного сообщения.
Достоинство – обеспечивает сравнительно хорошее качество речи.
Синтез речевых сообщения по правилам
Основано на расчленении речевого сигнала на отдельные фонетические составляющие. Что бы вывести речевые сообщения, необходимо иметь фонетическое описание произносимого слова, Фонетическое описание представляет собой последовательность элементов фонетического алфавита, включая паузы.



















