
Основные сведения из теории вероятностей и математической статистики
§ 2. Основные сведения из теории вероятностей и математической статистики
Большинство экономических показателей, с которыми приходится работать, можно рассматривать как случайные величины, принимающие в итоге опыта случайные значения.
Для того, чтобы прогнозировать поведение случайной величины, нам нужно знать ее закон распределения: ряд распределения, функцию распределения F(x) или плотность распределения f(x). В некоторых случаях вид закона распределения предсказывает. Другой путь получения закона распределения - проведение и обработка эксперимента над случайной величиной X.
Проводится n экспериментов (наблюдений) над случайной величиной X. В каждом из них случайная величина принимает какое-то из своих возможных значений. В результате получаем n чисел
{ x 1 , x 2 , x 3 , . . . , x n }
Каждое число называется «варианта »,
все они вместе образуют «выборку» ,
n - «объем выборки» .
Рекомендуемые материалы
Закон распределения - это соответствие между возможными значениями случайной величины и вероятностями того, что она примет эти значения. Но вероятность этих возможных значений мы можем найти экспериментально как относительную частоту
W(A)=m/n ,
n - число опытов,
m - число появлений интересующего нас события ).
Рассмотрим дискретную случайную величину X. В опытах ее значения могут повторяться. Для каждого опытного значения x i найдем его частоту n i и относительную частоту w i = n i / n . Если записать в таблицу варианты x i и их частоты w i , то получим представление о ряде распределения :
| x i | x 1 | x 2 | . . . | . . . | x k |
| w i | w 1 | w 2 | . . . | . . . | w k |
Для любой случайной величины универсальным способом задания закона распределения является функция распределения F(x). По определению, функция распределения - это вероятность попадания случайной величины в область, лежащую слева от аргумента x : F(x) = P(X<x).
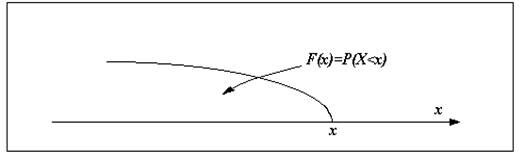
Из эксперимента мы можем найти относительную частоту попадания в область, лежащую слева от аргумента , и это будет эмпирическая или статистическая функция распределения :
F*(x) = W(X<x).
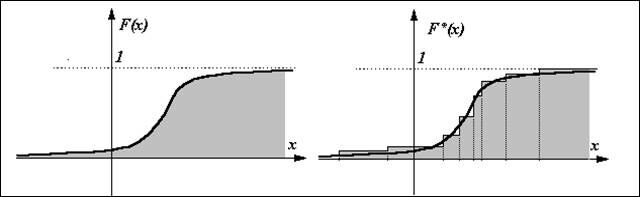
Если построить график статистической функции распределения F*(x), то это будет изображенная справа ступенчатая фигура, которая позволяет получить представление о характере теоретической функции распределения F(x).
Для непрерывной случайной величины закон распределения задается в виде плотности распределения f(x). Вероятность попадания случайной величины в любой интервал (a, b) - это площадь под графиком плотности, опирающаяся на интервал (a, b) .
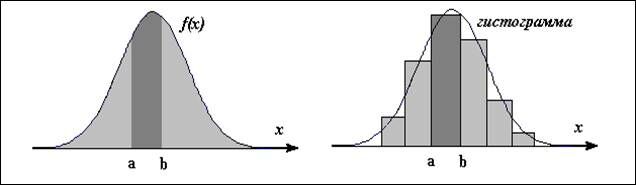
Если в эксперименте подсчитать относительную частоту w i попадания в разные интервалы и построить прямоугольники соответствующей площади, то полученная фигура (гистограмма) покажет нам , какой должна быть плотность распределения .
Общее замечание: В опытах мы получаем только часть информации о случайной величине. В выборку попадает только часть возможных значений случайной величины, и относительная частота дает только приблизительное значение вероятности. Значит и закон распределения мы получаем из опыта не точно, а приблизительно.
У любой случайной величины есть числовые характеристики:
· математическое ожидание, мода, медиана ;
· дисперсия, среднеквадратическое отклонение и т. д..
Их мы тоже можем определить по опытным данным и тоже только приблизительно. Числа, которые мы подсчитаем по опытным данным и возьмем вместо математического ожидания, дисперсии и т.д., называют точечными оценками параметров распределения.
Числовые характеристики выборки:
Выборочная средняя  .
.
Статистическая мода m o* - варианта с наибольшей частотой
Статистическая медиана m e* - варианта стоящая посередине вариационного ряда.
Статистические дисперсия Dв и среднеквадратическое отклонение sв (характеризуют разброс данных в выборке):

Удобнее пользоваться вспомогательной формулой :

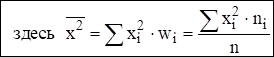
Точечные оценки параметров распределения :
Найденные числовые характеристики выборки используют для оценки параметров распределения.
Статистической оценкой для математического ожидания служит
выборочная средняя: 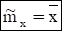
Статистической оценкой для дисперсии служит
исправленная выборочная дисперсия:
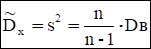
Статистической оценкой для среднеквадратического отклонения служит
исправленное выборочное среднеквадратическое отклонение:
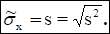
Интервальная оценка параметров распределения .
Точное значение математического ожидания, дисперсии и среднеквадратического отклонения мы найти по опытным данным в принципе не можем, так как в опытах мы получаем только часть информации о случайной величине.
При отыскании интервальных оценок определяется граница интервалов, между которыми с определенной долей вероятности можно предполагать, что там находится истинное значение изучаемого параметра.
Рекомендуем посмотреть лекцию "Государственные институты и их роль в формировании и реализации идеологии белорусского государства".
Когда вместо математического ожидания мы берем из опыта выборочную среднюю, мы допускаем погрешность. Оценить ее можно с помощью доверительного интервала . Выбирается интервал  и находится доверительная вероятность g - вероятность того, что истинное значение математического ожидания лежит в этом интервале. Имеются формулы, по которым для заданного g находят величину и положение доверительного интервала:
и находится доверительная вероятность g - вероятность того, что истинное значение математического ожидания лежит в этом интервале. Имеются формулы, по которым для заданного g находят величину и положение доверительного интервала:
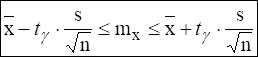

s (1-qg) £ s x £ s (1+qg)



















