
Последовательный статистический анализ
Власов М. П.
конспект лекций по дисциплине
Компьютерные методы статистического анализа и прогнозирование
ТЕМА 2 Последовательный статистический анализ
Содержание
стр.
1. Последовательный статистический анализ ……….……………..….. 2
2. Гамма-распределение ……………………………………………….. 12
3. Распределение и критерий Хи-квадрат …………………………….. 13
Рекомендуемые материалы
4. Непараметрические методы ……………………………………….. 17
5. Оценивание параметров и метод максимального правдоподобия ... 20
6. Стохастическая аппроксимация ……………………….………….… 27
Санкт-Петербург 2008
1. Последовательный статистический анализ
Последовательный статистический анализ это метод решения статистических задач, при котором необходимое число наблюдений не фиксируется заранее, а определяется в процессе эксперимента. Таким образом, характерной особенностью последовательного статистического анализа является тот факт, что число наблюдений (объём выборки) представляет собой случайную величину, зависящую от результатов наблюдений в том смысле, что решение об окончании или продолжении наблюдений принимается последовательно после каждого наблюдения. Одно из преимуществ последовательного статистического анализа в том, что во многих случаях для получения обоснованных выводов применение последовательного статистического анализа позволяет ограничиться значительно меньшим (в среднем) числом наблюдений, чем при способах, в которых число наблюдений фиксируется заранее. Определение необходимого числа наблюдений в рамках последовательного статистического анализа представляет собой одну из сторон задачи планирования эксперимента.
В наибольшей степени идеи последовательного статистического анализа нашли применение в теории статистических гипотез проверки (впервые последовательные методы проверки гипотез были использованы при контроле качества изделий).
Статистическая гипотеза это предположительное суждение о вероятностных закономерностях, которым подчиняется изучаемое случайное явление. Как правило, статистическая гипотеза определяет значения параметров распределения вероятностей или непосредственно его вид и свойства. Статистическая гипотеза называется простой, если она определяет единственный закон распределения; в ином случае статистическая гипотеза называется сложной и может быть представлена как множество простых статистических гипотез. Например, гипотеза о том, что распределение вероятностей, которому подчиняются данные результаты наблюдений, является нормальным распределением с математическим ожиданием  и дисперсией
и дисперсией  , будет сложной, составленной из
, будет сложной, составленной из  (
( и
и  - заданные числа).
- заданные числа).
Уровень значимости статистического критерия это вероятность ошибочно отвергнуть основную проверяемую гипотезу, когда она верна. В теории статистической проверки гипотез уровень значимости называется вероятностью ошибки первого рода. Понятие «уровень значимости» возникло в связи с задачей проверки согласованности теории с опытными данными. Если, например, в результате наблюдений регистрируются значения  случайных величин
случайных величин  и если требуется по этим данным проверить гипотезу
и если требуется по этим данным проверить гипотезу  , согласно которой совместное распределение величин обладает некоторым определённым свойством, то соответствующий статистический критерий конструируется с помощью подходящим образом подобранной функции
, согласно которой совместное распределение величин обладает некоторым определённым свойством, то соответствующий статистический критерий конструируется с помощью подходящим образом подобранной функции  . Эта функция обычно принимает одни (например, малые) значения, когда гипотеза верна, и другие (например, большие) значения, когда ложна.
. Эта функция обычно принимает одни (например, малые) значения, когда гипотеза верна, и другие (например, большие) значения, когда ложна.
При выборе уровня значимости следует учитывать ущерб, неизбежно возникающий при использовании любого критерия значимости. Так, например, если уровень значимости чрезмерно велик, то основной ущерб будет происходить от ошибочного отклонения правильной гипотезы; если же уровень значимости мал, то ущерб будет, как правило, возникать от ошибочного принятия гипотезы, когда она ложна. Практически при обычных статистических расчётах в качестве уровня значимости выбирают вероятность в пределах от 0,01 до 0,1. Значения уровня значимости, меньшие, чем 0,01, используются, например, при статистическом выявлении токсичных медицинских препаратов, а также в других особых случаях, когда первостепенное значение приобретает гарантия от ошибочного отклонения проверяемой гипотезы.
Проверка статистических гипотез это один из основных разделов математической статистики, объединяющий методы проверки соответствия статистических данных некоторой статистической гипотезе (гипотезе о вероятностной природе данных). Процедуры проверки статистических гипотез позволяют принимать или отвергать статистические гипотезы, возникающие при обработке или интерпретации результатов наблюдений во многих практически важных разделах науки и производства, связанных со случайным экспериментом. Правило, в соответствии с которым принимается или отклоняется данная гипотеза, называется статистическим критерием. Построение критерия определяется выбором подходящей функции  от результатов наблюдений , служащей мерой расхождения между опытными и гипотетическими значениями, Эта функция, являющаяся случайной величиной, называется статистикой критерия. При этом предполагается, что распределение вероятностей
от результатов наблюдений , служащей мерой расхождения между опытными и гипотетическими значениями, Эта функция, являющаяся случайной величиной, называется статистикой критерия. При этом предполагается, что распределение вероятностей  может быть вычислено при допущении, что проверяемая гипотеза верна, и что это распределение не зависит от характеристик гипотетического распределения. По распределению статистики находится критическое значение
может быть вычислено при допущении, что проверяемая гипотеза верна, и что это распределение не зависит от характеристик гипотетического распределения. По распределению статистики находится критическое значение  такое, что если гипотеза верна, то вероятность неравенства
такое, что если гипотеза верна, то вероятность неравенства  равна
равна  , где - заранее заданный уровень значимости (область значений
, где - заранее заданный уровень значимости (область значений  , для которых
, для которых  , область отклонения гипотезы
, область отклонения гипотезы  , называется критической областью). Если в конкретном случае обнаружится, что , то считается, что расхождение значимо, и гипотеза отвергается, тогда как появление значения
, называется критической областью). Если в конкретном случае обнаружится, что , то считается, что расхождение значимо, и гипотеза отвергается, тогда как появление значения  не противоречит гипотезе. Такого рода критерии, называемые критериями значимости, используются, как для проверки гипотез о параметрах распределения, так и гипотез о самих распределениях. В частном случае, когда проверяется согласие между выборочным и гипотетическим определениями, пользуются термином критерий согласия.
не противоречит гипотезе. Такого рода критерии, называемые критериями значимости, используются, как для проверки гипотез о параметрах распределения, так и гипотез о самих распределениях. В частном случае, когда проверяется согласие между выборочным и гипотетическим определениями, пользуются термином критерий согласия.
Пусть, например, проверяется гипотеза о том, что независимые результаты наблюдений подчиняются нормальному распределению со средним значением  при известной дисперсии . При этом арифметическая средняя
при известной дисперсии . При этом арифметическая средняя  результатов наблюдений распределена нормально с математическим ожиданием , и дисперсией
результатов наблюдений распределена нормально с математическим ожиданием , и дисперсией  , а величина
, а величина  распределена нормально с параметрами (0, 1). Полагая
распределена нормально с параметрами (0, 1). Полагая  можно найти связь между и
можно найти связь между и  по таблицам нормального распределения. Например, при гипотезе
по таблицам нормального распределения. Например, при гипотезе  событие Т> 1,96 имеет вероятность 0,05. Правило, в соответствии с которым гипотеза объявляется неверной при Т > 1,96, будет приводить к ложному отбрасыванию этой гипотезы в среднем в 5 случаях из 100, в которых она верна. Если же
событие Т> 1,96 имеет вероятность 0,05. Правило, в соответствии с которым гипотеза объявляется неверной при Т > 1,96, будет приводить к ложному отбрасыванию этой гипотезы в среднем в 5 случаях из 100, в которых она верна. Если же  1,96, то это ещё не означает, что гипотеза подтверждается, так как указанное неравенство с большой вероятностью может выполняться при , близких к . Следовательно, при использовании предложенного критерия можно лишь утверждать, что результаты наблюдений не противоречат гипотезе . Если дисперсия неизвестна, то вместо данного критерия для проверки гипотезы можно воспользоваться критерием Стъюдента, основанным_на статистике
1,96, то это ещё не означает, что гипотеза подтверждается, так как указанное неравенство с большой вероятностью может выполняться при , близких к . Следовательно, при использовании предложенного критерия можно лишь утверждать, что результаты наблюдений не противоречат гипотезе . Если дисперсия неизвестна, то вместо данного критерия для проверки гипотезы можно воспользоваться критерием Стъюдента, основанным_на статистике
,
которая включает несмещённую оценку дисперсии
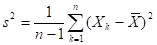
и подчинена распределению Стьюдента с  степенями свободы. Для проверки гипотезы о неизвестном значении используется критерий хи-квадрат. При выборе статистики всегда явно или неявно высказывают гипотезы, альтернативные проверяемой гипотезе.
степенями свободы. Для проверки гипотезы о неизвестном значении используется критерий хи-квадрат. При выборе статистики всегда явно или неявно высказывают гипотезы, альтернативные проверяемой гипотезе.
Например, при проверке гипотезы с известным вместо  следует взять
следует взять  , если заранее известно, что
, если заранее известно, что  , т. е. отклонение гипотезы влечёт принятие гипотезы
, т. е. отклонение гипотезы влечёт принятие гипотезы  .
.
При решении вопроса о принятии или отклонении какой-либо гипотезы с помощью любого критерия, основанного на результатах наблюдения, могут быть допущены ошибки двух типов. Ошибка «первого рода» совершается тогда, когда отвергается верная гипотеза . Ошибка «второго рода» совершается в том случае, когда гипотеза принимается, а на самом деле верна не она, а какая-либо альтернативная гипотеза  . Естественно требовать, чтобы критерий для проверки данной гипотезы приводил возможно реже к ошибочным решениям. Обычная процедура построения наилучшего критерия для простой гипотезы заключается в выборе среди всех критериев с заданным уровнем значимости (вероятность ошибки 1-го рода) такого, который имел бы наименьшую вероятность ошибки 2-го рода (или, что то же самое, наибольшую вероятность отклонения гипотезы, когда она неверна). Последняя вероятность (дополняющая до единицы вероятность ошибки 2-го рода) называются мощностью статистического критерия. В случае, когда альтернативная гипотеза , простая, наилучшим будет критерий, имеющий наибольшую мощность среди всех других критериев с заданным уровнем значимости (наиболее мощный статистический критерий). Если альтернативная гипотеза сложная, например, зависит от параметра, то мощность критерия будет функцией, определённой на классе простых альтернативных гипотез, составляющих , т. е. будет функцией параметра. Критерий, имеющий наибольшую мощность при каждой альтернативной гипотезе из класса , называется равномерно наиболее мощным статистическим критерием. Однако следует отметить, что такой критерий существует лишь в немногих специальных ситуациях. В задаче проверки простой гипотезы о среднем значении нормальной совокупности против сложной альтернативы гипотезы равномерно наиболее мощный критерий существует, тогда как при проверке той же гипотезы против альтернативы
. Естественно требовать, чтобы критерий для проверки данной гипотезы приводил возможно реже к ошибочным решениям. Обычная процедура построения наилучшего критерия для простой гипотезы заключается в выборе среди всех критериев с заданным уровнем значимости (вероятность ошибки 1-го рода) такого, который имел бы наименьшую вероятность ошибки 2-го рода (или, что то же самое, наибольшую вероятность отклонения гипотезы, когда она неверна). Последняя вероятность (дополняющая до единицы вероятность ошибки 2-го рода) называются мощностью статистического критерия. В случае, когда альтернативная гипотеза , простая, наилучшим будет критерий, имеющий наибольшую мощность среди всех других критериев с заданным уровнем значимости (наиболее мощный статистический критерий). Если альтернативная гипотеза сложная, например, зависит от параметра, то мощность критерия будет функцией, определённой на классе простых альтернативных гипотез, составляющих , т. е. будет функцией параметра. Критерий, имеющий наибольшую мощность при каждой альтернативной гипотезе из класса , называется равномерно наиболее мощным статистическим критерием. Однако следует отметить, что такой критерий существует лишь в немногих специальных ситуациях. В задаче проверки простой гипотезы о среднем значении нормальной совокупности против сложной альтернативы гипотезы равномерно наиболее мощный критерий существует, тогда как при проверке той же гипотезы против альтернативы  его нет. Поэтому часто ограничиваются поиском равномерно наиболее мощных критериев в тех или иных специальных классах (инвариантных, несмещённых и т. п. критериев).
его нет. Поэтому часто ограничиваются поиском равномерно наиболее мощных критериев в тех или иных специальных классах (инвариантных, несмещённых и т. п. критериев).
Теория проверки статистических гипотез позволяет с единой точки зрения трактовать задачи математической статистики, связанные с проверкой гипотез (оценка различия между средними значениями, проверка гипотезы постоянства дисперсии, проверка гипотез независимости, проверка гипотез о распределениях и т. п.). Идеи последовательного статистического анализа, применённые к проверке статистических гипотез, указывают на возможность связать решение о принятии или отклонении гипотезы с результатами последовательно проводимых наблюдений (в этом случае число наблюдений, на основе которых по определённому правилу принимается решение, не фиксируется заранее, а определяется в ходе эксперимента). Основные задачи проверки статистических гипотез могут быть сформулированы в рамках теории статистических решений.
Критерий Стьюдента это статистический критерий, основанный на распределении Стьюдента и используемый для проверки гипотез о средних значениях нормальных распределений.
Распределение Стьюдента ( - распределение с степенями свободы), распределение вероятностей случайной величины , заданное плотностью вероятности (рис.)
- распределение с степенями свободы), распределение вероятностей случайной величины , заданное плотностью вероятности (рис.)
 ,
,  ,
,
где  - гамма-функция. При
- гамма-функция. При  распределение Стьюдента совпадает с распределением Коши. Функция распределения Стьюдента выражается формулой
распределение Стьюдента совпадает с распределением Коши. Функция распределения Стьюдента выражается формулой
 .
.
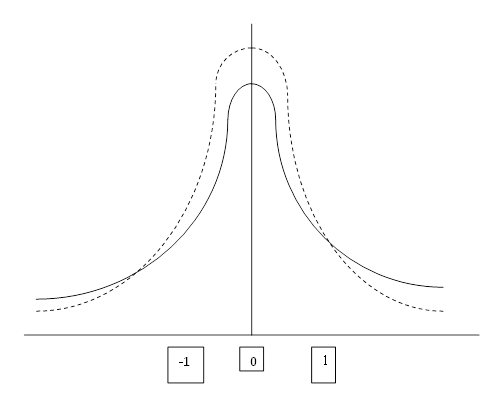
Рис. Плотность распределения Стьюдента при  . Пунктиром показана кривая нормальной плотности,
. Пунктиром показана кривая нормальной плотности,  ,
,  .
.
Распределение Стьюдента унимодально и симметрично относительно точки  . Все моменты порядка
. Все моменты порядка  конечны при
конечны при  ; при
; при  они равны 0, при
они равны 0, при  равны
равны
 .
.
Математическое ожидание  при
при  равно 0, дисперсия при
равно 0, дисперсия при  равна
равна
 .
.
Распределение Стьюдента с степенями свободы определяется как распределение отношения  независимых случайных величин
независимых случайных величин  и
и  , где подчиняется нормальному распределению с параметрами 0 и 1, а
, где подчиняется нормальному распределению с параметрами 0 и 1, а  имеет Хи - квадрат распределение с степенями свободы. Важная роль распределения Стьюдента в математической статистике объясняется следующим фактом: если случайные величины независимы и одинаково нормально распределены с
имеет Хи - квадрат распределение с степенями свободы. Важная роль распределения Стьюдента в математической статистике объясняется следующим фактом: если случайные величины независимы и одинаково нормально распределены с  и
и  , то при любых действительных и
, то при любых действительных и  отношение
отношение  , где
, где  и
и  подчиняется распределению Стьюдента с
подчиняется распределению Стьюдента с  степенями свободы. Это свойство было впервые использовано английским учёным У. Госсетом (псевдоним Стьюдент) при построении критерия для проверки гипотезы о том, что математическое ожидание нормального распределения равно заданному числу в случае, когда дисперсия неизвестна. В условиях этой задачи распределение Стьюдента используется также при построении доверительного интервала для неизвестного значения .
степенями свободы. Это свойство было впервые использовано английским учёным У. Госсетом (псевдоним Стьюдент) при построении критерия для проверки гипотезы о том, что математическое ожидание нормального распределения равно заданному числу в случае, когда дисперсия неизвестна. В условиях этой задачи распределение Стьюдента используется также при построении доверительного интервала для неизвестного значения .
И так рассмотрим критерий Стьюдента. Пусть результаты наблюдений - взаимно независимые нормально распределённые случайные величины с неизвестными параметрами а и а2. Для проверки гипотезы а = а0 в соответствии с критерием Стьюдента предлагается статистика
 ,
,
где
 ,
,  .
.
При условии, что гипотеза справедлива, статистика  имеет распределение Стьюдента с степенями свободы. Поэтому при заданном уровне значимости гипотеза принимается, если
имеет распределение Стьюдента с степенями свободы. Поэтому при заданном уровне значимости гипотеза принимается, если
 ,
,
где  находится из соотношения
находится из соотношения
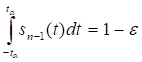
по плотности  распределения Стьюдента. В ином случае отклоняется в пользу альтернативной гипотезы . Если заранее известно, что
распределения Стьюдента. В ином случае отклоняется в пользу альтернативной гипотезы . Если заранее известно, что  , то гипотеза будет отклоняться в пользу гипотезы при
, то гипотеза будет отклоняться в пользу гипотезы при
 ,
,
где
 .
.
и приниматься в противоположном случае. При этом критерий Стьюдента будет равномерно наиболее мощным критерием уровня среди всех критериев проверки гипотезы относительно альтернативных гипотез .
Критерий Стьюдента используется также как критерий однородности двух нормальных выборок. Пусть и  - две последовательности взаимно независимых результатов наблюдений, причём величины
- две последовательности взаимно независимых результатов наблюдений, причём величины  имеют нормальное распределение с параметрами
имеют нормальное распределение с параметрами  и
и  , a Y- - нормальное распределение с параметрами
, a Y- - нормальное распределение с параметрами  и
и  . Гипотеза однородности формулируется как гипотеза равенства средних значений
. Гипотеза однородности формулируется как гипотеза равенства средних значений  . Если параметр неизвестен, то в качестве оценки общей дисперсии принимается
. Если параметр неизвестен, то в качестве оценки общей дисперсии принимается
 .
.
Тогда статистика
 ,
,
где
,  ,
,
 ,
,  ,
,
имеет распределение Стьюдента с  степенями свободы в предположении, что гипотеза справедлива. Соответствующий критерий Стьюдента строится стандартным образом.
степенями свободы в предположении, что гипотеза справедлива. Соответствующий критерий Стьюдента строится стандартным образом.
Впервые критерий Стьюдента был применён в 1908 английским учёным У. Госсетом, известным под псевдонимом Стьюдент.
Распределение Коши это распределение вероятностей случайной величины , заданное плотностью
 , ,
, ,
где  и
и  — параметры. Распределение Коши унимодально и симметрично относительно точки
— параметры. Распределение Коши унимодально и симметрично относительно точки  , являющейся модой и медианой этого распределения. Ни один из моментов положительного порядка, в т. ч. и математическое ожидание, не существует. Характеристическая функция распределения Коши имеет вид
, являющейся модой и медианой этого распределения. Ни один из моментов положительного порядка, в т. ч. и математическое ожидание, не существует. Характеристическая функция распределения Коши имеет вид
Бесплатная лекция: "2 Источники финансирования инвестиционных потребностей" также доступна.
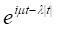
Произвольное распределение Коши с параметрами  и
и  выражается через (стандартное) распределение Коши с параметрами 0 и 1 формулой
выражается через (стандартное) распределение Коши с параметрами 0 и 1 формулой
 ,
,
где
 .
.
Сумма независимых случайных величин, подчинённых распределению Коши снова имеет распределение Коши. Следствием этого является замечательное свойство распределения Коши: если независимые случайные величины имеют одно и то же распределение Коши, то их арифметическое среднее имеет такое же распределение Коши с параметрами 0 и 1 может быть получено как распределение отношения X/Y двух независимых случайных величин X и , имеющих нормальное распределение с параметрами 0 и 1, или как распределение тангенса  случайной величины
случайной величины  , имеющей равномерное распределение на отрезке [
, имеющей равномерное распределение на отрезке [ ]. Распределение Коши было рассмотрено 0. Коши (1853), ранее - С. Пуассоном (ок. 1830).
]. Распределение Коши было рассмотрено 0. Коши (1853), ранее - С. Пуассоном (ок. 1830).



















