
Модели данных
Тема: Модели данных.
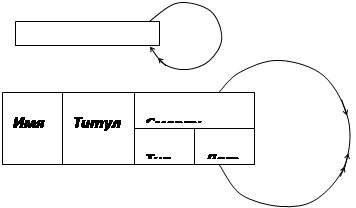
Совокупность данных, изображенных на рис. 7, описывается как двумерный (плоский) файл.
Каждая запись имеет одинаковый набор полей, и поэтому файл может быть представлен в виде двумерной матрицы. Типы структур могут быть представлены как деревья или сети.
1. Деревья.
Дерево представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел – корень.
Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемым исходным узлом для данного узла. Каждый узел, кроме корня, связан с одним или несколькими элементами на более низком уровне. Они называются порожденными. Элементы, расположенные в корце ветви, то есть не имеющие порожденных, называются листьями.
Дерево может быть определено как иерархия узлов с двойными связями, такими что:
1) самый верхний уровень иерархии имеет один узел, называемый корнем;
2) все узлы, кроме корня, связываются с одним и только одним узлом на более высоком уровне по отношению к ним самим.
Рекомендуемые материалы
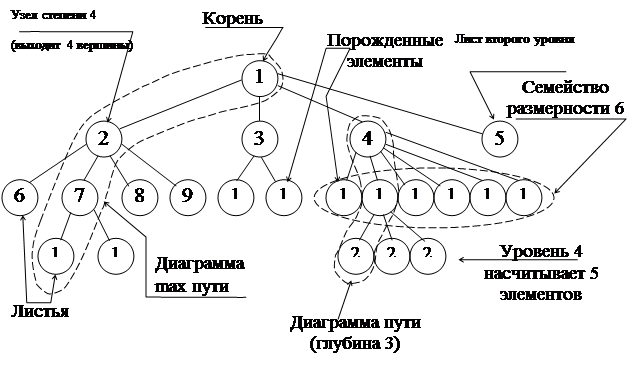 |
Рис. 16
Диаграмма дерева имеет высоту 4(число уровней), момент 22(число узлов), вес 16(число листьев), основание 1(число корней).
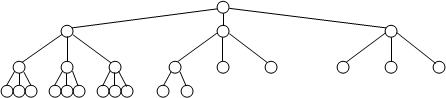
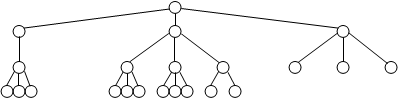
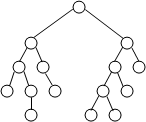
Сбалансированное дерево – дерево, в котором каждый узел имеет одинаковое число ветвей, причем процесс включения новых ветвей в узлы дерева идет сверху вниз, а на каждом уровне дерева – слева направо. На рис. 17 приведены примеры сбалансированных и несбалансированных деревьев.
 |
Сбалансированное дерево
 | |||
 |
Несбалансированные деревья
Рис.17
Древовидная структура, в которой допускается не более двух ветвей для одного узла, называется двоичным деревом.
Двоичные деревья, как и другие сбалансированные деревья представляют основной интерес для физического, а не логического представления данных.
2. Иерархическим файлом называется файл, в котором записи связаны в виде древовидной структуры. На рис. 18 приведен файл типа «основная запись – детальная запись», представляющая собой общий вид иерархического файла с двумя типами записей.
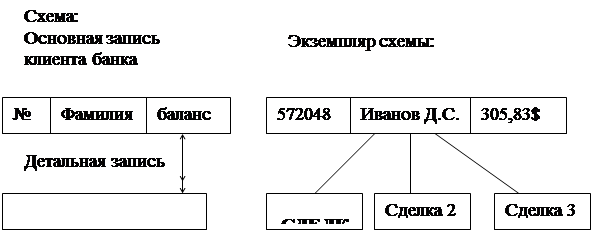
Рис.18
Однородные структуры – структуры у которых каждый узел дерева может быть представлен одним и тем же типом записи.
Иерархическая модель данных лежит в основе таких СУБД, как Ока и ИНЕС.
Иерархическая модель данных ИНЕС представляет БД в виде дерева, терминальные вершины которого соответствуют элементарным данным, корень – всей БД, а прочие вершины – структурным информационным объектам различной сложности. Такое дерево отражает логическую структуру информации и называется ИНЕС деревом БД. Но реальные данные содержатся только в терминальных вершинах. Посредством использования ссылочных связей модель допускает создание сетей и потенциально бесконечных деревьев. Дерево БД, помимо собственно данных, содержит также информацию о структуре, типах и именах информационных объектов, повторяющуюся для многих однородных объектов. Эта информация задается администратором БД в виде схемы БД на ЯОД и преобразуется соответствующим транслятором в дерево описания данных. Данные, представленные в БД присутствуют в двух частях ДОД и дереве данных, содержащем, собственно, значения данных.
В системе ИНЕС существует три категории типов данных:
· Элементарные;
· Структурные;
· Ссылочные.
Категория элементарных данных состоит из шести родовых типов, параметр каждого из которых определяет количество байтов памяти, отводимой под представление одного значения. Элементарные данные находятся в терминальных вершинах ДД. К простым типам относятся: целый, вещественный, десятичный, символьный и двоичной последовательности, и перечислений. В ИНЕС существует два основных типа структурных данных: структуры и массивы. Структура может быть собственно структурой или условной структурой (объединением), массив может быть простым массивом (аналог последовательного файла), массивом с номерами (аналог файла с прямым доступом) или массивом с ключами (индивидуально – последовательные файлы). В ИНЕС имеется четыре вида ссылочных данных: ссылка на значение, ссылка на шаблон, ссылка на словарное данное типа идентификатор и типа код.
Данное типа ссылки на значение является указателем на другое данное (аналог указателя Си).
Ссылка на шаблон означает, что данное, описанное посредством такой ссылки, имеет тот же тип, что и данное, на которое делается ссылка, при этом соответственно совпадают типы всех подчиненных им данных (аналог определения типа Паскаль).
Данному со ссылкой на словарное данное типа идентификатор ставится в соответствие набор данных, называемых словарем типа идентификатор.
В ДД записывается только крайний идентификатор, а текст и соответствующий ему идентификатор в словарь.
В дополнение к словарям типа идентификатор могут существовать словари типа код. Эти данные имеют форму: код – текст – синонимы. Пример: шифр предприятия – полное наименование предприятия – краткое наименование предприятия.
Сетевые структуры.
Если порожденный элемент в отношении между данными имеет более одного исходного элемента, то это отношение описывают в виде сетевой структуры.
Любой элемент в сетевой структуре может быть связан с любым другим элементом. На рисунке 19 приведены примеры сетевых структур.
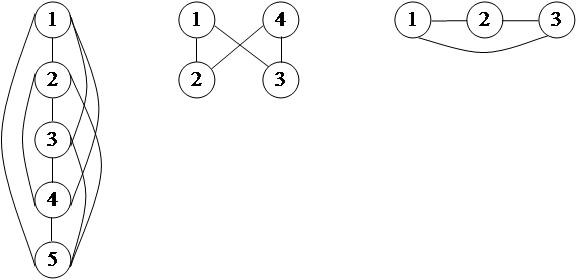 |
Рис.19
В первом примере самый нижний узел имеет четыре исходных. Во втором примере на рисунке 19 каждый порожденный элемент имеет два исходных. В третьем примере не указано направление отношений, но какой бы узел не был самым нижним, у него будет два исходных.
Структура на одной из линий схемы, которой сдвоенные стрелки, указывающие в разные стороны, называется сложной сетевой структурой, а схему, в которой ни на одной из линий нет сдвоенных стрелок, в обоих направлениях – простой сетевой структурой. На рисунке 20 показана простая сетевая структура.
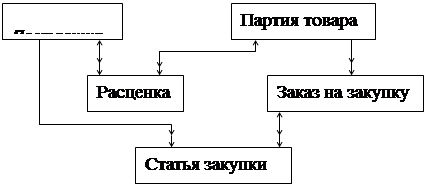 |
Рис.20
Для существования сложной сетевой структуры достаточно двух типов записей. На рисунке 21 пример, в котором запись Поставщик может иметь несколько порожденных, потому что поставщик может поставлять более одного вида товара.
Запись Партия_товара может иметь более одной исходной записи, так как этот товар может поставляться различными поставщиками.
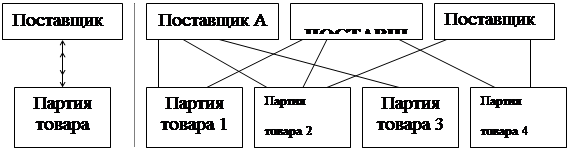 |
Рис.21
Ситуация, в которой предшественник узла является в то же время его последователем, называются циклом. Отношения исходный – порожденный образуют при этом замкнутый контур. Например, завод выпускает различную продукцию. Некоторые изделия производятся на других заводах. С одним контрактом может быть связано производство нескольких изделий. Представление этих отношений и образует цикл (рисунок 22). Но не все СУБД способны представлять циклы. Специальным типом цикла является цикл, состоящий из одного только типа записи, то есть тип порожденной записи совпадает с типом исходной записи. Эта ситуация называется петлей.
Генеалогическое дерево можно представить схемой, приведенной на рисунке 23. Большинство других однородных структур можно упростить аналогично, но в большинстве СУБД петли не допускается.
 | |||
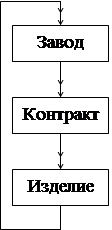 | |||
Рис.22 Рис. 23
Представление однородного дерева простой схемой с петлями.
Сетевая структура может быть приведена к более простому виду введением избыточности.
Любую простую сетевую структуру можно представить с помощью дерева или множества деревьев с избыточными элементами. Каждое отношение со сложными связями в обоих направлениях должно быть заменено двумя древовидными структурами. Дублирование блоков не вызовет избыточности на уровне физического хранения данных (рисунок 24).
 Интерес к тому, представлены ли отношения сетевыми или древовидными структурами, объясняется тем, что большинство способов физического размещения данных, являющихся эффективными для деревьев, оказываются неэффективными для сетевых структур. Поэтому одни СУБД работают с сетевыми структурами, а другие – только с древовидными. Именно способы физической организации данных определяют ограничения на типы допустимых схем.
Интерес к тому, представлены ли отношения сетевыми или древовидными структурами, объясняется тем, что большинство способов физического размещения данных, являющихся эффективными для деревьев, оказываются неэффективными для сетевых структур. Поэтому одни СУБД работают с сетевыми структурами, а другие – только с древовидными. Именно способы физической организации данных определяют ограничения на типы допустимых схем.
 | |||||
| |||||
 |
Преобразование сети с рис. 21
Рис. 24
Реляционные БД.
Избежать растущей сложности древовидных и сетевых структур можно с помощью метода, называемого нормализацией отношений. Этот метод был разработан Коддом. Принципы, которые применял Кодд при разработке БД относятся к представлению данных пользователем или к логическому описанию данных. Существует много способов отображения БД Кодда на физическом носителе.
В принципе, требуется найти такой способ описания данных, который 1) понятен пользователю, не имеющему особых навыков в программировании; 2) позволяет подсоединять новых пользователей без изменения существующей логической структуры и ПП-й; 3) допускает максимальную гибкость при формировании непредсказуемых или случайных запросов с терминалов.
Один из самых естественных способов представления данных для пользователя непрограммиста – это двумерная таблица (рисунок 7). Она привычна для пользователя, понятна и обозрима, ее легко запомнить. Поскольку любая сетевая структура может быть разложена в совокупность древовидных структур (рисунок 24), то и любое представление данных может быть сведено к двумерным плоским файлам (тоже с некоторой избыточностью). Этот процесс представления данных в форме двумерных таблиц, выполняемый шаг за шагом для каждого отношения между данными в базе называется нормализацией. Таблицы могут быть построены таким образом, что не будет утеряна информация об отношениях между элементами данных. Рассматриваемая таблица – это прямоугольные массивы, которые можно описать математически. Таблица обладает следующими свойствами:
1. каждый элемент таблицы представляет собой один элемент данных, повторяющиеся группы отсутствуют;
2. все столбцы в таблице однородные, то есть элементы столбца имеют одинаковую природу;
3. столбцам однозначно присвоены имена;
4. в таблице нет двух одинаковых строк;
5. в операциях с такой таблицей ее строки и столбцы могут просматриваться в любом порядке и в любой последовательности безотносительно к их информационному содержанию и смыслу.
Таблица такого вида, как на рисунке 7 называется отношением. БД, построенная с помощью отношений называются реляционной БД.
Отношение, или таблица – это набор кортежей. Если кортежи являются n – мерными, то есть, если таблица имеет n столбцов, отношение называется отношением степени n, или n – арным отношением.
Набор значений элементов данных одного типа, то есть один столбец таблицы, называется доменом.
Столбец с номером j называется j – м доменом отношения.
Кодд разработал специальный ЯМД для такой БД. В этом языке может быть выражен обычный диалог человека с машиной. В нем есть возможность извлекать подмножества столбцов таблицы для одних пользователей, создавая таблицы меньшей размерности, а также объединять таблицы для других пользователей, создавая таблицы большей размерности. Язык Кодда содержит обе эти операции разрезания и склеивания таблицы, поэтому он обладает гибкостью, которой лишено большинство древовидных и сетевых структур.
Каждый кортеж должен иметь ключ – идентификатор. Ключ должен обладать двумя свойствами:
А) Однозначная идентификация кортежа: кортеж должен однозначно определяться значением ключа.
Б) Отсутствие избыточности: никакой атрибут нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации.
Для кортежей одного отношения может существовать несколько наборов атрибутов, удовлетворяющих этим свойствам. Такие наборы называются возможными ключами. Тот ключ, который фактически будет использоваться для идентификации записей, называется основным или первичным ключом. Для основного ключа атрибуты следует выбирать так, чтобы для них был заранее известен диапазон значений, а их количество было бы как можно меньше.
На рисунке 26 показано четырехуровневое дерево, и оно же приведено в виде шести отношений, ключ некоторого отношения может содержать ключ отношения, соответствующего вышестоящей вершине.
Схема БД древовидной структуры.
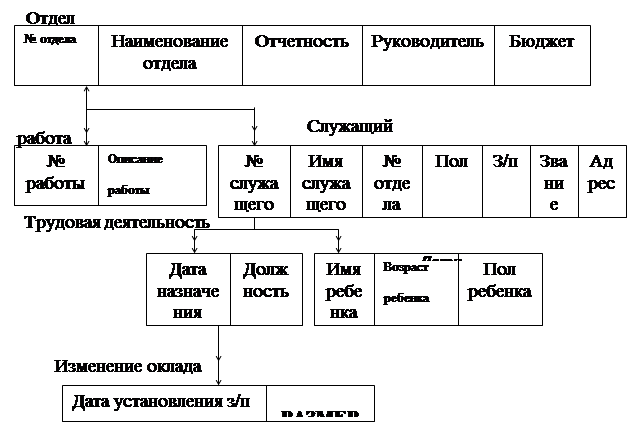 |
Нормализованная форма схемы:
Отдел (№_отдела, название_отдела, отчетность, руководитель, бюджет),
Информация в лекции "18. Освещение в СМИ ВК и ГП" поможет Вам.
Работа (№_отдела, №_работы, описание_работы),
Служащий (№_служащего, имя_служащего, №_отдела, пол, з/пл, звание, адрес),
Изменение оклада (№_служащего, дата_установления_з/пл, размер_з/пл),
Дети (№_служащего, имя_ребенка, возраст_ребенка, пол_ребенка),
Трудовая деятельность (№_служащего, дата_назначения, должность).
Рис. 26


















