
Лекция 3
1.1.3 Модели знаний на основе продукций
В модели знаний на основе продукций знания представлены совокупностью правил в формате "ЕСЛИ - ТО". Рассмотрим, например, правила порождения родительного падежа слов, задаваемые таблицей 1.1.
Для того, чтобы получить родительный падеж слова "Знахарь" отыскиваем первую подходящую строку, начиная с верхней, в левом колонке табл.1.1. Строка будет подходящей, если указываемое в ней окончание совпадает с окончанием слова (в данном случае выбирается строка 5). Нетрудно, однако видеть, что строка 6 также подходит для нашей цели, хотя выдаваемый ею результат (правая колонка табл. 1.1.) не верен. Прежде чем мы рассмотрим более подробно это свойство системы продукций, выясним их природу. Рассматривая структуру продукции, нетрудно видеть, что ее условная часть ("ЕСЛИ...") определяет ситуацию, в которой продукция применима. В примере со словом " знахарь" ситуация определяется его окончанием, т.е. либо окончанием "арь", либо ''-ь".
Таблица 1.1.
| № п/п | Слово или его окончание в именительном падеже | Слово или его окончание в родительном падеже |
| 1. | кино | Рекомендуемые материалыВопросы и ответы из теста по 1С Платформе 8.3. -82% Создать проект Win32, в окне нарисовать самолет, у которого крылья будут синего цвета, иллюминаторы – белые, хвост - зеленый. С помощью элемента управления – кнопки1 – отображать рисунок на экране, с помощью кнопки2 – очищать окно от рисунка, с помощ FREE Методические пособия по C++ Г.С.Иванова 3 части РК3 билеты (РК6) Вариант 1 - Отчёт по практике №3 ЛР1 - 30В Отчет+код -кино |
| 2. | -ча | -чи |
| 3. | -ка | -ки |
| 4. | -а | -ы |
| 5. | -арь | -аря |
| 6. | -ь | -и |
| 7. | -ие | -ия |
| 8. | -мя | -мени |
| 9. | -я | -и |
Если ситуация удовлетворяет продукции, то в результате ее применения может быть получен новый объект (состояние) согласно части " ТО ... " в структуре продукции. Так, применение продукции с номером 5 в табл.1.1. к слову "знахарь" порождает слово "знахаря", а применение продукции номер 6 дает слово "знахари". Таким образом, одним из основных вопросов в реализации продукционных систем является стратегия выбора альтернативных правил. В общем случае эта проблема нетривиальна. Условная часть продукции может иметь различные формы, такие например, как в следующих примерах:
² ЕСЛИ (идет - дождь) ²;
² ЕСЛИ (a > b2 - b) ²;
² ЕСЛИ (P C Q) ².
В структуре продукции дополнительно могут указываться метка и строка, содержащая объяснение применения продукции. Метка может быть простым идентификатором (или номером) или некоторым пояснительным текстом, например, "определение окраски инфекции по Граму" Строка-объяснение показывает, почему используется продукция. Следующий пример демонстрирует полную продукцию:
МЕТКА: R26 Использование зонтика
УСЛОВИЕ: ЕСЛИ (идет дождь)
ДЕЙСТВИЕ: ТО (возьмите зонтик)
ОБЪЯСНЕНИЕ: (зонтик предохраняет от дождя)
Как правило, задача, формулируемая для продукционной системы, имеет одну из следующих структур
<S0, Sf - ?> (1.5)
<S0 - ?, Sf> (1.6)
<S0, Sf, A - ?> (1.7)
<S0, Sf - ?, A - ?> (1.8)
где: S0 - начальная ситуация
Sf - конечная (желаемая, требуемая ситуация)
А - алгоритм (последовательность выполняемых продукций), переводящий систему из состояния S0 в состояние Sf
Задача (1.5) связана с определением ситуации (состояния) Sf, удовлетворяющей некоторому критерию, которая может быть получена из заданной начальной ситуации.
Задача (1.6) является обратной по отношению к предыдущей.
Задача (1.7) заключается в отыскании алгоритма преобразования начальной ситуации в конечную.
Задача (1 .8) представляет обобщение задач (1 .5) и (1 .7).
Продукции удачно моделируют человеческий способ рассуждений при решении проблем. Поэтому продукции широко используются во многих действующих ЭС. Система MYCIN, фрагмент которой приведен во введении, а также ее более поздняя редакция EMYCIN являются примерами продукционных систем.
Продукционные системы впервые изобретены Постом в 1941г. Продукция в системе Поста имеет следующую схему
 (1.9)
(1.9)
где t1, t2, ..., tn называются посылками, а t заключением продукции.
Применение схемы (1.9) основывается на подстановке цепочек знаков вместо всех переменных, причем вместо вхождений одной и той же переменной подставляется одна и та же цепочка.
В качестве других классических продукционных систем отметим нормальные алгоритмы Маркова и машину Тьюринга.
Развитием модели на основе правил является модель "доски объявлений". Эта модель реализована в системе распознавания разговорной речи HEARSAY - 2. Основной принцип организации модели доски объявлений заключается в разбиении продукций по уровням иерархии. При этом заключения продукций на нижних уровнях используются как входные условия для продукций более высокого уровня. На самом нижнем уровне модели доски объявлений представлены факты, на самом верхнем - результирующее заключение.
Иерархическое разбиение множества продукций позволяет более эффективно организовать их выполнение, существенно сократив затраты на перебор множества продукций при проверке условий их срабатывания, что определяет дополнительный интерес к продукционным системам.
В рамках этой модели продукция определяется четверкой:
P = < L, C, N, A >,
где L – метка;
С – условие применимости;
N – ядро продукции, описываемое формулой (1.9);
А – постдействие.
В качестве примера составления системы продукций рассмотрим задачу распознавания символов, в которой введем следующие упрощения: будут исследованы прописные буквы Кириллицы. В примере будем использовать структурный метод. Этот метод заключается в структуризации всех символов по определенным признакам.
Приведем алфавит:
 G1: А И Х
G1: А И Х
 G2: Б З Р Ы Ь Я В
G2: Б З Р Ы Ь Я В
G3: С О Э Ю
 G4: Е Н П Т Ш Г
G4: Е Н П Т Ш Г
 G5:
G5:
G6: Ц Ъ Щ
Данный алфавит был разделен на группы, исходя из внутреннего строения каждого символа.
Таким образом получено следующее множество:
f1’ – вертикальные наклонные (отвесные) прямые;
f2’ – горизонтальные прямые;
f3’ – полуовалы;
f4’ – большие овалы;
f5’ – вертикальные прямые;
f6’ – короткие вертикальные наклонные отрезки;
 f7’ – хвостики.
f7’ – хвостики.
Данная продукция может быть представлена в виде:
P = < L, C, N, A >, где L=L1, а С – условие применимости данного шрифта.
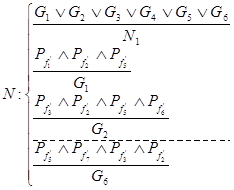
Постдействие А определяет процедуру, которая может либо вызывать продукцию для определения буквы найденного класса, либо выставлять на доску объявлений сообщения о том, что найдена группа, которой принадлежит исследуемая буква и передается номер этой буквы.
На языке Prolog такая продукция выглядит так:
N1:–G1;G2;G3;G4;G5;G6.
G1:–Pf1’, Pf2’, Pf5’.
……………
Для распознавания буквы в группе можно все факты представить следующим образом:
f1 – кривая замкнутая полная (на высоту кадра);
f2 – кривая с левосторонней выпуклостью;
f3 – кривая с правосторонней выпуклостью;
f4 – кривая верхняя с правосторонней выпуклостью;
f5 – кривая верхняя с левосторонней выпуклостью;
f6 – кривая нижняя с правосторонней выпуклостью;
f7 – кривая нижняя с левосторонней выпуклостью;
f8 – вертикальный левый отрезок;
f9 – вертикальный правый отрезок;
f10 – вертикальный центральный отрезок;
f11 – вертикальный левый верхний отрезок;
f12 – вертикальный левый нижний отрезок;
f13 – вертикальный правый верхний отрезок;
f14 – вертикальный правый нижний отрезок;
f15 – вертикальный центральный верхний отрезок;
f16 – вертикальный центральный нижний отрезок;
f17 – вертикальный отрезок с углом наклона менее 90°;
f18 – вертикальный отрезок с углом наклона более 90°;
f19 – вертикальный верхний отрезок с углом наклона менее 90°;
f20 – вертикальный верхний отрезок с углом наклона более 90°;
f21 – вертикальный нижний отрезок с углом наклона менее 90°;
f22 – вертикальный нижний отрезок с углом наклона более 90°;
f23 – горизонтальный верхний отрезок;
f24 – горизонтальный нижний отрезок;
Если Вам понравилась эта лекция, то понравится и эта - 9. Итальянская журналистика в 1948 - 53.
f25 – горизонтальный центральный отрезок;
f26 – хвостик.
Рассмотрим символы из второй группы.
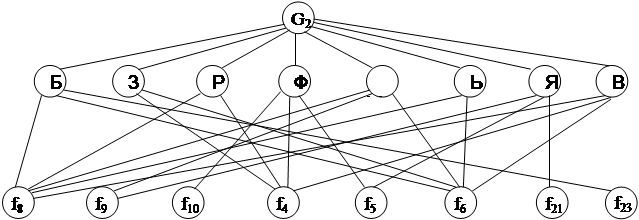 |
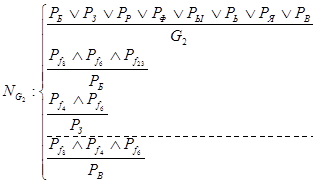
Постдействием для такой продукции будет процедура помещения распознанной буквы в какую-либо базу данных.




















