
Анализ различий
Глава 3 Анализ различий
Цель анализа различий — выявление групп респондентов, статистически значимо различающихся между собой. Все статистические процедуры, относящиеся к группе процедур, которые позволяют выявить такие различия (t-тесты и дисперсионный анализ), сравнивают респондентов на основании средних значений переменных. Иными словами, провести различие можно на основании двух или более числовых переменных.
В практике маркетинговых исследований достаточно часто встречаются ситуации, когда в ходе предварительного анализа (на основании опыта исследователя, когнитивного или статистического анализа) появляется гипотеза о разделении всей выборочной совокупности на определенные группы на основании одного или нескольких признаков (например, при сегментировании потребителей продукта или при построении разрезов). Линейное распределение может показывать, что данные группы респондентов действительно различаются (например, мужчин в выборке в два раза больше, чем женщин). Однако визуального различия между категориями недостаточно для того, чтобы с уверенностью констатировать наличие статистически значимого различия. На установление статистической значимости различий между целевыми группами респондентов и направлены процедуры, объединенные под названием «Анализ различий».
Существует два основных метода определения различий между группами: t-тесты и дисперсионный анализ. Первый метод прост в использовании, и поэтому он применяется часто (в том числе и в маркетинговых исследованиях). Однако в связи с ограничением на количество тестируемых групп (между которыми устанавливается различие) t-тесты не могут применяться для решения всех задач, возникающих при проведении маркетингового анализа. Для преодоления данного ограничения используется дисперсионный анализ, являющийся универсальной методикой для определения статистически значимых различий между любым числом групп респондентов.
3.1. Т-тесты
Т-тесты предназначены для установления различий между двумя группами респондентов. При этом сравниваются только два средних значения. SPSS предлагает три основных типа t-тестов:
Рекомендуемые материалы
■ для двух независимых выборок;
■ для двух зависимых выборок;
■ для одной выборки.
В последующих разделах мы подробно расскажем о каждом из них, но сначала приведем основные характеристики переменных, участвующих в t-тестах (табл. 3.1).
| Т-тесты для независимых выборок | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| Одна | Дихотомическая интервальная | Любое | Интервальная |
| Т-тесты для зависимых выборок | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| - | - | Две | Интервальная |
| Т-тесты для одной выборки | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| - | - | Любое | Интервальная |
Обратите внимание: зависимая переменная есть только для t-тестов независимых выборок. Для других видов t-тестов (зависимых выборок и одной выборки) зависимая переменная отсутствует. Это связано с тем, что в последнем случае анализу подвергается фактически одна и та же выборка респондентов. В качестве тестируемых независимых переменных во всех случаях используются только переменные с интервальной шкалой. Порядковые переменные могут использоваться только после преобразования их к интервальному виду (см. раздел 2.1).
3.1.1. Т-тесты для независимых выборок
В случае t-тестов для независимых выборок под независимыми выборками понимаются бинарные категории (то есть варианты ответа) какой-либо переменной. Например, мужчины и женщины (вопрос Пол респондента), покупатели и не покупатели какого-либо продукта (вопрос Покупаете ли Вы данный продукт?) и т. д. То есть когда есть два уровня группирующей (зависимой) переменной и несколько независимых переменных, на основании которых и будет выполняться различие между группами зависимой переменной.
Рассмотрим методику проведения t-тестов для независимых выборок на следующем примере. Предположим, что мы оцениваем различия в частоте посещения игровых клубов между посетителями заведений марки X и других марок. Откройте диалоговое окно Independent-Samples T Test при помощи меню Analyze ► Compare Means ► Independent-Samples T Test (рис. 3.1). В область Test Variable(s) поместите переменные, являющиеся критерием для установления различий (в нашем случае это ql8_i Частота посещения). Затем в поле Grouping Variable переместите переменную, которая будет являться группирующей (зависимой). В нашем случае это переменная ql_8, кодирующая категории респондентов, посещающих/не посещающих игровые залы марки X.
 |
 |
Так как данная переменная является вариантом ответа на многовариантный вопрос Какие игровые клубы Вы посещаете?, она может принимать два значения:
■ 1 — посещают клубы X;
■ 0 — не посещают клубы X.
 |
Эти два значения необходимо указать в специальном диалоговом окне Define Groups, вызываемом одноименной кнопкой (рис. 3.2). Обратите внимание, что если вместо дихотомии мы имеем группирующую переменную с интервальной шкалой, это диалоговое окно позволяет установить точку отсечения Cut point, которая буде! разделять все возможные значения данной переменной на две группы.
 |
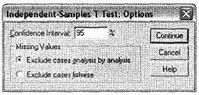
С помощью кнопки Options в главном диалоговом окне рассматриваемой процедуры можно установить доверительный уровень для результатов расчета t-теста (рис. 3.3). По умолчанию установлен уровень доверия 95 %. Как было показано выше в разделе 1.2, этот уровень точности (достоверности) результатов является достаточным при проведении статистического анализа в маркетинговых исследованиях.
 |
 |
После завершения процедуры расчета t-теста в окне SPSS Viewer будут отражены результаты (рис. 3.4). В первой таблице Group Statistics вы видите средние значения тестируемой переменной (частота посещения клубов) для обеих групп зависимой переменной X. Как следует из рисунка, для респондентов, посещающих игровые залы марки X, средняя частота посещения составляет 11,9 раз в месяц. Для респондентов, не посещающих данные залы, это значение равно 11,5. Вторая таблица Independent Samples Test позволяет установить статистическое различие между данными значениями.
 T-Test
T-Test
| X | N | Mean | Std. Deviation | Std. Emor Mean | |
| Частота посещения | 1 | 49 | 11,9288 | 10,43081 | 1,49140 |
| 0 | 526 | 11,5048 | 9,98682 | ,43546 |
| Levene’s Test for Equality of Variances | t-test for Equality of Means | |||||||||
| F | Sug. | t | df | Sig. (2-talid) | Mean Difference | Std. Emor Difference | ||||
| Lower | Upper | |||||||||
| Частота посеще-ния | Equal variances assumed | ,382 | ,547 | ,283 | 573 | ,777 | ,4238 | 1,49745 | -2,61734 | 3,36497 |
| Equal variances not assumed | ,273 | 56,495 | ,786 | ,4230 | 1,55367 | -2,68795 | 3,51559 |

Анализ этой таблицы начинается с определения значимости теста Ливина (Levene). Данный тест служит для тестирования гипотезы о равенстве дисперсий в тестируемых переменных. Если значение в столбце Sig. столбца Levene's Test for Equality of Variances показывает статистическую незначимость теста (в нашем случае — 0,547), то различие между двумя анализируемыми средними определяется из строки Equal variances assumed. В противном случае, если тест Levene статистически значим, различие между двумя средними определяется из строки Equal variances not assumed.
Поскольку в нашем примере тест Ливина является статистически незначимым, то определить значимость различия между двумя тестируемыми группами можно при помощи значения, находящегося на пересечении первой строки и столбца Sig. (2-tailed). Значение 0,777 говорит о том, что различие в частоте посещения игровых залов респондентами, посещающими и не посещающими клубы марки X, является статистически незначимым.
3.1.2. Т-тесты для спаренных выборок
Т-тесты для спаренных выборок применяются в случае, когда на различные вопросы отвечает одна и та же группа респондентов.
Например, пассажиры оценивают уровень и качество питания авиакомпании X и авиакомпании Y. Чтобы определить, является ли статистически значимой разница в оценке этих двух авиакомпаний, следует воспользоваться диалоговым окном Paired-Samples T Test, вызываемым при помощи меню Analyze ► Compare Means ► Paired-Samples T Test (рис. 3.5). В левом списке содержатся все доступные переменные из базы данных. Выберите из списка две переменные для тестирования. В нашем случае это qll (Питание в авиакомпании X) и q26 (Питание в авиакомпании Y). По мере того как вы будете выбирать переменные, они будут последовательно отображаться в области Current Selections. Указав две переменные для анализа, щелкните на кнопке с символом ► , чтобы перенести переменные в область Paired Variables. Кнопка Options позволяет установить уровень доверия для производимых расчетов.
 |
 |
После щелчка на кнопке ОК будут произведены расчеты t-теста для анализируемых переменных; результаты теста будут отражены в окне SPSS Viewer (рис. 3.6). Как видно на рисунке, SPSS выводит на экран три таблицы. Рассмотрим их по порядку.
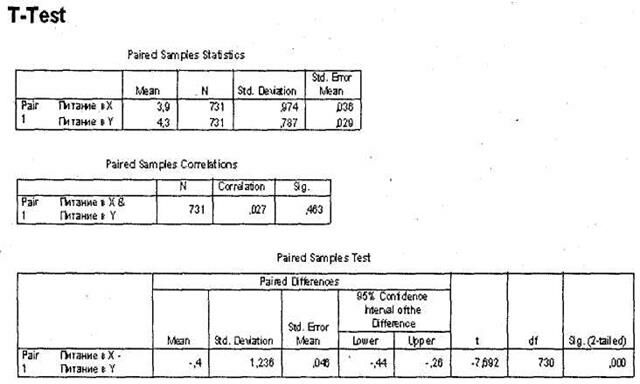
Итак, в первой таблице, Paired Samples Statistics, вы видите рассчитанные средние значения для обеих тестируемых переменных. Так, в нашем случае респонденты оценили питание в авиакомпании Y в среднем на 0,4 балла выше, чем в авиакомпании X.
В следующей таблице Paired Samples Correlations представлен коэффициент корреляции (Пирсона) между оценками двух анализируемых переменных. Подробно корреляционный анализ рассматривается в разделе 4.2. Здесь стоит сказать лишь, что чем ближе значение коэффициента к 1, тем сильнее линейная связь между переменными (при условии статистической значимости коэффициента). То есть чем выше уровень оценки по первой переменной, тем выше оценка второй — и наоборот. В нашем случае налицо отсутствие линейной связи между оценками питания в авиакомпании X и Y (коэффициент корреляции = 0,027 при статистической значимости 0,463).
 T-Test
T-Test
| Mean | N | Std. Devition | Std. Emor Mean | ||
| Pair | Питание в X | 3,9 | 731 | ,974 | ,036 |
| 1 | Питание в Y | 4,3 | 731 | ,787 | ,029 |
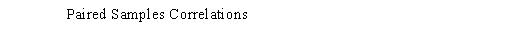
N | Correlation | Sig. | ||
| Pair | Питание в X & | 731 | ,027 | ,463 |
| 1 | Питание в Y |
| Paired Diffirences | t | df | Sig. (2-tailed) | ||||||
| Mean | Std. Devition | Std. Emor Mean | 95% Confidence interval of the Difference | ||||||
| Lower | Upper | ||||||||
| Pair | Питание в X & | -,4 | 1,236 | ,046 | -,44 | -,26 | -7,692 | 730 | ,000 |
| 1 |
|
 Питание в Y
Питание в YНаконец, третья таблица, Paired Samples Test, позволяет сделать вывод о наличии/ отсутствии статистически значимого различия между тестируемыми переменными, что следует из значения в столбце Sig. (2-tailed). В нашем случае различие между оценками питания в авиакомпаниях X и Y, равное 0,4 балла, является статистически значимым (<0,001).
3.1.3. Т-тесты для одной выборки
В результате t-теста для одной выборки можно выяснить, отличается ли значительно реальное среднее значение какой-либо переменной от стандарта. В маркетинговых исследованиях при помощи данного теста определяют, отличается ли среднее значение какого-либо параметра для определенной целевой группы респондентов от среднего значения по всей выборке.
Например, питание на борту самолетов авиакомпании X (переменная qll) всеми респондентами оценено в среднем на 4,0 балла. Вместе с тем пассажиры первого класса оценили питание несколько выше: в среднем на 4,1 балла. Возникает вопрос, является ли выявленное различие статистически значимым. То есть отличаются ли пассажиры первого класса от всех респондентов на основании уровня оценки питания на борту? Выяснить это нам поможет t-тест для одной выборки. Ниже описан механизм его проведения.

 |
Для проведения t-теста мы должны отобрать только тех респондентов, которые летают первым классом. (Как это сделать, см. в разделе 1.5.1.1.) После этого следует воспользоваться меню Analyze ► Compare Means ► One-Sample T Test, чтобы открыть диалоговое окно One-Sample T Test (рис. 3.7). Далее перенесите из левого списка всех доступных переменных в область Test Variable(s) интересующую нас переменную qll (Питание). В поле Test Value укажите стандартное значение, с которым мы будем сравнивать среднее тестируемой переменной. В нашем случае это 4,0. Кнопка Options позволяет указать доверительный уровень, для которого устанавливается различие.
После того как SPSS завершит расчет t-теста, в окне SPSS Viewer появятся две таблицы с результатами (рис. 3.8).
 |
В первой таблице, One-Sample Statistics, отражены расчеты среднего значения исследуемой переменной (столбец Mean). В нашем случае данное значение отражает среднюю оценку питания пассажиров первого класса (4,1 балла). Вторая таблица, One-Sample Test, позволяет сделать вывод о статистической значимости/незначимости тестируемого различия. Как следует из значения столбца Sig. (2-tailed), различие в оценках пассажиров первого класса и всей выборочной совокупности респондентов является статистически незначимым (0,149). Разница между реальным и тестируемым значениями (в нашем случае — 0,1 балла) отражается в столбце Mean Difference.
3.2. Дисперсионный анализ
Иногда при анализе данных маркетинговых исследований достаточно сравнить только две группы респондентов, то есть установить различия между двумя категориями опрошенных. Однако часто у исследователей возникает необходимость проанализировать не две, а три или более категории респондентов. В этом случае
следует прибегнуть к использованию дисперсионного анализа, который позволяет анализировать одновременно любое число групп.
Различают одномерный (Analysis of variance, ANOVA) и многомерный (Multiple analysis of variance, MANOVA) дисперсионный анализ. Для одномерного дисперсионного анализа существует только одна зависимая переменная; для многомерного — несколько. Также в этом разделе мы рассмотрим одномерный дисперсионный анализ с повторными измерениями (ANOVARM)1.
В табл. 3.2 приведены основные характеристики переменных, участвующих в различных видах дисперсионного анализа.
Таблица 3.2. Основные характеристики переменных, участвующих в дисперсионном анализе
| Одномерный дисперсионный анализ | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| Одна | Любой | Любое | Любой |
| Одномерный дисперсионный анализе повторными измерениями | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| Одна | Любой | Любой | Любой |
| Многомерный дисперсионной анализ | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| Любое | Любой | Любое | Любой |
3.2.1. Одномерный дисперсионный анализ
Как было сказано выше, одномерный дисперсионный анализ исследует влияние одной или нескольких независимых переменных на одну зависимую. Одномерный дисперсионный анализ может быть однофакторным (one-way ANOVA) или многофакторным (n-way ANOVA). В первом случае есть только одна независимая переменная; во втором — несколько.
Однофакторный одномерный дисперсионный анализ можно проводить двумя способами: при помощи специальной процедуры One-way ANOVA (меню Analyze ► Compare Means ► One-way ANOVA) или посредством обобщенной линейной модели (меню Analyze ► General Linear Model ► Univariate). Второй прием является более универсальным и обладает полным объемом функциональности первого, поэтому далее мы рассмотрим только GLM (использование первого метода аналогично GLM). Необходимо отметить, что для проведения одномерного дисперсионного анализа на практике (в маркетинговых исследованиях) существует одно весьма существенное ограничение. При увеличении количества факторов (то есть независимых переменных) в модели сложность интерпретации результатов расчета возрастает многократно. Так, однофакторный анализ является наиболее простым. Его результаты понятны сразу при взгляде на итоговую таблицу. Двухфакторный анализ намного сложнее в интерпретации — чтобы понять его результаты, приходится потратить много времени, разбираясь в таблицах и графиках. Для интерпретации результатов трехфакторного анализа необходимо обладать некоторым опытом в его проведении. Четырех- и мультифакторные модели в большинстве своем могут успешно интерпретироваться только квалифицированными исследователями. Таким образом, для практических целей лучше воздержаться от исследования большого числа взаимодействий между факторами и ограничиться несколькими наиболее важными. В настоящем разделе мы последовательно рассмотрим одно-, двух- и трехфакторные модели одномерного дисперсионного анализа. При этом будут использоваться следующие исходные данные:
Исследуется покупательское поведение потребителей глазированных сырков. Респонденты разделяются на целевые группы в зависимости от их пола (q3), возраста (q4) и количества членов семьи (q72). Одним из вопросов анкеты является: «Какое количество глазированных сырков в среднем Вы покупаете за одно посещение магазина?» (q6) с вариантами ответа: 1 шт., 2 шт., 3 шт., 4 шт., 5 шт., 6-7 шт., 8-10 шт. и более 10 шт. Требуется выяснить, различается ли кратность покупок глазированных сырков различными целевыми группами респондентов (половыми, возрастными и по количеству членов семьи).
Прежде всего мы проведем однофакторный одномерный дисперсионный анализ и установим, насколько значимо различается кратность покупок в различных возрастных группах респондентов (1 — младше 18 лет; 2 — 19-35 лет; 3 — 36-60 лет; 4 — старше 60 лет).
Диалоговое окно одномерного дисперсионного анализа запускается при помощи меню Analyze ► General Linear Model ► Univariate (рис. 3.9). Из левого списка всех доступных переменных переместите в поле для зависимой переменной Dependent Variable переменную q6 (Кратность покупок). Как видите, в качестве зависимой переменной в дисперсионном анализе выступает основание сегментирования респондентов по группам, то есть та переменная, которая и определяет различия между категориями независимой переменной. (Это замечание достаточно сложно осознать, так как при проведении дисперсионного анализа как бы стираются границы в трактовке зависимых и независимых переменных — по крайней мере, по сравнению с другими видами статистического анализа, например регрессионного.)
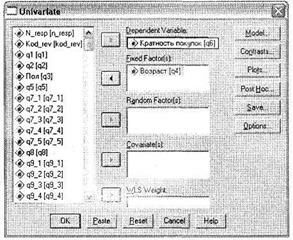 |
В область для независимых переменных Fixed Factor(s) поместите Возраст (q4). Обратите внимание на разницу между областями Fixed Factor(s) (факторы с фиксированными эффектами) и Random Factor(s) (факторы со случайными эффектами). Фиксированными факторами называют переменные, уровни которых охватывают все возможные состояния этой переменной. Например, пол может быть только мужской или женский, а возраст, например, младше 30 лет, от 30 до 60 лет и старше 60 лет. Случайные факторы представляют переменные, уровни которых охватывают лишь часть из всего многообразия возможных состояний. Так как в нашем случае переменная q4 (Возраст) содержит все возможные возрастные группы респондентов, мы поместили ее в область фиксированных факторов.
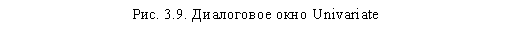 |
Если после этого вы щелкнете на кнопке ОК, то получите только одну таблицу, из которой можно узнать лишь о наличии/отсутствии значимых различий между возрастными группами. Однако останется неизвестным, какие именно группы отличаются от других.
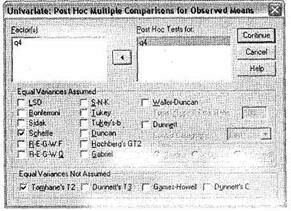
Для того чтобы определить это, существуют дополнительные статистические тесты, задаваемые при помощи кнопки Post Hoc. Соответствующее диалоговое окно представлено на рис. 3.10. Перенесите из области Factor(s) в область Post Hoc Tests for те независимые переменные (факторы), которые необходимо подвергнуть тестированию на предмет установления различий между их группами. В нашем случае есть всего одна факторная переменная q4, которую и следует перенести в область тестирования. Далее укажите релевантные дополнительные тесты для указанной переменной. При этом, как видно на рисунке, SPSS выводит различные тесты для равных и неравных дисперсий (Equal Variances Assumed и Equal Variances Not Assumed соответственно).
Установить равенство/неравенство дисперсий позволяет тест Levene, вывод которого на экран мы покажем ниже. В общем случае мы не знаем, равны ли дисперсии и, соответственно, какую группу статистических тестов следует использовать. Поэтому рекомендуется сразу вывести тесты для равных и неравных дисперсий, чтобы сократить количество итераций при проведении дисперсионного анализа. SPSS предлагает много различных дополнительных тестов, помогающих определить различия между группами исследуемых переменных. Однако использовать их все нецелесообразно. Мы рекомендуем ограничиться наиболее популярным и универсальным тестом Scheffe для равных дисперсий и тестом Tamhane's T2 — для неравных дисперсий. Теперь можно закрыть описываемое диалоговое окно щелчком на кнопке Continue.
 |
 |
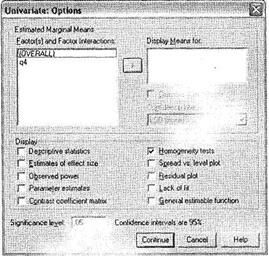 |
Выше мы упомянули о специальном тесте, позволяющем установить равенство/ неравенство дисперсий. На необходимость проведения данного теста (так же как и многих других) можно указать в диалоговом окне Options, вызываемом одноименной кнопкой в главном диалоговом окне Univariate (рис. 3.11). Для однофакторного дисперсионного анализа можно ограничиться только одним тестом Levene на равенство дисперсий (параметр Homogeneity tests).
 |
Следует отметить, что если исследуемая независимая переменная имеет всего две категории (дихотомия), апостериорные тесты для нее не проводятся. Установить направление различия между категориями позволяет вывод средних значений зависимой переменной в каждой из двух категорий. Для этого перенесите исследуемую независимую дихотомическую переменную из области Factor(s) and Factor Interactions
в область Display Means for. В нашем случае единственная независимая переменная Возраст имеет больше двух категорий (4), и поэтому специально выводить для нее средние значения нет смысла (они будут выведены в таблице Homogenous Subsets).
Остальные кнопки главного диалогового окна Univariate предназначены для многофакторного анализа, рассматриваемого ниже. Теперь щелкните на кнопке О К, чтобы запустить процедуру дисперсионного анализа. В окне SPSS Viewer будут выведены результаты расчетов.
Первой практически значимой таблицей является результат теста на равенство дисперсий зависимой и независимых переменных Levene's Test of Equality of Error Variances (рис. 3.12). В столбце Sig. данной таблицы содержится единственное интересующее нас значение — это статистическая значимость тестовой статистики F. Если значение в данном столбце показывает незначимость F — значит, дисперсии равны, и в дальнейшем мы будем анализировать результаты расчета теста Scheffe (предполагающего равенство дисперсий). В противном случае, если F-статистика значима, — дисперсии не равны, и при анализе различий между группами следует использовать тест Tamhane's T2 (предполагающий неравенство дисперсий). Как вы видите на рисунке, статистика F незначима (Sig. = 0,433) — и, следовательно, можно сделать вывод о равенстве дисперсий.
 |
 |
Следующая таблица — это Tests of Between-Subjects Effects (рис. 3.13). Данная таблица является центральной в выводимых результатах дисперсионного анализа и показывает наличие/отсутствие значимых различий между категориями исследуемых переменных. Первое, на что следует обратить внимание при анализе описываемой таблицы, — это величина R2, отражающая долю совокупной дисперсии в зависимой переменной, описываемой статистической моделью. Другими словами, это та часть вариации зависимой переменной, которую можно объяснить на основании независимой переменной. Естественно, что чем меньше независимых переменных, тем меньше величина R2, и наоборот.
Так, в нашем случае есть только одна независимая переменная q4 (Возраст), и при этом R2 весьма мала (0,019). Для дисперсионного анализа значения R2 можно просто проигнорировать, так как они не важны для практического использования полученной модели'. Второе, на что обращают внимание исследователи при интерпретации таблицы Tests of Between-Subjects Effects, — это собственно значимость различия между группами независимой переменной. Этот вывод следует из значения на пересечении строки, содержащей соответствующую независимую переменную, и столбца Sig.. Как вы видите на рисунке, имеет место статистически высоко значимое различие между различными возрастными группами респондентов по кратности покупок глазированных сырков (значимость F-статистики у переменной q4 < 0,001). Обратите внимание, что если тест Levene выявил факт неравенства дисперсий независимых и зависимых переменных, следует поднять по
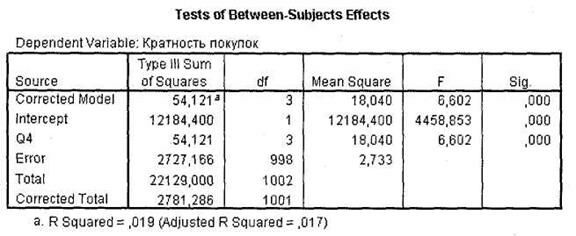 |
рог значимости со стандартного значения 0,05 до 0,01.
 |
После того как мы установили наличие статистически значимого различия между возрастными группами респондентов на основании кратности покупок сырков, необходимо определить, какие из четырех имеющихся возрастных групп отличаются от остальных и каким образом (в большую или в меньшую сторону).
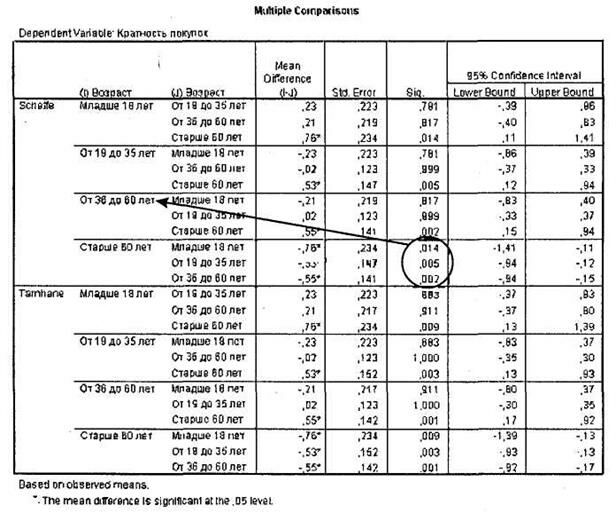
Давайте сделаем это при помощи таблицы Multiple Comparisons, представленной на рис. 3.14. При интерпретации данной таблицы прежде всего вспомните результаты теста Levene. Так, в нашем случае на основании данного теста дисперсии оказались равными, и поэтому в данной таблице мы будем рассматривать только ту ее часть, в которой приведены расчеты по методу Scheffe (напомним, что тест Tamhane мы бы применяли только если бы дисперсии были неравны).
Итак, в первой части таблицы (Scheffe) мы видим сравнение различий между каждой из четырех возрастных категорий с остальными категориями. На основе этих данных и определяются та или те группы, которые значимо отличаются от других. Так, из столбца Sig. (статистическая значимость) мы видим, что только группа респондентов старше 60 лет статистически значимо отличается от всех остальных. Остальные целевые группы не отличаются друг от друга. При этом из столбца Mean Difference можно видеть, насколько отличается среднее значение той или иной группы от среднего значения других групп (звездочками отмечены значимые различия при 95%-ном доверительном уровне)1.
Наконец, в последней таблице Homogeneous Subsets (рис. 3.15) представлена однозначная картина различий между группами независимой переменной. Здесь все возрастные группы разделены на две категории на основании различий в кратности покупок. В первую категорию входит целевая группа респондентов старше 60 лет; во вторую — все остальные возрастные группы (то есть респонденты младше 60 лет). Если бы оказалось, что статистически значимых различий в кратности покупок глазированных сырков различными возрастными группами респондентов не наблюдается, все группы независимой переменной были бы отнесены к одной категории (Subset был бы только 1). Иногда возникает ситуация, при которой одна и та же группа респондентов может относиться сразу к нескольким группам. В таком случае следует поднять порог значимости со стандартных 0,05, скажем, до 0,01 (или любого другого значения).

Также из рассматриваемой таблицы можно сделать вывод о направлении различия между выделенными категориями. Так, в нашем случае мы можем заключить, что респонденты старше 60 лет покупают глазированные сырки в меньших объемах, чем респонденты младше 60 лет. В точности определить размер или величину различия можно, только если в качестве зависимой переменной выступает интервальная переменная. Так как у нас переменная q6 Кратность покупок относится к порядковой шкале, мы не можем сделать точный вывод о величине различия. Если стоит такая задача, можно преобразовать зависимую порядковую переменную к интервальному виду (например, при помощи перекодирования кодов групп в средние значения данных групп: 1 (от 16 до 18 лет) —> 17 и пересчитать дисперсионный анализ. Это даст хотя бы приблизительную оценку величины различия. Нам достаточно только установленной статистической значимости (то есть существования) различия и его направления (респонденты старше 60 лет покупают меньше сырков, чем более молодые).
 |
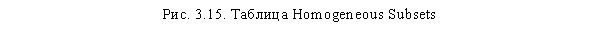
Рассмотрим теперь ситуацию, когда необходимо исследовать сразу две независимые переменные (и взаимодействия между ними), то есть выполнить двухфактор-ный одномерный дисперсионный анализ.
Исходные данные останутся такими же, как в предыдущем примере, однако теперь мы будем устанавливать различие в кратности покупок сырков возрастными и половыми группами (переменная q3). Для этого вновь откроем диалоговое окно Univariate (рис. 3.9) и добавим в область для фиксированных факторов (независимых переменных с фиксированными эффектами) переменную Пол. При проведении многофакторного анализа (двухфакторной и более) кнопка Model позволяет задать исследование либо всех возможных взаимодействий между независимыми переменными (в нашем случае будет установлено различие не только между четырьмя возрастными и двумя половыми группами по отдельности, но и между каждой половозрастной группой), либо только каких-то конкретных взаимодействий. В диалоговом окне Model можно задать и другие значения, но для большинства задач маркетинговых исследований достаточно оставлять все эти значения по умолчанию. Иными словами, кнопкой Model лучше не пользоваться. То же самое касается и кнопки Contrasts (исследование взаимодействий между уровнями независимых переменных), а также кнопки Save, позволяющей сохранять некоторые значения. В большинстве практических случаев, встречающихся в маркетинговых исследованиях, при проведении дисперсионного анализа вам не потребуется ничего сохранять. При проведении многофакторного дисперсионного анализа в диалоговом окне Post Нос (рис. 3.10) следует добавить к списку исследуемых переменных все независимые факторы, кроме дихотомических. В нашем случае переменная Пол является
дихотомической, так что добавлять ее в область Post Hoc Tests for (дополнительно к переменной Возраст) не следует. Таким образом, все параметры этого диалогового окна останутся неизменными по сравнению с предыдущим примером.
В диалоговом окне Options (рис. 3.11) необходимо добавить дихотомическую переменную q3 (Пол), а также ее взаимодействие с переменной q4 (Возраст) — q3*q4 — в область Display Means for, что позволит вывести средние значения по каждой группе мужчин и женщин при определении направления различия между ними. После этого можно запускать процедуру дисперсионного анализа на выполнение.
В окне SPSS Viewer будут выведены результаты расчетов. Они будут отличаться от результатов предыдущего примера. Во-первых, как видно из рис. 3.16, тест Levene теперь является значимым (Sig. = 0,033), из чего следует вывод о неравенстве дисперсий.
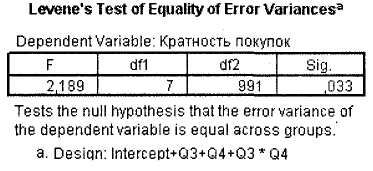 |
 |
Во-вторых, в таблице Tests of Between-Subjects Effects появились результаты расчета значимости F-статистики для переменной Пол (q3), а также для взаимодействия q3*q4. Как видно из рис. 3.17, мужчины и женщины не имеют статистически значимых различий по кратности покупок глазированных сырков. То же относится и к взаимодействию q3*q4: оно не является статистически значимым. При этом, несмотря на неравенство дисперсий (порог значимости возрос до 0,01), переменная q4 (Возраст) сохранила свое значимое влияние на зависимую переменную (Sig. = 0,011), то есть возрастные группы по-прежнему различаются по кратности покупок сырков. Необходимо также отметить, что с добавлением переменной q3 доля совокупной дисперсии в зависимой переменной, объясняемая построенной моделью, несколько возросла (R2 = 0,022).
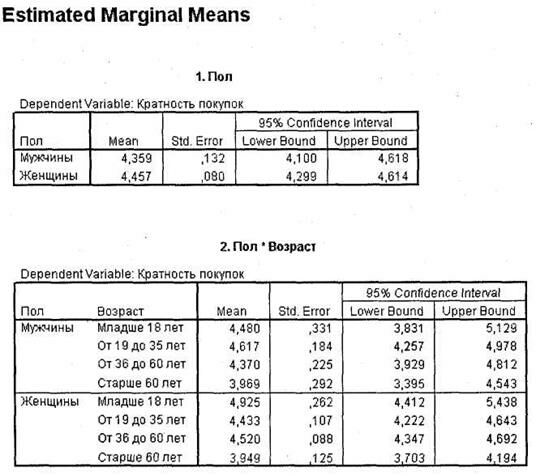
После таблицы Tests of Between-Subjects Effects следуют расчеты средних значений для дихотомической переменной q3 (Пол) и для взаимодействия q3 x q4 (рис. 3.18). В нашем случае ни переменная q3, ни ее взаимодействие с q4 не являются статистически значимыми, поэтому данные таблицы бесполезны. Однако если бы переменная Пол была значима (то есть различие между мужчинами и женщинами существовало), на основании первой таблицы можно было бы сделать заключение о том, какая именно половая группа покупает больше сырков.
Так, если предположить, что влияние переменной Пол статистически значимо, из рис. 3.18 можно было бы заключить, что женщины покупают глазированные сырки в больших объемах по сравнению с мужчинами. То же можно сказать и относительно второй таблицы (Пол х Возраст). Случается, что по результатам таблицы Tests of Between-Subjects Effects некая переменная оказывается незначимой, однако в таблице Multiple Comparisons отдельные уровни этой переменной значимо отличаются друг от друга. В такой ситуации все равно следует признать рассматриваемую переменную незначимой и в дальнейшем игнорировать связанные с нею апостериорные тесты.
 |
 |
 |
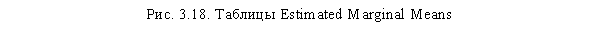 |
Завершают вывод результатов двухфакторного анализа таблицы с расчетами апостериорных тестов. В нашем случае они практически такие же, как в предыдущем примере, поскольку переменная Возраст сохранила свою значимость (см. рис. 3.14 и 3.15). Однако при интерпретации таблицы Multiple Comparisons следует помнить
о неравенстве дисперсий. Поэтому значимость различий между отдельными возрастными группами надо устанавливать на основании второй части таблицы Tamhane.
Итак, мы рассмотрели одно- и двухфакторный одномерный дисперсионный анализ. Далее мы поговорим более подробно о трехфакторном дисперсионном анализе. На его примере мы рассмотрим построение графиков и методы их использования с целью облегчения интерпретации значимых взаимодействий между переменными.
Теперь мы будем использовать все четыре переменные из исходного условия задачи (см. выше), то есть проанализируем различия в кратности покупки глазированных сырков анализируемыми целевыми группами респондентов (половыми, возрастными и по количеству членов семьи). Откройте диалоговое окно Univariate и добавьте в список независимых переменных (область Fixed Factor(s)) еще одну переменную q72 (Количество членов семьи).
Здесь необходимо сделать одно важное отступление. Время проведения расчетов в дисперсионном анализе (как одномерном, так и многомерном) при добавлении каждого нового фактора существенно возрастает. Если при этом зависимая переменная содержит достаточно большое количество уровней, расчеты могут затянуться на весьма длительное время. Исследователям-практикам следует знать об одной существенной особенности SPSS: скорость ее работы лимитируется тактовой частотой основного микропроцессора и объемом оперативной памяти (скорость работы жесткого диска не играет существенной роли). SPSS может использовать в своей работе только один процессор, то есть если у вас в компьютере установлено два и более процессора, для SPSS это не будет иметь никакого значения. Поэтому при работе с данной программой мы настоятельно рекомендуем использовать мощные машины с высокопроизводительным процессором и достаточным объемом оперативной памяти. К сожалению, в настоящее время не все отечественные компании имеют возможность приобретать мощные компьютеры. Предлагаем следующий выход. В главном диалоговом окне Univariate есть кнопка Model, которая, как мы сказали выше, в маркетинговых исследованиях используется редко, поскольку при проведении дисперсионного анализа не требуется анализировать сразу много (четыре и более) факторов и, следовательно, скорость работы программы будет приемлемой. Однако если в анализ приходится включать четыре и более независимых переменных, придется воспользоваться кнопкой Model. Щелкните на ней — и вы увидите одноименное диалоговое окно, показанное на рис. 3.19. По умолчанию в SPSS выбрана полнофакторная модель дисперсионного анализа Full factorial, где исследуется влияние на зависимую переменную:
1. всех независимых переменных по отдельности;
2. всех возможных взаимодействий между независимыми переменными.
 |
Именно на расчеты, связанные со вторым пунктом, и тратится основное время. Поэтому при ограничениях, налагаемых аппаратным обеспечением компьютера, следует отказаться от использования полнофакторных моделей в пользу определяемых пользователем (Custom). Если ограничения жесткие, можно выполнить только исследования влияния независимых переменных на зависимую по отдельности (в терминологии SPSS, Main effects)1.
 |
В данном диалоговом окне в левом списке содержатся все выбранные для анализа независимые переменные. Чтобы определить пользовательскую модель, в левом списке Factors & Covariates выберите переменные, которые будут включены в итоговую пользовательскую модель. Затем из раскрывающегося списка Build Term(s) выберите тот или иной тип взаимодействия между переменными. И наконец, щелкните на соответствующей кнопке, чтобы перенести сформированную пользовательскую модель в правый список Model.
Если вы хотите рассмотреть только влияние факторных переменных по отдельности, выполните действия, показанные на рис. 3.19. Выберите все независимые переменные в левом списке, тип модели Main effects и перенесите эти переменные в правую область. Другими видами моделей являются:
■ Interaction — исследование всех видов взаимодействий между выбранными переменными;
■ АН 2-, 3-, 4-, 5-way — исследование только взаимодействий соответственно второго (ql*q2), третьего (ql*q2*q3), четвертого (ql*q2*q3*q4) и пятого (ql*q2*q3*q4*q5) порядков.
Обратите внимание, что одновременно можно сформировать в правом списке Model сколько угодно различных моделей, подбирая только основные, необходимые вам взаимодействия факторов.
Для иллюстрации решения задачи (выполнение трехфакторного дисперсионного анализа) не будем задавать пользовательские модели, а воспользуемся полнофакторной моделью, установленной по умолчанию. В диалоговом окне Model есть еще два не рассмотренных ранее параметра: Sum of squares и Include interceptin model. Первый параметр позволяет задать тип формулы для расчета суммы квадратов (тестовой величины, на основании которой и производится расчет статистической значимости различий). В маркетинговых исследованиях рекомендуется использовать тип III, установленный по умолчанию. Второй параметр служит для указания на необходимость включить в итоговую модель расчеты значимости отрезка значений. Данный параметр также можно всегда оставлять установленным по умолчанию.
Вернемся к описанию решения поставленной задачи. Мы добавили в соответствующие поля главного диалогового окна Univariate одну зависимую переменную и cразу три независимые. При помощи кнопок Post Hoc и Options необходимо выбрать те же параметры, которые мы выбирали для одно- и двухфакторного анализа. В результате останется не рассмотренной одна важная кнопка в главном диалоговом окне Plots, позволяющая указать параметры для построения графиков. Эту кнопку следует использовать в тех ситуациях, когда обнаружено статистически значимое взаимодействие между факторами.
Для того чтобы построить график взаимодействия факторов, сначала мы должны провести дисперсионный анализ по обычной схеме (без графиков) и выяснить, есть ли значимые взаимодействия. После щелчка на кнопке ОК в окне SPSS Viewer будут выведены результаты расчетов для трехфакторного одномерного дисперсионного анализа. Нет смысла приводить их здесь — в них нет ничего для вас нового. Вместо этого давайте посмотрим, как интерпретировать значимые взаимодействия между факторами.
Существует два основных способа интерпретации взаимодействий:
■ в табличной форме — по результатам апостериорных тестов;
■ в графической форме — по построенным графикам взаимодействий.
Графическая форма представления результатов зачастую более предпочтительна по сравнению с табличной, особенно при анализе взаимодействий трех и более уровней. На рис. 3.20 показано диалоговое окно Profile Plots. Для того чтобы построить график по двухуровневому взаимодействию, из левого списка всех независимых переменных (область Factors) выберите переменную, категории которой будут располагаться по оси абсцисс (горизонтальной), и поместите ее в поле Horizontal Axis. Далее выберите переменную, значения каждой категории которой будут отображаться на графике в виде отдельных линий (пример см. ниже), и поместите ее в поле Separate Lines.
 |
 |
Для иллюстрации процесса построения графиков предположим, что по результатам трехфакторного дисперсионного анализа была установлена статистическая значимость взаимодействия между переменными q3 (Пол) и q4 (Возраст). В окне Profile Plots мы поместили переменную с наименьшим числом категорий q3 в поле Horizontal Axis, а переменную q4 — в поле Separate Lines. Теперь щелкните на кнопке Add, чтобы подтвердить построение графика с заданными параметрами. Таким способом можно задать вывод сразу нескольких графиков.
После того как SPSS завершит расчеты, связанные с дисперсионным анализом, в окне SPSS Viewer после таблиц появится заданный график. В нашем примере он будет выглядеть так, как показано на рис. 3.21.
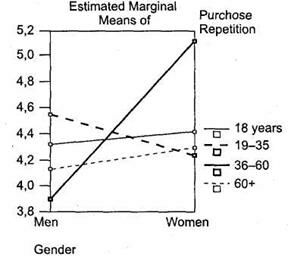 |
 |
По оси ординат здесь (вертикальная ось) располагаются средние значения кратности покупок глазированных сырков каждой из рассматриваемых половозрастных групп. При этом на рисунке видно, что в возрастных группах от 36 до 60 лет и старше 60 лет кратность покупок сырков мужчинами и женщинами практически не различается (соответствующие линии близки к параллели), тогда как в других возрастных группах различие между мужчинами и женщинами выражено достаточно существенно (соответствующие линии перпендикулярны). Так, мужчины младше 18 лет характеризуются существенно меньшей кратностью покупок сырков, чем женщины младше 18 лет. Мужчины в возрасте до 18 лет имеют наименьшую кратность покупок и по сравнению со всеми другими половозрастными группами. Мужчины в возрасте 19-35 лет характеризуются наивысшей кратностью покупок сырков среди всех возрастных групп мужчин. Можно заметить, что ситуация с женщинами в двух рассматриваемых возрастных группах диаметрально противоположная. Мужчины младше 18 лет имеют наименьшую кратность покупок; женщины младше 18 лет — наивысшую. Мужчины от 19 до 35 лет имеют наивысшую кратность покупок; женщины 19-35 лет — наименьшую.
Таким образом, вы видите, что графики в дисперсионном анализе являются весьма ценным ресурсом для построения заключений и выводов. Еще одним направлением интерпретации является кластеризация респондентов на основании их средних показателей (например, кратности покупок). Так, в нашем примере на основании кратности покупок можно разделить всех респондентов на следующие целевые сегменты:
1. мужчины младше 18 лет характеризуются наименьшей кратностью покупок сырков;
2. мужчины старше 36 лет и женщины старше 19 лет характеризуются средней кратностью покупок сырков;
3. мужчины от 19 до 35 лет и женщины младше 18 лет характеризуются наивысшей кратностью покупок сырков.
В целом общая схема интерпретации графиков в дисперсионном анализе состоит из двух этапов. Сначала следует определить категории респондентов, отличающиеся и не отличающиеся друг от друга. При этом интерпретация графиков всегда происходит только по двум переменным (представленным по горизонтальной оси и в виде отдельных линий). Для установления различия следует смотреть на форму данных линий. Если две (или более) линии близки к параллели, следовательно, различия между данными категориями минимальны (незначимы). В противном случае, если линии пересекаются, следует признать различие между ними существенным (значимым).
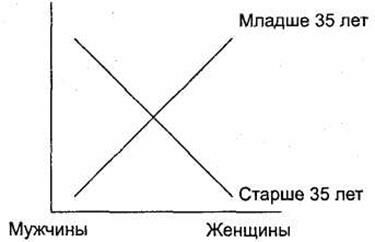 |
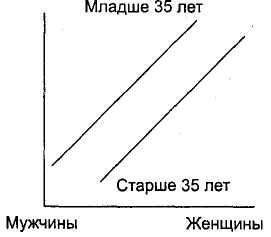
Наиболее простым для интерпретации случаем является ситуация, в которой по горизонтальной оси располагается дихотомическая переменная (например, переменная Пол). Если линии на отрезке между двумя категориями данной переменной не пересекаются — различий нет; если пересекаются — различия есть. На рис. 3.22 представлен пример максимальных различий (линии пересекаются под прямым углом); на рис. 3.23 — минимальных (линии параллельны).
 |

 |
Можно сформулировать следующие рекомендации по построению графиков в дисперсионном анализе.
1. Для горизонтальной оси лучше выбирать дихотомические вопросы.
2. Если дихотомических переменных нет, следует выбрать переменную с наименьшим четным количеством категорий и перекодировать данные категории в дихотомию. Для горизонтальной оси следует выбирать именно данную (уже дихотомическую) переменную. Данный способ работает далеко не всегда, ведь часто различия между взаимодействиями факторов находятся именно в тех категориях, которые будут перекодированы (сокращены).
При исследовании трехуровневых взаимодействий (ql x q2 x q3) переменную с наименьшим числом категорий (лучше дихотомическую) следует поместить в поле Separate Plots в диалоговом окне Univariate (например, ql), а для остальных двух исследуемых переменных (например, q2 и q3) — следовать вышеописанным правилам. Это будет означать, что в результате будут построены отдельные графики по каждой категории переменной ql, где будут показаны двухуровневые взаимодействия переменных q2 и q3.
В заключение настоящего раздела необходимо особо отметить, что графики взаимодействий могут эффективно применяться только при числе взаимодействий 2 (ql х q2) или 3 (ql x q2 x q3). При взаимодействиях первого уровня (ql) мы говорим уже не о взаимодействиях как таковых, а о главных эффектах (Main effects), то есть о влиянии на зависимую переменную только каждого фактора в отдельности. В таком случае различия между конкретными группами независимой переменной определяются исходя из результатов апостериорных тестов. При числе взаимодействий более трех сохраняется возможность разбиения данного взаимодействия на несколько взаимодействий второго или третьего уровней и построения затем серии графиков. Однако в этом случае интерпретация данных графиков является практически неразрешимой задачей.
3.2.2. Одномерный дисперсионный анализ с повторными
измерениями
Одномерный дисперсионный анализ с повторными измерениями (ANOVARM) является расширением одномерного дисперсионного анализа (ANOVA). Цель его заключается в анализе различий между ответами одних и тех же респондентов на одни и те же вопросы в несколько приемов, то есть в течение ряда дискретных временных промежутков.
В качестве примера можно привести панельные исследования, когда одни и те же респонденты (потребители какого-либо продукта) отвечают на одни и те же вопросы через определенные интервалы времени (скажем, каждый квартал). Одной из основных целей дисперсионного анализа в рассматриваемом случае будет оценка влияния на ответы респондентов временного фактора. Таким образом, в частности, можно установить уровень лояльности к продуктам различных марок: если с течением времени средние оценки продукта марки X существенно не меняются/ возрастают/убывают, следовательно, и отношение респондентов к данной марке сохраняется на прежнем уровне/улучшается/ухудшается. Иными словами, дисперсионный анализ с повторными измерениями может применяться для оценки значимости тенденций.
В маркетинговых исследованиях этот тип статистического анализа находит весьма разнообразные применения. Он может применяться не только в процессе анализа баз данных по маркетинговым исследованиям, но и в процессе сбора анкет — для контроля работы интервьюеров. Например, если опрос производится каждый
день в течение недели в одних и тех же местах, можно анализировать средние значения основных переменных, во-первых, по дням недели, а во-вторых, по каждому интервьюеру. Если будут выявлены существенные различия в анкетах интервьюеров, то высока вероятность фальсификации (тем интервьюером, анкеты которого наиболее сильно отличаются от остальных).
Необходимо сделать важное отступление. Дело в том, что некоторые источники иногда относят анализ с повторными измерениями к одномерному, а иногда — к многомерному дисперсионному анализу. В справочной системе SPSS не указана явно принадлежность ANOVARM к одной или другой группе статистических методов. По сути расчетов ANOVARM близок к многомерному дисперсионному анализу, поскольку в качестве зависимой переменной выступают сразу несколько переменных, кодирующих ряд временных периодов. Но так как основная задача данного пособия — объяснение практических приемов работы с SPSS для эффективного применения этого программного продукта в маркетинговых исследованиях, мы отдаем предпочтение семантическому толкованию статистических терминов. Зависимые переменные в ANOVARM по смыслу (с точки зрения исследователя) представляют собой фактически одну и ту же переменную, только измеренную многократно. В этой трактовке следует скорее говорить о специфической форме одномерного дисперсионного анализа, в котором зависимая переменная представлена набором подпеременных (точно так же, как при кодировании многовариантных вопросов; см. раздел 1.4.2). Таким образом, мы придерживаемся точки зрения тех авторов, которые считают ANOVARM видом одномерного дисперсионного анализа (ANOVA).
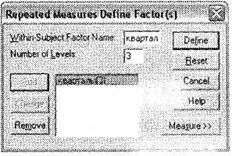
Итак, в качестве иллюстрации использования одномерного дисперсионного анализа с повторяющимися измерениями рассмотрим следующий пример. Проводится исследование мнений респондентов относительно одежды марки X. Одним из вопросов анкеты является следующий: Поставьте оценку одежды марки X по пятибалльной шкале (от 1 — очень плохо до 5 — отлично). Респонденты разделяются на группы по полу и возрасту. Исследование проводится с частотой раз в квартал в течение года. В результате в итоговой базе данных получены три переменные: ql8, ql9 и q20, отражающие уровень оценки респондентами одежды марки X в первом, втором и третьем кварталах, а также две переменные, указывающие пол (q80) и возраст (q74) опрошенных. Требуется установить, как меняется общая картина восприятия респондентами одежды марки X в течение одного года. Поставленная задача легко решается методом одномерного дисперсионного анализа с повторяющимися измерениями. Откройте диалоговое окно Repeated Measures Define Factor(s) при помощи меню Analyze ► General Linear Model ► Repeated Measures (рис. 3.24). Это диалоговое окно предназначено для формирования временных факторов, то есть определения составных переменных, описывающих эти факторы. У нас есть три временных интервала (квартала), поэтому в поле Within-Subject Factor Name напишите название этой составной переменной: кварталы, а в поле Number of Levels — число временных периодов, когда производились измерения (3 квартала). После этого щелкните на кнопке Add, чтобы добавить новую составную переменную в список. Таким способом можно задать сразу несколько составных временных переменных, однако в маркетинговых ис
 |
следованиях в большинстве случаев ограничиваются только одной.
 |
Кнопка Measure служит для задания дополнительных измерений временных переменных, но в маркетинговых исследованиях эта функция обычно не используется.
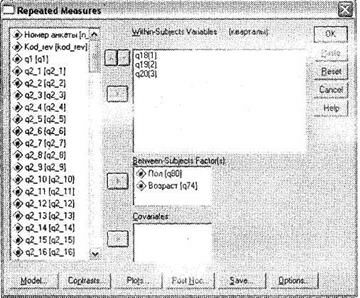 |
Щелкните на кнопке Define, и откроется новое диалоговое окно Repeated Measures (рис. 3.25), похожее (как по внешнему виду, так и по своим функциям) на окно Univariate. В этом окне в левом списке всех доступных переменных выберите те, в которых закодированы оценки респондентов в каждый из временных промежутков (в нашем случае — ql8, ql9, q20), и последовательно (то есть в порядке возрастания периодов) перенесите их в область Within-Subjects Variables (кварталы).
 |
Теперь в рассматриваемой области определена составная временная переменная, описывающая оценки респондентами одежды марки X в каждый из трех рассматриваемых кварталов. Таким образом, область Within-Subjects Variables (кварталы) является аналогом области Dependent Variable в одномерном дисперсионном анализе, только зависимая переменная в нашем случае как бы распадается на три подпеременные, вместе составляющие одно целое. Далее в область Between-Subjects Factor(s) поместите те переменные, которые служат основаниями для различения оценок. В нашем случае это демографические характеристики респондентов: пол (q80) и возраст (q74).
Итак, вы задали все переменные для исследования и можете использовать кнопки, расположенные в нижней части этого диалогового окна, — так же, как вы делали это при одномерном дисперсионном анализе (см. раздел 3.2.1). В окне Post Нос задайте апостериорные тесты Scheffe (для равных дисперсий) и Tumhale (для неравных дисперсий) для переменных, имеющих более двух категорий (в нашем случае это только q74 — Возраст). В окне Options выберите параметр Homogeneity Tests и в соответствующее поле поместите переменные с двумя категориями, для которых следует рассчитать средние значения (q80 — Пол и все взаимодействия, в которых она участвует). Остальные диалоговые окна аналогичны рассмотренным для одномерного дисперсионного анализа, поэтому мы не приводим их второй раз.
В результате мы выясняем, какой из трех факторов — пол, возраст или время (кварталы) — определяет различия в оценках одежды марки X. Запустив программу на исполнение щелчком на кнопке ОК, в окне SPSS Viewer вы увидите результаты дисперсионного анализа. В целом они аналогичны результатам, отображаемым при одномерном дисперсионном анализе, однако данные результаты значительно обширнее и содержат несколько дополнительных таблиц. Так как настоящее пособие посвящено сугубо практическим задачам использования SPSS в маркетинговых исследованиях, мы рассмотрим только ту часть результатов, которая необходима на практике.
 |
Итак, первое, что должно привлечь ваше внимание, — это таблица Box's Test of Equality of Covariance Matrices (рис. 3.26). Тестовая статистика Box показывает, существуют ли статистически значимые различия в оценках респондентов в каждом из анализируемых периодов. В нашем случае мы видим высокую значимость (Sig. < 0,001), свидетельствующую о том, что оценки респондентами одежды марки X существенно меняются от квартала к кварталу.
 |
После анализа результатов теста Box мы смотрим на следующую важную таблицу — Multivariate Tests (рис. 3.27), позволяющую сделать выводы о том, в какой степени выявленные различия определяются влиянием временного фактора, а также взаимодействием этого фактора с другими переменными, включенными
в анализ. Так, в нашем случае мы видим, что непосредственно временной фактор (кварталы) в значительной степени определяет различия в исследуемых оценках (Sig. < 0,001). Сочетание эффектов времени и пола (Кварталы х q80), а также времени и возраста респондентов (Кварталы х q74) с высокой вероятностью определяют различия в оценках одежды (Sig. = 0,002 и 0,024). А вот тройственное взаимодействие всех анализируемых величин в совокупности не оказывает никакого влияния на изучаемую разницу в оценках (Sig. = 0,935). Обратите внимание на то, что при интерпретации таблицы Multivariate Tests следует оценивать значимость того или иного фактора всегда на основании теста Pillai's Trace. Именно этот тест статистической значимости является наиболее надежным (робастп-ным).
 |
 |
Мы ответили на два основных вопроса:
1. изменяются ли статистически значимо оценки респондентами одежды марки X?
2. чем определяются эти различия: только влиянием временного фактора или также влиянием независимых переменных (пола и возраста)?
В результате анализа мы смогли утвердительно ответить на оба вопроса: различия в оценках есть, и они определяются как временем, так и его взаимодействием с полом и возрастом. Дальнейший анализ будет направлен на исследование влияния независимых переменных и их взаимодействий по отдельности на оценки респондентов.
Следующие три таблицы: — Mauchly's Test of Sphericity, Tests of Within-Subjects Effects и Tests of Within-Subjects Contrasts — обычно пропускаются, так как они не позволяют сделать никаких новых выводов и лишь подтверждают представленные выше результаты. После трех таблиц следуют результаты одномерного дисперсионного анализа для независимых переменных, для которых не производятся повторные измерения, знакомые вам по разделу 3.2.1.
Таблица Levene's Tests of Equality of Error Variances (рис. 3.28) позволяет определить однородность дисперсий в каждый из исследуемых промежутков времени. Так, в нашем случае мы видим, что во всех трех исследуемых кварталах дисперсии однородны (Sig. > 0,05).

 |
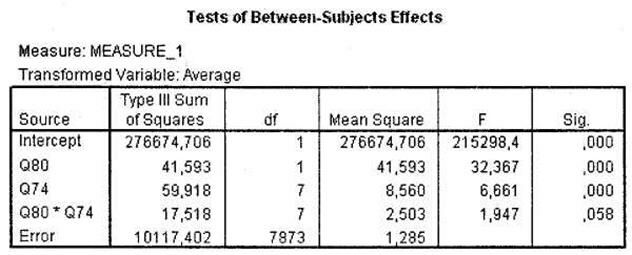
Из таблицы Tests of Between-Subjects Effects (рис. 3.29) мы видим, что и пол, и возраст респондентов с весьма высокой вероятностью определяют различия в оценках одежды марки X (Sig. < 0,001), а вот их взаимодействие — нет (Sig. = 0,058).

Теперь нам осталось определить, как именно различаются оценки под влиянием выявленных значимых факторов и их взаимодействий. Во-первых, мы определи-
ли, что на различии в оценках респондентов в каждый из трех анализируемых периодов оказывают влияние пяти эффектов:
■ временной фактор (кварталы);
■ взаимодействие времени с полом;
■ взаимодействие времени с возрастом;
■ пол;
■ возраст.
К сожалению, провести апостериорные тесты для временной переменной SPSS не позволяет, поэтому при определении различий между группами временной переменной приходится ориентироваться исключительно на средние значения (оценки). Возраст является единственной переменной, для которой можно провести стандартные апостериорные тесты (см. далее). Для остальных значимых взаимодействий выводятся средние значения: оценки одежды марки X в каждой рассматриваемой категории респондентов (см. рис. 3.28). Кроме таблиц для данных взаимодействий целесообразно вывести и графики. Это облегчит интерпретацию и позволит наглядно определить различия между категориями респондентов.
 |
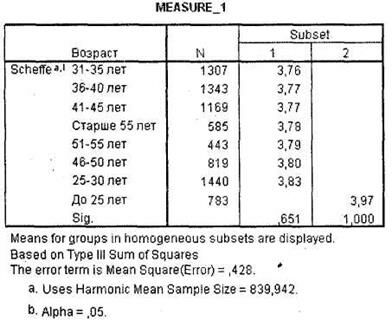 |
Завершают вывод результатов одномерного дисперсионного анализа с повторяющимися измерениями таблицы апостериорных тестов для переменных с числом категорий более двух1. В нашем случае это две таблицы для переменной Возраст: Multiple Comparisons и Homogeneous Subsets. Первую таблицу мы не приводим из-за ее большого размера, вместо этого приведена дублирующая ее вторая таблица, показывающая однородные группы респондентов по оценкам одежды марки X
(рис. 3.30). Из таблицы вы видите, что наивысший уровень оценок достигается в возрастной группе респондентов (в среднем 4,0 балла) младше 25 лет. Респонденты старше 25 лет склонны оценивать одежду марки X несколько ниже (в среднем на 3,8 балла).
3.2.3. Многомерный дисперсионный анализ
Многомерный дисперсионный анализ является дальнейшим расширением одномерного дисперсионного анализа (после рассмотренного в разделе 3.2.2 ANOVARM), предназначенным для одновременного анализа сразу нескольких зависимых и независимых переменных. Процесс проведения многомерного анализа аналогичен рассмотренному выше обычному одномерному дисперсионному анализу, за исключением того, что в данном случае в область для зависимых переменных можно поместить сразу несколько переменных, а при интерпретации приходится анализировать сразу несколько различий (во всех зависимых переменных).
Давайте рассмотрим процесс проведения многомерного дисперсионного анализа на примере, аналогичном приведённому в разделе 3.2.1 для обычного одномерного дисперсионного анализа, — но в качестве зависимых переменных мы будем рассматривать не только кратность покупок глазированных сырков, но и частоту покупок. В качестве независимых переменных мы возьмем также две переменные: возраст респондентов и количество членов их семей.
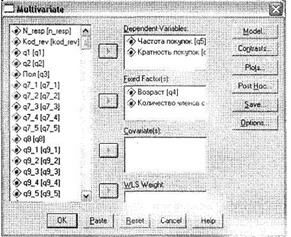
Откройте диалоговое окно Multivariate при помощи меню Analyze ► General Linear Model ► Multivariate. Как вы видите на рис. 3.31, оно аналогично окну Univariate. Поместите две зависимые переменные: q5 (Частота покупок) и q6 (Кратность покупок) в область для зависимых переменных Dependent Variables, а переменные q4 (Возраст) и q72 (Количество членов семьи) — в область для независимых переменных Fixed Factor(s). После этого так же, как для одномерного дисперсионного анализа в окне Post Hoc, задайте вывод тестов Scheffe и Tumhale для обеих независимых переменных, а в окне Options отметьте параметр Homogeneity Tests. После этого можно начать расчеты, щелкнув на кнопке ОК.
В окне SPSS Viewer появятся результаты многомерного дисперсионного анализа. Первой таблицей, которая должна привлечь ваше внимание, является Box's Test of Equality of Covariance Matrices, представленная на рис. 3.32. В отличие от одномерного дисперсионного анализа с повторяющимися измерениями, здесь тест Box должен быть незначимым (как в нашем случае, Sig. = 0,131), так как неравенство дисперсий исследуемых зависимых переменных в многомерном анализе не является положительным фактом. И напротив, равенство дисперсий зависимых переменных является одним из основных условий проведения многомерного дисперсионного анализа1.
Таблица Multivariate Tests позволяет сделать выводы относительно влияния независимых переменных в отдельности, а также их взаимодействий на зависимые переменные в целом. Поскольку с практической точки зрения влияние не несет никакой смысловой нагрузки, данная таблица обычно не рассматривается.
 |
 |
 |
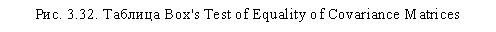 |
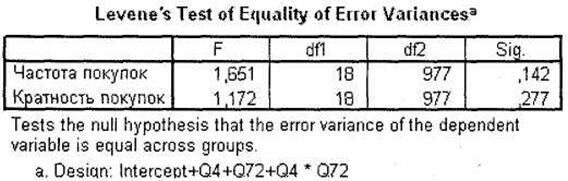
Следующей важной таблицей является тест Levene на равенство дисперсий зависимых переменных. Как мы помним из описания одномерного дисперсионного анализа, от факта равенства/неравенства дисперсий в дальнейшем зависит выбор конкретного апостериорного теста: Scheffe или Tumhale. Как вы видите на рис. 3.33, в нашем случае дисперсии равны у обеих зависимых переменных, поэтому далее мы будем опираться на результаты теста Scheffe.
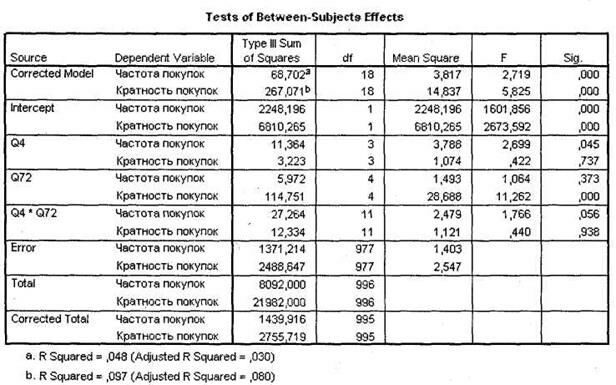
Таблица Tests of Between-Subjects Effects (рис. 3.34) позволяет установить, как каждый эффект влияет на каждую зависимую переменную в отдельности. В отличие от таблицы Multivariate Tests, рассматриваемая таблица позволяет выяснить, на какую конкретно зависимую переменную влияет та или иная независимая переменная и их комбинации. В нашем случае мы видим, что частота покупок определяет различия между категориями переменной q4 Возраст (Sig. = 0,045), а кратность покупок — в категориях переменной q72 Количество членов семьи (Sig. < 0,001).
 |
 | |||
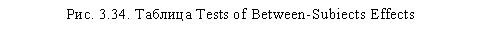 |
"2 Элементы и процессы твердотельной электроники" - тут тоже много полезного для Вас.
И наконец, последнее, что важно при практической интерпретации результатов многомерного дисперсионного анализа: какие группы каждой из рассматриваемых независимых переменных различаются на основании средних значений зависимых переменных. Это позволяют определить апостериорные тесты (в нашем случае Scheffe). Они рассчитываются для каждой комбинации зависимая переменная/ независимая переменная для всех значений индексов i. Эти таблицы по своему виду аналогичны рассмотренным в предыдущих разделах, посвященных дисперсионному анализу.
Мы не приводим полностью результаты апостериорных тестов из-за их большого объема.
На рис. 3.35 представлены результирующие таблицы Homogenous Subsets, по которым можно сделать выводы относительно различий между отдельными категориями независимых переменных на основании обеих рассматриваемых зависимых переменных. Также в этих таблицах вы видите однородные кластеры респондентов, различающиеся частотой и кратностью покупок глазированных сырков.
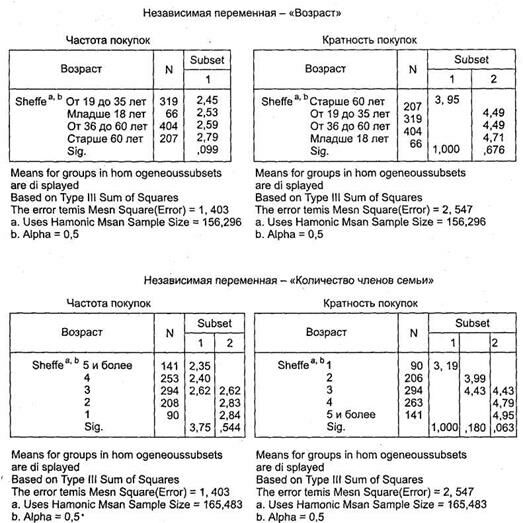 |
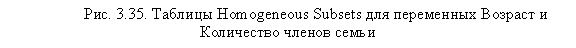 |
Итак, в данной главе мы рассмотрели статистические методы, применяемые для анализа различий между целевыми группами респондентов. Несмотря на то что данные методы (особенно обобщенная линейная модель) достаточно сложны для изучения, их применение позволяет поднять аналитическую работу на существенно более высокий уровень.



















