
Классификация параллельных ВС
Классификация параллельных вычислительных систем
Параллельные вычислительные системы, программирование которых составляет предмет нашего рассмотрения, имеют архитектуру, существенно отличающуюся от одной системы к другой, поэтому единой концепции параллельного программирования, подобной последовательному, нет. Программирование параллельных вычислительных систем требует хорошего знания их архитектуры с тем, чтобы можно было в наиболее полной степени использовать их возможности. В настоящее время известны многие сотни различных по архитектуре параллельных вычислительных систем и рассматривать каждую из них в отдельности нереально и не имеет смысла. Для параллельных вычислительных систем, несмотря на их различия, имеются определенные сходные черты, которые являются основой для их классификации. Первая из таких классификаций была предложена Флинном [4] , она является достаточно грубой, но все же позволяет разбить вычислительные системы на четыре существенно различных класса. Следует отметить, что реальные системы могут иметь признаки, относящие их к разным классам, т.е. отнесение той или иной системы к тому или иному классу расплывчато.
Все вычислительные системы Флинн классифицировал по потокам команд и данных следующим образом:
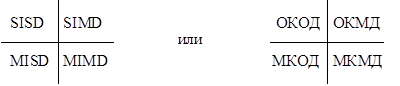
где SISD (ОКОД) – одиночный поток команд, одиночный поток данных;
SIMD (ОКМД) – одиночный поток команд, множественный поток данных;
MISD (МКОД) – множественный поток команд, одиночный поток данных;
MIMD (МКМД) – множественный поток команд, множественный поток данных.
Первый из этих классов – ОКОД – соответствует последовательным ЭВМ с одним СчА, через который реализуется один поток команд, определяющий обработку одного потока данных.
Рекомендуемые материалы
Второй класс – ОКМД – соответствует ситуации, когда в системе имеется несколько АЛУ, каждое со своей памятью данных, а УУ и СчА – в одном экземпляре. Так же, как и в системах ОКОД, УУ считывает из области кодов очередную команду, дешифрирует ее, готовится к выполнению очередной команды, но данная команда уже поступает на выполнение не в одно АЛУ, а в несколько одновременно, и каждое из них считывает операнды из ячеек с указанными адресами, но каждое из своей локальной ОП - области данных. Эта ситуация может быть проиллюстрирована следующей бытовой ситуацией: руководитель туристической группы дает указания туристам по заполнению, например, таможенной декларации, при пересечении границы – «Напишите фамилию в пункте 1» и т.д. Здесь руководитель выступает в роли общего УУ, каждый турист – в роли АЛУ, а его память и бланк – в роли локальной памяти данных. Системы ОКМД называют часто векторными или матричными, так как элементарные процессоры (АЛУ + локальная ОП) организованы в виде одномерного (вектор) или многомерного (в частности, двумерного) массива.
Третий класс – МКОД – по мнению ряда исследователей, соответствует параллельным системам конвейерного типа. Здесь имеется несколько исполнительных процессоров (ИП), каждый из которых работает под управлением своего потока команд, но обрабатываемые данные последовательно передаются от одного процессора к другому. Так, например, осуществляется сборка автомобилей на современных заводах – одно изделие продвигается последовательно по ступеням конвейера от первой к последней, на каждой ступени подвергаясь специфическим преобразованиям. Готовое изделие получается на выходе последней ступени конвейера. В конвейерных вычислительных системах также результат вычислений получается только на выходе последней ступени. Обработка каждого данного изделия (задачи) протекает столько же времени и так же точно, как при последовательной обработке, но за счет того, что обрабатывающих устройств много, сделав некоторую операцию для данной задачи, обрабатывающая ступень может перейти к выполнению такой же операции, но уже для другой задачи. Для эффективной работы конвейера требуется поток однотипных задач, тогда при условии, что на каждой ступени конвейера операция выполняется за время t, результат на выходе конвейера в стационарном режиме будет также получаться со скважностью t. Для эффективной работы систем типа ОКМД требуется, чтобы была возможность массового распараллеливания алгоритма по данным, т.е. чтобы много разных данных обрабатывались единообразно. Системы обоих указанных типов нашли широкое применение, так как многие математические и физические задачи удовлетворяют указанным ограничениям. В то же время, во многих ситуациях алгоритмы обработки более сложны, данные неоднородны, и системы указанных типов в таких ситуациях недостаточно эффективны.
Применительно к системам МКОД имеет смысл отметить, что большинство ученых все-таки полагают, что реальных прототипов таких систем в мире не существует.
Системы класса МКМД позволяют каждому исполнительному процессору работать под управлением своего потока команд. Такая архитектура – наиболее гибкая и распространенная из рассмотренных, однако наиболее сложна в реализации и программировании.
В последнее время стал популярен подход ОПМД (SPMD) – одна программа – много потоков данных, когда каждый ИП работает под управлением своего УУ, в локальную ОП каждого ИП загружена одна и та же программа (коды), но разные данные. Такой подход чаще всего используется при кластерных вычислениях.
Лекция "Предисловие" также может быть Вам полезна.
Одним из недостатков классификации Флинна является чрезмерная заполненность класса MIMD. Этот недостаток попытался устранить Р.Хокни. Классификация Хокни приведена на рис. 2.
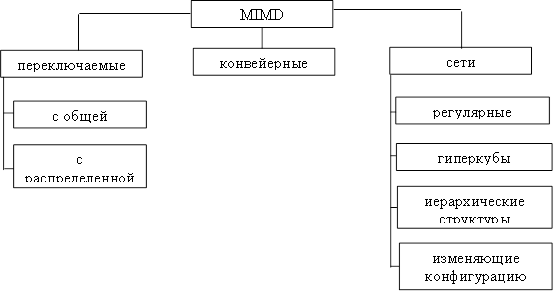
Рис. 2
Конвейерные MIMD обрабатывают множественный поток данных одним конвейером, работающим в режиме разделения времени между потоками.
В переключаемых и сетевых MIMD каждый поток данных обрабатывается отдельным устройством. В случае переключателей (PASM) каждый процессор может быть связан с любым другим, а в случае сети – только с близлежащими, номера которых задаются структурой сети.
 Прежде чем переходить к рассмотрению вопросов программирования параллельных вычислительных систем, мы приведем примеры нескольких вычислительных систем, представляющих указанные классы. Подходы к программированию будут существенным образом опираться на представления об архитектуре этих вычислительных систем.
Прежде чем переходить к рассмотрению вопросов программирования параллельных вычислительных систем, мы приведем примеры нескольких вычислительных систем, представляющих указанные классы. Подходы к программированию будут существенным образом опираться на представления об архитектуре этих вычислительных систем.




















