
Информационно-поисковые системы
Информационно-поисковые системы.
Одним из способов поиска информации является применение информационно-поисковых систем. Такие системы посещают информационные веб-ресурсы, сканируют документы, хранящиеся на них, индексируют и заносят их описания в собственные базы данных.
Индексирование – это оптимизация поиска данных в информационном пространстве по различным критериям путем ведения индексов. Характеристиками индексирования являются:
· время поиска,
· объем индексной информации,
· время модификации индексных таблиц и т.д.
Поисковые системы обычно состоят из трех компонент:
1. Программа-сканер (агент, паук, кроулер, робот), которая сканирует сеть и собирает информацию, а также выполняет ряд дополнительных функций: ведет базы данных, создает «зеркала» информационных ресурсов, ведет поиск информационных ресурсов и т.д.;
2. База данных, которая содержит всю информацию, собираемую сканерами;
Рекомендуемые материалы
3. Поисковый механизм для интерфейса взаимодействия с БД.
Существуют метапоисковые системы, которые не обладают собственной индексной базой данных, но выступают в качестве шлюза, который передает запросы на поисковые системы и возвращает результаты поиска.
Типовая схема информационно-поисковой Web-системы (Рис 3) включает в себя:
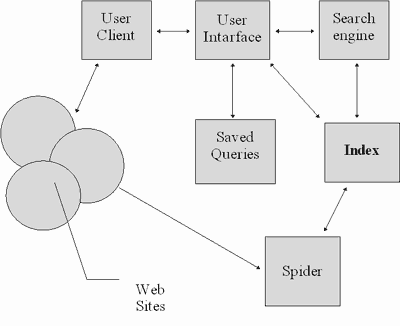
1. Браузер (client) - программа просмотра информационного ресурса;
2. Интерфейс пользователя (user interface) - способ общения пользователя с поисковым механизмом системы, т.е. с системой формирования запросов и просмотров результатов поиска.
3. Поисковый движок (search engine) – подсистема трансляции запроса пользователя, который подготавливается на информационно-поисковом языке, в формальный запрос системы, поиска ссылок на информационные ресурсы и выдачи результатов этого поиска пользователю.
4. Индексный каталог (index database) - это основной массив данных информационно-поисковой системы. Он служит для поиска адреса информационного ресурса. Архитектура устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было оценить ценность найденных информационных ресурсов.
5. Запросы пользователя (queries) сохраняются в его личной базе данных. На отладку каждого запроса уходит время, поэтому важно хранить запросы в кеш-памяти.
6. Робот-индексировщик (index robot) – программа, которая служит для сканирования Интернет и поддержки базы данных индекса в актуальном состоянии. Программа является источником информации о состоянии информационных ресурсов сети.
7. Информационный Web-ресурсы (www sites) - это информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим назначение и принцип построения компонент более подробно
Cредства сканирования используются для сбора информации о документах в Интернет. Это специальные программы, которые занимаются поиском страниц, извлекают гипертекстовые ссылки на этих страницах и автоматически индексируют информацию, которую они находят, для построения базы данных. Каждый поисковый механизм имеет набор правил сбора документов. Средства сканирования можно разделить на следующие:
1. Агенты – «интеллектуальные» поисковые средства. Они могут искать cайты заданной тематики и возвращать их списки, отсортированные по посещаемости. Агенты могут обрабатывать содержание документов, находить и индексировать другие информационные ресурсы. Они могут также быть запрограммированы для извлечения информации из баз данных. Некоторые из агентов индексируют каждое слово во встречающемся документе, другие индексируют только наиболее часто встречаемые или важные слова в документе, индексируют размер документа и число слов в нем, название, заголовки и подзаголовки и т.д.
2. Пауки – осуществляют общий поиск информации. Они сообщают о содержании найденного документа, индексируют его и извлекают итоговую информацию. Также они просматривают заголовки, ссылки и посылают проиндексированную информацию базе данных поисковой машины.
3. Кроулеры просматривают только заголовки документов и возращают ссылки на данные документы.
4. Роботы запрограммированы так, чтобы переходить по cсылкам различной глубины вложенности, выполнять индексацию и проверять ссылки в документе. Недостатком их использования является то, что они могут застревать в циклических гиперссылках. Робот перемещается по сети, запрашивает документ и рекурсивно возвращает все документы, на которые данный документ ссылается. Роботы используют стандартные cетевые протоколы. Роботы могут использоваться для выполнения задач, таких как статистический анализ, обслуживание гипертекстов (удаление мусора), исследование ресурсов, создание «зеркалов» архивов.
Вместе с этой лекцией читают "5. Мероприятия, проводимые по повышению пожарной безопасности".
Создание «зеркалов» - механизм поддержания архивов информационных ресурсов. Зеркало рекурсивно копирует полное дерево каталогов информационного ресурса, и затем регулярно обновляет те документы, которые изменились или были добавлены. Это позволяет распределить запросы пользователей между несколькими территориально удаленными информационными ресурсами, перенаправить информационные ресурсы в случае отказа информационного ресурса, обеспечить быстрый и дешевый доступ к ближайшему ресурсу, автономный доступ.
Выделим два основных типа поискового механизма
1. Каталоги или индексные архивы (Index sites) – это Web-сервера, содержащие большое количество ссылок на другие сервера или на WWW-документы. Могут быть специализированными или универсальными. Если предметная область универсальна, то ссылки обычно иерархически рассклассифицированы, в другом случае они упорядочены по алфавиту. От Search engines индексные архивы отличаются ограниченным числом ссылок, их подбором и отсутствием поиска по ключевым словам. Также в отличие от поисковых машин в каталог информация заносится по инициативе человека. Добавляемая страница должна быть привязана к принятой в каталоге иерархической классификации. Конструкция страниц значения не имеет. Каталоги ресурсов также делятся на глобальные, локальные и корпоративные. Они представляют собой базы данных с адресами ресурсов, разным масштабом информации и охватом тематики. Механизмы доступа к каталогам делятся на два класса:
· Работающие по запросу клиента на стороне Web-сервера;
· Работающие непосредственно на стороне клиента.
2. Поисковая машина (Search engine) – это Web-сервер, отрабатывающий запросы на поиск WWW-адресов документов по ключевым словам. Для поисковых систем важна конструкция документа.


















