
Язык определения данных
1. Языки БД. Язык определения данных
Внутренний язык СУБД для работы с данными состоит из 2-х частей: языка определения данныx (DDL)и языка управления данными (DML).
Язык определения данных используется для определения схемы данных, язык управления данными служит для чтения и обновления данных, хранимых в базе. Во многих СУБД предусмотрена возможность внедрения операторов подъязыка данных в программы, написанные на языках высокого уровня.
Язык DDL позволяет описывать таблицы БД и связи между ними. Результатом компиляции DDL-операторов является набор таблиц, хранимых в особых файлах, называемых системным каталогом. В системном каталоге содержатся метаданные, т.е. данные, которые описывают объекты БД.
Язык DML содержит набор операторов для манипулирования данными:
· вставки в БД данных новых сведений;
· модификации сведений;
· извлечение сведений, хранимых в базе;
· удаления сведений из базы.
Рекомендуемые материалы
Языки DML различаются базовыми конструкциями извлечения данных. Различают два типа языков: процедурный и непроцедурный. С помощью процедурного языка можно указать, какие данные необходимы, и как их можно получить. Языки сетевых и иерархических СУБД обычно бывают процедурными.
Непроцедурный язык позволяет указать лишь то, какие данные необходимо получить, без указания на то, как их следует извлекать. Реляционные СУБД обычно включают поддержку непроцедурных языков манипулирования данными, чаще всего SQL.
2. Создание БД. Способы создания БД
Обычному пользователю, как правило, не приходится создавать БД или таблицы внутри нее. Традиционно он работает с уже готовой структурой, которая уже разработана и реализована администратором БД.
С помощью операторов DDL можно:
· создать новую БД,
· определить структуру новой таблицы и создать эту таблицу,
· удалить существующую таблицу,
· изменить определение существующей таблицы,
· определить представление данных,
· обеспечить условия безопасности БД,
· создать индексы для доступа к таблицам,
· управлять размещением данных на устройствах хранения..
DDL базируется на трех командах SQL.
· CREATE – позволяет определить и создать объект БД;
· DROP - применяется для удаления существующего объекта БД;
· ALTER - изменяет определение объекта БД.
Использование DDL в процессе работы позволяет сделать структуру реляционной БД динамической. С течением времени БД может расти, в нее могут добавляться новые таблицы, без приостановки эксплуатации БД.
Операторы DDL можно использовать как в интерактивном, так и в программном SQL. Например, если программе или пользователю требуется таблица для временного хранения результатов, то допускается создать эту таблицу, заполнить ее информацией, выполнить необходимые манипуляции с данными и затем удалить ее. В реальных условиях за создание новых БД отвечает администратор.
Методы создания БД, применяемые в ведущих реляционных СУБД, имеют ряд различий. Например, в MS SQL SERVER существует оператор CREATE DATABASE, который является частью языка определения данных и служит для создания БД. Соответственно, оператор DROP DATABASE удаляет существующие БД. Эти операторы можно использовать как в интерактивном, так и в программном режиме.
Создание базы данных – это процесс указания имени базы и определения размеров и размещения файлов базы данных (первичного и вторичных файлов базы данных, файла журнала транзакций). В primary файле базы данных (расширение .mdf) записывается информация об основных её объектах – таблицах, индексах и т. д., а в файл журнала транзакций (расширение .ldf) информация о процессе работы с транзакциями (контроль целостности данных, состояние базы данных до и после выполнения транзакции). Если в процессе использования базы данных планируется размещение её на нескольких дисках, то в этом случае создаются secondary файлы (расширение .ndf). По умолчанию базы данных имеют право создавать только те пользователи, которым назначены роли sysadmin и dbcreator.
Синтаксис
CREATE DATABASE имя_базы_данных
[ON
[PRIMARY] (NAME=логическое_имя_файла,
FILENAME=‘физическое_имя_файла’
[, SIZE=размер]
[, MAXSIZE=максимальный размер]
[, FILEGROWTH=шаг_приращения_размера])
[, …n]
]
[LOG ON
(NAME=логическое_имя_файла_журнала,
FILENAME=‘физическое_имя_файла_журнала’
[, SIZE=размер_журнала])
[, …n]
]
[FOR RESTORE]
При этом следует иметь в виду, что пробелы используются для разделения элементов команды SQL, и поэтому они не могут быть частью имени базы данных, таблицы или какого-либо другого создаваемого объекта.
При создании базы данных можно указать следующие параметры:
· PRIMARY указывает файлы основной группы файлов, которая содержит все системные таблицы базы данных. Кроме того, здесь также содержатся объекты, не привязанные к пользовательским группам файлов. В любой базе данных должен быть лишь один основной (первичный) файл данных. Он служит отправной точкой базы данных и указывает на все прочие её файлы. Стандартное расширение имени основного файла данных – .mdf. Если ключевое слово PRIMARY опущено, основным файлом становится первый файл в операторе;
· FILENAME – задаёт физическое имя и путь к файлу. В пути (физическое_имя_файла) необходимо указывать папку локального диска сервера, на котором установлен SQL Server;
· SIZE – указывает размер файла: в мегабайтах, тогда используется суффикс MB (по умолчанию), или в килобайтах – в этом случае применяется суффикс KB. Минимально возможное значение – 512 кб. Параметр size задает минимальный (начальный) размер файла. Файл может увеличиваться, однако его нельзя сжать так, чтобы его объем стал меньше заданного минимального размера;
· MAXSIZE – указывает максимальный размер файла. Если размер не указан, то файл будет увеличиваться до полного заполнения диска;
· FILEGROWTH – задает шаг приращения размера файла. Если SQL Server необходимо увеличить размер файла, он увеличит его на значение, заданное параметром FILEGROWTH, причем ноль означает запрет увеличения размера. По умолчанию (если параметр FILEGROWTH не определен) – шаг приращения равен 10%, а его минимальное значение – 64 Кб. Указанный вами размер округляется до ближайшего числа, кратного 64 Кб;
· FOR RESTORE – задаёт восстановление системы по журналу транзакций в случае её сбоя. Имеется в виду сбой системы, нарушающий все выполняемые в данный момент транзакции, но не нарушающий базу данных физически. При сбое носителей, который представляет собой физическую угрозу для данных, восстановление осуществляется с резервной копии БД.
3. Создание таблиц базы данных
Таблицы создаются командой CREATE TABLE. Эта команда создает пустую таблицу, не содержащую записей. Очевидно, что данные в нее можно внести, например, с помощью команды INSERT. В команде CREATE TABLE определяется имя таблицы, и набор имен полей, которые указываются в нужном порядке. Кроме того, этой же командой оговариваются типы данных и длины полей.
Синтаксис команды CREATE TABLE следующий:
CREATE TABLE <имя таблицы>
(<имя поля1> <тип данных> [(<длина>)],
(<имя поля2> <тип данных> [(<длина>)]),
…).
Пробелы не могут быть частью имени таблицы или любого другого создаваемого объекта, поэтому для разделения слов, как правило, используется символ подчеркивания. Значение длины поля зависит от типа данных. Если его не указывать, то СУБД сама назначает значение автоматически (для числовых данных такой вариант предпочтительнее). Для данных типа CHAR указание размера обязательно. По умолчанию значение длины равно 1.
Пользователи, не являющиеся владельцами таблиц, могут задавать ссылки на эти таблицы с помощью имени владельца. Например, SA.STUDENTS (таблица STUDENTS с идентификатором разрешения SA).
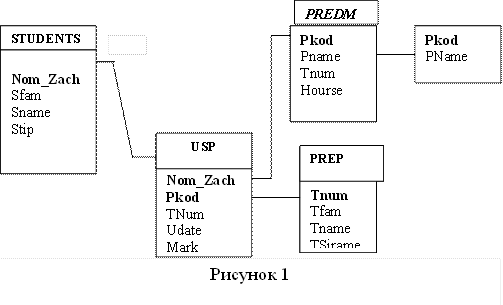
Пример (для БД, схема которой приведена на рисунке 9):
CREATE TABLE STUDENTS
(NOM_ZACH INTEGER,
SFAM CHAR (20),
SNAME CHAR (10),
STIP DECIMAL);
 |
4. Декларативные ограничения при создании таблиц
При создании таблиц могут быть заданы декларативные ограничения целостности атрибутов: значения по умолчанию (DEFAULT), задание обязательности или необязательности значений (NULL), условия проверки значения (CHECK), задание уникальность столбца и др.
Например, на значение стипендии может быть наложено ограничение (стипендия должна находиться в пределах от 20 до 50 тысяч рублей) по умолчанию значение стипендии равно 25 тыс. руб.
STIP DECIMAL DEFAULT 25 CHECK(STIP >=25 AND <=50).
Задание проверки значений атрибутов для БД “Библиотека”:
Возраст читателя должен быть не менее 17 лет:
BIRTH_DAY DATE CHECK (DATEDIFF(YEAR, GETDATE(),BIRTH_DAY) >=17)
Функция DATEDIFF (часть даты, начальная дата, конечная дата) определяет разность между начальной и конечной датами в единицах, заданных первым параметром.
Для ключевого поля задается ограничение NOT NULL PRIMARY KEY. Для запрета неопределенных значений на столбец следует наложить ограничение NOT NULL.
Часто в поле требуется реализовать ограничение, связанное уникальностью значений. В этом случае в ограничение поля при создании таблицы помещают ключевое слово UNIQUE. Можно определить группу полей как уникальную, например, в таблице USP уникальными должны быть комбинации полей NOM_ZACH и PKOD:
UNIQUE NOM_ZACH,PKOD
Ограничение PRIMARY KEY действует аналогично UNIQUE, но для таблицы должен быть определен только один первичный ключ, а уникальных полей может быть несколько.
Ключ может быть составным (как в таблице USP, где ключ состоит из атрибутов NOM_ZACH и PKOD). В этом случае ограничение PRIMARY KEY будет относиться не к одному полю, а ко всей таблице. Оператор создания таблицы USP,имеющий составной ключ:
CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL,
PKOD INTEGER,
TNUM INTEGER,
UDATE DATE ,
MARK INTEGER CHECK (MARK BETWEEN 3 AND 5),
PRIMARY KEY(NOM_ZACH, PKOD));
5. Задание ограничений ссылочной целостности
При описании таблиц задаются ограничения, обеспечивающие ссылочную целостность данных с помощью средств задания внешних ключей и NULL-ограничений. Например, таблица USP (см. рисунок 9.) подчинена двум другим таблицам: PREDM и STUDENTS. При этом таблица USP связана с таблицей STUDENTS обязательной связью, так как в ней должны быть отражены данные обо всех студентах. Каждому значению атрибута NOM_ZACH в таблице USP должно соответствовать ровно одно значение этого же атрибута в таблице STUDENTS. В таблице USP не может быть значений атрибута NOM_ZACH, которых нет в таблице STUDENTS. В то же время кто-либо из студентов мог не сдавать один или несколько экзаменов, поэтому связь с таблицей PREDM будет не обязательной. Для моделирования этих связей должны быть определены два внешних ключа (FOREIGN KEY) для полей NOM_ZACH и PKOD. Для поля NOM_ZACH должно быть задано значение NOT NULL.
Ключ FOREIGN KEY ограничивает значения, которые можно ввести в БД так, чтобы заставить внешний и родительский ключи соответствовать принципу ссылочной целостности. Одно из действий этого ограничения – отбрасывать такие значения для полей, ограниченных как внешний ключ, которые отсутствуют в родительском ключе. Синтаксис ограничения FORIGN KEY:
FOREIGN KEY <список полей> REFERENCES <имя таблицы, содержащей родительский ключ >[список полей родительского ключа].
Создадим таблицу USP с полем NOM_ZACH, определенном в качестве внешнего ключа, ссылающегося на таблицу STUDENTS.
CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL,
PKOD INTEGER,
TNUM INTEGER,
UDATE DATE ,
MARK INTEGER,
PRIMARY KEY(NOM_ZACH, PKODL)
FOREIGN KEY (NOM_ZACH) REFERENCES STUDENTS (NOM_ZACH),
FOREIGN KEY (PKOD) REFERENCES PREDM (PKOD));
Используя ограничения FOREIGN KEY, можно не указывать список полей родительского ключа, если родительский ключ имеет ограничение PRIMARY KEY. При этом в случае употребления ключей со многими полями, обязательно выполнение условия, чтобы порядок полей во внешних и первичных ключах совпадал. То есть, возможно, следующее описание таблицы.
CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL FOREIGN KEY REFERENCES STUDENTS,
PKOD INTEGER FOREIGN KEY REFERENCES PREDM,
TNUM INTEGER,
UDATE DATE ,
MARK INTEGER,
PRIMARY KEY (NOM_ZACH,PKOD));
В соответствии со стандартом, изменение или удаление значений родительского ключа не допускается. Это означает, что нельзя удалить данные о студенте из таблицы STUDENTS до тех пор, пока в таблице USP для него имеется какая-нибудь информация. Однако довольно часто возникают ситуации, когда необходимо удалить информацию о студенте, например, в случае его отчисления. В таких случаях рассматривается возможность каскадирования или ограничения действий.
При необходимости изменить или удалить текущее ссылочное значение родительского ключа существует три возможности:
1. Запретить изменения.
2. Сделав изменения в родительском ключе, произвести изменения во внешнем ключе автоматически (каскадное изменение).
3. Сделать изменение в родительском ключе и установить внешний ключ в NULL значение автоматически.
В пределах этих возможностей выполняются все команды модификации. (При использовании команды INSERT ситуация несколько отличается, так как при ее использовании помещаются новые значения родительского ключа в таблицу).
Итак, изменения в родительском ключе можно разделить на ограниченные (RESTRICTED), каскадируемые (CASCADES) и пустые (NULL) изменения. Рассмотрим примеры: предположим, что есть необходимость в изменении номера зачетной книжки, причем оценки должны сохраниться у этого же студента c новым номером. В этом случае следует указать команду UPDATE c каскадируемыми изменениями. То есть:
CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL FOREIGN KEY REFERENCES STUDENTS,
PKOD INTEGER FOREIGN KEY REFERENCES PREDM,
TNUM INTEGER,
UDATE DATE ,
MARK INTEGER,
PRIMARY KEY(NOM_ZACH,PKOD),
UPDATE OF STUDENTS CASCADES);
Если данные о студенте удаляются, удаление их должно быть выполнено сначала в главной (STUDENTS), а затем в подчиненной таблице (USP). В этом случае используется ограничение
DELETED OF STUDENTS RESTRICTED
После этого при удалении данных о студенте из таблицы STUDENT команда не будет выполнена до тех пор, пока не будут удалены его данные из таблицы USP.
Для того чтобы при удалении номера зачетки из таблицы STUDENTS его оценки сохранились в таблице USP, а в поле NOM_ZACH таблицы USP, относящемся к данному студенту появились NULL значения, необходимо указать:
CREATE TABLE USP
(NOM_ZACH INTEGER FOREIGN KEY REFERENCES STUDENTS,
PKOD INTEGER FOREIGN KEY REFERENCES PREDM,
TNUM INTEGER,
UDATE DATE ,
MARK INTEGER,
PRIMARY KEY(NOM_ZACH,PKOD),
DELETED OF STUDENTS NULLS);
В этом случае ограничения NOT NULL для поля NOM_ZACH, быть не должно.
6. Изменение таблиц
Изменение таблицы осуществляется командой ALTER TABLE. Чаще всего с помощью этой команды добавляют поля к таблице.
ALTER TABLE <имя таблицы>
ADD <имя поля> <тип данных> <длина поля>;
Поле будет добавлено с NULL значениями для всех записей таблицы. Кроме того, новое поле станет последним по порядку в таблице. Допускается добавление сразу нескольких полей. Они должны быть отделены друг от друга запятыми. Изменение структуры таблицы в тот момент, когда она используется, может привести к потере информации. Поэтому БД лучше разрабатывать так, чтобы использовать команду изменения в самом крайнем случае.
В таблицу могут быть добавлены не только новые поля, но и новые ограничения с помощью команды ADD CONSTRAINT <имя ограничения>. Имя ограничения состоит из краткого названия типа ограничения (например, PK для первичного ключа, ID для индекса), символа подчёркивания, имени поля или таблицы и порядкового номера ограничения данного типа, если к одному объекту задаётся несколько ограничений одного типа.
Например, добавить ограничение PRIMARY KEY с именем PK_Tnum для поля TNum таблицы Prep.
ALTER TABLE Prep
ADD CONSTRAINT PK_ Tnum PRIMARY KEY (TNum)
Для добавления ограничения, задающего значение по умолчанию:
ALTER TABLE USP
ADD CONSTRAINT Def_Mark DEFAULT 5 FOR MARK.
Для добавления ограничения проверки значения:
ALTER TABLE USP
ADD CONSTRAINT Сh_Mark CHECK MARK IN (2,3,4,5).
Удаление таблиц выполняется с помощью команды DROP TABLE. Для того чтобы иметь возможность удалить таблицу, пользователь должен быть ее владельцем. Кроме того, перед удалением SQL требует очистки таблицы от данных, что позволяет избежать случайной и невосполнимой потери информации. Таким образом, таблица с находящимися в ней данными не может быть удалена. Перед удалением следует убедиться, что на таблицу не ссылается никакая другая таблица, и что она не используется в каком-либо представлении. Синтаксис команды удаления:
DROP TABLE <имя таблицы>
7. Создание индексов в системе SQL-сервер
Индексом принято называть упорядоченный список полей или групп полей в таблице. Таблицы могут иметь огромное количество записей, при этом записи не находятся в каком-либо определенном порядке, поэтому на их поиск по указанному критерию может потребоваться достаточно продолжительное время. Когда создается индекс в поле, база данных запоминает порядок всех значений этого поля в специальной области памяти. При этом каждое значение поля в индексе содержит ссылку на физическое расположение записи в самой таблице.
Индексы могут состоять сразу из нескольких полей, при этом первое поле является как бы главным, второе упорядочивается внутри первого, третье внутри второго и т.д.
Таким образом, индексы представляют собой наборы уникальных значений для некоторой таблицы с соответствующими ссылками на данные, расположенные в самой таблице. Индексы являются удобным внутренним механизмом системы SQL-сервер, с помощью которого осуществляется доступ к данным наиболее оптимальным способом.
В индексы следует включать поля, к которым часто выдаются запросы при выполнении операций поиска. К ним относятся:
· основные ключи;
· внешние ключи, а также другие поля, часто используемые для соединения таблиц;
· поля, в которых производится поиск диапазонов ключевых значений;
· поля, к которым производится упорядоченный доступ.
Для создания индекса используется оператор CREATE INDEX.
Синтаксис:
CREATE INDEX имя_индекса ON таблица (поле[, …n])
Таблица, для которой создается индекс, должна уже существовать и содержать имена индексируемых полей. При этом имя индекса не может быть использовано для чего-либо другого в базе данных и SQL сам решает, когда он необходим для работы и использует его автоматически.
Для создания уникальных (не содержащих повторяющихся значений) индексов используется ключевое слово UNIQUE в операторе CREATE INDEX (CREATE UNIQUE INDEX …).
Например, создать индекс c именем Ind_Tnum для поля TNUM таблицы PREDM:
CREATE INDEX Ind_Tnum ON PREDM (TNUM)
Для удаления индекса используется оператор DROP INDEX.
Синтаксис:
DROP INDEX таблица.индекс[,…n]
Кластеризованный индекс
Использование опции Clustered index позволяет произвести так называемое кластерное индексирование, в результате чего будут отсортированы данные в самой таблице согласно порядку этого индекса, и вся добавляемая информация будет приводить к изменению физического порядка данных. При этом нужно учитывать, что в таблице может быть определён только один кластерный индекс.
8. КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Перечислите основные функции языка определения данных.
2. Назовите основные операторы языка DDL.
3. Перечислите основные функции языка управления данными.
4. Назовите основные операторы языка DML.
Рекомендуем посмотреть лекцию "3.2. Классификация ИВС".
5. Каким образом задаются декларативные ограничения целостности при создании таблиц?
6. Каким образом задаются ограничения ссылочной целостности при создании таблиц?
7. Возможно ли изменение или удаление значений первичного ключа в главной таблице, если в подчиненной таблице имеются связанные записи?
8. Как добавить в существующую таблицу новое ограничение?
9. Какая команда служит для создания индекса?
10. Что понимают под кластеризованным индексом?



















