
Даталогическое проектирование
Даталогическое проектирование
В реляционных БД даталогическое или логическое проектирование приводит к разработке схемы БД, то есть совокупности схем отношений, которые адекватно моделируют абстрактные объекты предметной области и семантические связи между этими объектами. Основой анализа корректности схемы являются так называемые функциональные зависимости между атрибутами БД. Некоторые зависимости между атрибутами отношений являются нежелательными из-за побочных эффектов и аномалий, которые они вызывают при модификации БД. При этом под процессом модификации БД мы понимаем внесение новых данных в БД или удаление некоторых данных из БД, а также обновление значений некоторых атрибутов.
Однако этап логического или даталогического проектирования не заканчивается проектированием схемы отношений. В общем случае в результате выполнения этого этапа должны быть получены следующие результирующие документы:
- Описание концептуальной схемы БД в терминах выбранной СУБД.
- Описание внешних моделей в терминах выбранной СУБД.
- Описание декларативных правил поддержки целостности базы данных.
- Разработка процедур поддержки семантической целостности базы данных.
- Однако перед тем как описывать построенную схему в терминах выбранной СУБД, нам надо выстроить эту схему. Именно этому процессу и посвящен данный раздел.
- Мы должны построить корректную схему БД, ориентируясь на реляционную модель данных.
ОПРЕДЕЛЕНИЕ
Корректной назовем схему БД, в которой отсутствуют нежелательные зависимости между атрибутами отношений.
Процесс разработки корректной схемы реляционной БД называется логическим проектированием БД.
Проектирование схемы БД может быть выполнено двумя путями:
- путем декомпозиции (разбиения), когда исходное множество отношений, входящих в схему БД заменяется другим множеством отношений (число их при этом возрастает), являющихся проекциями исходных отношений;
- путем синтеза, то есть путем компоновки из заданных исходных элементарных зависимостей между объектами предметной области схемы БД.
Классическая технология проектирования реляционных баз данных связана с теорией нормализации, основанной на анализе функциональных зависимостей между атрибутами отношений. Понятие функциональной зависимости является фундаментальным в теории нормализации реляционных баз данных. Мы определим его далее, а пока коснемся смысла этого понятия. Функциональные зависимости определяют устойчивые отношения между объектами и их свойствами в рассматриваемой предметной области. Именно поэтому процесс поддержки функциональных зависимостей, характерных для данной предметной области, является базовым для процесса проектирования.
Процесс проектирования с использованием декомпозиции представляет собой процесс последовательной нормализации схем отношений, при этом каждая последующая итерация соответствует нормальной форме более высокого уровня и обладает лучшими свойствами по сравнению с предыдущей.
Рекомендуемые материалы
Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений.
В теории реляционных БД обычно выделяется следующая последовательность нормальных форм:
- первая нормальная форма (1NF);
- вторая нормальная форма (2NF);
- третья нормальная форма (3NF);
- нормальная форма Бойса—Кодда (BCNF);
- четвертая нормальная форма (4NF);
- пятая нормальная форма, или форма проекции-соединения (5NF или PJNF).
Основные свойства нормальных форм:
- каждая следующая нормальная форма в некотором смысле улучшает свойства предыдущей;
- при переходе к следующей нормальной форме свойства предыдущих нормальных форм сохраняются.
В основе классического процесса проектирования лежит последовательность переходов от предыдущей нормальной формы к последующей. Однако в процессе декомпозиции мы сталкиваемся с проблемой обратимости, то есть возможности восстановления исходной схемы. Таким образом, декомпозиция должна сохранять эквивалентность схем БД при замене одной схемы на другую.
ОПРЕДЕЛЕНИЕ
Схемы БД называются эквивалентными, если содержание исходной БД может быть получено путем естественного соединения отношений, входящих в результирующую схему, и при этом не появляется новых кортежей в исходной БД.
При выполнении эквивалентных преобразований сохраняется множество исходных фундаментальных функциональных зависимостей между атрибутами отношений.
Функциональные зависимости определяют не текущее состояние БД, а все возможные ее состояния, то есть они отражают те связи между атрибутами, которые присущи реальному объекту, который моделируется с помощью БД.
Поэтому определить функциональные зависимости по текущему состоянию БД можно только в том случае, если экземпляр БД содержит абсолютно полную информацию (то есть никаких добавлений и модификации БД не предполагается). В реальной жизни это требование невыполнимо, поэтому набор функциональных зависимостей задает разработчик, системный аналитик, исходя из глубокого системного анализа предметной области.
Приведем ряд основных определений.
Функциональной зависимостью набора атрибутов В отношения R от набора атрибутов A того же отношения, обозначаемой как R.A  R.B или A B
R.B или A B
называется такое соотношение проекций R[A] и R[B], при котором в каждый момент времени любому элементу проекции R[A] соответствует только один элемент проекции R[B], входящий вместе с ним в какой-либо кортеж отношения R.
Функциональная зависимость R.A R.B называется полной, если набор атрибутов B функционально зависит от A и не зависит функционально от любого подмножества A, то есть R.A R.B называется полной, если:
 A1
A1  A R.A -/ R.B,
A R.A -/ R.B,
что читается следующим образом:
для любого A1, являющегося подмножеством А, R.B функционально не зависит от R.A, в противном случае зависимость R.A R.B называется неполной.
Функциональная зависимость R.A R.B называется транзитивной, если существует набор атрибутов С такой, что:
1. С не является подмножеством А.
2. С не включает в себя B.
3. Существует функциональная зависимость R.A R.C.
4. Не существует функциональной зависимости R.C R.A.
5. Существует функциональная зависимость R.C R.B.
Возможным ключом отношения называется набор атрибутов отношения, который полностью и однозначно (функционально полно) определяет значения всех остальных атрибутов отношения, то есть возможный ключ — это набор атрибутов, однозначно определяющий кортеж отношения, и при этом при удалении любого атрибута из этого набора его свойство однозначной идентификации кортежа теряется.
А может ли быть ситуация, когда отношение не имеет возможного ключа? Давайте вспомним определение отношения: отношение — это подмножество декартова произведения множества доменов. И в полном декартовом произведении все наборы значений различны, тем более в его подмножестве. Значит, обязательно для каждого отношения всегда существует набор атрибутов, по которому можно однозначно определить кортеж отношения. В вырожденном случае это просто полный набор атрибутов отношения, потому что если мы зададим для всех атрибутов конкретные значения, то, по определению отношения, мы получим только один кортеж.
В общем случае в отношении может быть несколько возможных ключей.
Среди всех возможных ключей отношения обычно выбирают один, который считается главным и который называют первичным ключом отношения.
Неключевым атрибутом называется любой атрибут отношения, не входящий в состав ни одного возможного ключа отношения.
Взаимно-независимые атрибуты — это такие атрибуты, которые не зависят функционально один от другого.
Если в отношении существует несколько функциональных зависимостей, то каждый атрибут или набор атрибутов, от которого зависит другой атрибут, называется детерминантом отношения.
Для функциональных зависимостей как фундаментальной основы проекта БД были проведены исследования, позволяющие избежать избыточного их представления. Ряд зависимостей могут быть выведены из других путем применения правил, названных аксиомами Армстронга, по имени исследователя, впервые сформулировавшего их. Это три основных аксиомы:
1. Рефлексивность: если В является подмножеством А, то А B
2. Дополнение: если АB , то A.C B.C
3. Транзитивность: если A B и B C , то A C.
Доказано, что данные правила являются полными и исчерпывающими, то есть, применяя их, из заданного множества функциональных зависимостей можно вывести все возможные функциональные зависимости.
Множество всех возможных функциональных зависимостей, выводимое из заданного набора исходных функциональных зависимостей, называется его замыканием.
ОПРЕДЕЛЕНИЕ
Отношение находится в первой нормальной форме тогда и только тогда, когда на пересечении каждого столбца и каждой строки находятся только элементарные значения атрибутов.
В некотором смысле это определение избыточно, потому что собственно оно определяет само отношение в теории реляционных баз данных. Однако в силу исторически сложившихся обстоятельств и для преемственности такое определение первой нормальной формы существует и мы должны с ним согласиться. Отношения, находящиеся в первой нормальной форме, часто называют просто нормализованными отношениями. Соответственно, ненормализованные отношения могут интерпретироваться как таблицы с неравномерным заполнением, например таблица "Расписание", которая имеет вид:
| Преподаватель | День недели | Номер пары | Название дисциплины | Тип занятий | Группа |
| Петров В. И. | Понед. | 1 | Теор. выч. проц. | Лекция | 4906 |
| Вторник | 1 | Комп. графика | Лаб. раб.. | 4907 | |
| Вторник | 2 | Комп. графика | Лаб. раб | 4906 | |
| Киров В. А. | Понед. | 2 | Теор. информ. | Лекция | 4906 |
| Вторник | 3 | Пр-е на С++ | Лаб. раб. | 4907 | |
| Вторник | 4 | Пр-е на С++ | Лаб. раб. | 4906 | |
| Серов А. А. | Понед. | 3 | Защита инф. | Лекция. | 4944 |
| Среда | 3 | Пр-е на VB | Лаб. раб | 4942 | |
| Четверг | 4 | Пр-е на VB | Лаб. раб. | 4922 |
Здесь на пересечении одной строки и одного столбца находится целый набор элементарных значений, соответствующих набору дней, перечню пар, набору дисциплин, по которым проводит занятия один преподаватель.
Для приведения отношения "Расписание" к первой нормальной форме необходимо дополнить каждую строку фамилией преподавателя.
ОПРЕДЕЛЕНИЕ
Отношение находится во второй нормальной форме тогда и только тогда, когда оно находится в первой нормальной форме и не содержит неполных функциональных зависимостей непервичных атрибутов от атрибутов первичного ключа.
| Преподаватель | День недели | Номер пары | Название дисциплины | Тип занятий | Группа |
| Петров В. И. | Понед. | 1 | Теор. выч. проц. | Лекция | 4906 |
| Петров В. И. | Вторник | 1 | Комп. графика | Лаб. раб.. | 4907 |
| Петров В. И. | Вторник | 2 | Комп. графика | Лаб. раб | 4906 |
| Киров В. А. | Понед. | 2 | Теор. информ. | Лекция | 4906 |
| Киров В. А. | Вторник | 3 | Пр-е на С++ | Лаб. раб. | 4907 |
| Киров В. А. | Вторник | 4 | Пр-е на С++ | Лаб. раб. | 4906 |
| Серов А. А. | Понед. | 3 | Защита инф. | Лекция. | 4944 |
| Серов А. А. | Среда | 3 | Пр-е на VB | Лаб. раб | 4942 |
| Серов А. А. | Четверг | 4 | Пр-е на VB | Лаб. раб. | 4922 |
Рассмотрим отношение, моделирующее сдачу студентами текущей сессии. Структура этого отношения определяется следующим набором атрибутов:
(ФИО, Номер зач.кн., Группа, Дисциплина, Оценка)
Так как каждый студент сдает целый набор дисциплин в процессе сессии, то первичным ключом отношения может быть (Номер. зач.кн., Дисциплина), который однозначно определяет каждую стоку отношения. С другой стороны, атрибуты ФИО и Группа зависят только от части первичного ключа — от значения атрибута Номер зач. кн., поэтому мы должны констатировать наличие неполных функциональных зависимостей в данном отношении. Для приведения данного отношения ко второй нормальной форме следует разбить его на проекции, при этом должно быть соблюдено условие восстановления исходного отношения без потерь. Такими проекциями могут быть два отношения:
(ФИО, Номер.зач.кн., Группа) (Номер зач.кн., Дисциплина, Оценка)
Этот набор отношений не содержит неполных функциональных зависимостей, и поэтому эти отношения находятся во второй нормальной форме.
А почему надо приводить отношения ко второй нормальной форме? Иначе говоря, какие аномалии или неудобства могут возникнуть, если мы оставим исходное отношение и не будем его разбивать на два? Давайте рассмотрим ситуацию, когда студент переведен из одной группы в другую. Тогда в первом случае (если мы не разбивали исходное отношение на два) мы должны найти все записи с данным студентом и в них изменить значение атрибута Группа на новое. Во втором же случае меняется только один кортеж в первом отношении. И конечно, опасность нарушения корректности (непротиворечивости содержания) БД в первом случае выше. Может получиться так, что часть кортежей поменяет значения атрибута Группа, а часть по причине сбоя в работе аппаратуры останется в старом состоянии. И тогда наша БД будет содержать записи, которые относят одного студента одновременно к разным группам. Чтобы этого не произошло, мы должны принимать дополнительные непростые меры, например организовывать процесс согласованного изменения с использованием сложного механизма транзакций, который мы будем рассматривать в лекциях, посвященных вопросам распределенного доступа к БД. Если же мы перешли ко второй нормальной форме, то мы меняем только один кортеж. Кроме того, если у нас есть студенты, которые еще не сдавали экзамены, то в исходном отношении мы вообще не можем хранить о них информацию, а во второй схеме информация о студентах и их принадлежности к конкретной группе хранится отдельно от информации, которая связана со сдачей экзаменов, и поэтому мы можем в этом случае отдельно работать со студентами и отдельно хранить и обрабатывать информацию об успеваемости и сдаче экзаменов, что в действительности и происходит.
ОПРЕДЕЛЕНИЕ
Отношение находится в третьей нормальной форме тогда и только тогда, когда оно находится во второй нормальной форме и не содержит транзитивных зависимостей.
Рассмотрим отношение, связывающее студентов с группами, факультетами и специальностями, на которых он учится.
(ФИО, Номер зач.кн., Группа, Факультет, Специальность, Выпускающая кафедра)
Первичным ключом отношения является Номер зач.кн., однако рассмотрим остальные функциональные зависимости. Группа, в которой учится студент, однозначно определяет факультет, на котором он учится, а также специальность и выпускающую кафедру. Кроме того, выпускающая кафедра однозначно определяет факультет, на котором обучаются студенты, выпускаемые по данной кафедре. Но если мы предположим, что одну специальность могут выпускать несколько кафедр, то специальность не определяет выпускающую кафедру. В этом случае у нас есть следующие функциональные зависимости:
Номер зач.кн. ФИО
Номер зач.кн. Группа
Номер зач.кн. Факультет
Номер зач.кн. Специальность
Номер зач.кн. Выпускающая кафедра
Группа Факультет
Группа Специальность
Группа Выпускающая кафедра
Выпускающая кафедра Факультет
И эти зависимости образуют транзитивные группы. Для того чтобы избежать этого, мы можем предложить следующий набор отношений:
(Номер.зач.кн., ФИО, Специальность, Группа)
(Группа, Выпускающая кафедра)
(Выпускащая кафедра, Факультет)
Первичные ключи отношений выделены.
Теперь необходимо удостовериться, что при естественном соединении мы не потеряем ни одной строки и не получим лишних кортежей. И это упражнение я предлагаю выполнить вам самостоятельно.
Полученный набор отношений находится в третьей нормальной форме.
ОПРЕДЕЛЕНИЕ
Отношение находится в нормальной форме Бойса—Кодда, если оно находится в третьей нормальной форме и каждый детерминант отношения является возможным ключом отношения.
Рассмотрим отношение, моделирующее сдачу студентом текущих экзаменов. Предположим, что студент может сдавать экзамен по одной дисциплине несколько раз, если он получил неудовлетворительную оценку. Допустим, что во избежание возможных полных однофамильцев мы можем однозначно идентифицировать студента номером его зачетной книги, но, с другой стороны, у нас ведется электронный учет текущей успеваемости студентов, поэтому каждому студенту -присваивается в период его обучения в вузе уникальный номер-идентификатор. Отношение, которое моделирует сдачу текущей сессии, имеет следующую структуру:
(Номер зач.кн., Идентификатор_студента, Дисциплина, Дата, Оценка)
Возможными ключами отношения являются Номер_зач.кн, Дисциплина, Дата и Иден-тификатор_студента, Дисциплина, Дата.
Какие функциональные зависимости у нас имеются?
Номер_зач.кн, Дисциплина, Дата Оценка;
Идентификатор_студента, Дисциплина, Дата Оценка;
Номер зач.кн. Идентификатор_студента;
Идентификатор_студента Номер зач.кн.
- Откуда взялись две последние функциональные зависимости? Но ведь мы предварительно описали, что каждому студенту ставится в соответствие один номер зачетной книжки и один Идентификатор_студента, поэтому по значению Номер зач.кн. можно однозначно определить Идентификатор_студента (это третья зависимость) и обратно (и это четвертая зависимость). Оценим это отношение.
- Это отношение находится в третьей нормальной форме, потому что неполных функциональных зависимостей непервичных атрибутов от атрибутов возможного ключа здесь не присутствует и нет транзитивных зависимостей. А как же третья и четвертая зависимости, разве они не являются неполными? Нет, потому что зависимым не является непервичный атрибут, то есть атрибут, не входящий ни в один возможный ключ. Поэтому придраться к этому мы не можем. Но вот под четвертую нормальную форму наше отношение не подходит, потому что у нас есть два детерминанта Номер зач.кн. и Идентификатор_студента, которые не являются возможными ключами отношения. Для приведения отношения к нормальной форме Бойса—Кодда надо разделить отношение, например, на два со следующими схемами:
· (Идентификатор_студента, Дисциплина, Дата, Оценка)
· (Номер зач.кн., Идентификатор_студента)
или наоборот:
(Номер зач.кн., Дисциплина, Дата, Оценка)
(Номер зач.кн., Идентификатор_студента)
Эти схемы равнозначны с точки зрения теории нормализации, поэтому выбирать проектировщикам следует исходя из некоторых дополнительных рассуждений. Ну, например, если учесть, что зачетные книжки могут теряться, то как они будут восстанавливаться: если с тем же самым номером, то нет разницы, но если с новым номером, то тогда первая схема предпочтительней.
В большинстве случаев достижение третьей нормальной формы или даже формы Бойса—Кодда считается достаточным для реальных проектов баз данных, однако в теории нормализации существуют нормальные формы высших порядков, которые уже связаны не с функциональными зависимостями между атрибутами отношений, а отражают более тонкие вопросы семантики предметной области и связаны с другими видами зависимостей. Прежде чем перейти к рассмотрению нормальных форм высших порядков, дадим еще несколько определений.
ОПРЕДЕЛЕНИЕ
В отношении R (A, B, C) существует многозначная зависимость (multi valid dependence, MVD) R.A ->> R.B в том и только в том случае, если множество значений B, соответствующее паре значений A и C, зависит только от A и не зависит от С.
Когда мы рассматривали функциональные зависимости, то каждому значению детерминанта соответствовало только одно значение зависимого от него атрибута. При рассмотрении многозначных зависимостей мы выделяем случаи, когда одному значению некоторого атрибута соответствует устойчиво постоянное множество значений другого атрибута. Когда это может быть? Рассмотрим конкретную ситуацию, понятную всем студентам. Пусть дано отношение, которое моделирует предстоящую сдачу экзаменов на сессии. Допустим, оно имеет вид:
(Номер зач.кн., Группа, Дисциплина)
Перечень дисциплин, которые должен сдавать студент, однозначно определяется не его фамилией, а номером группы (то есть специальностью, на которой он учится).
В данном отношении существуют следующие две многозначные зависимости:
Группа ->> Дисциплина
Группа ->> Номер зач.кн.
Это означает, что каждой группе однозначно соответствует перечень дисциплин по учебному плану и номер группы определяет список студентов, которые в этой группе учатся.
Если мы будем работать с исходным отношением, то мы не сможем хранить информацию о новой группе и ее учебном плане — перечне дисциплин, которые должна пройти группа до тех пор, пока в нее не будут зачислены студенты. При изменении перечня дисциплин по учебному плану, например при добавлении новой дисциплины, внести эти изменения в отношение для всех студентов, занимающихся в данной группе, весьма затруднительно. С другой стороны, если мы добавляем студента в уже существующую группу, то мы должны добавить множество кортежей, соответствующих перечню дисциплин для данной группы. Эти аномалии модификации отношения как раз и связаны с наличием двух многозначных зависимостей.
В теории реляционных баз данных доказывается, что в общем случае в отношении R (A, B, C) существует многозначная зависимость R.A ->> R.B в том и только в том случае, когда существует многозначная зависимость R.A ->> R.C.
Дальнейшая нормализация отношений, подобных нашему, основывается на теореме Фейджина.
ТЕОРЕМА ФЕЙДЖИНА
Отношение R (A, B, C) можно спроецировать без потерь в отношения R1 (A, B) и R2 (A, C) в том и только в том случае, когда существует MVD A ->> B | C ( что равнозначно наличию двух зависимостей A ->> B и A ->> C).
Под проецированием без потерь понимается такой способ декомпозиции отношения путем применения операции проекции, при котором исходное отношение полностью и без избыточности восстанавливается путем естественного соединения полученных отношений. Практически теорема доказывает наличие эквивалентной схемы для отношения, в котором существует несколько многозначных зависимостей.
ОПРЕДЕЛЕНИЕ
Отношение R находится в четвертой нормальной форме (4NF) в том и только в том случае, если в случае существования многозначной зависимости A ->> B все остальные атрибуты R функционально зависят от A.
В нашем примере можно произвести декомпозицию исходного отношения в два отношения:
(Номер зач.кн., Группа)
(Группа, Дисциплина)
Оба эти отношения находятся в 4NF и свободны от отмеченных аномалий. Действительно, обе операции модификации теперь упрощаются: добавление нового студента связано с добавлением всего одного кортежа в первое отношение, а добавление новой дисциплины выливается в добавление одного кортежа во второе отношение, кроме того, во втором отношении мы можем хранить любое количество групп с определенным перечнем дисциплин, в которые пока еще не зачислены студенты.
Последней нормальной формой является пятая нормальная форма 5NF, которая связана с анализом нового вида зависимостей, зависимостей "проекции соединения" (project-join зависимости, обозначаемые как PJ-зависимости). Этот вид
зависимостей является в некотором роде обобщением многозначных зависимостей.
ОПРЕДЕЛЕНИЕ
Отношение R (X, Y,…, Z) удовлетворяет зависимости соединения (X, Y,…, Z) в том и только в том случае, когда R восстанавливается без потерь путем соединения своих проекций на X, Y, …, Z. Здесь X, Y, …, Z — наборы атрибутов отношения R.
Наличие PJ-зависимости в отношении делает его в некотором роде избыточным и затрудняет операции модификации.
ОПРЕДЕЛЕНИЕ
Отношение R находится в пятой нормальной форме (нормальной форме проекции-соединения — PJ/NF) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R.
Рассмотрим отношение R1:
R1(Преподаватель, Кафедра, Дисциплина)
Предположим, что каждый преподаватель может работать на нескольких кафедрах и на каждой кафедре может вести несколько дисциплин. В этом случае ключом отношения является полный набор из трех атрибутов. В отношении отсутствуют многозначные зависимости, и поэтому отношение находится в 4NF.
Введем следующие обозначения наборов атрибутов:
ПК (Преподаватель, Кафедра)
ПД (Преподаватель, Дисциплина)
КД (Кафедра, Дисциплина)
Допустим, что отношение R1 удовлетворяет зависимости проекции соединения (ПК, ПД, КД). Тогда отношение R1 не находится в NF/PJ, потому что единственным ключом его является полный набор атрибутов, а наличие зависимости PJ связано с наборами атрибутов, которые не составляют возможные ключи отношения R1. Для того чтобы привести это отношение к NF/PJ, его надо представить в виде трех отношений:
R2 (Преподаватель, Кафедра)
R3 (Преподаватель, Дисциплина)
R4 (Кафедра, Дисциплина)
Пятая нормальная форма редко используется на практике. В большей степени она является теоретическим исследованием. Очень тяжело определить само наличие зависимостей "проекции—соединения", потому что утверждение о наличии такой зависимости делается для всех возможных состояний БД, а не только для текущего экземпляра отношения R1. Однако знание о возможном наличии подобных зависимостей, даже теоретическое, нам все же необходимо.
Инфологическое моделирование
Инфологическая модель применяется на втором этапе проектирования БД, то есть после словесного описания предметной области. Зачем нужна инфологическая модель и какую пользу она дает проектировщикам? Еще раз хотим напомнить, что процесс проектирования длительный, он требует обсуждений с заказчиком, со специалистами в предметной области. Наконец, при разработке серьезных корпоративных информационных систем проект базы данных является тем фундаментом, на котором строится вся система в целом, и вопрос о возможном кредитовании часто решается экспертами банка на основании именно грамотно сделанного инфологического проекта БД. Следовательно, инфологическая модель должна включать такое формализованное описание предметной области, которое легко будет "читаться" не только специалистами по базам данных. И это описание должно быть настолько емким, чтобы можно было оценить глубину и корректность проработки проекта БД, и конечно, как говорилось раньше, оно не должно быть привязано к конкретной СУБД. Выбор СУБД — это отдельная задача, для корректного ее решения необходимо иметь проект, который не привязан ни к какой конкретной СУБД.
Инфологическое проектирование прежде всего связано с попыткой представления семантики предметной области в модели БД. Реляционная модель данных в силу своей простоты и лаконичности не позволяет отобразить семантику, то есть смысл предметной области. Ранние теоретико-графовые модели в большей степени отображали семантику предметной области. Они в явном виде определяли иерархические связи между объектами предметной области.
Проблема представления семантики давно интересовала разработчиков, и в семидесятых годах было предложено несколько моделей данных, названных семантическими моделями. К ним можно отнести семантическую модель данных, предложенную Хаммером (Hammer) и Мак-Леоном (McLeon) в 1981 году, функциональную модель данных Шипмана (Shipman), также созданную в 1981 году, модель "сущность—связь", предложенную Ченом (Chen) в 1976 году, и ряд других моделей. У всех моделей были свои положительные и отрицательные стороны, но испытание временем выдержала только последняя. И в настоящий момент именно модель Чена "сущность—связь", или "Entity Relationship", стала фактическим стандартом при инфологическом моделировании баз данных. Общепринятым стало сокращенное название ER-модель, большинство современных CASE-средств содержат инструментальные средства для описания данных в формализме этой модели. Кроме того, разработаны методы автоматического преобразования проекта БД из ER-модели в реляционную, при этом преобразование выполняется в даталогическую модель, соответствующую конкретной СУБД. Все CASE-системы имеют развитые средства документирования процесса разработки БД, автоматические генераторы отчетов позволяют подготовить отчет о текущем состоянии проекта БД с подробным описанием объектов БД и их отношений как в графическом виде, так и в виде готовых стандартных печатных отчетов, что существенно облегчает ведение проекта.
В настоящий момент не существует единой общепринятой системы обозначений для ER-модели и разные CASE-системы используют разные графические нотации, но разобравшись в одной, можно легко понять и другие нотации.
Модель "сущность-связь"
Как любая модель, модель "сущность—связь" имеет несколько базовых понятий, которые образуют исходные кирпичики, из которых строятся уже более сложные объекты по заранее определенным правилам.
Эта модель в наибольшей степени согласуется с концепцией объектно-ориентированного проектирования, которая в настоящий момент несомненно является базовой для разработки сложных программных систем, поэтому многие понятия вам могут показаться знакомыми, и если это действительно так, то тем проще вам будет освоить технологию проектирования баз данных, основанную на ER-модели.
В основе ER-модели лежат следующие базовые понятия:
- Сущность, с помощью которой моделируется класс однотипных объектов. Сущность имеет имя, уникальное в пределах моделируемой системы. Так как сущность соответствует некоторому классу однотипных объектов, то предполагается, что в системе существует множество экземпляров данной сущности. Объект, которому соответствует понятие сущности, имеет свой набор атрибутов — характеристик, определяющих свойства данного представителя класса. При этом набор атрибутов должен быть таким, чтобы можно было различать конкретные экземпляры сущности. Например, у сущности Сотрудник может быть следующий набор атрибутов: Табельный номер, Фамилия, Имя, Отчество, Дата рождения, Количество детей, Наличие родственников за границей. Набор атрибутов, однозначно идентифицирующий конкретный экземпляр сущности, называют ключевым. Для сущности Сотрудник ключевым будет атрибут Табельный номер, поскольку для всех сотрудников данного предприятия табельные номера будут различны. Экземпляром сущности Сотрудник будет описание конкретного сотрудника предприятия. Одно из общепринятых графических обозначений сущности — прямоугольник, в верхней части которого записано имя сущности, а ниже перечисляются атрибуты, причем ключевые атрибуты помечаются, например, подчеркиванием или специальным шрифтом (рис. 7.1):

Рис. 7.1. Пример определения сущности в модели ER
Между сущностями могут быть установлены связи — бинарные ассоциации, показывающие, каким образом сущности соотносятся или взаимодействуют между собой. Связь может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). Она показывает, как связаны экземпляры сущностей между собой. Если связь устанавливается между двумя сущностями, то она определяет взаимосвязь между экземплярами одной и другой сущности. Например, если у нас есть связь между сущностью "Студент" и сущностью "Преподаватель" и эта связь — руководство дипломными проектами, то каждый студент имеет только одного руководителя, но один и тот же преподаватель может руководить множеством студентов-дипломников. Поэтому это будет связь "один-ко-многим" (1:М), один со стороны "Преподаватель" и многие со стороны "Студент" (см. рис. 7.2).
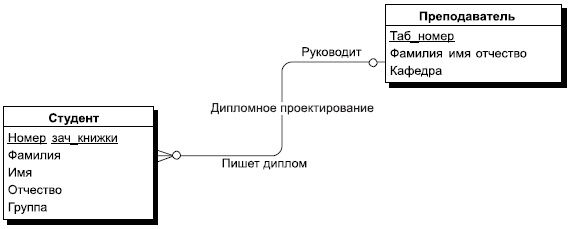
Рис. 7.2. Пример отношения "один-ко-многим" при связывании сущностей "Студент" и "Преподаватель"
В разных нотациях мощность связи изображается по-разному. В нашем примере мы используем нотацию CASE системы POWER DESIGNER, здесь множественность изображается путем разделения линии связи на 3. Связь имеет общее имя "Дипломное проектирование" и имеет имена ролей со стороны обеих сущностей. Со стороны студента эта роль называется "Пишет диплом под руководством", со стороны преподавателя эта связь называется "Руководит". Графическая интерпретация связи позволяет сразу прочитать смысл взаимосвязи между сущностями, она наглядна и легко интерпретируема. Связи делятся на три типа по множественности: один-к-одному (1:1), один-ко-многим (1:M), многие-ко-многим (M:M). Связь один-к-одному означает, что экземпляр одной сущности связан только с одним экземпляром другой сущности. Связь 1: M означает, что один экземпляр сущности, расположенный слева по связи, может быть связан с несколькими экземплярами сущности, расположенными справа по связи. Связь "один-к-одному" (1:1) означает, что один экземпляр одной сущности связан только с одним экземпляром другой сущности, а связь "многие-ко-многим" (M:M) означает, что один экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и наоборот, один экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Например, если мы рассмотрим связь типа "Изучает" между сущностями "Студент" и "Дисциплина", то это связь типа "многие-ко-многим" (M:M), потому что каждый студент может изучать несколько дисциплин, но и каждая дисциплина изучается множеством студентов. Такая связь изображена на рис. 7.3.
- Между двумя сущностями может быть задано сколько угодно связей с разными смысловыми нагрузками. Например, между двумя сущностями "Студент" и "Преподаватель" можно установить две смысловые связи, одна — рассмотренная уже ранее "Дипломное проектирование", а вторая может быть условно названа "Лекции", и она определяет, лекции каких преподавателей слушает данный студент и каким студентам данный преподаватель читает лекции. Ясно, что это связь типа многие-ко-многим. Пример этих связей приведен на рис. 7.3.
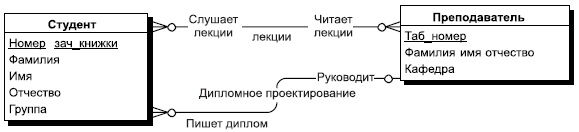
Рис. 7.3. Пример моделирования связи "многие-ко-многим"
- Связь любого из этих типов может быть обязательной, если в данной связи должен участвовать каждый экземпляр сущности, необязательной — если не каждый экземпляр сущности должен участвовать в данной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны. Обязательность связи тоже по-разному обозначается в разных нотациях. Мы снова используем нотацию POWER DESIGNER. Здесь необязательность связи обозначается пустым кружочком на конце связи, а обязательность перпендикулярной линией, перечеркивающей связь. И эта нотация имеет простую интерпретацию. Кружочек означает, что ни один экземпляр не может участвовать в этой связи. А перпендикуляр интерпретируется как то, что по крайней мере один экземпляр сущности участвует в этой связи. Рассмотрим для этого ранее приведенный пример связи "Дипломное проектирование". На нашем рисунке эта связь интерпретируется как необязательная с двух сторон. Но ведь на самом деле каждый студент, который пишет диплом, должен иметь своего руководителя дипломного проектирования, но, с другой стороны, не каждый преподаватель должен вести дипломное проектирование. Поэтому в данной смысловой постановке изображение этой связи изменится и будет выглядеть таким, как представлено на рис. 7.4.
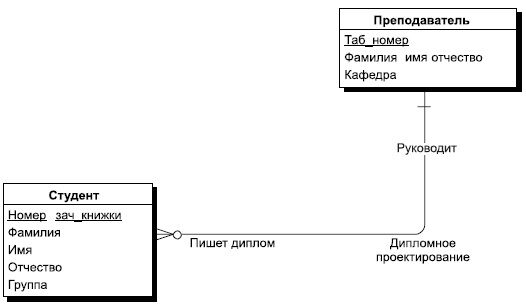
Рис. 7.4. Пример обязательной и необязательной связи между сущностями
Кроме того, в ER-модели допускается принцип категоризации сущностей. Это значит, что, как и в объектно-ориентированных языках программирования, вводится понятие подтипа сущности, то есть сущность может быть представлена в виде двух или более своих подтипов — сущностей, каждая из которых может иметь общие атрибуты и отношения и/или атрибуты и отношения, которые определяются однажды на верхнем уровне и наследуются на нижнем уровне. Все подтипы одной сущности рассматриваются как взаимоисключающие, и при разделении сущности на подтипы она должна быть представлена в виде полного набора взаимоисключающих подтипов. Если на уровне анализа не удается выявить полный перечень подтипов, то вводится специальный подтип, называемый условно ПРОЧИЕ, который в дальнейшем может быть уточнен. В реальных системах бывает достаточно ввести подтипизацию на двух-трех уровнях.
Сущность, на основе которой строятся подтипы, называется супертипом. Любой экземпляр супертипа должен относиться к конкретному подтипу. Для графического изображения принципа категоризации или типизации сущности вводится специальный графический элемент, называемый узел-дискриминатор, в нотации POWER DESIGNER он изображается в виде полукруга, выпуклой стороной обращенного к суперсущности. Эта сторона соединяется направленной стрелкой с суперсущностью, а к диаметру этого круга стрелками подсоединяются подтипы данной сущности (см. рис. 7.5).
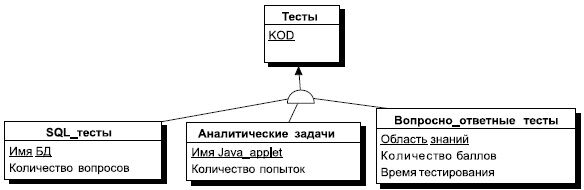
Рис. 7.5. Диаграмма подтипов сущности ТЕСТ
Эту диаграмму можно расшифровать следующим образом. Каждый тест в некоторой системе тестирования является либо тестом проверки знаний языка SQL, либо некоторой аналитической задачей, которая выполняется с использованием заранее написанных Java-апплетов, либо тестом по некоторой области знаний, состоящим из набора вопросов и набора ответов, предлагаемых к каждому вопросу.
В результате построения модели предметной области в виде набора сущностей и связей получаем связный граф. В полученном графе необходимо избегать циклических связей — они выявляют некорректность модели.
В качестве примера спроектируем инфологическую модель системы, предназначенной для хранения информации о книгах и областях знаний, представленных в библиотеке. Описание предметной области было приведено ранее. Разработку модели начнем с выделения основных сущностей.
Прежде всего, существует сущность "Книги", каждая книга имеет уникальный шифр, который является ее ключом, и ряд атрибутов, которые взяты из описания предметной области. Множество экземпляров сущности определяет множество книг, которые хранятся в библиотеке. Каждый экземпляр сущности "Книги" соответствует не конкретной книге, стоящей на полке, а описанию некоторой книги, которое дается обычно в предметном каталоге библиотеке. Каждая книга может присутствовать в нескольких экземплярах, и это как раз те конкретные книги, которые стоят на полках библиотеки. Для того чтобы отразить это, мы должны ввести сущность "Экземпляры", которая будет содержать описания всех экземпляров книг, которые хранятся в библиотеке. Каждый экземпляр сущности "Экземпляры" соответствует конкретной книге на полке. Каждый экземпляр имеет уникальный инвентарный номер, однозначно определяющий конкретную книгу. Кроме того, каждый экземпляр книги может находиться либо в библиотеке, либо на руках у некоторого читателя, и в последнем случае для данного экземпляра указываются дополнительно дата взятия книги читателем и дата предполагаемого возврата книги.
Между сущностями "Книги" и "Экземпляры" существует связь "один-ко-многим" (1:М), обязательная с двух сторон. Чем определяется данный тип связи? Мы можем предположить, что каждая книга может присутствовать в библиотеке в нескольких экземплярах, поэтому связь "один-ко-многим". При этом если в библиотеке нет ни одного экземпляра данной книги, то мы не будем хранить ее описание, поэтому если книга описана в сущности "Книги", то по крайней мере один экземпляр этой книги присутствует в библиотеке. Это означает, что со стороны книги связь обязательная. Что касается сущности "Экземпляры", то не может существовать в библиотеке ни одного экземпляра, который бы не относился к конкретной книге, поэтому и со стороны "Экземпляры" связь тоже обязательная.
Теперь нам необходимо определить, как в нашей системе будет представлен читатель. Естественно предложить ввести для этого сущность "Читатели", каждый экземпляр которой будет соответствовать конкретному читателю. В библиотеке каждому читателю присваивается уникальный номер читательского билета, который будет однозначно идентифицировать нашего читателя. Номер читательского билета будет ключевым атрибутом сущности "Читатели". Кроме того, в сущности "Читатели" должны присутствовать дополнительные атрибуты, которые требуются для решения поставленных задач, этими атрибутами будут: "Фамилия Имя Отчество", "Адрес читателя", "Телефон домашний" и "Телефон рабочий". Почему мы ввели два отдельных атрибута под телефоны? Потому что надо в разное время звонить по этим телефонам, чтобы застать читателя, поэтому администрации библиотеки будет важно знать, к какому типу относится данный телефон. В описании нашей предметной области существует ограничение на возраст наших читателей, поэтому в сущности "Читатели" надо ввести обязательный атрибут "Дата рождения", который позволит нам контролировать возраст наших читателей.
Из описания предметной области мы знаем, что каждый читатель может держать на руках несколько экземпляров книг. Для отражения этой ситуации нам надо провести связь между сущностями "Читатели" и "Экземпляры". А почему не между сущностями "Читатели" и "Книги"? Потому что читатель берет из библиотеки конкретный экземпляр конкретной книги, а не просто книгу. А как же узнать, какая книга у данного читателя? А это можно будет узнать по дополнительной связи между сущностями "Экземпляры" и "Книги", и эта связь каждому экземпляру ставит в соответствие одну книгу, поэтому мы в любой момент можем однозначно определить, какие книги находятся на руках у читателя, хотя связываем с читателем только инвентарные номера взятых книг. Между сущностями "Читатели" и "Экземпляры" установлена связь "один-ко-многим", и при этом она не обязательная с двух сторон. Читатель в данный момент может не держать ни одной книги на руках, а с другой стороны, данный экземпляр книги может не находиться ни у одного читателя, а просто стоять на полке в библиотеке.
Теперь нам надо отразить последнюю сущность, которая связана с системным каталогом. Системный каталог содержит перечень всех областей знаний, сведения по которым содержатся в библиотечных книгах. Мы можем вспомнить системный каталог в библиотеке, с которого мы обычно начинаем поиск нужных нам книг, если мы не знаем их авторов и названий. Название области знаний может быть длинным и состоять из нескольких слов, поэтому для моделирования системного каталога мы введем сущность "Системный каталог" с двумя атрибутами: "Код области знаний" и "Название области знаний". Атрибут "Код области знаний" будет ключевым атрибутом сущности.
Из описания предметной области нам известно, что каждая книга может содержать сведения из нескольких областей знаний, а с другой стороны, из практики известно, что в библиотеке может присутствовать множество книг, относящихся к одной и той же области знаний, поэтому нам необходимо установить между сущностями "Системный каталог" и "Книги" связь "многие-ко-многим", обязательную с двух сторон. Действительно, в системном каталоге не должно присутствовать такой области знаний, сведения по которой не представлены ни в одной книге нашей библиотеки, противное было бы бессмысленно. И обратно, каждая книга должна быть отнесена к одной или нескольким областям знаний для того, чтобы читатель мог ее быстрее найти.
Инфологическая модель предметной области "Библиотека" представлена на рис. 7.6.
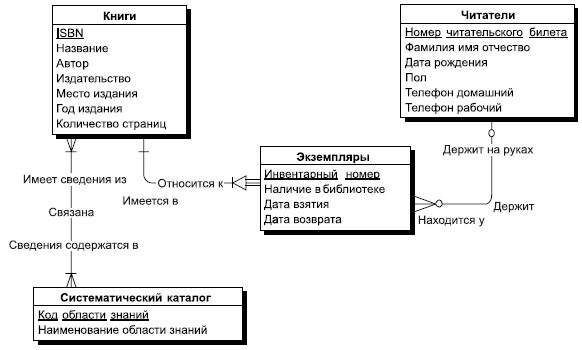
Рис. 7.6. Инфологическая модель "Библиотека"
Инфологическая модель "Библиотека" разработана нами под те задачи, которые были перечислены ранее. В этих задачах мы не ставили условие хранения истории чтения книги, например, с целью поиска того, кто раньше держал книгу и мог нанести ей вред или забыть в ней случайно большую сумму денег. Если бы мы ставили перед собой задачу хранения и этой информации, то наша инфологическая модель была бы другой. Я оставлю эту задачу для вашего самостоятельного творчества.
Переход к реляционной модели данных
Инфологическая модель используется на ранних стадиях разработки проекта. Если понимать язык условных обозначений, которые соответствуют категориям ER-модели, то ее можно легко "читать", следовательно, она доступна для анализа программистам-разработчикам, которые будут разрабатывать отдельные приложения. Она имеет однозначную интерпретацию, в отличие от некоторых предложений естественного языка, и поэтому здесь не может быть никакого недопонимания со стороны разработчиков.
Все специалисты всегда предпочитают выражать свои мысли на некотором формальном языке, который обеспечивает однозначную их трактовку. Таким языком для программистов раньше был язык алгоритмов. Любой алгоритм имел однозначную интерпретацию. Он мог быть реализован на разных языках программирования, но сам алгоритм был и оставался одним и тем же. В первые годы развития вычислительной техники широко издавались сборники алгоритмов для широко распространенных математических задач. Эти сборники программистами прочитывались как увлекательные детективные романы, и они все настоящим программистам были понятны, хотя специалисты других профилей смотрели на эти сборники как на издания на иностранных, неведомых им, языках. Для описания алгоритмов могли использоваться разные формализмы. Одним из таких формализмов был метаязык, в котором использовались слова на естественном языке и каждый мог прочесть эти слова, но смысл самого алгоритма мог понять только тот, кто владел знаниями трактовки алгоритмов.
Вот таким условным общепринятым языком описания базы данных и стал язык ER-модели. Для ER-модели существует алгоритм однозначного преобразования ее в реляционную модель данных, что позволило в дальнейшем разработать множество инструментальных систем, поддерживающих процесс разработки информационных систем, базирующихся на технологии баз данных. И во всех этих системах существуют средства описания инфологической модели разрабатываемой БД с возможностью автоматической генерации той даталогической модели, на которой будет реализовываться проект в дальнейшем.
Рассмотрим правила преобразования ER-модели в реляционную.
1. Каждой сущности ставится в соответствие отношение реляционной модели данных. При этом имена сущности и отношения могут быть различными, потому что на имена сущностей могут не накладываться дополнительные синтаксические ограничения, кроме уникальности имени в рамках модели. Имена отношений могут быть ограничены требованиями конкретной СУБД, чаще всего эти имена являются идентификаторами в некотором базовом языке, они ограничены по длине и не должны содержать пробелов и некоторых специальных символов. Например, сущность может быть названа "Книжный каталог", а соответствующее ей отношение желательно назвать, например, BOOKS (без пробелов и латинскими буквами).
2. Каждый атрибут сущности становится атрибутом соответствующего отношения. Переименование атрибутов должно происходить в соответствии с теми же правилами, что и переименование отношений в п.1. Для каждого атрибута задается конкретный допустимый в СУБД тип данных и обязательность или необязательность данного атрибута (то есть допустимость или недопустимость NULL значений для него).
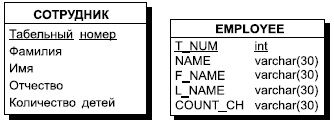
Рис. 7.7. Преобразование сущности СОТРУДНИК к отношению EMPLOYEE
3. Первичный ключ сущности становится PRIMARY KEY соответствующего отношения. Атрибуты, входящие в первичный ключ отношения, автоматически получают свойство обязательности (NOT NULL).
| Таблица 7.8. Свойства атрибутов отношения EMPLOYEE | |
| Column Code | Type |
| COUNT CH | Varchar(30) Null |
| F NAME | Varchar(30) Not Null |
| L NAME | Varchar(30) Null |
| NAME | Varchar(30) Null |
| T NUM | Int Not Null |
4. В каждое отношение, соответствующее подчиненной сущности, добавляется набор атрибутов основной сущности, являющейся первичным ключом основной сущности. В отношении, соответствующем подчиненной сущности, этот набор атрибутов становится внешним ключом (FOREING KEY).
5. Для моделирования необязательного типа связи на физическом уровне у атрибутов, соответствующих внешнему ключу, устанавливается свойство допустимости неопределенных значений (признак NULL). При обязательном типе связи атрибуты получают свойство отсутствия неопределенных значений (признак NOT NULL).
6. Для отражения категоризации сущностей при переходе к реляционной модели возможны несколько вариантов представления. Возможно создать только одно отношение для всех подтипов одного супертипа. В него включают все атрибуты всех подтипов. Однако тогда для ряда экземпляров ряд атрибутов не будет иметь смысла. И даже если они будут иметь неопределенные значения, то потребуются дополнительные правила различения одних подтипов от других. Достоинством такого представления является то, что создается всего одно отношение.
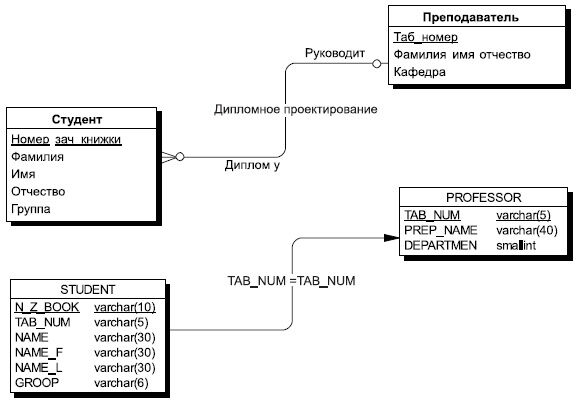
Рис. 7.9. Преобразование взаимосвязанных сущностей СТУДЕНТ и ПРЕПОДАВАТЕЛЬ к взаимосвязанным отношениям STUDENT и PROFESSOR
7. При втором способе для каждого подтипа и для супертипа создаются свои отдельные отношения. Недостатком такого способа представления является то, что создается много отношений, однако достоинств у такого способа больше, так как вы работаете только со значимыми атрибутами подтипа. Кроме того, для возможности переходов к подтипам от супертипа необходимо в супертип включить идентификатор связи.
8. Дополнительно при описании отношения между типом и подтипами необходимо указать тип дискриминатора. Дискриминатор может быть взаимоисключающим (M/E, mutually exclusive ) или нет. Если установлен данный тип дискриминатора, то это значит, что один экземпляр сущности супертипа связан только с одним экземпляром сущности подтипа и для каждого экземпляра сущности супертипа существует потомок. Кроме того, необходимо указать для второго способа, наследуется ли только идентификатор супертипа в подтипы или наследуются все атрибуты супертипа.
9. Если мы зададим наследование только идентификатора, то мы получим следующее преобразование (см. рис. 7.10 и 7.11).
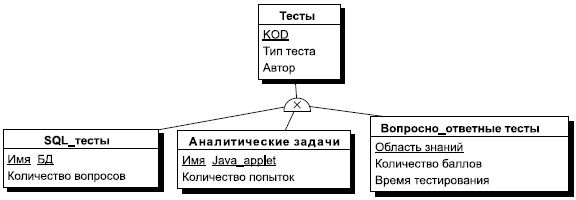
Рис. 7.10. Исходная модель взаимосвязи супертипа и подтипов
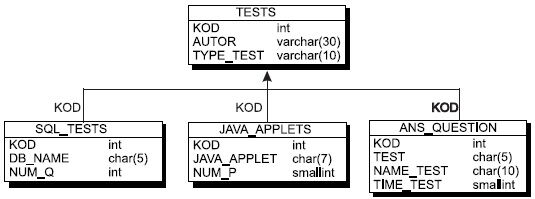
Рис. 7.11. Результирующая модель с наследованием только идентификатора суперсущности
Разрешение связей типа "многие-ко-многим". Так как в реляционной модели данных поддерживаются между отношениями только связи типа "один-ко-многим", а в ER-модели допустимы связи "многие-ко-многим", то необходим специальный механизм преобразования, который позволит отразить множественные связи, неспецифические для реляционной модели, с помощью допустимых для нее категорий. Это делается введением специального дополнительного связующего отношения, которое связано с каждым исходным связью "один-ко-многим", атрибутами этого отношения являются первичные ключи связываемых отношений. Так, например, в схеме "Библиотека" присутствует связь такого типа между сущностью "Книги" и "Системный каталог". Для разрешения этой неспецифической связи при переходе к реляционной модели должно быть введено специальное дополнительное отношение, которое имеет всего два атрибута: ISBN (шифр книги) и KOD (код области знаний). При этом каждый из атрибутов нового отношения является внешним ключом (FOREING KEY), а вместе они образуют первичный ключ (PRIMARY KEY) новой связующей сущности. На рис. 7.12 представлена реляционная модель, соответствующая представленной ранее на рис. 7.6 инфологической модели "Библиотека".
Теория нормализации, которую мы рассматривали ранее применительно к реляционной модели, применима и к модели "сущность—связь". Поэтому нормализацию можно проводить и на уровне инфологической (семантической) модели и
смысл ее аналогичен нормализации реляционной модели. Алгоритм приведения семантической модели к 5-й нормальной форме может быть следующим:
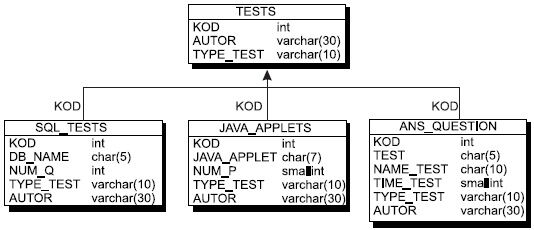
Рис. 7.12. Результирующая модель с наследованием всех атрибутов суперсущности
Шаг 1. Проанализировать схему на присутствие сущностей, которые скрыто моделируют несколько разных взаимосвязанных классов объектов реального мира (именно это соответствует ненормализованным отношениям). Если такое выявлено, то разделить каждую из этих сущностей на несколько новых сущностей и установить между ними соответствующие связи, полученная схема будет находиться в первой нормальной форме. Перейти к шагу 2.
Шаг 2. Проанализировать все сущности, имеющие составные первичные ключи, на наличие неполных функциональных зависимостей непервичных атрибутов от атрибутов возможного ключа. Если такие зависимости обнаружены, то разделить данные сущности на 2, определить для каждой сущности первичные ключи и установить между ними соответствующие связи. Полученная схема будет находиться во второй нормальной форме. Перейти к шагу 3.
Рекомендация для Вас - 32. Национальные ежедневные газеты Франции.
Шаг 3. Проанализировать неключевые атрибуты всех сущностей на наличие транзитивных функциональных зависимостей. При обнаружении таковых расщепить каждую сущность на несколько таким образом, чтобы ликвидировать транзитивные зависимости. Схема находится в третьей нормальной форме. Перейти к шагу 4.
Шаг 4. Проанализировать все сущности на наличие детерминантов, которые не являются возможными ключами. При обнаружении подобных расщепить сущность на две, установив между ними соответствующие связи. Полученная схема соответствует нормальной форме Бойса—Кодда. Перейти к шагу 5.
Шаг 5. Проанализировать все сущности на наличие многозначных зависимостей. Если обнаружатся сущности, у которыx имеется более одной многозначной зависимости, то расщепить такие сущности на две, установив между ними соответствующие связи. Полученная схема будет находиться в четвертой нормальной форме. Перейти к шагу 6.
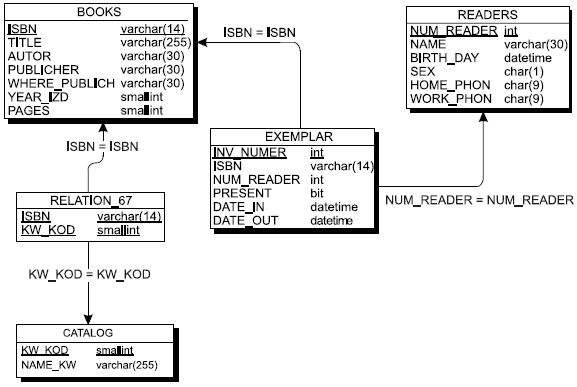
Рис. 7.13. Реляционная схема "Библиотека"
Шаг 6. Проанализировать сущности на наличие в них зависимостей проекции-соединения. При обнаружении таковых расщепить сущность на требуемое число взаимосвязанных сущностей и установить между ними требуемые связи. Полученная таким образом схема будет находиться в пятой нормальной форме и, будучи формально преобразованной к реляционной схеме по указанным выше принципам, даст реляционную схему также в пятой нормальной форме.



















