
Независимые и взаимодействующие процессы
4.3. Независимые и взаимодействующие вычислительные процессы
Независимые и взаимодействующие вычислительные процессы
Основной особенностью мультипрограммных OC является то, что в их среде параллельно развивается несколько (последовательных) вычислительных процессов. С точки зрения внешнего наблюдателя эти последовательные вычислительные процессы выполняются одновременно («параллельно»). При этом под параллельными понимаются не только процессы, одновременно развивающиеся на различных процессорах, каналах и устройствах ввода-вывода, но и те последовательные процессы, которые разделяют центральный процессор и в своем выполнении хотя бы частично перекрываются во времени. Любая мультипрограммная ОС вместе с параллельно выполняющимися процессами может быть логически представлена как совокупность последовательных вычислений, которые, с одной стороны, состязаются за ресурсы, переходя из одного состояния в другое, а с другой – действуют почти независимо один от другого, но при этом образуя единую систему посредством установления разного рода связей между собой (путем пересылки сообщений и синхронизирующих сигналов).
Итак, параллельными называют такие последовательные вычислительные процессы, которые одновременно находятся в каком-нибудь активном состоянии. Два параллельных процесса могут быть независимыми (англ. independent processes) либо взаимодействующими (англ. cooperating processes).
Независимыми являются процессы, множества переменных которых не пересекаются. Под переменными в этом случае понимают файлы данных, а также области оперативной памяти, сопоставленные промежуточным и определенным в программе переменным. Независимые процессы не влияют на результаты работы друг друга, так как не могут изменять значения переменных друг у друга. Они могут только явиться причиной в задержках исполнения друг друга, так как вынуждены разделять ресурсы системы.
Взаимодействующие процессы используют совместно некоторые (общие) переменные, и выполнение одного процесса может повлиять на выполнение другого. Следует отметить, что при рассмотрении вопросов синхронизации вычислительных процессов (п. 3.3.2), из числа разделяемых ими ресурсов исключаются центральный процессор и программы, реализующие эти процессы, то есть с логической точки зрения каждому процессу соответствуют свои процессор и программа, хотя в реальных системах обычно несколько процессов разделяют один процессор и одну или несколько программ. Многие ресурсы вычислительной системы могут совместно использоваться несколькими процессами, но в каждый момент времени к разделяемому ресурсу может иметь доступ только один процесс. Ресурсы, которые не допускают одновременного использования несколькими процессами, называются критическими.

4.3.2. Цели и средства синхронизации
Цели и средства синхронизации
Синхронизация процессов – приведение двух или более процессов к такому их протеканию, когда определенные стадии разных процессов совершаются в определенном порядке, либо одновременно. Потребность в синхронизации возникает только в мультипрограммной ОС и связана с совместным использованием аппаратных и информационных ресурсов вычислительной системы. Синхронизация необходима в любых случаях, когда параллельно протекающим процессам (потокам) необходимо взаимодействовать – для исключения гонок и тупиков при обмене данными между потоками, разделении данных, при доступе к устройствам ввода-вывода. Для ее организации используются средства межпроцессного взаимодействия (Inter Process Communications, IPC), что отражает историческую первичность понятия «процесс» по отношению к понятию «поток». Среди наиболее часто используемых средств синхронизации – сигналы, сообщения, семафоры и мьютексы.
Рекомендуемые материалы
Выполнение процесса (потока) в мультипрограммной среде всегда имеет асинхронный характер. Очень сложно с полной определенностью сказать, на каком этапе выполнения будет находиться процесс в определенный момент времени. Даже в однопрограммном режиме не всегда можно точно оценить время выполнения задачи. Это время во многих случаях существенно зависит от значения исходных данных, которые влияют на количество циклов, направления разветвления программы, время выполнения операций ввода-вывода и т.п. В связи с тем, что исходные данные в разные моменты запуска задачи могут быть разными, то и время выполнения отдельных этапов и задачи в целом является весьма неопределенной величиной.
Еще более неопределенным является время выполнения программы в мультипрограммной системе. Моменты прерывания потоков, время нахождения их в очередях к разделяемым ресурсам, порядок выбора потоков для выполнения – все эти события являются результатом стечения многих обстоятельств и могут быть интерпретированы как случайные. В лучшем случае можно оценить вероятностные характеристики вычислительного процесса, например, вероятность его завершения за данный период времени.
Учитывая вышеизложенное, можно сделать вывод, что потоки в общем случае (когда программист не предпринял специальных мер по их синхронизации) протекают независимо, асинхронно друг другу. Это справедливо как по отношению к потокам одного процесса, выполняющим общий программный код, так и по отношению к потокам разных процессов, каждый из которых выполняет собственную программу.
Для синхронизации потоков прикладных программ программист может использовать как собственные средства и приемы синхронизации, так и средства ОС. Например, два потока одного прикладного процесса могут координировать свою работу с помощью доступной для них обоих глобальной логической переменной, которая устанавливается в единицу при осуществлении некоторого события, например выработки одним потоком данных, нужных для продолжения работы другого. Однако во многих случаях более эффективными или даже единственно возможными являются средства синхронизации, предоставляемые ОС в форме системных вызовов. Так, потоки, принадлежащие разным процессам, не имеют возможности вмешиваться каким-либо образом в работу друг друга. Без посредничества ОС они не могут приостановить друг друга или оповестить о произошедшем событии.
Средства синхронизации используются ОС не только для синхронизации прикладных процессов, но и для ее внутренних нужд. Обычно разработчики ОС предоставляют в распоряжение прикладных и системных программистов широкий спектр средств синхронизации. Эти средства могут образовывать иерархию, когда на основе более простых средств строятся более сложные, а также могут быть функционально специализированными. Например, средства для синхронизации потоков одного процесса, средства для синхронизации потоков разных процессов при обмене данными и т.д.
4.3.3. Пример необходимости синхронизации
Пример необходимости синхронизации
Пренебрежение вопросами синхронизации процессов, выполняющихся в режиме мультипрограммирования, может привести к их неправильной работе или даже к краху системы.
Рассмотрим пример, демонстрирующий необходимость синхронизации двух процессов, каждый из которых работает с некоторым общим ресурсом – программой печати файлов (принт-сервером, рис. 17).
Эта программа печатает по очереди содержимое файлов, имена которых последовательно в порядке поступления записывают в специальный общедоступный файл «заказов». Специальная переменная NEXT, доступная всем процессам-клиентам, содержит номер первой свободной позиции для записи имени файла в файле «заказов». Процессы-клиенты считывают значение этой переменной, определяя тем самым очередную свободную позицию для записи имени файла, после чего значение переменой NEXT увеличивается на единицу.
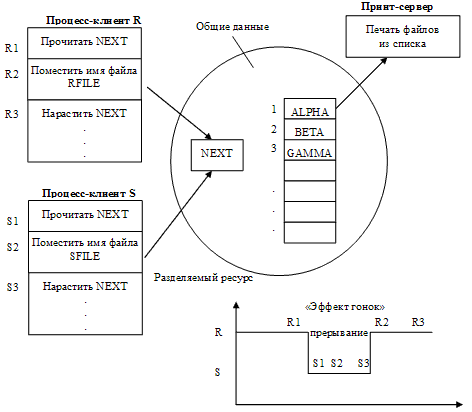
Рисунок 17 – Пример необходимости синхронизации при доступе к одному файлу заказов
Предположим, что в некоторый момент времени процесс R решил распечатать свой файл, для чего считал текущее значение переменной NEXT (пусть NEXT = k). Затем, например, вследствие исчерпания кванта времени, выделенного процессу, выполнение процесса было прервано.
Очередной процесс S, желающий также распечатать файл, считал значение k переменной NEXT, поместил в позицию k имя своего файла и нарастил значение переменной NEXT на единицу.
Когда в очередной раз управление будет передано процессу R, то он, продолжая свое выполнение, в полном соответствии со считанным ранее значением текущей свободной позиции, запишет имя файла для печати в файл «заказов» также в позицию k (поверх имени файла процесса S). Поэтому, файл процесса S не будет напечатан.
Очевидно, что решение проблемы синхронизации в данном случае зависит от взаимных скоростей процессов и моментов их прерывания, то есть при других названных параметрах потери файлов при печати могло и не быть. Это подтверждает нерегулярность рассинхронизации процессов и наличие сложностей в обеспечении их синхронизации.
Ситуации подобные этой, когда два или более процессов обрабатывают разделяемые данные, и конечный результат зависит от соотношения скоростей процессов, называются гонками.
Важным понятием, используемым при синхронизации потоков, является понятие «критической секции» программы. Критическая секция – это часть программы, результат выполнения которой может непредсказуемо меняться, если переменные, относящиеся к этой части программы, изменяются другими потоками в то время, когда выполнение этой части еще не завершено. Критическая секция всегда определяется по отношению к определенным критическим данным, при несогласованном изменении которых могут возникнуть нежелательные эффекты. В примере, представленном на рис. 17, такой критической секцией является файл «заказов», являющийся разделяемым ресурсом для процессов R и S.
4.3.4. Механизмы синхронизации
Механизмы синхронизации
Как было отмечено выше в п. 3.3.2, ОС поддерживает целый ряд различных средств синхронизации процессов, позволяющих избежать проблем, подобной той, что описана выше и представлена на рис. 17. Рассмотрим каждое из этих средств синхронизации процессов более подробно.
Блокирующие переменные. Для синхронизации потоков одного процесса прикладной программист может использовать глобальные блокирующие переменные. С этими переменными, к которым все потоки процесса имеют прямой доступ, программист работает, не обращаясь к системным вызовам ОС. Каждому набору критических данных ставится в соответствие двоичная переменная, которой поток присваивает значение 0, когда он входит в критическую секцию, и значение 1, когда он ее покидает.
На рис. 18 показан фрагмент алгоритма потока, использующего для реализации взаимного исключения доступа к критическим данным D блокирующую переменную F(D). Перед входом в критическую секцию поток проверяет, не работает ли уже какой-нибудь другой поток с данными D. Если переменная F(D) установлена в 0, то данные заняты и проверка циклически повторяется. Если же данные свободны (F(D) = 1), то значение переменной F(D) устанавливается в 0 и поток входит в критическую секцию. После того, как поток выполнит все действия с данными D, значение переменной F(D) снова устанавливается равным 1.
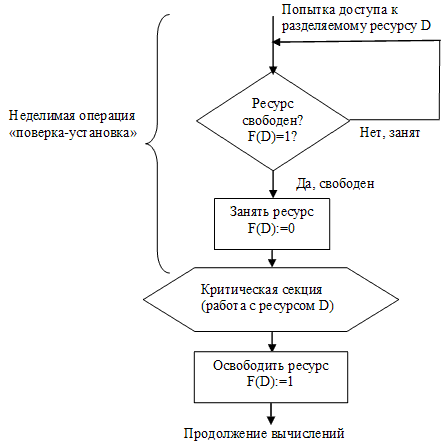
Рисунок 18 – Работа в критической секции с использованием блокирующих переменных
Блокирующие переменные могут использоваться не только при доступе к разделяемым данным, но и при доступе к разделяемым ресурсам любого вида. Если все потоки разработаны с учетом вышеописанных соглашений, то взаимное исключение гарантируется. При этом потоки могут быть прерваны ОС в любой момент и в любом месте, в том числе в критической секции. Однако следует заметить, что одно ограничение на прерывания все же имеется – нельзя прерывать поток между выполнением операций проверки и установки блокирующей переменной, т.к. это нарушит принцип взаимного исключения.
Действительно, пусть в результате проверки переменной поток определил, что ресурс свободен, но сразу после этого, не успев установить переменную в 0, был прерван. За время его приостановки другой поток занял ресурс, вошел в свою критическую секцию, но также был прерван, не завершив работы с разделяемым ресурсом. Когда управление было возвращено первому потоку, он, считая ресурс свободным, установил признак занятости и начал выполнять операции в критической секции. Таким образом, в одной критической секции производят работу два различных потока, а это потенциально может привести к нежелательным последствиям.
Во избежание подобных ситуаций в системе команд многих компьютеров предусмотрена единая, неделимая команда анализа и присвоения значения логической переменной (например, команды ВТС, BTR и ВТ5 процессора Pentium). При отсутствии такой команды в процессоре соответствующие действия должны реализовываться специальными системными примитивами – базовыми функциями ОС, которые бы запрещали прерывания на протяжении всей операции проверки и установки.
Реализация взаимного исключения с использованием глобальных блокирующих переменных имеет существенный недостаток: в течение времени, когда один поток находится в критической секции, другой поток, которому требуется тот же ресурс, получив доступ к процессору, будет непрерывно опрашивать блокирующую переменную, бесполезно растрачивая выделяемое ему процессорное время, которое могло бы быть использовано для выполнения какого-нибудь другого потока. Для устранения этого недостатка во многих ОС предусматриваются специальные системные вызовы (аппарат событий) для работы с критическими секциями.
Семафоры. В разных ОС аппарат событий реализуется по своему, но в любом случае используются системные функции аналогичного назначения, которые условно именуют WAIT(x) и POST(x), где x – идентификатор некоторого события. На рис. 19 показан фрагмент алгоритма процесса, использующего эти функции.
Если ресурс занят, то процесс не выполняет циклический опрос, а вызывает системную функцию WAIT(D), здесь D обозначает событие, заключающееся в освобождении ресурса D. Функция WAIT(D) переводит активный процесс в состояние ожидание и делает отметку в его дескрипторе о том, что процесс ожидает события D. Процесс, который в это время использует ресурс D, после выхода из критической секции выполняет системную функцию POST(D), ОС просматривает очередь ожидающих процессов и переводит процесс, ожидающий события D, в состояние готовность.
Обобщающее средство синхронизации процессов с использованием изложенных выше принципов, названное семафор, предложил Э.В. Дейкстра (Edsger Wybe Dijkstra) – выдающийся нидерландский учёный, идеи которого оказали огромное влияние на развитие компьютерной индустрии. Семафор – объект, позволяющий войти в заданный участок кода не более чем n потокам. Осуществляется это путем использования специальной защищенной переменной S, значения которой можно опрашивать и менять только при помощи специальных операций P(S) и V(S) и операции инициализации. Семафор может принимать целое неотрицательное значение. При выполнении потоком операции P над семафором S значение семафора уменьшается на 1 при S > 0, или поток блокируется, «ожидая на семафоре», при S = 0. При выполнении операции V(S) происходит пробуждение одного из потоков, ожидающих на семафоре S, а если таковых нет, то значение семафора увеличивается на 1 (как можно заметить, по сути – операции P и V аналогичны функциям POST и WAIT). Как следует из вышесказанного, при входе в критическую секцию поток должен выполнять операцию P(S), а при выходе из критической секции – операцию V(S).
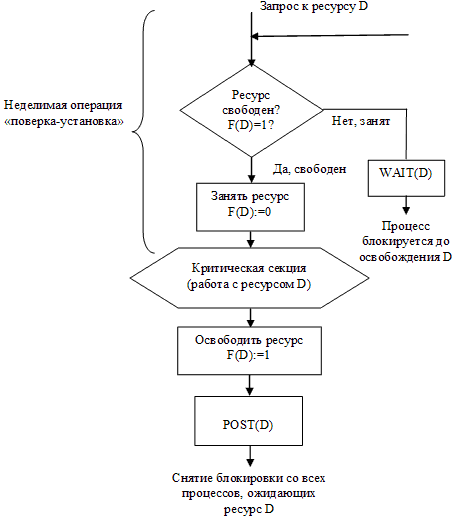
Рисунок 19 – Работа в критической секции с использованием системных функций WAIT(D) и POST(D)
В простом случае, когда семафор работает в режиме 2-х состояний (S > 0 и S = 0), его алгоритм работы полностью совпадает с алгоритмом мьютекса, а S выполняет роль блокирующей переменной.
Рассмотрим использование семафоров на классическом примере взаимодействия двух процессов, выполняющихся в режиме мультипрограммирования, один из процессов пишет данные в буферный пул, а другой считывает их из буферного пула. Пусть буферный пул состоит из N буферов, каждый из которых может содержать одну запись. Процесс «писатель» должен приостанавливаться, когда все буфера оказываются занятыми, и активизироваться при освобождении хотя бы одного буфера. Напротив, процесс «читатель» приостанавливается, когда все буферы пусты, и активизируется при появлении хотя бы одной записи. Введем следующие семафоры:
· e – число пустых буферов («e» – empty);
· f – число заполненных буферов («f» – full);
· b – двоичный семафор, используемый для обеспечения
взаимного исключения.
Операции с буфером (запись, считывание) являются критическими секциями. Процессы могут быть описаны следующим образом:
// Глобальные переменные
#define N 256
int e = N, f = 0, b = 1;
void Writer ()
{
while(1)
{
PrepareNextRecord(); /* подготовка новой записи */
P(e); /* Уменьшить число свободных буферов, если они есть */
/* в противном случае ждать, пока они освободятся */
P(b); /* Вход в критическую секцию */
AddToBuffer(); /* Добавить новую запись в буфер */
V(b); /* Выход из критической секции */
V(f); /* Увеличить число занятых буферов */
}
}
void Reader ()
{
while(1)
{
P(f); /* Уменьшить число занятых буферов, если они есть */
/* в противном случае ждать, пока они появятся */
P(b); /* Вход в критическую секцию */
GetFromBuffer(); /* Взять запись из буфера */
V(b); /* Выход из критической секции */
V(e); /* Увеличить число свободных буферов */
ProcessRecord(); /* Обработать запись */
}
}
Достоинства использования операций на семафоре:
1. Пассивное ожидание (постановка в очередь и автоматическая выдача ресурсов).
2. Возможность управления группой однородных ресурсов.
К недостаткам использования семафоров относят то, что некорректное использование операций на семафоре может привести к нарушению работоспособности параллельных систем.
Действительно, если в рассмотренном примере переставить местами операции P(e) и P(b) в функции «писатель», то при некотором стечении обстоятельств эти два процесса могут взаимно заблокировать друг друга. Так, пусть «писатель» первым войдет в критическую секцию и обнаружит отсутствие свободных буферов; он начнет ждать, когда «читатель» возьмет очередную запись из буфера, но «читатель» не сможет этого сделать, так как для этого необходимо войти в критическую секцию, вход в которую заблокирован процессом «писатель».
Мониторы. В связи с тем, что использование семафоров требует особой осторожности (одна незначительная ошибка может привести к останову системы), для облегчения корректного функционирования программ было предложено высокоуровневое средство синхронизации, называемое монитором. Мониторы представляют собой тип данных, обладающий собственными переменными, определяющими его состояние. Значения этих переменных извне могут быть изменены только с помощью вызова функций-методов монитора. Функции-методы могут использовать в работе только данные, находящиеся внутри монитора, и свои параметры. Важной особенностью мониторов является то, что в любой момент времени только один процесс может быть активен, т.е. находиться в состоянии готовность или исполнение, внутри данного монитора. Вот пример описания монитора:
monitor monitor_name
{
описание переменных;
void m1(...){... }
void m2(...){... }
...
void mn(...){... }
{ блок инициализации внутренних переменных;}
}
Однако одних только взаимоисключений недостаточно для того, чтобы в полном объеме реализовать решение задач, возникающих при взаимодействии процессов. Необходимы средства организации очередности процессов, подобно семафорам f(full) и e(empty) в примере.
Для этого в мониторах было введено понятие условных переменных, над которыми можно совершать две операции wait и signal, отчасти похожие на операции P и V над семафорами.
monitor ProducerConsumer
{
condition full, empty;
int count;
void put()
{
if(count == N) full.wait;
put_item;
count += 1;
if(count == 1) empty.signal;
}
void get()
{
if (count == 0) empty.wait;
get_item();
count -= 1;
if(count == N-1) full.signal;
}
}
Producer: while(1)
{
produce_item;
ProducerConsumer.put();
}
Consumer: while(1)
{
ProducerConsumer.get();
consume_item;
}
Функция монитора выполняет операцию wait над какой-либо условной переменной. При этом процесс, выполнивший операцию wait, блокируется, становится неактивным, и другой процесс получает возможность войти в монитор.
Когда ожидаемое событие происходит, другой процесс внутри функции совершает операцию signal над той же самой условной переменной. Это приводит к пробуждению ранее заблокированного процесса, и он становится активным.
Отличительной особенностью мониторов является то, что исключение входа нескольких процессов в монитор реализуется не программистом, а компилятором, что делает ошибки менее вероятными. Реализация мониторов требует использования специальных языков программирования и компиляторов для них (например, «параллельный Евклид» , «параллельный Паскаль» , Java).
Следует отметить, что эмуляция семафоров значительно проще эмуляции мониторов – в отличие от семафоров Дейкстры, условные переменные мониторов не запоминают предысторию, поэтому операция signal всегда должна выполняться после операции wait. Если операция signal выполняется над условной переменной, с которой не связано ни одного заблокированного процесса, то информация о произошедшем событии будет утеряна, и выполнение операции wait всегда будет приводить к блокированию процесса.
Сигналы. Вообще, сигнал – это некоторое значимое событие (например, прерывание), источником которого может быть ОС или иная составляющая вычислительной системы. Сигналы вызывают прерывание процесса, выполнение заранее предусмотренных действий.
Сигналы могут вырабатываться как результат работы самого процесса (т.е. вырабатываться синхронно), а могут быть направлены процессу другим процессом (т.е. вырабатываться асинхронно). Синхронные сигналы чаще всего приходят от системы прерываний процессора и свидетельствуют о действиях процесса, блокируемых аппаратурой, например деление на нуль, ошибка адресации, нарушение защиты памяти и т.д. Примером асинхронного сигнала является сигнал с терминала (например, сигнал об оперативном снятии процесса с выполнения с помощью некоторой нажатой комбинации клавиш – Ctrl + C, Ctrl + Break), в результате чего ОС вырабатывает сигнал и направляет его активному процессу.
Сигналы обеспечивают логическую связь между процессами, а также между процессами и пользователями (терминалами). Поскольку посылка сигнала предусматривает знание идентификатора процесса, то взаимодействие посредством сигналов возможно только между родственными процессами, которые могут получить данные об идентификаторах друг друга.
Следует отметить, что в распределенных системах, состоящих из нескольких процессоров, каждый из которых имеет собственную оперативную память, блокирующие переменные, семафоры, сигналы и другие аналогичные средства, основанные на разделяемой памяти, оказываются непригодными. В таких системах синхронизация может быть реализована только посредством обмена сообщениями, рассмотренными ниже в п. 3.3.6.
4.3.5. 3Проблемы синхронизации
Проблемы синхронизации
В п. 3.3.4 рассмотрен ряд механизмов ОС, используемых для синхронизации параллельно действующих процессов. Однако, в некоторых случаях, при конкуренции нескольких процессов за обладание конечным числом ресурсов, может возникнуть ситуация, когда запрашиваемый процессом ресурс недоступен, и ОС переводит данный процесс в состояние ожидания. В то же время, если этот же ресурс удерживается другим ожидающим процессом, то первый процесс не сможет сменить свое состояние. Подобная ситуация называется взаимной блокировкой, дедлоком (англ. deadlocks), клинчем (англ. clinch), или тупиком. Например, тупик возникнет при перестановке местами операций Р(е) и Р(b) в примере с процессами «читатель» и «писатель», рассмотренном выше. В этом случае ни один из этих потоков не сможет завершить начатую работу и возникнет тупиковая ситуация, которая не может разрешиться без внешнего воздействия.
Тупиковые ситуации следует отличать от простых очередей хотя те и другие возникают при совместном использовании ресурсов и внешне выглядят схоже – процесс приостанавливается и ждет освобождения ресурса. Однако очередь – это нормальное явление, неотъемлемый признак высокого коэффициента использования ресурсов при случайном поступлении запросов. Очередь появляется тогда, когда ресурс недоступен в данный момент, но освободится через некоторое время, позволив потоку продолжить выполнение. Тупик же, что видно из его названия, является в некотором роде неразрешимой ситуацией. Необходимым условием возникновения тупика является потребность потока сразу в нескольких ресурсах.
Разрешение проблемы тупиков может быть осуществлено путем:
· распознавания тупиков;
· предотвращения тупиков;
· восстановления системы после тупиков;
· игнорирования.
Рассмотрим каждый из аспектов проблемы тупиков более подробно.
Распознавание тупиков. В случаях, когда тупиковая ситуация образована многими процессами, использующими много ресурсов, распознавание тупика является нетривиальной задачей. Тупиковые ситуации следует отличать от простых очередей, хотя и те и другие возникают при совместном использовании ресурсов и внешне выглядят схоже: процесс приостанавливается и ждет освобождения ресурса. Однако очередь – это нормальное явление, неотъемлемый признак высокого коэффициента использования ресурсов при случайном поступлении запросов. Очередь появляется тогда, когда ресурс недоступен в данный момент, но освободится через некоторое время, позволив потоку продолжить выполнение, а тупик – является в некотором роде неразрешимой ситуацией.
Существуют формальные, программно-реализованные методы распознавания тупиков, основанные на ведении таблиц распределения ресурсов и таблиц запросов к занятым ресурсам, анализ которых позволяет обнаружить взаимные блокировки.
Предотвращение тупиков. Тупики могут быть предотвращены на стадии проектирования и разработки программного обеспечения, чтобы тупик не мог возникнуть ни при каком соотношении взаимных скоростей процессов.
В качестве необходимых условий возникновения тупиков называют следующие четыре:
1. Условие взаимоисключения (англ. Mutual exclusion). Одновременно использовать ресурс может только один процесс.
2. Условие ожидания ресурсов (англ. Hold and wait). Процессы удерживают ресурсы, уже выделенные им, и могут запрашивать другие ресурсы.
3. Условие «неперераспределяемости» (англ. No preemtion). Ресурс, выделенный ранее, не может быть принудительно забран у процесса до его завершения. Освобождены они могут быть только процессом, который их удерживает.
4. Условие кругового ожидания (англ. Circular wait). Существует кольцевая цепь процессов, в которой каждый процесс ждет доступа к ресурсу, удерживаемому другим процессом цепи.
Соответственно, решить проблему возникновения тупиков можно путем избегания описанных выше ситуаций 2-4 (ситуация взаимоисключения – объективна):
· ситуацию ожидания дополнительных ресурсов можно нарушить, если потребовать, чтобы процессы запрашивали сразу все ресурсы одновременно (очевидные недостатки – снижение уровня мультипрограммирования и нерациональное использование ресурсов);
· ситуацию «неперераспределяемости» можно нарушить, если потребовать, чтобы процесс, который не получил дополнительных ресурсов, сам освобождал удерживаемые;
· ситуацию кругового ожидания можно предотвратить, если процессы запрашивают ресурсы в заранее определенном порядке, то есть ресурсы имеют уникальные упорядоченные номера, которые распределяются в соответствии с некоторым планом (планирование распределения ресурсов).
Восстановление системы после тупиков. При возникновении тупиковой ситуации не обязательно снимать с выполнения все заблокированные процессы, а можно:
· снять только часть из них, при этом освобождая ресурсы, ожидаемые остальными процессами;
· вернуть некоторые процессы в область «свопинга»;
· совершить «откат» некоторых процессов до некоторой контрольной точки (т.е. места, где возможен тупик), в которой запоминается вся информация, необходимая для восстановления выполнения программы с данного места.
Игнорирование. Простейший подход – не замечать проблему тупиков. Для того чтобы принять такое решение, необходимо оценить вероятность возникновения взаимоблокировки и сравнить ее с вероятностью ущерба от других отказов аппаратного и программного обеспечения. Подход большинства современных ОС (Unix, Windows и др.) состоит в том, чтобы игнорировать данную проблему в предположении, что маловероятный случайный тупик предпочтительнее, чем внедрение сложных и дорогостоящих средств борьбы с тупиками, и жертвовать производительностью системы или удобством пользователей (например, ограничивать пользователей в числе процессов, открытых файлов и т.п.) не стоит.
4.3.6. Механизмы межпроцессного взаимодействия
Механизмы межпроцессного взаимодействия
Помимо решения задачи синхронизации процессов и потоков, в ОС требуется обеспечение и обмена данными между ними. Если речь идет о необходимости обмена данными между потоками одного процесса, то решение этой задачи не представляет никакой сложности, т.к. они имеют общее адресное пространство и файлы, и получают беспрепятственный доступ к данным друг друга. Другое дело – обмен данными потоков, выполняющихся в рамках разных процессов. В этом случае обмену препятствуют развитые средства ОС по защите процессов друг от друга, находящихся к тому же в разных адресных пространствах.
Операционная система имеет доступ ко всем областям памяти, поэтому она может играть роль посредника в информационном обмене потоков: при возникновении необходимости в обмене данными поток обращается с запросом к ОС, по которому ОС, пользуясь своими привилегиями, создает различные системные средства связи, такие, например, как каналы, очереди сообщений или разделяемую память. Эти средства (как и рассмотренные выше средства синхронизации процессов), относят к классу средств межпроцессного взаимодействия.
Следует помнить, что многие из средств межпроцессного обмена данными выполняют также и функции синхронизации: в том случае, когда данные для процесса-получателя отсутствуют, последний переводится в состояние ожидания средствами ОС, а при поступлении данных от процесса-отправителя процесс-получатель активизируется.
Каналы. Один из методов взаимодействия между процессами получил название канал связи, конвейер или транспортер (англ. pipe) – однонаправленный механизм передачи данных (неструктурированного потока байтов) между процессами без необходимости создания файла на диске. Канал представляет собой буфер в оперативной памяти, поддерживающий очередь байт согласно FIFO. Для программиста, использующего канал, этот буфер выглядит как безымянный файл, в который можно писать и читать, осуществляя тем самым обмен данными.
Механизм каналов часто используется не только программистами, но и обычными пользователями ОС для организации конвейера команд в случае, когда выходные данные одной команды пользователя становятся входными данными для другой команды. Так, наиболее простой вариант канала создает оболочка Unix между программами, запускаемыми из командной строки, разделенными символом «|». Например, командная строка dmesg | less создает канал от программы dmesg, выводящей отладочные сообщения ядра при загрузке к программе постраничного просмотра less.
Обычный канал получил развитие, результатом которого стало появление именованного канала или именованного конвейера – зарегистрированного в системе канала (по сути – запись в каталоге файловой системы), который разрешено использовать различным процессам или потокам (не обязательно родственным). Реализуется это путем создания одним, а чтения – другим процессом (потоком) файла типа FIFO с одним и тем же указанным в процессах именем.
Также можно создать канал с помощью, например, команд mknod или mkfifo и настроить gzip на сжатие того, что туда попадает:
mkfifo pipe
gzip -9 -c < pipe > out
Параллельно, в другом процессе можно выполнить:
cat file > pipe,
что приведёт к сжатию передаваемых данных gzip-ом.
Именованный канал существует в ОС и после завершения процесса, поэтому после окончания использования он должен быть «отсоединен» или удален. Следует иметь в виду, что именованные каналы используют файловую систему только для хранения имени конвейера, а данные между процессами передаются через буфер в оперативной памяти, как и в случае обычного канала.
Очереди сообщений. Механизм очередей сообщений (англ. queues) в целом схож с механизмом каналов, но позволяет процессам и потокам обмениваться структурированными сообщениями. При этом синхронизация осуществляется по сообщениям, то есть процесс, пытающийся прочитать сообщение, переводится в состояние ожидания в том случае, если в очереди нет ни одного полного сообщения.
Следует отметить, что в распределенных системах, состоящих из нескольких процессоров и неразделяемых блоков памяти, использование таких средств синхронизации как блокирующие переменные, семафоры, сигналы является непригодным. В таких системах синхронизацию следует реализовывать только посредством обмена сообщениями.
С помощью очередей можно из одной или нескольких задач независимым образом посылать сообщения некоторой задаче-приемнику. При этом только процесс-приемник может читать и удалять сообщения из очереди, а процессы-клиенты имеют право лишь помещать в очередь свои сообщения. Таким образом, очередь работает только в одном направлении, а если необходима двухсторонняя связь, то следует создать две очереди.
Очереди сообщений являются глобальными средствами коммуникаций для процессов ОС, как и именованные каналы, так как каждая очередь имеет в пределах ОС уникальное имя. В ОС Unix в качестве такого имени используется числовое значение – так называемый ключ. Ключ является числовым аналогом имени файла, при использовании одного и того же значения ключа процессы будут работать с одной и той же очередью сообщений.
Работа с очередями сообщений имеет ряд отличий от работы с каналами:/div>
1. Очереди сообщений предоставляют возможность использовать несколько дисциплин обработки сообщений (FIFO, LIFO, приоритетный доступ, произвольный доступ).
2. Если при чтении сообщения оно удаляется из конвейера, то при чтении сообщения из очереди этого не происходит, и сообщение может быть прочитано несколько раз.
3. В очередях присутствуют не непосредственно сами сообщения, а их адреса в памяти и размер. Эта информация размещается системой в сегменте памяти, доступном для всех задач, общающихся с помощью данной очереди. Каждый процесс, использующий очередь, должен предварительно получить разрешение на доступ в общий сегмент памяти с помощью системных запросов API, ибо очередь – это системный механизм, и для работы с ним требуются системные ресурсы и, соответственно, обращение к самой ОС.
Для наглядности, при обзоре механизмов реализации средств межпроцессного взаимодействия здесь и далее будем использовать конкретные системные вызовы ОС Unix.
Так, для работы с очередью сообщений процесс должен воспользоваться системным вызовом msgget, указав в качестве параметра значение ключа. Если очередь с данным ключом в настоящий момент не используется ни одним процессом, то для нее резервируется область памяти, а затем процессу возвращается идентификатор очереди, который, как и дескриптор файла, имеет локальное для процесса значение. Если же очередь уже используется, то процессу просто возвращается ее идентификатор.
После открытия очереди процесс может помещать в него сообщения с помощью вызова msgsnd или читать сообщения с помощью вызова msgrsv. Программист может влиять на то, как ОС будет обрабатывать ситуацию, когда процесс пытается читать сообщения, которые еще не поступили в очередь, то есть на синхронизацию процесса с данными.
Разделяемая память. Разделяемая память представляет собой сегмент физической памяти, отображенной в виртуальное адресное пространство двух или более процессов. Механизм разделяемой памяти поддерживается подсистемой виртуальной памяти, которая настраивает таблицы отображения адресов для процессов, запросивших разделение памяти, так что одни и те же адреса некоторой области физической памяти соответствуют виртуальным адресам разных процессов.
Для работы с разделяемой памятью используются четыре системных вызова:
· shmget – создает новый сегмент разделяемой памяти или находит существующий сегмент с тем же ключом;
· shmat – подключает сегмент с указанным дескриптором к виртуальной памяти обращающегося процесса;
· shmdt – отключает от виртуальной памяти ранее подключенный к ней сегмент с указанным виртуальным адресом начала;
· shmctl – служит для управления разнообразными параметрами, связанными существующим сегментом.
После того как сегмент разделяемой памяти подключен к виртуальной памяти процесса, процесс может обращаться к соответствующим элементам памяти с использованием обычных машинных команд чтения и записи, не прибегая к дополнительным системным вызовам. Синтаксис системного вызова shmget выглядит следующим образом:
shmid = shmget ( key, size, flag );
Параметр size определяет желаемый размер сегмента в байтах. Далее, если в таблице разделяемой памяти находится элемент, содержащий заданный ключ, и права доступа не противоречат текущим характеристикам обращающегося процесса, то значением системного вызова является дескриптор существующего сегмента (и обратившийся процесс так и не узнает реального размера сегмента, хотя впоследствии его можно узнать с помощью системного вызова shmctl). В противном случае создается новый сегмент, размер которого не меньше, чем установленный в системе минимальный размер сегмента разделяемой памяти, и не больше, чем установленный максимальный размер. Создание сегмента не означает немедленного выделения для него основной памяти. Это действие откладывается до первого системного вызова подключения сегмента к виртуальной памяти некоторого процесса. Аналогично, при выполнении последнего системного вызова отключения сегмента от виртуальной памяти соответствующая основная память освобождается.
Подключение сегмента к виртуальной памяти выполняется путем обращения к системному вызову shmat:
virtaddr = shmat ( id, addr, flags ).
Здесь id – ранее полученный дескриптор сегмента, addr – требуемый процессу виртуальный адрес, который должен соответствовать началу сегмента в виртуальной памяти. Значением системного вызова является реальный виртуальный адрес начала сегмента (его значение не обязательно совпадает со значением параметра addr). Если значением addr является нуль, ядро выбирает подходящий виртуальный адрес начала сегмента.
Для отключения сегмента от виртуальной памяти используется системный вызов shmdt:
Информация в лекции "Содержание" поможет Вам.
shmdt ( addr ),
где addr – виртуальный адрес начала сегмента в виртуальной памяти, ранее полученный с помощью системного вызова shmat. При этом система гарантирует (опираясь на данные таблицы сегментов процесса), что указанный виртуальный адрес действительно является адресом начала разделяемого сегмента в виртуальной памяти данного процесса.
Для управления памятью служит системный вызов shmctl:
shmctl ( id, cmd, shsstatbuf ).
Параметр cmd идентифицирует требуемое конкретное действие, то есть ту или иную функцию. Наиболее важной является функция уничтожения сегмента разделяемой памяти, которое производится следующим образом. Если к моменту выполнения системного вызова ни один процесс не подключил сегмент к своей виртуальной памяти, то основная память, занимаемая сегментом, освобождается, а соответствующий элемент таблицы разделяемых сегментов объявляется свободным. В противном случае в элементе таблицы сегментов выставляется флаг, запрещающий выполнение системного вызова shmget по отношению к этому сегменту, но процессам, успевшим получить дескриптор сегмента, по-прежнему разрешается подключать сегмент к своей виртуальной памяти. При выполнении последнего системного вызова отключения сегмента от виртуальной памяти операция уничтожения сегмента завершается.




















