
Основные понятия о базах данных
15.1. ОСНОВНЫЕ ПОНЯТИЯ
БАЗА ДАННЫХ
Общие положения
Цель любой информационной системы — обработка данных об объектах реального мира. В широком смысле слова база данных — это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления и в конечном счете автоматизации, например, предприятие, вуз и т.д.
Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро извлекать выборку с произвольным сочетанием признаков. Сделать это возможно, только если данные структурированы.
Структурирование — это введение соглашений о способах представления данных.
Неструктурированными называют данные, записанные, например, в текстовом файле.
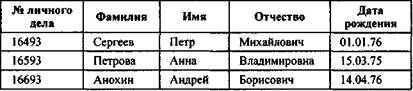
Пример 15.1. На рис. 15.1 пример неструктурированных данных, содержащих сведения о студентах (номер личного дела, фамилию, имя, отчество и год рождения). Легко убедиться, что сложно организовать поиск необходимых данных, хранящихся в неструктурированном виде, а упорядочить подобную информацию практически не представляется реальным.

Рекомендуемые материалы
Рис. 15.1. Пример неструктурированных данных
Чтобы автоматизировать поиск и систематизировать эти данные, необходимо выработать определенные соглашения о способах представления данных, т.е. дату рождения нужно записывать одинаково для каждого студента, она должна иметь одинаковую длину и определенное место среди остальной информации. Эти же замечания справедливы и для остальных данных (номер личного дела, фамилия, имя, отчество).
|
|
| Рис. 15.2. Пример структурированных данных |
Пример 15.2. После проведения несложной структуризации с информацией, указанной в примере (рис. 15.1), она будет выглядеть так, как это показано на рис. 15.2.
Пользователями базы данных могут быть различные прикладные программы, программные комплексы, а также специалисты предметной области, выступающие в роли потребителей или источников данных, называемые конечными пользователями.
В современной технологии баз данных предполагается, что создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляются централизованно с помощью специального программного инструментария — системы управления базами данных.
База данных (БД) — это поименованная совокупность структурированных данных, относящихся к определенной предметной области. Система управления базами данных (СУБД) — это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Централизованный характер управления данными в базе данных предполагает необходимость существования некоторого лица (группы лиц), на которое возлагаются функции администрирования данными, хранимыми в базе.
Классификация баз данных
По технологии обработки данных базы данных подразделяются на централизованные и распределенные.
Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования баз данных часто применяют в локальных сетях ПК.
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным (сетевым) доступом.
Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры подобных систем:
• файл-сервер;
• клиент-сервер.
Файл-сервер. Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно. Концепция файл-сервер условно отображена на рис. 15.3.
Клиент-сервер. В этой концепции подразумевается, что помимо хранения централизованной базы данных центральная машина (сервер базы данных) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка запросов SQL. Концепция клиент-сервер условно изображена на рис. 15.4.
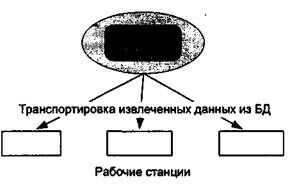
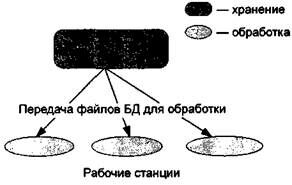
Рис. 15.3. Схема обработки информации Рис. 15.4. Схема обработки информации в БД по принципу в БД по принципу файл-сервер клиент-сервер
Структурные элементы базы данных
Понятие базы данных тесно связано с такими понятиями структурных элементов, как поле, запись, файл (таблица) (рис. 15,5).
Поле — элементарная единица логической организации данных, которая соответствует неделимой единице информации — реквизиту. Для описания поля используются следующие характеристики:
имя, например, Фамилия, Имя, Отчество, Дата рождения;
тип, например, символьный, числовой, календарный;
длина, например, 15 байт, причем будет определяться максимально возможным количеством символов;
точность для числовых данных, например два десятичных знака для отображения дробной части числа.
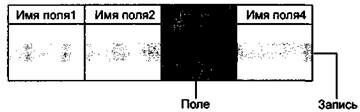
Рис. 15.5. Основные структурные элементы БД
Запись — совокупность логически связанных полей. Экземпляр записи — отдельная реализация записи, содержащая конкретные значения ее полей.
Файл (таблица) — совокупность экземпляров записей одной структуры.
Описание логической структуры записи файла содержит последовательность расположения полей записи и их основные характеристики, как это показано на рис. 15.6.
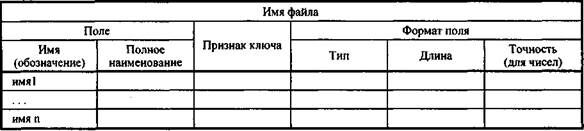
Рис. 15.6. Описание логической структуры записи файла
В структуре записи файла указываются поля, значения которых являются ключами: первичными (ПК), которые идентифицируют экземпляр записи, и вторичными (ВК), которые выполняют роль поисковых или группировочных признаков (по значению вторичного ключа можно найти несколько записей).
Пример 15.3. На рис. 15.7 приведен пример описания логической структуры записи файла (таблицы) СТУДЕНТ, содержимое которого приводится на рис 15.2. Структура записи файла СТУДЕНТ линейная, она содержит записи фиксированной длины. Повторяющиеся группы значений полей в записи отсутствуют. Обращение к значению поля производится по его номеру.
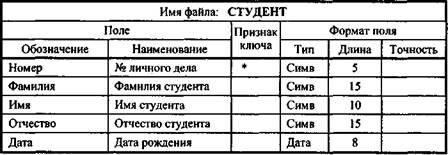
Рис. 15.7. Описание логической структуры записи файла СТУДЕНТ
ВИДЫ МОДЕЛЕЙ ДАННЫХ
Общие положения
Ядром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных — совокупность структур данных и операций их обработки.
СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве.
Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
Иерархическая модель данных
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рис. 15.8.
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рис. 15.8, для записи С4 путь проходит через записи А и В3.
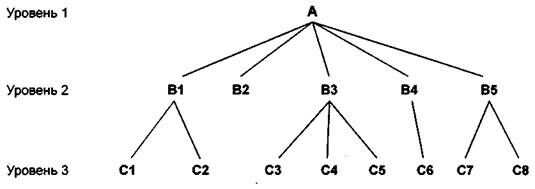
Рис. 15.8. Графическое изображение иерархической структуры БД
Пример 15.4. Пример, представленный на рис. 15.9, иллюстрирует использование иерархической модели базы данных.
Для рассматриваемого примера иерархическая структура правомерна, так как каждый студент учится в определенной (только одной) группе, которая относится к определенному (только одному) институту.
Сетевая модель данных
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
На рис. 15.10 изображена сетевая структура базы данных в виде графа.
Пример 15.5. Примером сложной сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС. Графическое изображение описанной в примере сетевой структуры, состоящей только из двух типов записей, показано на рис. 15.11. Единственное отношение представляет собой сложную связь между записями в обоих направлениях.
Реляционная модель данных
Понятие реляционный (англ, relation — отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда.
Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
• каждый элемент таблицы — один элемент данных;
• все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
• каждый столбец имеет уникальное имя;
• одинаковые строки в таблице отсутствуют;
• порядок следования строк и столбцов может быть произвольным.
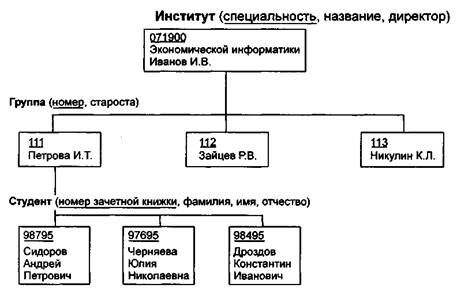
Рис. 15.9. Пример иерархической структуры БД
Рис. 15.10. Графическое изображение сетевой структуры
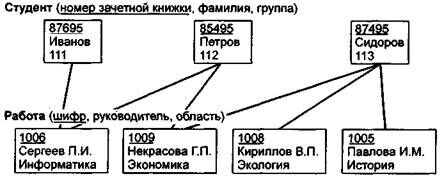
Рис. 15.11. Пример сетевой структуры БД
Пример 15.6. Реляционной таблицей можно представить информацию о студентах, обучающихся в вузе (рис. 15.12).

Рис. 15.12. Пример реляционной таблицы
Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы — атрибутам отношений, доменам, полям.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. В примере, показанном на рис. 15.12, ключевым полем таблицы является "№ личного дела".
Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ — ключ второй таблицы.
|
|
| Рис. 15.13. Пример реляционной модели |
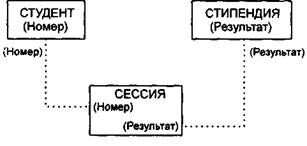
Пример 15.7. На рис. 15.13 показан пример реляционной модели, построенной на основе отношений: СТУДЕНТ, СЕССИЯ, СТИПЕНДИЯ.
СТУДЕНТ (Номер, Фамилия, Имя, Отчество, Пол, Дата рождения, Группа); СЕССИЯ (Номер, Оценка!, Оценка2, ОценкаЗ, Оценка4, Результат); СТИПЕНДИЯ (Результат, Процент).
Таблицы СТУДЕНТ И СЕССИЯ имеют совпадающие ключи (Номер), что дает возможность легко организовать связь между ними. Таблица СЕССИЯ имеет первичный ключ Номер и содержит внешний ключ Результат, который обеспечивает ее связь с таблицей СТИПЕНДИЯ.
15.2. РЕЛЯЦИОННЫЙ ПОДХОД К ПОСТРОЕНИЮ ИНФОЛОГИЧЕСКОЙ МОДЕЛИ
ПОНЯТИЕ ИНФОРМАЦИОННОГО ОБЪЕКТА
Информационный объект — это описание некоторой сущности (реального объекта, явления, процесса, события) в виде совокупности логически связанных реквизитов (информационных элементов). Такими сущностями для информационных объектов могут служить: цех, склад, материал, вуз, студент, сдача экзаменов и т.д.
Информационный объект определенного реквизитного состава и структуры образует класс (тип), которому присваивается уникальное имя (символьное обозначение), например Студент, Сессия, Стипендия.
Информационный объект имеет множество реализаций — экземпляров, каждый из которых представлен совокупностью конкретных значений реквизитов и идентифицируется значением ключа (простого — один реквизит или составного — несколько реквизитов). Остальные реквизиты информационного объекта являются описательными. При этом одни и те же реквизиты в одних информационных объектах могут быть ключевыми, а в других — описательными. Информационный объект может иметь несколько ключей.
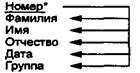
Пример 15.8. На рис. 15.14 представлен пример структуры и экземпляров информационного объекта Студент.
В информационном объекте Студент ключом является реквизит Номер (№ личного дела), к описательным реквизитам относятся: Фамилия (Фамилия студента), Имя (Имя студента), Отчество (Отчество студента), Дата (Дата рождения), Группа (№ группы). Если отсутствует реквизит Номер, то для однозначного определения характеристик конкретного студента необходимо использование составного ключа из трех реквизитов: Фамилия + Имя + Отчество.
|
|

| Рис. 15.14. Пример структуры и экземпляров информационного объекта |
|
|
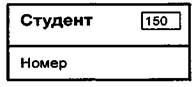
Пример 15.9. На рис.15.I5 изображен пример компактного представления информационного объекта Студент с обозначением имени объекта, ключа и указанием максимально возможного числа экземпляров записи.
| Пример 15.10. Пример представления информационного объекта Студент в виде графа на рис. 15.16. |
Рис. 15.15. Пример компактного представления информационного объекта
|
|
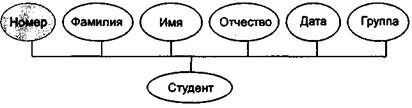
Рис. 15.16. Пример представления информационного объекта в виде графа
НОРМАЛИЗАЦИЯ ОТНОШЕНИЙ
Понятие нормализации отношений
Одни и те же данные могут группироваться в таблицы (отношения) различными способами, т.е. возможна организация различных наборов отношений взаимосвязанных информационных объектов. Группировка атрибутов в отношениях должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления. Определенный набор отношений обладает лучшими свойствами при включении, модификации, удалении данных, чем все остальные возможные наборы отношений, если он отвечает требованиям нормализации отношений.
Нормализация отношений — формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных.
Е.Коддом выделены три нормальные формы отношений и предложен механизм, позволяющий любое отношение преобразовать к третьей (самой совершенной) нормальной форме.
Первая нормальная форма
Отношение называется нормализованным или приведенным к первой нормальной форме, если все его атрибуты простые (далее неделимы). Преобразование отношения к первой нормальной форме может привести к увеличению количества реквизитов (полей) отношения и изменению ключа.
Например, отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой нормальной форме.
Вторая нормальная форма
Чтобы рассмотреть вопрос приведения отношений ко второй нормальной форме, необходимо дать пояснения к таким понятиям, как функциональная зависимость и полная функциональная зависимость.
Описательные реквизиты информационного объекта логически связаны с общим для них ключом, эта связь носит характер функциональной зависимости реквизитов.
Функциональная зависимость реквизитов — зависимость, при которой в экземпляре информационного объекта определенному значению ключевого реквизита соответствует только одно значение описательного реквизита.
Такое определение функциональной зависимости позволяет при анализе всех взаимосвязей реквизитов предметной области выделить самостоятельные информационные объекты.
|
|
Пример 15.11. Пример графического изображения функциональных зависимостей реквизитов Студент показан на рис. 15.17, на котором ключевой реквизит указан *.
Рис. 15.17. Графическое
изображение функциональной
зависимости реквизитов
В случае составного ключа вводится понятие функционально полной зависимости.
Функционально полная зависимость неключевых атрибутов заключается в том, что каждый неключевой атрибут функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа.
Отношение будет находиться во второй нормальной форме, если оно находится в первой нормальной форме, и каждый неключевой атрибут функционально полно зависит от составного ключа.
Пример 15.12. Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой и во второй нормальной форме одновременно, так как описательные реквизиты однозначно определены и функционально зависят от ключа Номер. Отношение Успеваемость = (Номер, Фамилия, Имя, Отчество, Дисциплина, оценка) находится в первой нормальной форме и имеет составной ключ Номер+Дисциплина. Это отношение не находится во второй нормальной форме, так как атрибуты Фамилия, Имя, Отчество не находятся в полной функциональной зависимости с составным ключом отношения.
Третья нормальная форма
Понятие третьей нормальной формы основывается на понятии нетранзитивной зависимости.
Транзитивная зависимость наблюдается в том случае, если один из двух описательных реквизитов зависит от ключа, а другой описательный реквизит зависит от первого описательного реквизита.
Отношение будет находиться в третьей нормальной форме, если оно находится во второй нормальной форме, и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Пример 15.13. Если в состав описательных реквизитов информационного объекта Студент включить фамилию старосты группы (Староста), которая определяется только номером группы, то одна и та же фамилия старосты будет многократно повторяться в разных экземплярах данного информационного объекта. В этом случае наблюдаются затруднения в корректировке фамилии старосты в случае назначения нового старосты, а также неоправданный расход памяти для хранения дублированной информации.
Для устранения транзитивной зависимости описательных реквизитов необходимо провести "расщепление" исходного информационного объекта. В результате расщепления часть реквизитов удаляется из исходного информационного объекта и включается в состав других (возможно, вновь созданных) информационных объектов.
Пример 15.14. "Расщепление" информационного объекта, содержащего транзитивную зависимость описательных реквизитов, показано на рис. 15.18. Как видно из рис. 15.17, исходный информационный объект Студент группы представляется в виде совокупности правильно структурированных информационных объектов (Студент и Группа), реквизитный состав которых тождественен исходному объекту. Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится одновременно в первой, второй и третьей нормальной форме.
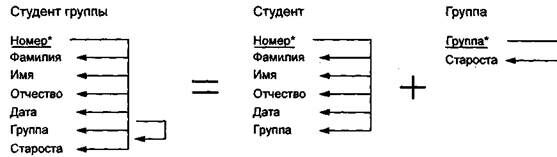
Рис. 15.18. Пример "расщепления" структуры информационного объекта
ТИПЫ СВЯЗЕЙ
Все информационные объекты предметной области связаны между собой. Различаются связи нескольких типов, для которых введены следующие обозначения:
• один к одному (1:1);
• один ко многим (1 :М);
• многие ко многим (М:М).
Рассмотрим эти типы связей на примере 15.15.
Пример 15.15. Дана совокупность информационных объектов, отражающих учебный процесс в вузе:
СТУДЕНТ (Номер, Фамилия, Имя, Отчество, Пол, Дата рождения, Группа) СЕССИЯ (Номер, Оценка!, 6ценка2, ОценкаЗ, Оценка4, Результат) СТИПЕНДИЯ (Результат, Процент) ПРЕПОДАВАТЕЛЬ (Код преподавателя, Фамилия, Имя, Отчество)
Связь один к одному (1:1) предполагает, что в каждый момент времени одному экземпляру информационного объекта А соответствует не более одного экземпляра информационного объекта В и наоборот.
|
|

| Рис. 15.19 иллюстрирует указанный тип отношений. |
Рис. 15.19. Графическое изображение реального отношения 1:1
Пример 15.16. Примером связи 1:1 может служить связь между информационными объектами СТУДЕНТ и СЕССИЯ:
СТУДЕНТ ↔ СЕССИЯ
Каждый студент имеет определенный набор экзаменационных оценок в сессию.
При связи один ко многим (1 :М) одному экземпляру информационного объекта А соответствует 0, 1 или более экземпляров объекта В, но каждый экземпляр объекта В связан не более чем с 1 экземпляром объекта А. Графически данное соответствие имеет вид, представленный на рис. 15.20.
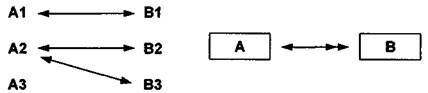
Рис. 15.20. Графическое изображение реального отношения 1 :М
Пример 15.17. Примером связи 1:М служит связь между информационными объектами СТИПЕНДИЯ и СЕССИЯ:
СТИПЕНДИЯ ↔> СЕССИЯ
Установленный размер стипендии по результатам сдачи сессии может повторяться многократно для различных студентов.
Связь многие ко многим (М:М) предполагает, что в каждый момент времени одному экземпляру информационного объекта А соответствует 0, 1 или более экземпляров объекта В и наоборот. На рис. 15.21 графически представлено указанное соответствие.

Рис. 15.21. Графическое изображение реального отношения М:М
Пример 15.18. Примером данного отношения служит связь между информационными объектами СТУДЕНТ и ПРЕПОДАВАТЕЛЬ:
СТУДЕНТ «–» ПРЕПОДАВАТЕЛЬ
Один студент обучается у многих преподавателей, один преподаватель обучает многих студентов.
ПОСТРОЕНИЕ ИНФОЛОГИЧЕСКОЙ МОДЕЛИ
Архитектура СУБД
Базы данных и программные средства их создания и ведения (СУБД) имеют многоуровневую архитектуру, представление о которой можно получить из рис. 15.22.
Различают концептуальный, внутренний и внешний уровни представления данных баз данных, которым соответствуют модели аналогичного назначения.
Концептуальный уровень соответствует логическому аспекту представления данных предметной области в интегрированном виде. Концептуальная модель состоит из множества экземпляров различных типов данных, структурированных в соответствии с требованиями СУБД к логической структуре базы данных.
Внутренний уровень отображает требуемую организацию данных в среде хранения и соответствует физическому аспекту представления данных. Внутренняя модель состоит из отдельных экземпляров записей, физически хранимых во внешних носителях.
Внешний уровень поддерживает частные представления данных, требуемые конкретным пользователям. Внешняя модель является подмножеством концептуальной модели. Возможно пересечение внешних моделей по данным. Частная логическая структура данных для отдельного приложения (задачи) или пользователя соответствует внешней модели или подсхеме БД. С помощью внешних моделей поддерживается санкционированный доступ к данным БД приложений (ограничен состав и структура данных концептуальной модели БД доступных в приложении, а также заданы допустимые режимы обработки этих данных: ввод, редактирование, удаление, поиск).
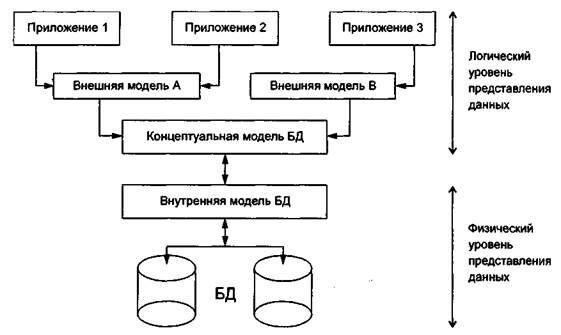
Рис. 15.22. Многоуровневое представление данных БД под управлением СУБД
|
|
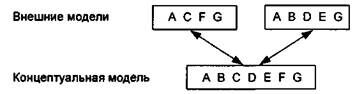
Пример 15.19. Соотношение между концептуальной и внешними моделями базы данных приведено на рис. 15.23.
Рис. 15.23. Пример соотношения
между концептуальной моделью
и внешними моделями
Появление новых или изменение информационных потребностей существующих приложений требуют определения для них корректных внешних моделей, при этом на уровне концептуальной и внутренней модели данных изменений не происходит. Изменения в концептуальной модели, вызванные появлением новых видов данных или изменением их структур, могут затрагивать не все приложения, т.е. обеспечивается определенная независимость программ от данных. Изменения в концептуальной модели должны отражаться на внутренней модели, и при неизменной концептуальной модели возможна самостоятельная модификация внутренней модели БД с целью улучшения ее характеристик (время доступа к данным, расхода памяти внешних устройств и др.). Таким образом БД реализует принцип относительной независимости логической и физической организации данных.
Понятие информационно-логической модели
Проектирование базы данных состоит в построении комплекса взаимосвязанных моделей данных. На рис. 15.24 условно отображены этапы процесса проектирования базы данных.
Важнейшим этапом проектирования базы данных является разработка инфологической (информационно-логической) модели предметной области, не ориентированной на СУБД. В инфологической модели средствами структур данных в интегрированном виде отражают состав и структуру данных, а также информационные потребности приложений (задач и запросов).
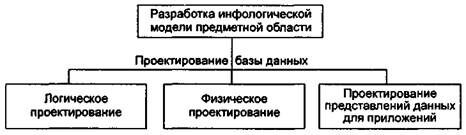
Рис. 15.24. Этапы процесса проектирования базы данных
Информационно-логическая (инфологическая) модель предметной области отражает предметную область в виде совокупности информационных объектов и их структурных связей.
Информация в лекции "Особенности кинетики биологических процессов" поможет Вам.
Инфологическая модель предметной области строится первой. Предварительная инфологическая модель строится еще на предпроектной стадии и затем уточняется на более поздних стадиях проектирования баз данных. Затем на ее основе строятся концептуальная (логическая), внутренняя (физическая) и внешняя модели.
|
|
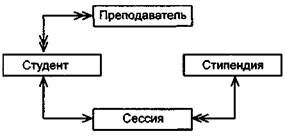
Пример 15.20. На рис. 15.25 представлена графическая форма информационно-логической модели, связывающей информационные объекты: Студент, Сессия, Стипендия, Преподаватель.
Рис. 15.25. Пример
графического представления
мифологической модели


















