COURSE (664969), страница 7
Текст из файла (страница 7)
Общая идея тривиальна: нужно разделить огромное число перебираемых вариантов на классы и получить оценки (снизу – в задаче минимизации, сверху – в задаче максимизации) для этих классов, чтобы иметь возможность отбрасывать варианты не по одному, а целыми классами. Трудность состоит в том, чтобы найти такое разделение на классы (ветви) и такие оценки (границы), чтобы процедура была эффективной.
Входные данные.
Алгоритм метода ветвей и границ предназначен для нахождения минимального гамильтонова контура на графе с N вершинами. В матрице расстояний задачи коммивояжера если между вершинами i и j нет дуги, то ставится символ "бесконечность". Этот же символ ставится по диагонали, что означает запрет на возвращение в вершину, через которую уже проходил контур.
Идея алгоритма.
Основная идея метода состоит в том, что вначале строят нижнюю границу длин множества гамильтоновых контуров ω0. Затем множество контуров разбивается на два подмножества таким образом, чтобы первое подмножество ω1ij состояло из гамильтоновых контуров, содержащих некоторую дугу (i,j), а другое подмножество ω1not ij не содержало этой дуги. Для каждого из подмножеств определяются нижние границы по тому же правилу, что и для первоначального множества гамильтоновых контуров. Полученные нижние границы подмножеств ω1ij и ω1not ij оказываются не меньше нижней границы всего множества гамильтоновых контуров, т.е.
Ф(ω0)<=Ф1ij,
Ф(ω0)<=Ф1not ij
Сравнивая нижние границы Ф1ij и Ф1not ij, можно выделить среди них то, которое с большей вероятностью содержит гамильтонов контур минимальной длины.
Затем одно из подмножеств ω1ij или ω1not ij по аналогичному правилу разбивается на два новых ω2ij и ω2ij. Для них снова отыскиваются нижние границы Ф2ij и Ф2not ij и т.д. Процесс ветвления продолжается до тех пор, пока не отыщется единственный гамильтонов контур. Его называют первым рекордом. Затем просматривают оборванные ветви. Если их нижние границы больше длины первого рекорда, то задача решена. Если же есть такие, для которых нижние границы меньше, чем длина первого рекорда, то подмножество с наименьшей нижней границей подвергается дальнейшему ветвлению, пока не убеждаются, что оно не содержит лучшего гамильтонова контура.
Если же такой найдется, то анализ оборванных ветвей продолжается относительно нового значения длины контура. Его называют вторым рекордом. Процесс решения заканчивается, когда будут проанализированы все подмножества.
Для практической реализации метода ветвей и границ применительно к задаче коммивояжера нужно указать прием определения нижних границ подмножеств и разбиения множества гамильтоновых контуров на подмножества (ветвление).
Определение нижних границ
Если к элементам любого ряда матрицы задачи коммивояжера (строке или столбцу) прибавить или вычесть из них некоторое число, то от этого оптимальность плана не изменится. Длина же любого гамильтонова контура изменится на данную величину.
Для того, чтобы найти нижнюю границу вычтем из каждой строки число, равное минимальному элементу этой строки, вычтем из каждого столбца число, равное минимальному элементу этого столбца. Полученная матрица называется приведенной по строкам и столбцам. Сумма всех вычтенных чисел называется константой приведения.
Константа приведения может быть выбрана в качестве нижней границы длины гамильтоновых контуров.
Разбиение множества контуров на подмножества
Для выделения претендентов на включение в множество дуг, по которым производится ветвление, рассмотрим в приведенной матрице все элементы, равные нулю. Найдем степени θij нулевых элементов этой матрицы. Степень нулевого элемента cij равна сумме минимальных элементов в строке i и столбце j при блокировании перехода (i,j) бесконечностью. С наибольшей вероятностью искомому гамильтонову контуру принадлежат дуги с максимальной степенью нуля.
Для получения матрицы контуров, включающей дугу (i,j) вычеркиваем в матрице строку i и столбец j, а чтобы не допустить образования не гамильтонова контура заменяем элемент замыкающий текущую цепочку на бесконечность.
Множество контуров, не включающих дугу (i,j) получаем путем замены элемента cij на бесконечность.
| - | 1 | 2 | 3 | 4 | 5 | 6 | |||
| 1 | - | 0 | 0 | 3 | 3 | 6 | |||
| 2 | 0 | - | 1 | 4 | 1 | 0 | |||
| 3 | 1 | 2 | - | 0 | 0 | 3 | |||
| 4 | 4 | 5 | 0 | - | 1 | 3 | |||
| 5 | 4 | 2 | 0 | 1 | - | 0 | |||
| 6 | 7 | 1 | 3 | 3 | 0 | - | |||
| 2 | 1 | 4 | |||||||
| табл. 4 | |||||||||
| - | 1 | 2 | 3 | 4 | 5 | 6 | |
| 1 | - | 2 | 0 | 4 | 3 | 10 | 4 |
| 2 | 0 | - | 1 | 5 | 1 | 4 | 6 |
| 3 | 1 | 4 | - | 1 | 0 | 7 | 3 |
| 4 | 4 | 7 | 0 | - | 1 | 7 | 4 |
| 5 | 4 | 4 | 0 | 2 | - | 4 | 3 |
| 6 | 7 | 3 | 3 | 4 | 0 | - | 7 |
| табл. 3 | |||||||
| - | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | - | 6 | 4 | 8 | 7 | 14 |
| 2 | 6 | - | 7 | 11 | 7 | 10 |
| 3 | 4 | 7 | - | 4 | 3 | 10 |
| 4 | 8 | 11 | 4 | - | 5 | 11 |
| 5 | 7 | 7 | 3 | 5 | - | 7 |
| 6 | 14 | 10 | 10 | 11 | 7 | - |
| табл. 2 | ||||||
Повторно запишем матрицу:
Вычитание константы из элементов любой строки или столбца матрицы С, не изменяет минимальный тур.
Для алгоритма нам будет удобно получить побольше нулей в матрице С, не получая там, однако, отрицательных чисел. Для этого мы вычтем из каждой строки ее минимальный элемент (это называется приведением по строкам, см. табл. 3), а затем вычтем из каждого столбца матрицы, приведенной по строкам, его минимальный элемент, получив матрицу, приведенную по столбцам (см. табл.4).
Прочерки по диагонали означают, что из города i в город i ходить нельзя. Заметим, что сумма констант приведения по строкам равна 27, сумма по столбцам 7, сумма сумм равна 34.
Тур можно задать системой из шести подчеркнутых (выделенных другим цветом) элементов матрицы С, например, такой, как показано на табл. 2. Подчеркивание элемента означает, что в туре из i-го элемента идут именно в j-ый. Для тура из шести городов подчеркнутых элементов должно быть шесть, так как в туре из шести городов есть шесть ребер. Каждый столбец должен содержать ровно один подчеркнутый элемент (в каждый город коммивояжер въехал один раз), в каждой строке должен быть ровно один подчеркнутый элемент (из каждого города коммивояжер выехал один раз); кроме того, подчеркнутые элементы должны описывать один тур, а не несколько меньших циклов. Сумма чисел подчеркнутых элементов есть стоимость тура. В таблице 2 стоимость равна 36, это тот минимальный тур, который получен лексикографическим перебором.
Теперь будем рассуждать от приведенной матрицы в табл. 2. Если в ней удастся построить правильную систему подчеркнутых элементов, т.е. систему, удовлетворяющую трем вышеописанным требованиям, и этими подчеркнутыми элементами будут только нули, то ясно, что для этой матрицы мы получим минимальный тур. Но он же будет минимальным и для исходной матрицы С, только для того, чтобы получить правильную стоимость тура, нужно будет обратно прибавить все константы приведения, и стоимость тура изменится с 0 до 34. Таким образом, минимальный тур не может быть меньше 34. Мы получили оценку снизу для всех туров.
Теперь приступим к ветвлению. Для этого проделаем шаг оценки нулей. Рассмотрим нуль в клетке (1,2) приведенной матрицы. Он означает, что цена перехода из города 1 в город 2 равна 0. А если мы не пойдем из города 1 в город 2? Тогда все равно нужно въехать в город 2 за цены, указанные во втором столбце; дешевле всего за 1 (из города 6). Далее, все равно надо будет выехать из города 1 за цену, указанную в первой строке; дешевле всего в город 3 за 0. Суммируя эти два минимума, имеем 1+0=1: если не ехать «по нулю» из города 1 в город 2, то надо заплатить не меньше 1. Это и есть оценка нуля. Оценки всех нулей поставлены на табл. 5 правее и выше
нуля (оценки нуля, равные нулю, не ставились).
Выберем максимальную из этих оценок (в примере есть несколько оценок, равных единице, выберем первую из них, в клетке (1,2)).
Итак, выбрано нулевое ребро (1,2). Разобьем все туры на два класса – включающие ребро (1,2) и не включающие ребро (1,2). Про второй класс можно сказать, что придется приплатить еще 1, так что туры этого класса стоят 35 или больше.
Что касается первого класса, то в нем надо рассмотреть матрицу в табл. 6 с вычеркнутой первой строкой и вторым столбцом.
Дополнительно в уменьшенной матрице поставлен запрет в клетке (2,1), т. к. выбрано ребро (1,2) и замыкать преждевременно тур ребром (2,1) нельзя.
| 1 | 3 | 4 | 5 | 6 |
| 2 | 1 | 4 | 1 | 0 |
| 3 | 01 | - | 1 | 3 |
| 4 | 0 | 1 | - | 0 |
| 5 | 3 | 3 | 01 | - |
| табл. 8 | ||||
| - | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | - | 01 | 0 | 3 | 3 | 6 |
| 2 | 01 | - | 1 | 4 | 1 | 0 |
| 3 | 1 | 2 | - | 01 | 0 | 3 |
| 4 | 4 | 5 | 01 | - | 1 | 3 |
| 5 | 4 | 2 | 0 | 1 | - | 0 |
| 6 | 7 | 1 | 3 | 3 | 01 | - |
| табл. 5 | ||||||
| - | 1 | 3 | 4 | 5 | 6 |
| 2 | 01 | 1 | 4 | 1 | 0 |
| 3 | 1 | - | 01 | 0 | 3 |
| 4 | 4 | 01 | - | 1 | 3 |
| 5 | 4 | 0 | 1 | - | 0 |
| 6 | 7 | 3 | 3 | 01 | - |
| - | 1 | 3 | 4 | 5 | 6 |
| 2 | 01 | 1 | 4 | 1 | 0 |
| 3 | 03 | - | 01 | 0 | 3 |
| 4 | 3 | 01 | - | 1 | 3 |
| 5 | 3 | 0 | 1 | - | 0 |
| 6 | 6 | 3 | 3 | 01 | - |
| табл. 7 | |||||
Уменьшенную матрицу можно привести на 1 по первому столбцу, так что каждый тур, ей отвечающий, стоит не меньше 35. Результат наших ветвлений и получения оценок показан на рис.6.
Кружки представляют классы: верхний кружок – класс всех тур ов; нижний левый – класс всех туров, включающих ребро (1,2); нижний правый – класс всех туров, не включающих ребро (1,2). Числа над кружками – оценки снизу.
ов; нижний левый – класс всех туров, включающих ребро (1,2); нижний правый – класс всех туров, не включающих ребро (1,2). Числа над кружками – оценки снизу.
Продолжим ветвление в положительную сторону: влево - вниз. Для этого оценим нули в уменьшенной матрице C[1,2] на табл. 7. Максимальная оценка в клетке (3,1) равна 3. Таким образом, оценка для правой нижней вершины на рис. 7 есть
| - | 3 | 4 | 6 |
| 2 | 1 | 3 | 03 |
| 4 | 03 | - | 3 |
| 5 | 0 | 03 | 0 |
| табл. 10 | |||
| - | 3 | 4 | 5 | 6 |
| 2 | 1 | 3 | 1 | 0 |
| 4 | 01 | - | 1 | 3 |
| 5 | 0 | 02 | - | 0 |
| 6 | 3 | 2 | 03 | - |
| табл. 9 | ||||
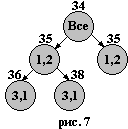 5+3=38. Для оценки левой нижней вершины на рис. 7 нужно вычеркнуть из матрицы C[1,2] еще строку 3 и столбец 1, получив матрицу C(1,2),(3,1) на табл. 8. В эту матрицу нужно поставить запрет в клетку (2,3), так как уже построен фрагмент тура из ребер (1,2) и (3,1), т.е. [3,1,2] и нужно запретить преждевременное замыкание (2,3). Эта матрица приводится по столбцу на 1 (табл. 9), таким образом, каждый тур соответствующего класса (т.е. тур, содержащий ребра (1,2) и (3,1)) стоит 36 и более.
5+3=38. Для оценки левой нижней вершины на рис. 7 нужно вычеркнуть из матрицы C[1,2] еще строку 3 и столбец 1, получив матрицу C(1,2),(3,1) на табл. 8. В эту матрицу нужно поставить запрет в клетку (2,3), так как уже построен фрагмент тура из ребер (1,2) и (3,1), т.е. [3,1,2] и нужно запретить преждевременное замыкание (2,3). Эта матрица приводится по столбцу на 1 (табл. 9), таким образом, каждый тур соответствующего класса (т.е. тур, содержащий ребра (1,2) и (3,1)) стоит 36 и более. Оцениваем теперь нули в приведенной матрице C[(1,2),(3,1)] нуль с максимальной оценкой 3 находится в клетке (6,5). Отрицательный вариант имеет оценку 38+3=41. Для получения оценки положительного варианта убираем строчку 6 и столбец 5, ставим запрет в клетку (5,6), см. табл. 10. Эта матрица неприводима. Следовательно, оценка положительного варианта не увеличивается (рис.8).
| - | 3 | 4 |
| 4 | 0 | - |
| 5 | 0 | 0 |
| табл. 11 | ||
В матрицу надо добавить запрет в клетку (5,3), ибо уже построен фрагмент тура [3,1,2,6,5] и надо запретить преждевременный возврат (5,3). Теперь, когда осталась матрица 2х2 с запретами по диагонали, достраиваем тур ребрами (4,3) и (5,4). Мы не зря ветвились, по положительным вариантам. Сейчас получен тур: 1→2→6→5→4→3→1 стоимостью в 36. При достижении низа по дереву перебора класс туров сузился до одного тура, а оценка снизу превратилась в точную стоимость.
матрицу надо добавить запрет в клетку (5,3), ибо уже построен фрагмент тура [3,1,2,6,5] и надо запретить преждевременный возврат (5,3). Теперь, когда осталась матрица 2х2 с запретами по диагонали, достраиваем тур ребрами (4,3) и (5,4). Мы не зря ветвились, по положительным вариантам. Сейчас получен тур: 1→2→6→5→4→3→1 стоимостью в 36. При достижении низа по дереву перебора класс туров сузился до одного тура, а оценка снизу превратилась в точную стоимость.
Итак, все классы, имеющие оценку 36 и выше, лучшего тура не содержат. Поэтому соответствующие вершины вычеркиваются. Вычеркиваются также вершины, оба потомка которой вычеркнуты. Мы колоссально сократили полный перебор. Осталось проверить, не содержит ли лучшего тура класс, соответствующий матрице С[Not(1,2)], т.е. приведенной матрице С с запретом в клетке 1,2, приведенной на 1 по столбцу (что дало оценку 34+1=35). Оценка нулей дает 3 для нуля в клетке (1,3), так что оценка отрицательного варианта 35+3 превосходит стоимость уже полученного тура 36 и отрицательный вариант отсекается.
Для получения оценки положительного варианта исключаем из матрицы первую строку и третий столбец, ставим запрет (3,1) и получаем матрицу. Эта матрица приводится по четвертой строке на 1, оценка класса достигает 36 и кружок зачеркивается. Поскольку у вершины «все» убиты оба потомка, она убивается тоже. Вершин не осталось, перебор окончен. Мы получили тот же минимальный тур, который показан подчеркиванием на табл. 2.
Удовлетворительных теоретических оценок быстродействия алгоритма Литтла и родственных алгоритмов нет, но практика показывает, что на современных ЭВМ они часто позволяют решить ЗК с n = 100. Это огромный прогресс по сравнению с полным перебором. Кроме того, алгоритмы типа ветвей и границ являются, если нет возможности доводить их до конца, эффективными эвристическими процедурами.
§6. Применение алгоритма Дейкстры к решению ЗК
Одним из вариантов решения ЗК является вариант нахождения кратчайшей цепи, содержащей все города. Затем полученная цепь дополняется начальным городом – получается искомый тур.
Известно множество простых алгоритмов. Один из них – алгоритм Дейкстры, предложенный Дейкстрой ещё в 1959г. Этот алгоритм решает общую задачу:
В ориентированной, неориентированной или смешанной сети найти кратчайший путь между двумя заданными вершинами.
При небольшой модификации алгоритм Дейкстры позволяет найти кратчайшие пути из данной вершины во все остальные. Матрица расстояний Dik задаёт длины дуг dik между i-ой и k-ой вершинами; если такой дуги нет, то dik присваивается большое число Б, равное “машинной бесконечности”. Алгоритм Дейкстры имеет квадратичную сложность O(n2).
Таким образом, для решения ЗК нужно n раз применить алгоритм Дейкстры следующим образом.
Возьмём произвольную пару вершин j,k. Исключим непосредственное ребро D[j,k]. С помощью алгоритма Дейкстры найдём кратчайшее расстояние между городами j,…,k. Пусть это расстояние включает некоторый город m. Имеем часть тура j,m,k. Теперь для каждой пары соседних городов (в данном примере – для j,m и m,k) удалим соответственное ребро и найдём кратчайшее расстояние. При этом в кратчайшее расстояние не должен входить уже использованный город.
Далее аналогично находим кратчайшее расстояние между парами вершин алгоритмом Дейкстры, до тех пор, пока все вершины не будут задействованы. Соединим последнюю вершину с первой и получим тур. Чаще всего это последнее ребро оказывается очень большим, и тур получается с погрешностью, однако алгоритм Дейкстры можно отнести к приближённым алгоритмам.
§7. Метод выпуклого многоугольника для решения ЗК
Рассмотрим рис. 9-10 и попытаемся найти в них кратчайшие туры. Очевидно, что кратчайший тур не должен содержать пересекающихся ребёр (в противном случае, поменяв вершины при пересекающихся рёбрах местами, получим более короткий тур). В первом случае кратчайшим является тур 1-2-4-5-3-1, а во втором – тур 1-2-3-4-5-1. Анализируя множество других аналогичных расположении пяти и более городов, можно сделать следующее общее предположение:
Если можно построить выпуклый многоугольник, по периметру к
 оторого лежат все города, то такой выпуклый многоугольник является кратчайшим туром.
оторого лежат все города, то такой выпуклый многоугольник является кратчайшим туром.
Однако не всегда можно построить выпуклый многоугольник, по периметру которого лежали бы все города. Велика вероятность того, что некоторые города не войдут в выпуклый многоугольник. Такие города будем называть “центральными”. Так как построить выпуклый многоугольник довольно легко, то задача сводится к тому, чтобы включить в тур в виде выпуклого многоугольника все центральные города с минимальными потерями. Пусть имеется массив T[n+1], содержащий в себе номера городов по порядку, которые должен посетить коммивояжер, т. е. вначале коммивояжер должен посетить город T[1], затем T[2], потом T[3] и т.д., причём T[n+1]=T[1] (коммивояжер должен вернуться в начальный город). Тогда, если выполняется равенство i![]() [1,2..n] C[T[i],p]+ C[p,T[i+1]]–C[T[I],T[i+1]] = min, то центральный город с номером p нужно включить в тур между городами T[i] и T[i+1]. Проделав эту операцию для всех центральных городов, в результате получим кратчайший тур. Для задачи, решённой нами методом ветвей и границ, этот алгоритм даёт правильное решение.
[1,2..n] C[T[i],p]+ C[p,T[i+1]]–C[T[I],T[i+1]] = min, то центральный город с номером p нужно включить в тур между городами T[i] и T[i+1]. Проделав эту операцию для всех центральных городов, в результате получим кратчайший тур. Для задачи, решённой нами методом ветвей и границ, этот алгоритм даёт правильное решение.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 1 | 13 | 6 | 13 | 14 | 15 | 14 | 16 | |
| 2 | 13 | 11 | 11 | 8 | 13 | 17 | 14 | |
| 3 | 6 | 11 | 5 | 6 | 11 | 7 | 11 | |
| 4 | 13 | 11 | 5 | 2 | 6 | 7 | 6 | |
| 5 | 14 | 8 | 6 | 2 | 6 | 5 | 6 | |
| 6 | 15 | 13 | 11 | 6 | 6 | 13 | 5 | |
| 7 | 14 | 17 | 7 | 7 | 5 | 13 | 9 | |
| 8 | 16 | 14 | 11 | 6 | 6 | 5 | 9 | |
| табл. 13 | ||||||||

Одним из возможных недостатков такого алгоритма является необходимость знать не матрицу расстояний, а координаты каждого города на плоскости. Если нам известна матрица расстояний между городами, но неизвестны их координаты, то для их нахождения нужно будет решить n систем квадратных уравнений с n неизвестными для каждой координаты. Уже для 6 городов это сделать очень сложно. Если же, наоборот, имеются координаты всех городов, но нет матрицы расстояний между ними, то создать эту матрицу несложно. Это можно легко сделать в уме для 5-6 городов. Для большего количества городов можно воспользоваться возможностями компьютера, в то время как промоделировать решение системы квадратных уравнений на компьютере довольно сложно.
На основе вышеизложенного можно сделать вывод, что этот алгоритм, наряду с деревянным алгоритмом и алгоритмом Дейкстры, можно отнести к приближённым (хотя за этим алгоритмом ни разу не было замечено выдачи неправильного варианта).
§8. Генетические алгоритмы
Пусть дана некоторая сложная функция (целевая функция), зависящая от нескольких переменных, и требуется найти такие значения переменных, при которых значение функции максимально. Задачи такого рода называются задачами оптимизации и встречаются на практике очень часто.
Г енетический алгоритм - это простая модель эволюции в природе, реализованная в виде компьютерной программы. В нем используются как аналог механизма генетического наследования, так и аналог естественного отбора. При этом сохраняется биологическая терминология в упрощенном виде. Вот как моделируется генетическое наследование:
енетический алгоритм - это простая модель эволюции в природе, реализованная в виде компьютерной программы. В нем используются как аналог механизма генетического наследования, так и аналог естественного отбора. При этом сохраняется биологическая терминология в упрощенном виде. Вот как моделируется генетическое наследование:
| Хромосома | Вектор (последовательность) из нулей и единиц. |
| Индивидуум = | Набор хромосом = вариант решения задачи. |
| Кроссовер | Операция, при которой две хромосомы обмениваются своими частями. |
| Мутация | Случайное изменение одной или нескольких позиций в хромосоме. |
Чтобы смоделировать эволюционный процесс, сгенерируем вначале случайную популяцию - несколько индивидуумов со случайным набором хромосом (числовых векторов). Генетический алгоритм имитирует эволюцию этой популяции как циклический процесс скрещивания индивидуумов и смены поколений.
Жизненный цикл популяции - это несколько случайных скрещиваний (посредством кроссовера) и мутаций, в результате которых к популяции добавляется какое-то количество новых индивидуумов. Отбором в генетическом алгоритме называется процесс формирования новой популяции из старой популяции, после чего старая популяция погибает. После отбора к новой популяции опять применяются операции кроссовера и мутации, затем опять происходит отбор, и так далее.
Отбор в генетическом алгоритме тесно связан с принципами естественного отбора в природе следующим образом:
| Приспособленность | Значение целевой функции на этом индивидууме. |
| Выживание наиболее | Популяция следующего поколения формируется в соответствии с целевой функцией. Чем приспособленнее индивидуум, тем больше вероятность его участия в кроссовере, т.е. размножении. |
Таким образом, модель отбора определяет, каким образом следует строить популяцию следующего поколения. Как правило, вероятность участия индивидуума в скрещивании берется пропорциональной его приспособленности. Часто используется так называемая стратегия элитизма, при которой несколько лучших индивидуумов переходят в следующее поколение без изменений, не участвуя в кроссовере и отборе. В любом случае каждое следующее поколение будет в среднем лучше предыдущего. Когда приспособленность индивидуумов перестает заметно увеличиваться, процесс останавливают и в качестве решения задачи оптимизации берут наилучшего из найденных индивидуумов.
Генетический алгоритм - новейший, но не единственно возможный с пособ решения задач оптимизации. С давних пор известны два основных пути решения таких задач - переборный и локально-градиентный. У этих методов свои достоинства и недостатки, и в каждом конкретном случае следует подумать, какой из них выбрать.
пособ решения задач оптимизации. С давних пор известны два основных пути решения таких задач - переборный и локально-градиентный. У этих методов свои достоинства и недостатки, и в каждом конкретном случае следует подумать, какой из них выбрать.
Рассмотрим достоинства и недостатки стандартных и генетических методов на примере классической задачи коммивояжера (TSP - traveling salesman problem). Суть задачи состоит в том, чтобы найти кратчайший замкнутый путь обхода нескольких городов, заданных своими координатами. Оказывается, что уже для 30 городов поиск оптимального пути представляет собой сложную задачу, побудившую развитие различных новых методов (в том числе нейросетей и генетических алгоритмов).
Каждый вариант решения (для 30 городов) - это числовая строка, где на j-ом месте стоит номер j-ого по порядку обхода города. Таким образом, в этой задаче 30 параметров, причем не все комбинации значений допустимы. Естественно, первой идеей является полный п еребор всех вариантов обхода.
еребор всех вариантов обхода.
Переборный метод наиболее прост по своей сути и тривиален в программировании. Для поиска оптимального решения (точки максимума целевой функции) требуется последовательно вычислить значения целевой функции во всех возможных точках, запоминая максимальное решение. Недостатком этого метода является большая вычислительная стоимость. В частности, в задаче коммивояжера потребуется просчитать длины более 1 030 вариантов путей, что совершенно нереально. Однако, если перебор всех вариантов за разумное время возможен, то можно быть абсолютно уверенным в том, что найденное решение действительно оптимально.
030 вариантов путей, что совершенно нереально. Однако, если перебор всех вариантов за разумное время возможен, то можно быть абсолютно уверенным в том, что найденное решение действительно оптимально.
Второй популярный способ основан на методе градиентного спуска. При этом вначале выбираются некоторые случайные значения параметров, а затем эти значения постепенно изменяют, добиваясь наибольшей скорости роста целевой функции. Дост игнув локального максимума, такой алгоритм останавливается, поэтому для поиска глобального оптимума потребуются дополнительные усилия.
игнув локального максимума, такой алгоритм останавливается, поэтому для поиска глобального оптимума потребуются дополнительные усилия.
Градиентные методы работают очень быстро, но не гарантируют оптимальности найденного решения. Они идеальны для применения в так называемых унимодальных задачах, где целевая функция имеет единственный локальный максимум (он же - глобальный). Легко видеть, что задача коммивояжера унимодальной не является.
Типичная практическая задача, как правило, мультимодальна и многомерна, то есть содержит много параметров. Для таких задач не существует ни одного универсального метода, который позволял бы достаточно быстро найти абсолютно точное решение.
Однако, комбинируя переборный и градиентный методы, можно надеяться получить хотя бы приближенное решение, точность которого будет возрастать при увеличении времени расчета.
Генетический алгоритм представляет собой именно такой комбинированный метод. Механизмы с крещивания и мутации в каком-то смысле реализуют переборную часть метода, а отбор лучших решений - градиентный спуск. На рисунке показано, что такая комбинация позволяет обеспечить устойчиво хорошую эффективность генетического поиска для любых типов задач.
крещивания и мутации в каком-то смысле реализуют переборную часть метода, а отбор лучших решений - градиентный спуск. На рисунке показано, что такая комбинация позволяет обеспечить устойчиво хорошую эффективность генетического поиска для любых типов задач.
Итак, если на некотором множестве задана с ложная функция от нескольких переменных, то генетический алгоритм - это программа, которая за разумное время находит точку, где значение функции достаточно близко к максимально возможному. Выбирая приемлемое время расчета, мы получим одно из лучших решений, которые вообще возможно получить за это время.
ложная функция от нескольких переменных, то генетический алгоритм - это программа, которая за разумное время находит точку, где значение функции достаточно близко к максимально возможному. Выбирая приемлемое время расчета, мы получим одно из лучших решений, которые вообще возможно получить за это время.
§9. Применение генетических алгоритмов
Определим теперь понятия, соответствующие мутации и кроссинговеру в генетическом алгоритме.
Мутация — это преобразование хромосомы, случайно изменяющее одну или несколько ее позиций (генов). Наиболее распространенный вид мутаций — случайное изменение только одного из генов хромосомы.
Кроссинговер (в литературе по генетическим алгоритмам также употребляется название кроссовер или скрещивание) — это операция, при которой из двух хромосом порождается одна или несколько новых хромосом. В простейшем случае кроссинговер в генетическом алгоритме реализуется так же, как и в биологии (см. рис. 1). При этом хромосомы разрезаются в случайной точке и обмениваются частями между собой. Например, если хромосомы (1, 2, 3, 4, 5) и (0, 0, 0, 0, 0) разрезать между третьим и четвертым генами и обменять их части, то получатся потомки (1, 2, 3, 0, 0) и (0, 0, 0, 4, 5).
Блок-схема генетического алгоритма изображена на рис. 1. Вначале генерируется начальная популяция особей (индивидуумов), т.е. некоторый набор решений задачи. Как правило, это делается случайным образом. Затем мы должны смоделировать размножение внутри этой популяции. Для этого случайно отбираются несколько пар индивидуумов, производится скрещивание между хромосомами в каждой паре, а полученные новые хромосомы помещаются в популяцию нового поколения. В генетическом алгоритме сохраняется основной принцип естественного отбора — чем приспособленнее индивидуум (чем больше соответствующее ему значение целевой функции), тем с большей вероятностью он будет участвовать в скрещивании. Теперь моделируются мутации — в нескольких случайно выбранных особях нового поколения изменяются некоторые гены. Затем старая популяция частично или полностью уничтожается и мы переходим к рассмотрению следующего поколения. Популяция следующего поколения в большинстве реализаций генетических алгоритмов содержит столько же особей, сколько начальная, но в силу отбора приспособленность в ней в среднем выше. Теперь описанные процессы отбора, скрещивания и мутации повторяются уже для этой популяции и т. д.
В каждом следующем поколении мы будем наблюдать возникновение совершенно новых решений нашей задачи. Среди них будут как плохие, так и хорошие, но благодаря отбору число хороших решений будет возрастать. Заметим, что в природе не бывает абсолютных гарантий, и даже самый приспособленный тигр может погибнуть от ружейного выстрела, не оставив потомства. Имитируя эволюцию на компьютере, мы можем избегать подобных нежелательных событий и всегда сохранять жизнь лучшему из индивидуумов текущего поколения — такая методика называется “стратегией элитизма”.
Чтобы использовать генетический алгоритм для решения практических задач, необходимо рассматривать более сложные варианты введенных выше понятий. Поясним это на примере задачи коммивояжера для 20 городов.
В качестве индивидуумов будем рассматривать маршруты обхода. Информацию о маршруте можно записать в виде одной хромосомы — вектора длины 20, где в первой позиции стоит номер первого города на пути следования, затем — номер второго города и т. д. Первое затруднение возникает, когда мы пытаемся определить мутации для таких хромосом — стандартная операция, изменяющая только одну позицию вектора, недопустима, так как приводит к некорректному маршруту. Но можно определить мутацию как перестановку значений двух случайно выбранных генов. При таком преобразовании путь следования меняется только в двух городах.
Найденный маршрут, вероятно, не является самым оптимальным, но близок к нему по длине — как правило, генетические алгоритмы “ошибаются” не более чем на 5—10%. Этот недостаток компенсируется для комбинаторных задач относительно высокой скоростью работы — в нашем примере ответ был получен за 25 секунд. На практике генетические алгоритмы нередко используют совместно с другими методами, которые позволяют повысить их точность.
Эксперименты показали, что погрешность разработанного алгоритма не зависит от погрешности начального решения и составляет (максимальные значения) для ориентированных графов - 5%, для неориентированных 1%. Причем в 90% случаев алгоритм находил точное решение. Эксперименты проводились для графов с количеством вершин, меньшим 75 (где было возможным нахождение точного решения).
Список литературы
-
В.М. Бондарев, В.И. Рублинецкий, Е.Г. Качко. Основы программирования, 1998 г.
-
Н. Кристофидес. Теория графов: алгоритмический подход, Мир, 1978 г.
-
Ф.А. Новиков. Дискретная математика для программистов, Питер, 2001 г.
-
В.А. Носов. Комбинаторика и теория графов, МГТУ, 1999 г.
-
О. Оре. Теория графов, Наука, 1982 г.
-
www.codenet.ru
-
www.algolist.ru
42
















