Вордовские лекции (1115151), страница 24
Текст из файла (страница 24)
int main(int argc, char **argv)
{
struct sockaddr_un party_addr, own_addr;
int sockfd;
int is_server;
char buf[BUFLEN];
int party_len;
int quitting;
if (argc != 2) {
printf("Usage: %s client|server.\n", argv[0]);
return 0;
}
quitting = 1;
/* определяем, кто мы: клиент или сервер*/
is_server = !strcmp(argv[1], "server");
memset(&own_addr, 0, sizeof(own_addr));
own_addr.sun_family = AF_UNIX;
strcpy(own_addr.sun_path, is_server?SADDRESS:CADDRESS);
/* создаем сокет */
if ((sockfd = socket(AF_UNIX, SOCK_DGRAM, 0)) < 0) {
printf("can't create socket\n");
return 0;
}
/* связываем сокет */
unlink(own_addr.sun_path);
if (bind(sockfd, (struct sockaddr *) &own_addr,
sizeof(own_addr.sun_family)+
strlen(own_addr.sun_path)) < 0)
{
printf("can't bind socket!");
return 0;
}
if (!is_server)
{
/* это – клиент */
memset(&party_addr, 0, sizeof(party_addr));
party_addr.sun_family = AF_UNIX;
strcpy(party_addr.sun_path, SADDRESS);
printf("type the string: ");
while (gets(buf)) {
/* не пора ли выходить? */
quitting = (!strcmp(buf, "quit"));
/* считали строку и передаем ее серверу */
if (sendto(sockfd, buf, strlen(buf) + 1, 0,
(struct sockaddr *) &party_addr,
sizeof(party_addr.sun_family) +
strlen(SADDRESS)) != strlen(buf) + 1)
{
printf("client: error writing socket!\n");
return 0;
}
/*получаем ответ и выводим его на печать*/
if (recvfrom(sockfd, buf, BUFLEN, 0, NULL, 0) < 0)
{
printf("client: error reading socket!\n");
return 0;
}
printf("client: server answered: %s\n", buf);
if (quitting) break;
printf("type the string: ");
} // while
close(sockfd);
return 0;
} // if (!is_server)
/* это – сервер */
while (1)
{
/* получаем строку от клиента и выводим на печать */
party_len = sizeof(party_addr);
if (recvfrom(sockfd, buf, BUFLEN, 0,(struct sockaddr *)
&party_addr, &party_len) < 0)
{
printf("server: error reading socket!");
return 0;
}
printf("server: received from client: %s \n", buf);
/* не пора ли выходить? */
quitting = (!strcmp(buf, "quit"));
if (quitting) strcpy(buf, "quitting now!");
else
if (!strcmp(buf, "ping!")) strcpy(buf, "pong!");
else strcpy(buf, "wrong string!");
/* посылаем ответ */
if (sendto(sockfd, buf, strlen(buf) + 1, 0,
(struct sockaddr *) &party_addr,
party_len) != strlen(buf)+1)
{
printf("server: error writing socket!\n");
return 0;
}
if (quitting) break;
} // while
close(sockfd);
return 0;
}
Пример работы с сокетами в рамках сети.
В качестве примера работы с сокетами в домене AF_INET напишем простой web-сервер, который будет понимать только одну команду :
GET /<имя файла>
Сервер запрашивает у системы сокет, связывает его с адресом, считающимся известным, и начинает принимать клиентские запросы. Для обработки каждого запроса порождается отдельный потомок, в то время как родительский процесс продолжает прослушивать сокет. Потомок разбирает текст запроса и отсылает клиенту либо содержимое требуемого файла, либо диагностику (“плохой запрос” или “файл не найден”).
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/stat.h>
#include <netinet/in.h>
#include <stdio.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
#define PORTNUM 8080
#define BACKLOG 5
#define BUFLEN 80
#define FNFSTR "404 Error File Not Found "
#define BRSTR "Bad Request "
int main(int argc, char **argv)
{
struct sockaddr_in own_addr, party_addr;
int sockfd, newsockfd, filefd;
int party_len;
char buf[BUFLEN];
int len;
int i;
/* создаем сокет */
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
printf("can't create socket\n");
return 0;
}
/* связываем сокет */
memset(&own_addr, 0, sizeof(own_addr));
own_addr.sin_family = AF_INET;
own_addr.sin_addr.s_addr = INADDR_ANY;
own_addr.sin_port = htons(PORTNUM);
if (bind(sockfd, (struct sockaddr *) &own_addr,
sizeof(own_addr)) < 0)
{
printf("can't bind socket!");
return 0;
}
/* начинаем обработку запросов на соединение */
if (listen(sockfd, BACKLOG) < 0)
{
printf("can't listen socket!");
return 0;
}
while (1) {
memset(&party_addr, 0, sizeof(party_addr));
party_len = sizeof(party_addr);
/* создаем соединение */
if ((newsockfd = accept(sockfd, (struct sockaddr *)
&party_addr, &party_len)) < 0)
{
printf("error accepting connection!");
return 0;
}
if (!fork())
{
/*это – сын, он обрабатывает запрос и посылает ответ*/
close(sockfd); /* этот сокет сыну не нужен */
if ((len = recv(newsockfd, &buf, BUFLEN, 0)) < 0)
{
printf("error reading socket!");
return 0;
}
/* разбираем текст запроса */
printf("received: %s \n", buf);
if (strncmp(buf, "GET /", 5))
{ /*плохой запрос!*/
if (send(newsockfd, BRSTR, strlen(BRSTR) + 1, 0) != strlen(BRSTR) + 1)
{
printf("error writing socket!");
return 0;
}
shutdown(newsockfd, 1);
close(newsockfd);
return 0;
}
for (i=5;buf[i] && (buf[i] > ' ');i++);
buf[i] = 0;
/* открываем файл */
if((filefd = open(buf+5, O_RDONLY)) < 0) {
/* нет файла! */
if (send(newsockfd, FNFSTR, strlen(FNFSTR) + 1, 0) != strlen(FNFSTR) + 1)
{
printf("error writing socket!");
return 0;
}
shutdown(newsockfd, 1);
close(newsockfd);
return 0;
}
/* читаем из файла порции данных и посылаем их клиенту */
while (len = read(filefd, &buf, BUFLEN))
if (send(newsockfd, buf, len, 0) < 0) {
printf("error writing socket!");
return 0;
}
close(filefd);
shutdown(newsockfd, 1);
close(newsockfd);
return 0;
}
/* процесс – отец. Он закрывает новый сокет и
продолжает прослушивать старый */
close(newsockfd);
}
}
9.2Интерфейс передачи сообщений: MPI.
9.2.1Базовые архитектуры.
Основным параметром классификации параллельных компьютеров является наличие общей памяти (в симметричных мультипроцессорных системах – SMP) или распределенной памяти (в массивно-параллельных системах – MPP). Нечто среднее между SMP и MPP представляют собой NUMA архитектуры – системы с неоднородным доступом к памяти. Память в NUMA-системах физически распределена, но логически общедоступна. Кластерные системы являются более дешевым вариантом MPP.
Массивно-параллельные системы (MPP) состоят из однородных вычислительных узлов, включающих
-
один или несколько процессоров (обычно RISC – reduced instruction set computer),
-
локальную память (прямой доступ к памяти с других узлов невозможен),
-
коммуникационный процессор или сетевой адаптер,
-
иногда – жесткие диски и/или другие устройства ввода/вывода.
К системе могут быть добавлены специальные узлы ввода-вывода и управляющие узлы. Узлы связаны через высокоскоростную сеть, коммутатор и т.п. Число процессоров в MPP-системах может достигать нескольких тысяч.
Существует два способа управления массивно-параллельными системами.
-
На каждом узле может работать полноценная, UNIX-подобная операционная система, функционирующая отдельно от других узлов.
-
Полноценная ОС работает только на управляющей машине, на каждом узле работает сильно урезанный вариант ОС, обеспечивающий работу соответствующей ветви параллельного приложения.
Схема MPP системы, где каждый вычислительный узел (ВУ) имеет процессорный элемент (например, RISC процессор, одинаковый для всех ВУ), память и коммуникационное устройство:
ВУ№1
ВУ№2
ВУ№N



Управляющий узел(ы)
... .........

ВУ№...
ВУ№M
ВУ№..
Ввод-вывод
... ..........
Программы для MPP-систем создаются в рамках модели передачи сообщений. Применяются технологии MPI, PVM и др.
Примеры массивно-параллельных систем – SGI/CRAY T3E, транспьютерные системы Parsytec.
Симметричные мультипроцессорные системы (SMP) состоят из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины, либо с помощью коммутатора. Аппаратно поддерживается согласованность данных в кэшах. Схематично SMP архитектуру можно изобразить так:
О б щ а я п а м я т ь


Высокоскоростная среда передачи данных
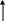
CPU
CPU
CPU
CPU
CPU
….. …….
Наличие общей памяти сильно упрощает взаимодействие процессоров, однако накладывает сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам, но иногда возможна и явная привязка. Программы для SMP-систем создаются в рамках модели общей памяти.. (POSIX threads, OpenMP). Стандарт MPI-2 позволяет создавать программы и для SMP-систем.
Системы с неоднородным доступом к памяти (NUMA) строятся на однородных базовых модулях. Модули состоят из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной. Обычно аппаратно поддерживается когерентность кэшей во всей системе (архитектура cc-NUMA – cache-coherent NUMA).
Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддержки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров.
Обычно вся система работает под управлением единой ОС. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000). Модель программирования - аналогична той, что используется на симметричных мультипроцессорных системах.
Примеры NUMA-систем: Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600.
Кластерные системы представляют собой набор рабочих станций (или даже ПК) общего назначения и используется в качестве дешевого варианта массивно-параллельного компьютера. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet). При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах. Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций.
В качестве операционной системы в кластерных системах чаще всего применяются свободно распространяемые ОС - Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и распределения нагрузки.
Взаимодействие узлов осуществляется, как правило, в рамках модели передачи сообщений (чаще всего - MPI). Дешевизна подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач. Примеры: NT-кластер в NCSA, Beowulf-кластеры.
В ы с о к о с к о р о с т н а я с е т ь


















