
Информационные сервисы Internet2
Информационные сервисы Internet2
4.1 Электронная почта в Internet
Электронная почта - один из важнейших информационных ресурсов Internet. Она является самым массовым средством электронных коммуникаций. Любой из пользователей Internet имеет свой почтовый ящик в сети.
4.1.1. Принципы организации
Электронная почта во многом похожа на обычную почтовую службу. Корреспонденция, подготавливается пользователем на своем рабочем месте либо программой подготовки почты, либо просто обычным текстовым редактором. Обычно, программа подготовки почты вызывает текстовый редактор, который пользователь предпочитает всем остальным программам этого типа. Затем пользователь должен вызвать программу отправки почты (программа подготовки почты вызывает программу отправки автоматически).
Для работы электронной почты в Internet разработан специальный протокол Simple Mail Transfer Protocol (SMTP), который является протоколом прикладного уровня и использует транспортный протокол TCP. Однако, совместно с этим протоколом используется и Unix-Unix-CoPy (UUCP) протокол. UUCP хорошо подходит для использования телефонных линий связи. Разница между SMTP и UUCP заключается в том, что при использовании первого протокола почтовый сервис пытается найти машину-получателя почты и установить с ней взаимодействие в режиме on-line для того, чтобы передать почту в ее почтовый ящик. В случае использования SMTP почта достигает почтового ящика получателя за считанные минуты и время получения сообщения зависит только от того, как часто получатель просматривает свой почтовый ящик. При использовании UUCP почта передается по принципу "stop-go", т.е. почтовое сообщение передается по цепочке почтовых серверов от одной машины к другой пока не достигнет машины-получателя или не будет отвергнуто по причине отсутствия абонента-получателя. С одной стороны, UUCP позволяет доставлять почту по плохим телефонным каналам, т.к. не требуется поддерживать линию в течении времени доставки от отправителя к получателю, а с другой стороны бывает обидно получить возврат сообщения через сутки после его отправки из-за того, что допущена ошибка в имени пользователя. В целом же общие рекомендации таковы: если имеется возможность надежно работать в режиме on-line и это является нормой, то следует настраивать почту для работы по протоколу SMTP, если линии связи плохие или on-line используется чрезвычайно редко, то лучше использовать UUCP.
Основой любой почтовой службы является система адресов. Без точного адреса невозможно доставить почту адресату. В Internet принята система адресов, которая базируется на доменном адресе машины, подключенной к сети.
4.1.2. Формат почтового сообщения (RFC-822)
Рекомендуемые материалы
Формат почтового сообщения Internet определен в документе RFC-822 (Standard for ARPA Internet Text Message). Это довольно большой документ объемом в 47 страниц машинописного текста. Почтовое сообщение состоит из трех частей: конверта, заголовка и тела сообщения. Пользователь видит только заголовок и тело сообщения. Конверт используется только программами доставки. Заголовок всегда находится перед телом сообщения и отделен от него пустой строкой. RFC-822 регламентирует содержание заголовка сообщения. Заголовок состоит из полей. Поля состоят из имени поля и содержания поля. Имя поля отделено от содержания символом ":". Минимально необходимыми являются поля Date, From, To.
Поле Date определяет дату отправки сообщения, поле From - отправителя, а поля To - получателя(ей). Чаще заголовок содержит дополнительные поля:
поле Sender указывает на отправителя. Поле Message-ID содержит уникальный идентификатор сообщения и используется программами доставки почты. Поле Subject определяет тему сообщения, Reply-To - пользователя, которому отвечают, Comment – комментарий. Поле Received: содержит транзитные адреса почтовых серверов с датой и временем прохождения сообщения. Вся эта информация полезна при разборе трудностей с доставкой почты.
Следует сказать, что формат сообщения постоянно дополняется и совершенствуется. В заключении хотелось бы отметить, что возможности почты не ограничиваются только пересылкой корреспонденции. По почте можно получить доступ ко многим ресурсам Internet, которые имеют почтовых роботов, отвечающих на запросы страждущих. Поэтому имеет смысл более детально изучить программное обеспечение, поддерживающее e-mail. Время, затраченное на чтение документации и опыты, окупятся возможностью получения информации из информационных архивов сети.
4.1.3. Формат представления почтовых сообщений MIME и его влияние на информационные технологии Internet
Стандарт MIME (Multipurpose Internet Mail Extensions или в нотации Internet, RFC-1341) предназначен для описания тела почтового сообщения Internet. Предшественником MIME является Стандарт почтового сообщения ARPA (RFC-822). Стандарт RFC-822 был разработан для обмена текстовыми сообщениями. С момента опубликования стандарта возможности аппаратных средств и телекоммуникаций ушли далеко вперед и стало ясно, что многие типы информации, которые широко используются в сети, невозможно передать по почте без специальных преобразований. Так в тело сообщения нельзя включить графику, аудио, видео и другие типы информации. RFC-822 не дает возможностей для передачи даже текстовой информации, которую нельзя реализовать 7-битовой кодировкой ASCII. Естественно, что при использовании RFC-822 не может быть и речи о передаче размеченного текста для отображения его различными стилями. Ограничения RFC-822 становятся еще более очевидными, когда речь заходит об обмене сообщениями в разных почтовых системах.
В некотором смысле стандарт MIME ортогонален стандарту RFC-822. Если последний подробно описывает в заголовке почтового сообщения текстовое тело письма и механизм его рассылки, то MIME, главным образом, ориентирован на описание в заголовке письма структуры тела почтового сообщения и возможности составления письма из информационных единиц различных типов.
В стандарте зарезервировано несколько способов представления разнородной информации. Для этого используются специальные поля заголовка почтового сообщения:
· поле версии MIME, которое используется для идентификации сообщения, подготовленного в новом стандарте;
· поле описания типа информации в теле сообщения, которое позволяет обеспечить правильную интерпретацию данных;
· поле типа кодировки информации в теле сообщения, указывающее на тип процедуры декодирования;
· два дополнительных поля, зарезервированных для более детального описания тела сообщения.
Стандарт MIME разработан как расширяемая спецификация, в которой подразумевается, что число типов данных будет расти по мере развития форм представления данных. При этом следует учитывать, что анархия типов (безграничное их увеличение) тоже не допустима.
4.1.4 Поля в MIME
Поле версии MIME (MIME-Version) Поле версии указывается в заголовке почтового сообщения и позволяет программе рассылки почты определить, что сообщение подготовлено в стандарте MIME. Поле версии указывается в общем заголовке почтового сообщения и относится ко всему сообщению целиком. Необходимо отметить, что в отличии от стандарта RFC-822 стандарт MIME позволяет перемешивать поля заголовка сообщения с телом сообщения. Поэтому все поля делятся на два класса: общие поля заголовка, которые записываются в начале почтового сообщения и частные поля заголовка, которые относятся только к отдельным частям составного сообщения и записываются перед ними.
Поле типа содержания тела почтового сообщения (Content-Type) Поле типа используется для описания типа данных, которые содержатся в теле почтового сообщения. Это поле сообщает программе чтения почты, какого сорта преобразования необходимы для того, чтобы сообщение правильно проинтерпретировать. Эта же информация используется и программой рассылки при кодировании/декодировании почты. Стандарт MIME определяет семь типов данных, которые можно передавать в теле письма:
текст (text); смешанный тип (multipart); почтовое сообщение (message); графический образ (image); аудио-информация (audio); фильм или видео (video); приложение (application).
Поле типа кодирования почтового сообщения (Content-Transfer-Encoding) Многие данные передаются по почте в их исходном виде. Это могут быть 7bit символы, 8bit символы, 64base символы и т.п. Однако, при работе в разнородных почтовых средах необходимо определить механизм их представления в стандартном виде.
Дополнительные необязательные поля "Content-ID" и "Content-Description". Первое поле определяет уникальный идентификатор содержания, а второе служит для комментария содержания. Ни то, ни другое программами просмотра, обычно, не отображаются.
4.1.5 Протокол обмена почтой SMTP (Simple Mail Transfer Protocol)
Протокол SMTP был разработан для обмена почтовыми сообщениями в сети Internet. SMTP не зависит от транспортной среды и может использоваться для доставки почты в сетях с протоколами, отличными от TCP/IP и Х.25. Достигается это за счет концепции IPCE (Inter-Process Communication Environment). IPCE позволяет взаимодействовать процессам, поддерживающим SMTP, в интерактивном режиме, а не в режиме "STOP-GO".
Модель протокола. Взаимодействие в рамках SMTP строится по принципу двусторонней связи, которая устанавливается между отправителем и получателем почтового сообщения. При этом отправитель инициирует соединение и посылает запросы на обслуживание, а получатель - отвечает на эти запросы. Фактически, отправитель выступает в роли клиента, а получатель - сервера.
4.2 Эмуляция удаленного терминала. Удаленный доступ к ресурсам сети
Telnet - это одна из самых старых информационных технологий Internet. Она входит в число стандартов, которых насчитывается три десятка на полторы тысячи рекомендуемых официальных материалов сети, называемых RFC (Request For Comments).
Под telnet понимают триаду, состоящую из:
· telnet-интерфейса пользователя;
· telnetd-процесса;
· TELNET-протокола.
Эта триада обеспечивает описание и реализацию сетевого терминала для доступа к ресурсам удаленного компьютера.
4.2.1 Протокол Telnet
Telnet как протокол описан в RFC-854 (май, 1983 год). Его авторы J.Postel и J.Reynolds во введении к документу определили назначение telnet так: "Назначение TELNET-протокола - дать общее описание, насколько это только возможно, двунаправленного, восьмибитового взаимодействия, главной целью которого является обеспечение стандартного метода взаимодействия терминального устройства и терминал-ориентированного процесса. При этом этот протокол может быть использован и для организации взаимодействий "терминал-терминал" (связь) и "процесс-процесс" (распределенные вычисления)."
Telnet строится как протокол приложения над транспортным протоколом TCP. В основу telnet положены три фундаментальные идеи:
· концепция сетевого виртуального терминала (Network Virtual Terminal) или NVT;
· принцип договорных опций (согласование параметров взаимодействия);
· симметрия связи "терминал-процесс".
При установке telnet-соединения программа, работающая с реальным терминальным устройством, и процесс обслуживания этой программы используют для обмена информацией спецификацию представления правил функционирования терминального устройства или Сетевой Виртуальный Терминал (Network Virtual Terminal). Для краткости будем обозначать эту спецификацию NVT. NVT - это стандартное описание наиболее широко используемых возможностей реальных физических терминальных устройств. NVT позволяет описать и преобразовать в стандартную форму способы отображения и ввода информации. Терминальная программа ("user") и процесс ("server"), работающий с ней, преобразовывают характеристики физических устройств в спецификацию NVT, что позволяет, с одной стороны, унифицировать характеристики физических устройств, а с другой обеспечить принцип совместимости устройств с разными возможностями. Характеристики диалога диктуются устройством с меньшими возможностями. Если взаимодействие осуществляется по принципу "терминал-терминал" или "процесс-процесс", то "user" - это сторона, инициирующая соединение, а "server" - пассивная сторона.
Принцип договорных опций или команд позволяет согласовать возможности представления информации на терминальных устройствах. NVT - это минимально необходимый набор параметров, который позволяет работать по telnet даже самым допотопным устройствам, реальные современные устройства обладают гораздо большими возможностями представления информации. Принцип договорных команд позволяет использовать эти возможности. Например, NVT является терминалом, который не может использовать функции управления курсором, а реальный терминал, с которого осуществляется работа, умеет это делать. Используя команды договора, терминальная программа предлагает обслуживающему процессу использовать Esc-последовательности для управления выводом информации. Получив такую команду процесс начинает вставлять управляющие последовательности в данные, предназначенные для отображения.
Симметрия взаимодействия по протоколу telnet позволяет в течении одной сессии программе-"user" и программе-"server" меняться местами. Это принципиально отличает взаимодействие в рамках telnet от традиционной схемы "клиент-сервер". Симметрия взаимодействия тесно связана с процессом согласования формы обмена данными между участниками telnet-соединения. Когда речь идет о работе на удаленной машине в режиме терминала, то возможности ввода и отображения информации определяются только конкретным физическим терминалом и договорной процесс сводится к заказу терминальной программой характеристик этого терминала. Гораздо сложнее обстоит дело, когда речь идет об обмене информацией между двумя терминальными программами в режиме "терминал-терминал". В этом случае каждая из сторон может выступать инициатором изменения принципов представления информации и здесь проявляется еще одна особенность протокола telnet. Протокол не использует принцип "запрос-подтверждение", а применяет принцип "прямого действия". Это значит, что если терминальная программа хочет расширить возможности представления информации, то она делает это (например, вставляет в информационный поток Esc-последовательности), если в ответ она получает информацию в новом представлении, то это означает, что попытка удалась, в противном случае происходит возврат к стандарту NVT.
Обычно процесс согласования форм представления информации происходит в начальный момент организации telnet-соединения. Каждый из процессов старается установить максимально возможные параметры сеанса. Однако эти параметры могут быть изменены и позже, в процессе взаимодействия (например, после запуска прикладной программы).
Сетевой виртуальный терминал (NVT). Концепция сетевого виртуального терминала позволяет обеспечить доступ к ресурсам удаленной машины с любого терминального устройства. Под терминальным устройством понимают любую комбинацию физических устройств, позволяющих вводить и отображать информацию. NVT предполагается буферизованным устройством. Это означает, что данные, вводимые с клавиатуры, не посылаются сразу по сети, а собираются в пакеты, которые отправляются либо по мере заполнения буфера, либо по специальной команде. Такая организация NVT призвана с одной стороны минимизировать сетевой трафик, а с другой обеспечить совместимость с реальными буферизованными терминалами.
4.3 Обмен файлами. Служба архивов FTP
FTP-архивы являются одним из основных информационных ресурсов Internet. Фактически, это распределенный депозитарий текстов, программ, фильмов, фотографий, аудио записей и прочей информации, хранящейся в виде файлов на различных компьютерах во всем мире.
4.3.1. Типы информационных ресурсов
Информация в FTP-архивах разделена на три категории:
· Защищенная информация, режим доступа к которой определяется ее владельцами и разрешается по специальному соглашению с потребителем. К этому виду ресурсов относятся коммерческие архивы (например, коммерческие версии программ в архивах ftp.microsoft.com или ftp.bsdi.com), закрытые национальные и международные некоммерческие, частная некоммерческая информация со специальными режимами доступа.
· Информационные ресурсы ограниченного использования, к которым относятся, например, программы класса shareware (Trumpet Winsock, Atis Mail, Netscape, и т.п.). В данный класс могут входить ресурсы ограниченного времени использования
· Свободно распространяемые информационные ресурсы или freeware, если речь идет о программном обеспечении. К этим ресурсам относится все, что можно свободно получить по сети без специальной регистрации. Это может быть документация, программы или что-либо еще.
Стержень технологии составляет FTP-протокол.
3.4.2. Протокол FTP
FTP (File Transfer Protocol или "Протокол Передачи Файлов") - один из старейших протоколов в Internet и входит в его стандарты. Обмен данными в FTP проходит по TCP-каналу. Построен обмен по технологии "клиент-сервер". В FTP соединение инициируется интерпретатором протокола пользователя. Управление обменом осуществляется по каналу управления в стандарте протокола TELNET. Команды FTP генерируются интерпретатором протокола пользователя и передаются на сервер. Ответы сервера отправляются пользователю также по каналу управления. В общем случае пользователь имеет возможность установить контакт с интерпретатором протокола сервера и отличными от интерпретатора пользователя средствами. Команды FTP определяют параметры канала передачи данных и самого процесса передачи. Они также определяют и характер работы с удаленной и локальной файловыми системами.
Сессия управления инициализирует канал передачи данных. При организации канала передачи данных последовательность действий другая, отличная от организации канала управления. В этом случае сервер инициирует обмен данными в соответствии с согласованными в сессии управления параметрами.
Режимы обмена данными
В протоколе большое внимание уделяется различным способам обмена данными между машинами различных архитектур. В общем случае, с точки зрения FTP, обмен может быть поточный или блоковый, с кодировкой в промежуточные форматы или без нее, текстовый или двоичный. При текстовом обмене все данные преобразуются в ASCII и в этом виде передаются по сети.
4.4 Информационно-поисковые системы Internet
Такие имена информационных служб как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и ряд других, хорошо известны пользователям Internet. Без пользования услугами этих систем практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено довольно большое количество статей, основная масса которых приходится на конец 70-х - начало 80-х годов.
4.4.1 Архитектура современных информационно-поисковых систем
Поэтому рассмотрим эту схему:
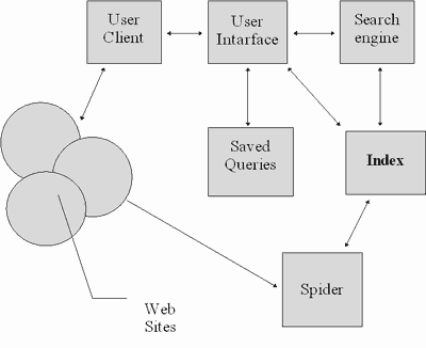
Рис. 3.41. Структура ИПС для Internet (Budi Yuwono, Dik L.Lee. Search and Ranking Algorims for Locating Resources on the World Wide Web)
client - это программа просмотра конкретного информационного ресурса. В настоящее время наиболее популярны мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов World Wide Web, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
user interface - интерфейс пользователя - это не просто программа просмотра. В случае информационно-поисковой системы под этим словосочетанием понимают и способ общения пользователя с поисковым аппаратом системы, т.е. с системой формирования запросов и просмотров результатов поиска.
earch engine - поисковая машина служит для трансляции запроса пользователя, который подготавливается на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
index database - индекс - это основной массив данных информационно-поисковой системы. Он служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
queries - запросы пользователя сохраняются в его личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно хранить запросы, на которые система дает хорошие ответы.
index robot - робот-индексировщик служит для сканирования Internet и поддержки базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
www sites - это весь Internet. А если говорить более точно, то это те информационные ресурсы, просмотр которых обеспечивается программами просмотра.
4.4.2 Информационные ресурсы и их представление в информационно-поисковой системе
Документальным массивом ИПС Internet является все множество документов основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet, статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных. Здесь есть и текстовая информация, и графическая информация, и аудио информация и вообще все, что есть в указанных выше хранилищах. Естественно встает вопрос, как информационно-поисковая система должна со всем этим работать. В традиционных системах есть понятие поискового образа документа - ПОД (Поисковый Образ Документа) - это нечто, что заменяет собой документ и используется при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель, в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл.
Таким образом, первая задача, которою должна решить информационно-поисковая система - это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием.
Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы. Таким образом, все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако, на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
После того, как ресурсы заиндексированы, т.е. система составила массив поисковых образов документов, начинается построение поискового аппарата системы. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД'ов займет много времени, что абсолютно не приемлемо для интерактивной системы, которой является Web. Для того, чтобы можно было быстро находить информацию в базе данных ПОД'ов строится индекс. Индекс в большинстве систем - система связанных между собой файлов, которая нацелена на быстрый поиск данных по запросу пользователя. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов. К этим факторам можно отнести и размер массива поисковых образов, и информационно-поисковый язык системы, и размещения различных компонентов системы и т.п.
Успех информационно-поисковой системы с точки зрения скорости поиска, определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является "секретом фирмы" и гордостью компании.
4.4.3 Информационно-поисковый язык системы
Однако, индекс - это только часть поискового аппарата, причем не видная глазу пользователя. Второй частью этого аппарата является информационно-поисковый язык. ИПЯ позволяет сформулировать запрос к системе в довольно простой и доходчивой форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка. Именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из этого списка удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом запрос типа:
>Software that is used on Unix Platform будет преобразован в: >Unix AND Platform AND Software
что будет означать примерно следующее: "Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно".
4.4.4 Традиционные информационно-поисковые языки и их модификации
Наиболее распространенным ИПЯ является язык, позволяющий составить логические выражения из набора терминов. При этом используются булевые операторы AND, OR, NOT. Такая схема достаточно проста, и поэтому наиболее широко применяется в современных информационно-поисковых системах. Но еще 20 лет тому назад были хорошо известны и ее недостатки.
Булевый поиск плохо масштабирует выдачу. Оператор AND может очень сильно сократить число документов, которые выдаются на запрос. При этом все будет очень сильно зависеть от того, насколько типичными для базы данных являются поисковые термины. Оператор OR напротив может привести к неоправданно широкому запросу, в котором полезная информация затеряется за информационным шумом. Для успешного применения этого ИПЯ следует хорошо знать лексику системы и ее тематическую направленность. Как правило, для системы с таким ИПЯ создаются специальные документально лексические базы данных со сложными словарями, которые называются тезаурусами и содержат информацию о связи терминов словаря друг с другом.
Модификацией булевого поиска является взвешенный булевый поиск. Идея такого поиска достаточно проста. Считается, что термин описывает содержание документа с какой-то точностью, и эту точность выражают в виде веса термина. При этом взвешивать можно как термины документа, так и термины запроса. Запрос может формулироваться на ИПЯ, описанном выше, но выдача документов при этом будет ранжироваться в зависимости от степени близости запроса и документа. При этом измерение близости строится таким образом, чтобы обычный булевый поиск был бы частным случаем взвешенного булевого поиска.
Языки типа "Like this". При внимательном рассмотрении взвешенного поиска закрадывается естественное желание вообще обойтись без логических коннекторов и измерять близость документа и запроса какими-либо другими критериями. Наиболее простой моделью этого типа является линейная модель индексирования и поиска, когда близость документа и запроса рассматривается как угол между ними. В этом случае высчитывается sin угла, который получают как скалярное произведение двух векторов. В соответствии со значением меры близости происходит ранжирование документов при выдаче ссылок на них пользователю.
Поиск в нечетких множествах. При этом типе поиска весь массив документов описывается как набор нечетких множеств терминов. Каждый термин определяет некую монотонную функцию принадлежности документам документального массива. Когда запрашивается AND, то это интерпретируется как минимум из двух функций, соответствующих терминам запросов, OR - как максимум, NOT - как 1-<значение функции>. В соответствии с полученными значениями результат поиска также ранжируется, как и в случае с поиском по мерам близости.
Следует сразу сказать, что этот метод поиска используется только в исследовательских системах и распространен крайне ограничено.
Пороговые модели. Как было видно из предыдущего изложения, на конечном этапе поиска выборка найденных документов ранжируется. поиск в нечетких множествах приводит к ранжированию всего массива документов в базе данных. Современные информационно-поисковые системы Internet имеют базы данных только индексов, занимающие террабайты. Ранжировать целиком такие массивы - это просто безумная затея. Поэтому применяются пороговые модели, которые задают пороговые значения для документов, выдаваемых пользователю.
Кластерная модель и Вероятностная модель информационного поиска. В кластерной модели может использоваться два подхода. Первый заключается в том, что массив заранее разбивается на подмножества документов и при поиске высчитывается близость запроса некоторому подмножеству.
При вероятностной модели вычисляется вероятность принадлежности документа классу релевантных запросу документов. При этом используется вероятность принадлежности терминов запроса каждому из документов базы данных.
Коррекция запроса по релевантности. Многие системы применяют механизм коррекции запроса по релевантности. Это означает, что процедура поиска носит интерактивный и итеративный характер. После проведения первичного поиска пользователь отмечает из всего списка найденных документов релевантные. На следующие итерации система расширяет/уточняет запрос пользователя терминами из этих документов и снова выполняет поиск. Так продолжается до тех пор пока пользователь не сочтет, что лучшего результата, чем он уже имеет добиться не удастся. Коррекция запроса по релевантности - это достаточно широко внедренный способ уточнения запросов.
3.6.6. Информационно-поисковые языки Internet
При описании и классификации информационно-поисковых систем ставилась задача проанализировать наиболее популярные и наиболее типичные системы, которыми пользуются в Сети.
Lycos
Как и большинство систем, Lycos дает возможность использовать простой запрос и более изощренный метод поиска. В простом запросе в качестве поискового критерия вводится предложение на естественном языке. Lycos производит нормализацию запроса, удаляя из него так называемые stop-слова, и только после этого приступает к его выполнению. Почти сразу выдается информация о числе документов на каждое слово, а уже позже и список ссылок на формально релевантные документы. В списке напротив каждого документа указывается его мера близости запросу, число слов из запроса, которые попали в документ и оценочная мера близости, которая может быть больше или меньше формально вычисленной. На апрель 1996 года в Lycos не был реализован булевый поиск, такие планы были анонсированы. Последнее предложение подразумевает только то, что нельзя вводить эти операторы в строке вместе с терминами, но использовать логику через систему меню Lycos позволяет. Последнее относится к расширенной форме запроса, который предназначен для использования искушенными пользователями системы, которые уже научились пользоваться этим механизмом.
Таким образом мы видим, что Lycos относится к системе с языком запросов типа "Like this", но предполагается его расширения и на другие способы организации поисковых предписаний.
AltaVista
Наиболее интересным с точки зрения информационно-поискового языка в AltaVista является возможность расширенного поиска. Здесь стоит сразу выделить, что в отличии от многих систем AltaVista поддерживает одноместный оператор NOT. Кроме этого есть еще и оператор NEAR, который реализует возможность контекстного поиска, когда термины должны располагаться рядом в тексте документа. AltaVista разрешает поиск по ключевым фразам, при этом она имеет довольно большой словарь этих фраз. Кроме всего прочего, при поиске в АltaVista можно задать имя поля где должно встретиться слово. Это может быть гипертекстовая ссылка, applet, название образа, заголовок и ряд других полей. К сожалению, подробно процедура ранжирования в документации по системе не описана, но сказано, что ранжирование применяется как при простом поиске, так и при расширенном запросе.
Реально эту систему можно отнести к системе с расширенным булевым поиском.
Yahoo
Данная система появилась в сети одной из первых, и поэтому говорить будем о сегодняшнем состоянии Yahoo, а не о состоянии годовой давности. В настоящее время Yahoo сотрудничает со многими производителями средств информационного поиска и на различных ее серверах используется различное программное обеспечение. На мой взгляд, это самая незатейливая информационная служба, которая сосредоточилась на информации о Web как таковой. ИПЯ Yahoo достаточно прост: все слова следует вводить через пробел и они соединяются либо AND, либо OR. При выдаче не выдается степени соответствия документа запросу, а только подчеркиваются слова из запроса, которые встретились в документе. При этом не производится нормализация лексики и не проводится анализ на "общие" слова. Хорошие результаты поиска получаются только тогда, когда пользователь знает, что информация в базе данных Yahoo точно есть. Ранжирование производится по числу терминов запроса в документе.
Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска.
OpenText
Информационная система OpenText представляет из себя самый коммерциализированный информационный продукт в сети. Все описания больше напоминают рекламу, чем реальное руководство по работе. Система позволяет провести поиск с использованием логических коннекторов, размер запроса ограничен тремя терминами или фразами. В данном случае речь идет о расширенном поиске. При выдаче результатов поиска сообщается степень соответствия документа запросу и размер документа. Система позволяет также улучшить результаты поиска в стиле традиционного булевого поиска.
OpenText можно было бы отнести без сомнения к разряду традиционных информационно-поисковых систем, если бы не механизм ранжирования.
InfoSeek
Система InfoSeek обладает довольно развитым информационно-поисковым языком, который позволяет не просто указывать какие термины должны встречаться в документах, но и своеобразно взвешивать их. Достигается это при помощи специальных знаков "+" - термин обязан быть в документе, "-" - термин обязан отсутствовать в документе. Кроме этого InfoSeek позволяет проводит то, что называется контекстным поиском. Это значит, что используя специальную форму запроса можно потребовать последовательной совместной встречаемости слов. Кроме этого можно указать, что некоторые слова должны совместно встречаться не только в одном документе, а даже в отдельном параграфе или заголовке. Есть возможность и указания ключевых фраз. Ключевая фраза от последовательной встречаемости отличается тем, что фраза всегда ищется как единое целое, а при последовательной встречаемости слова могут стоять рядом, но в произвольном порядке. Ранжирование при выдаче осуществляется по числу терминов запроса в документе, по числу фраз запроса в документе, за вычетом общих слов. Все эти факторы используются как вложенные процедуры.
Подводя краткое резюме можно сказать, что InfoSeek относится к традиционным системам с элементом взвешивания терминов при поиске.
WAIS
WAIS является одной из наиболее изощренных поисковых систем Internet. В отличии от многих поисковых машин, ИПЯ системы позволяет строить не только вложенные булевые запросы, считать формальную релевантность по различным мерам близости, взвешивать термины запроса и документа, но и осуществлять коррекцию запроса по релевантности. Система также позволяет использовать усечение терминов, разбиение документов на поля и ведение распределенных индексов. Не случайно именно эта система была выбрана в качестве основной поисковой машины для реализации энциклопедии "Британика" на Internet.
Применение языков на практике
Рассмотрим теперь небольшой сравнительный пример использования описанных выше поисковых машин. В качестве запроса использовалась фраза:
"Best on the Web"
Подразумевалось, что следует найти документ, связанный с конкурсами "Лучший на Сети". Понятно, что уже в самом запросе есть определенная некорректность, но тем интереснее посмотреть, как с ней справились различные системы. Эта фраза задавалась в качестве набора слов и при этом получались следующие результаты.
AltaVista - после нормализации лексики от запроса осталось только Best. Естественно, что при этом качество поиска было отвратительным. Однако, использование поиска по фразе как по единому целому, поставило требуемый документ на первое место в списке найденных.
Lycos - здесь отсеялись "on the" и документ был указан только в конце списка. Поиск по фразе улучшения результатов не дал.
InfoSeek - при расширенном поиске нужный документ был найден третьим в списке из десяти документов. Уточнение поиска привело только к миграции документа вглубь списка.
OpenText - документ занимает пятую строчку в списке из десяти документов. Как и в случае с InfoSeek уточнение запроса результатов не дало.
Yahoo - документ попал в список найденных и занял третье место (ошибка в запросе: вместо "on the" следовало указывать "of the"). Но здесь следует заметить, что основное место хранения этого документа база данных Yahoo, т.е. запрос точно совпадает с тематикой базы данных.
Следует заметить, что приведенный пример не стоит рассматривать как реальную оценку возможностей описанных выше систем. Это просто иллюстрация, которая поможет провести свой собственный выбор наиболее подходящего средства поиска.
В завершении хотелось бы обратить внимание читателей еще на один аспект выбора информационно-поисковой системы. Это профиль ее баз данных. Можно возразить, что все системы индексируют одно и тоже - массив документов Internet. Однако делают они это по-разному. Очень важен профиль системы, который задается разбиением документов по темам и словарем индексирования, а также способом его поддержания. Определенным ориентиром здесь могут служить виртуальные библиотеки. Но об этом в следующий раз.
Вместе с этой лекцией читают "Лекция 4".
3.6.7. Интерфейс системы
Важным фактором является вид представления информации в программе-интерфейсе. При этом различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню-ориентированный подход, либо командную строку. Меню-ориентированный подход позволяет ввести список терминов, обычно через пробел, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На нашей схеме (рисунок 3.41) есть так называемые сохраненные запросы пользователя. В большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один тип использования сохраненных запросов. В традиционных системах это называется расширением или уточнением запроса, в зависимости от того, что получаем в результате преобразования запроса: увеличение размера выборки или ее сокращение. При этом традиционная система хранит не запрос как таковой, а результат поиска, т.е. список идентификаторов документов, который объединяется/пересекается со списком полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в World Wide Web не практикуется. Вызвано это особенностью протоколов взаимодействия программы-клиента и сервера системы, которые не поддерживают сеансовый режим работы.
Как стало уже понятно из выше изложенного, результат поиска в базе данных ИПС - это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых системах выдается только список ссылок, а в таких системах как Lycos, AltaVista, Yahoo кроме ссылок дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого система сообщает на сколько найденный документ соответствует запросу. В Yahoo, например, сообщается сколько терминов запроса содержится в поисковом образе документа и в соответствии с этим ранжируется результат поиска. В Lycos выдается мера соответствия документа запросу и ранжирование производится по этому параметру. Обычно пользователь имеет возможность уточнить запрос.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности[7]. Релевантность - это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Формальная - это та, что вычисляет система и на основании чего ранжируется выборка найденных документов. Реальная - это та, как сам пользователь оценивает найденные документы. Некоторые системы имеют для этого специальное поле[6], где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа. И выдача снова ранжируется. Так происходит до тех пор, пока результат не стабилизируется. Это означает, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http://host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают и система не индексирует. Если с http-ссылками все более или менее понятно, то ссылки WAIS - это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы. Это значит, что одна ИПС, например, Lycos строит поисковый аппарат над поисковым аппаратом другой системы - WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, т.е. разбить их на поля, и хранить документы как один файл. индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения. В этом случае программа просмотра ресурсов Internet должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.



















