Лабораторные 101-104 (942787), страница 2
Текст из файла (страница 2)

Рис. 1.1. Кодовое дерево
Отметим в заключение особенности систем эффективного кодирования.
Одна из особенностей обусловлена различием в длине кодовых комбинаций для разных букв. Если буквы выдаются через равные промежутки времени, то кодирующее устройство через равные промежутки времени выдает комбинации различной длины. Поскольку линия связи используется эффективно только в том случае, когда символы поступают в нее с постоянной скоростью, то на выходе кодирующего устройства должно быть предусмотрено буферное устройство ("упругая" задержка). Оно запасает символы по мере их поступления и выдает их в линию связи с постоянной скоростью. Аналогичное устройство необходимо и на приемной стороне.
Вторая особенность связана с возникновением задержки в передаче информации. Наибольший эффект достигается при кодировании длинными блоками, а это приводит к необходимости накапливать буквы, прежде чем сопоставить им определенную последовательность символов. При декодировании задержка возникает снова. Общее время задержки может быть велико, особенно при появлении блока, вероятность которого мала. Это следует учитывать при выборе длины кодируемого блока.
Еще одна особенность заключается в специфическом влиянии помех на достоверность приема. Одиночная ошибка может перевести передаваемую кодовую комбинацию в другую, не равную ей по длительности. Это повлечет за собой неправильное декодирование целого ряда последующих комбинаций, который называют треком ошибки. Специальными методами построения эффективного кода трек ошибки стараются свести к минимуму.
1.2. Программные и технические средства реализации
Лабораторная работа выполняется на ПЭВМ, подключенных к локальной сети кафедры. При проведении занятий на кафедре ВМСС необходимо при помощи определенных команд войти в кафедральную сеть. Затем запустить на выполнение программу effect.exe, состоящую из трёх частей. В первой части строится кодирующее устройство по методу Шеннона-Фено, во второй – по методу Хаффмена. Третья часть представляет собой пример построения дерева Хаффмена. Для случая, когда корреляционные связи между буквами отсутствуют и имеется возможность управлять моментами считывания информации с источника.
1.3. Описание программного обеспечения и технической
реализации эффективных кодов
Управление программой осуществляется через главное меню. Работу рекомендуется начать со сборки кодирующего устройства – кодера (рис.1.2).

Рис. 1.2. Пример схемы кодирующего устройства для
технической реализации эффективных кодов
Устройство включает схему поучения моментов считывания очередной буквы (матричный шифратор 1 с регистром сдвига 1) и шифратор букв (матричный шифратор 2 с регистром сдвига 2). Число горизонтальных шин шифраторов равно числу кодируемых букв, а число вертикальных шин в каждом из них равно числу символов в самой длинной комбинации используемого кода. Схема рассчитана на использование алфавита из 8 букв (сообщений). Источник информации удовлетворяет требованиям идеального источника по Хартли, т.е. в каждый данный момент он возбуждает шину только одной буквы, выставляя на нее сигнал "1". В регистре 1 появляется сигнал "1" в разряде соответствующем длине кодовой комбинации буквы, что обеспечивается диодным переходом. В регистре 2 появляется код соответствующий букве, шина которой возбуждена. Что тоже обеспечивается соответствующими диодными переходами с возбужденной шины на триггеры регистра 2. Сдвигающими импульсами код буквы последовательно выталкивается в канал связи, а единица "вытолкнутая" из регистра 1 разрешает источнику выдать очередную букву.
При выполнении домашней подготовки студент должен построить эффективный код, используя методики Шеннона - Фено и Хаффмена. В первой части лабораторной работы применяется кодирование по Шеннону - Фено. На экране представлена заготовка схемы кодера. Необходимо правильно расставить диоды шифраторов. Текущее соединение отображается красной пунктирной линией, которую можно перемещать клавишами управления курсором. Фиксируется соединение клавишами <Пробел> или <ENTER>. В случае ошибки снять соединения можно с помощью все тех же клавиш.
Закончив сборку схемы, нажмите <ESC>. Протестируйте схему для каждой буквы. Исправьте допущенные ошибки.
Сборка декодирующего устройства – декодера производится аналогично сборке кодера рис 1.3.
Информация поступает из канала связи в приемный регистр 3. Регистр 3 состоит из триггеров, количество которых на один больше, чем самая длинная кодовая комбинация одной из букв алфавита. В начальном состоянии в регистре 3 в триггере T6 записана “1”. Перемещаясь по регистру сдвигающими импульсами по мере приема информации из линии связи, она информирует о приеме очередной буквы. Когда кодовая комбинация буквы разместится в регистре 3 полностью, в этот момент должна схема совпадения “И”, соответствующая принятой букве.
Для этого на все входы схемы "И" этой буквы должны быть поданы сигналы "1" через диоды подключеные к триггерам регистра 3, состояния которых соответствуют кодовой комбинации принятой буквы. Если триггер находится в состоянии "1", то диод подключается к правому или единичному выходу, а если в состоянии "0", то к левому или нулевому выходу. Срабатывание схемы "И" принятой буквы индицирует ее и через схему “ИЛИ” сбрасывает в ноль все разряды регистра 3, кроме первого, в котором снова выставляется "1". После этого схема декодера готова к приему очередной буквы.
После завершения сборки производится тестирование декодера для каждой буквы.
После проверки работы кодера и декодера в отдельности проверим их совместную работу. В начале предлагается выбрать последовательность кодируемых букв. Это осуществляется с помощью клавиш управления курсором и <ENTER>. Ошибки исправляются через <ESC>. Выбрав нужную последовательность, переведите курсор на <кодировать>. Схема кодера работает потактно. Причем процессы кодирования и передачи сигналов разделены, что позволяет четко проследить прохождение каждого сигнала по схеме. Переданные сигналы высвечиваются темно-зеленым цветом, полученные – ярко-зеленым. Номер такта отображается в правом верхнем углу. Закодированная последовательность выходит из схемы в "перевернутом" виде (справа-налево). Для выполнения схемой следующего такта нажмите любую клавишу.
После того, как будут закодированы все заданные буквы, для продолжения процесса передачи букв также нажмите любую клавишу.
Затем производим проверку работы декодера. Управление схемой декодирования аналогично управлению схемой кодирования. После завершения процесса декодирования проверьте соответствие закодированных и декодированных букв. Далее рекомендуется запустить декодер с изменением в одном разряде и выяснить как это отразится на декодировании.
регистр 3
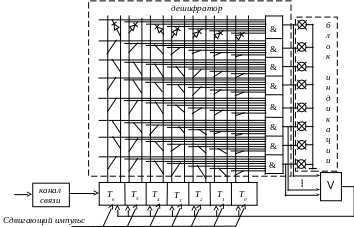
Рис. 1.3. Пример декодирующего устройства для
технической реализации эффективных кодов
С помощью главного меню можно получить информацию о способах эффективного кодирования и как работать с данной программой.
Во второй части лабораторной работы применяется кодирование по Хаффмену. Порядок действий аналогичен выполнению первой части лабораторной работы.
Заключительной частью лабораторной работы является построение дерева Хаффмена для кодирования небольшого текста. Эта часть является чисто демонстрационной. В ней шаг за шагом рассматривается процесс кодирования и построения дерева Хаффмена.
В окно с надписью "Текст для кодирования" вводится подготовленный текст. Во всех случаях для продолжения работы нажимается F10, для возврата назад – F9, подсказка – F1. Рядом в окне показывается частота появления букв в тексте. Для удобства можно передвигаться по тексту и выбрав любую букву клавишей <ENTER>, наглядно посмотреть эту букву в тексте. Она будет выделена другим цветом.
На следующем этапе строится дерево Хаффмена. Дерево расшифровывается следующим образом. Красный прямоугольник – узел дерева, соответствующий букве. В нижней половине прямоугольника выводится сама буква, а в верхней – количество вхождений этой буквы в текст. Серые узлы дерева – узлы, которые получились в процессе свертки. Число внутри такого узла показывает общую сумму вхождений. Каждому ребру дерева присваивается “0” или “1”. Чтобы определить код конкретной буквы, входящей в текст, необходимо пройти путь от начала дерева до этой буквы в его конце, накапливая символы (“0” или “1”) при перемещении по ребрам дерева.
ЗАДАНИЕ
Выполняется при домашней подготовке
1. Изучить описание и рекомендованную литературу, изучить методы построения и технической реализации эффективных кодов.
2. По конкретным значениям вероятностей встречаемости букв, заданных студенту преподавателем или выбранно самостоятельно (отличающихся от рассмотренного в описании, не более 8 букв и нетривиальный случай), построить эффективный код, используя методики Шеннона-Фено и Хаффмена.
3. Вычислить энтропию источника и среднюю длину комбинации полученного кода.
4. Подготовить небольшой текст на 150–200 букв для построения дерева кодирования демонстрационной программой.
Выполняется в лаборатории
1. Используя построенный код по методу Шеннона-Фено и Хаффмена правильно расставить диоды в схемах кодирующего и декодирующего устройства.
2. Проверить работоспособность системы передачи.
3. Ввести текст для построения дерева кодирования.
-
Зарисовать таблицу и дерево Хаффмена.
-
Подсчитать выигрыш от записи текста эффективным кодом.
Требования к отчету
Отчет должен включать:
-
таблицу построения эффективного кода по методике Шеннона-Фено;
-
схемы шифратора и дешифратора для построенного кода;
-
таблицу и кодовое дерево, иллюстрирующие построение эффективного кода по методике Хаффмена.
-
Результаты расчетов энтропии источника и среднюю длину кода для буквы, отдельно для заданного Вами алфавита из 8 букв и текста.
Контрольные вопросы
-
Когда целесообразно использовать эффективное кодирование?
-
Каковы сложности в реализации систем передачи с применением эффективных кодов?
3. До какого предела может быть сокращена средняя длина кодовой комбинации?
4. Каковы преимущества методики Хаффмена?
-
Какой код называется префиксным?
-
Как учесть взаимосвязь букв в тексте ? Что произойдет с энтропией, если учесть взаимосвязь букв ?
ЛИТЕРАТУРА
-
Дмитриев В.И. Прикладная теория информации. – M.: Высш. шк., 1989. – 320 с. (С. 184–196).
-
Темников Ф.Е., Афонин В.А., Дмитриев В.И. Теоретические основы информационной техники. М.: Энергия, 1979.– 512с. (С. 119-131).
Лабораторная работа N 102
ПОСТРОЕНИЕ И РЕАЛИЗАЦИЯ ГРУППОВЫХ КОДОВ
Целью работы является усвоение принципов построения и технической реализации кодирующих и декодирующих устройств групповых корректирующих кодов.
2 Указания к построению кодов
2.1. Определение числа избыточных символов
Групповой код относится к блоковым кодам, в которых формируемая кодовая комбинация содержит n разрядов, из которых k–информационных и m– проверочных (m=n-k). Взаимосвязь между блоками отсутствует , то есть передача и исправление ошибок в разных блоках происходят независимо друг от друга. Математической основой группового кода является теория групп (отсюда и название кода) [1]. В качестве основной операции в групповых кодах используется операция сложения по модулю два.
Построение конкретного корректирующего кода производится исходя из числа передаваемых букв (команд) или дискретных значений измеряемой величины, то есть алфавита из N элементов и статистических данных о наиболее вероятных векторах ошибок в используемом канале связи. Вектором ошибки будем называть кодовую комбинацию, имеющую единицу в разрядах, подвергающихся искажению, и нули во всех остальных разрядах. Любую искаженную кодовую комбинацию можно рассматривать теперь как сумму по модулю два разрешенной кодовой комбинации и вектора ошибки.
Будем рассматривать как независимые ошибки, так и пачки ошибок. Независимые ошибки, это когда по одной из них ничего нельзя сказать о других. В пачках ошибки расположены рядом. Длиной пачки ошибки называется дистанция между первым и последним искаженным символом. Внутри пачки могут оказаться и неискаженные символы.
Исходя из неравенства ![]() , определяем число информационных разрядов k, необходимое для передачи заданного числа команд обычным двоичным кодом.
, определяем число информационных разрядов k, необходимое для передачи заданного числа команд обычным двоичным кодом.
Каждой из ![]() ненулевых комбинаций К-разрядного кода нам необходимо поставить в соответствие комбинацию из n разрядов. Значения символов в n–к проверочных разрядах такой комбинации устанавливаются в результате суммирования по модулю два значений символов в определенных информационных разрядах.
ненулевых комбинаций К-разрядного кода нам необходимо поставить в соответствие комбинацию из n разрядов. Значения символов в n–к проверочных разрядах такой комбинации устанавливаются в результате суммирования по модулю два значений символов в определенных информационных разрядах.
















