Отчёт_неявная_схема (1185589)
Текст из файла
Отчёт по практической задаче №2 ( неявная схема ).
В рамках курса «Параллельные методы решения задач».
Выполнил: Волков Н. И. , академическая группа 523/1
-
Постановка задачи.
Производится численное решение двумерного нестационарного неоднородного уравнения теплопроводности в прямоугольной области ( в некотором материале ).
Такой перенос тепла описывается уравнением следующего вида
![]()
где T – температура, зависит от x, y, t; Q – функция, характеризующая дополнительные источники тепловыделения, зависит в общем случае от x, y, t, T. X, Y – декартовы координаты, t – время. ρ, с, λ – параметры, характеризующие «материал» области, в которой рассматривается уравнение теплопроводности. При решении задаётся размер сетки и количество шагов по времени. При этом сам размер поля остаётся неизменным.
-
Описание метода решения и способа декомпозиции области.
Для численного решения уравнения область равномерно разбивается между процессами ( сетка подбирается таким образом, чтобы обеспечить точное разбиение ). Каждому процессу в итоге соответствует некоторый прямоугольник из заданной области, определяемый по координатам процесса в двумерной MPI решетке. Это допустимо, поскольку вычислительная сложность каждой ячейки сетки условно одинакова ( в том смысле, что каждая ячейка сетки подлежит расчёту по одному и тому же алгоритму ).
В процессе решения задачи используемые узлы формируют двумерную MPI решетку. Расчёт новых значений температуры на каждом шаге по времени производится в два этапа. На первом этапе каждый процесс построчно рассматривает свою расчётную область. Тепловой поток в направлении оси Y представляется в неявной форме ( в момент времени t(i + 1) ), тепловой поток в направлении оси X игнорируется. На втором полушаге всё происходит наоборот. При этом функция дополнительных источников тепла в обоих полушагах берется для момента времени t(i + ½), что заложено в код программы. Таким образом, получается две разностные схемы вида.
![]()
![]()
В первой из них неявной частью является та, что соответствует Φ, во второй — та, что соответствует Ω.
-
Описание модели поведения материала и точного решения.
Для проведения тестов и верификации в качестве начального значения температуры берется функция sinx + siny. При этом размер рассматриваемой области берется кратным 2*π. Тогда на границах области начальная температура равна, соответственно sinx или siny. Дополнительные источники тепла функционируют одинаково во всей области по закону f = p * cos( t / q ), то есть каждая точка области попеременно нагревается и охлаждается в определенной степени. В программу можно встроить и иные параметры. Например, если постановить f = 0 в любой момент времени в любой точке области, то будет известно точное решение![]() , при условии, что граничные условия выражаются функциями
, при условии, что граничные условия выражаются функциями ![]() и
и ![]() в каждый момент времени. Это свойство будет применено в дальнейшем для верификации программы.
в каждый момент времени. Это свойство будет применено в дальнейшем для верификации программы.
-
Описание используемой вычислительной системы.
Расчёты проводились на вычислительной системе IBM Blue Gene/P, установленной в суперкомпьютерном комплексе МГУ. Основные её свойства следующие:
-
2048 вычислительных узлов.
-
2048 процессоров ( 1 процессор на узел ).
-
8192 ядра ( 4 ядра на процессор ).
-
интерконнект для операций точка-точка — имеет топологию трехмерного тора, пропускная способность одного соединения — 450 MB/s. Латентность - 0.1μс для пакета в 32 байта, 0.8μс для пакета в 256 байта, до ближайшего соседа.
-
интерконнект для глобальных операций — по 3 соединения между каждым узлом и I/O картой ( 1 карта на 128 узлов ); пропускная способность одного соединения — 850 MB/s. Латентность - 3.0μс (полный обход ).

Рис 1: Первый вариант расчёта
Более подробные характеристики этой системы можно найти по адресу http://hpc.cmc.msu.ru/bgp . Для расчётов использовалось 256 узлов, т. е. 1024 ядра, а также 64 узла ( 256 ядер ). Поскольку необходимо сравнивать эффективность параллельной программы с эффективностью последовательной, пришлось использовать сетки небольших размеров: 1024 * 1024, 2048 * 2048, 4096 * 4096 итп, чтобы последовательной программе хватило памяти на узле для оперирования всей расчётной сеткой, а также, чтобы хватило лимита времени для возможных тестов с большим числом шагов по времени.
-
Верификация программы, сходимость, проверка корректности вычислений.
Как уже было сказано, установка функции генерации тепла в тестовый режим принципиально не влияет на вычисления ( изменяются только значения конкретного числового коэффициента F ). Проверка корректности вычислений производится в 2 этапа. Сначала показывается корректность последовательной версии алгоритма. Затем показывается соответствие результатов работы последовательной и параллельной версий алгоритма. Примечание: для верификации использовались области малого размера, иначе бы долго работал верификатор ( это простая утилита, не предназначенная для запуска на кластерной вычислительной системе ).

Рис 2: Второй вариант расчёта

Рис 3: Отклонение от точного решения в зависимости от размера сетки на 100-ом шаге. Шкала логарифмическая.

Рис 4: Время работы алгоритма без openmp на 1 узле, на 64 узлах, на 256 узлах
Применяется два варианта расчётной сетки. Их суть изложена на Рис. 1 и Рис. 2 выше. Левый и правый столбцы, верхняя и нижняя строки соответствуют границе исследуемой области. Зеленый прямоугольник — область, для которой производится непосредственный расчёт ( на изображениях параметр размера расчётной сетки в первом случае равен 4, во втором — 2 ). Все остальные прямоугольники обозначают области, значения в которых рассматриваются как граничные условия. Полностью корректной является первая схема, однако вторая обладает интересными свойствами погрешности. Для проверки корректности достаточно взять значения в конкретных точках с конкретного шага по времени и сравнить их со значением точного решения при тех же параметрах. Коэффициенты ρ, с, λ, смысл которых заключается в физических характеристиках материала, в котором рассматривается теплопроводность, приравниваются к единице для более простой верификации. На Рис. 3 изображено отклонение от точного решения на 100-ом шаге по времени ( параметр t = 0.01, то есть рассматривается момент времени 1.0 ) согласно результатам работы верификатора на сетках размера 128, 256, 384, 512, 640, 768, 1024, для первого и второго варианта расчётов. Погрешность вычисляется как среднее отклонение вычисленного решения от истинного значения в данной точке. Эти значения также совпадают с точностью до машинного нуля для последовательной и параллельной версий алгоритма. Поэтому соответствующий график интереса не представляет и не приводится. Интересный вывод заключается в том, что хотя погрешность 1 варианта уменьшается со сгущением сетки и уже на сетке 2048 * 2048 должна быть, по крайней мере, сопоставима с погрешностью второго варианта ( которая почти не зависит от размера сетки ), второй вариант обеспечивает хорошую точность на сетках малого размера. В дальнейших расчётах, однако, используется первый вариант.
-
Графики времени решения, эффективности распараллеливания итп.
К сожалению, последовательное решение на Blue Gene / P при более-менее значительных размерах сеток выполняется долго, вплоть до выхода за лимит времени. Поэтому последовательный алгоритм запускается для малого числа шагов по времени, а параллельный алгоритм — для большего числа шагов по времени. В качестве основной меры времени выполнения, эффективности итп. программы используется среднее время выполнения одного шага, получаемое простым арифметическим делением общего времени выполнения на количество
Рис 5: Ускорение алгоритма без openmp на 64 узлах, на 256 узлах по сравнению с 1 узлом

Рис 6: Эффективность алгоритма без openmp на 64 и 256 узлах
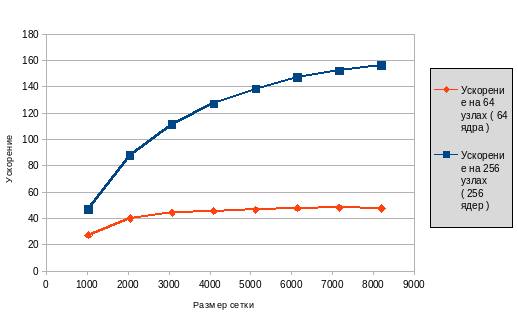
шагов. Этот параметр рассматривается для квадратных сеток со стороной 1024, 2048, 3072, 4096, 5120, 6144, 7168, 8192. Во всех случаях рассматривается область одного размера ( 2 * π ), то есть для все сеток шаг по х одинаков с шагом по y и равен ( 2 * π ) / ( data_size – 1 ). Шаг по времени во всех случаях равен 0.01. В каждом случае на Рис. 4 приведено среднее время выполнения одного шага для последовательного алгоритма на 1 узле, параллельного алгоритма на 64 узлах, параллельного алгоритма на 256 узлах. На Рис. 5 показано ускорение на 64 узлах и на 256 узлах по сравнению с последовательным алгоритмом. Критерий сравнения не меняется, использованные размеры сетки также не меняются. На Рис. 6 указана эффективность алгоритма согласно определению эффективности ( ускорение / число используемых узлов ). Нужно помнить о том, что рассматриваемый алгоритм включает в себя параллельную блочную прогонку, эффективность которой не может превышать 50%.

Рис 7: Сравнение времени работы программы с использованием openmp и без него

Рис 8: Ускорение алгоритма c openmp на 64, 256 узлах в сравнении с 1 узлом

Рис 9: Эффективность алгоритма c openmp на 64, 256 узлах
Параллельный алгоритм включает в себя использование openmp. Openmp используется следующим образом: Функция выполнения шага по времени имеет следующую структуру (outer_cycle_1 (inner_1_1) (inner_1_2) (INTERACT) (inner_1_3) )(outer_cycle_1 (inner_1_1) (inner_1_2) (INTERACT) (inner_1_3) ). Здесь каждый из внешних циклов обеспечивает обработку всей области, за которую отвечает процесс. Их два, поскольку каждый шаг по времени предполагает выполнение двух полушагов. Во внешних циклах использование openmp проблематично, поскольку их внутренняя структура включает в себя взаимодействие узлов. Первый внутренний цикл обеспечивает первоначальный расчёт коэффициентов и построение СЛАУ. В нём можно свободно использовать openmp. Второй внутренний цикл выполняет прямой ход метода прогонки в локальной области. Здесь НЕЛЬЗЯ использовать openmp ( например, для организации встречной прогонки ), поскольку мы можем выполнить только
прямой ход. Группа функций INTERACT отвечает за взаимодействие процессов ( пересылку нижних строк матрицы. Здесь также нельзя использовать openmp. Однако openmp нужно и можно использовать для организации метода встречной прогонки в «главном» процессе каждого столбца на первом этапе и каждой строки на втором этапе, когда происходит решение трехдиагональной СЛАУ для матрицы из последних строк; что и делается.
Наконец, третий внутренний цикл представляет собой модифицированный обратный ход метода прогонки и также может выполняться лишь последовательно. На Рис. 7 приведено соотношение времени работы программы c использованием openmp ( версия, использованная во всех остальных тестах ) и программы, откуда использование openmp было удалено. Для последовательной версии алгоритма данные не приводятся, т. к. последовательная версия алгоритма не использует openmp по определению. На Рис. 8 и Рис. 9, однако, приводятся графики ускорения алгоритма без openmp на 64, 256 узлах по сравнению с последовательным вариантом ( Для сеток больших размеров, которые не были рассчитаны последовательным алгоритмов, используется линейная интерполяция для установления возможного времени вычисления последовательным алгоритмов. Сетки такого размера в умещаются в оперативную память ) а также их эффективность относительно пиковой производительности системы.
-
Анализ результатов и заключение.
Необходимо вкратце описать свойства реализованного алгоритма. Во-первых, часть с построением СЛАУ может выполняться одновременно и параллельно на всех узлах в процессе выполнения каждого шага по времени. Во-вторых, каждый узел при расчете очередного шага по времени производит пересылку 2 * (local_length + local_width) данных и принимает столько же посредством MPI. Между независимыми узлами пересылки также могут выполняться параллельно. Наконец, использован модифицированный вариант алгоритма блочной прогонки, в котором на обратном проходе зануляются наддиагональные элементы строк собственной полосы матрицы, начиная с предпоследней + последней строки с предыдущей полосы. Ускорение этого алгоритма составляет примерно ![]() , где p – число блоков, n – число строк матрицы. Для систем с общей памятью n >> p, то есть ускорение должно быть близким к p / 2. Из этого можно сделать вывод о достаточно высокой эффективности представленной реализации алгоритма, т. к. на при достаточно большом размере сетки на p процессах он ускоряется приблизительно в p / 2 раз по сравнению с последовательным вариантом. Фактическое значение ускорение по всему алгоритму превосходит p / 2 по нескольким причинам. Во-первых, один шаг по времени включает не только алгоритм блочной прогонки, и некоторые из операций ( например, формирование СЛАУ ) ускоряются именно в p раз. Во-вторых, планировщик задач Blue Gene / P не позволяет запускать на моём аккаунте задачи менее чем на 16 узлов. Отсюда могут происходить некоторые накладные расходы в последовательном алгоритме.
, где p – число блоков, n – число строк матрицы. Для систем с общей памятью n >> p, то есть ускорение должно быть близким к p / 2. Из этого можно сделать вывод о достаточно высокой эффективности представленной реализации алгоритма, т. к. на при достаточно большом размере сетки на p процессах он ускоряется приблизительно в p / 2 раз по сравнению с последовательным вариантом. Фактическое значение ускорение по всему алгоритму превосходит p / 2 по нескольким причинам. Во-первых, один шаг по времени включает не только алгоритм блочной прогонки, и некоторые из операций ( например, формирование СЛАУ ) ускоряются именно в p раз. Во-вторых, планировщик задач Blue Gene / P не позволяет запускать на моём аккаунте задачи менее чем на 16 узлов. Отсюда могут происходить некоторые накладные расходы в последовательном алгоритме.
Если говорить более конкретно, то на обработку одного столбца на одном шаге по времени уходит ~N операций на формирование СЛАУ и ~3 * N операций на решение этой СЛАУ методом прогонки. Используя P процессоров, мы получим ~N/P + 6 * N / P операций, которые необходимо выполнить последовательно. Это означает 7 * N / P операций по сравнению с 4 * N для последовательного алгоритма. То есть ускорение последовательного алгоритма на 64 узлах составило бы 36.57142... . Реальное ускорение несколько больше, т. к. операции формирования СЛАУ имеют большую вычислительную сложность, особенно в сравнении с вычислением значений неизвестных на последнем этапе метода прогонки. Еще одним источником ускорения являются N ^ 2 операций по определению граничных условий в начале каждого шага по времени, которые также распараллеливаются на p процессоров.
Характеристики
Тип файла документ
Документы такого типа открываются такими программами, как Microsoft Office Word на компьютерах Windows, Apple Pages на компьютерах Mac, Open Office - бесплатная альтернатива на различных платформах, в том числе Linux. Наиболее простым и современным решением будут Google документы, так как открываются онлайн без скачивания прямо в браузере на любой платформе. Существуют российские качественные аналоги, например от Яндекса.
Будьте внимательны на мобильных устройствах, так как там используются упрощённый функционал даже в официальном приложении от Microsoft, поэтому для просмотра скачивайте PDF-версию. А если нужно редактировать файл, то используйте оригинальный файл.
Файлы такого типа обычно разбиты на страницы, а текст может быть форматированным (жирный, курсив, выбор шрифта, таблицы и т.п.), а также в него можно добавлять изображения. Формат идеально подходит для рефератов, докладов и РПЗ курсовых проектов, которые необходимо распечатать. Кстати перед печатью также сохраняйте файл в PDF, так как принтер может начудить со шрифтами.
















