
Структурирование информации в базах данных
Тема 26. Структурирование информации в базах данных
Под базой данных понимается некоторая унифицированная совокупность данных, совместно используемая персоналом/населением группы, предприятия, региона, страны, мира. Задача базы данных состоит в хранении всех представляющих интерес данных в одном или нескольких местах, причем таким способом, который заведомо исключает ненужную избыточность. В хорошо спроектированной базе данных избыточность данных исключается, и вероятность сохранения противоречивых данных минимизируется. Таким образом, создание баз данных преследует две основные цели: понизить избыточность данных и повысить их надежность.
Жизненный цикл любого программного продукта, в том числе и системы управления базой данных, состоит из стадий проектирования, реализации и эксплуатации.
Естественно, наиболее значительным фактором в жизненном цикле приложения, работающего с базой данных, является стадия проектирования. От того, насколько тщательно продумана структура базы, насколько четко определены связи между ее элементами, зависит производительность системы и ее информационная насыщенность, а значит – и время ее жизни.
Требования к базам данных
Итак, хорошо спроектированная база данных:
1. Удовлетворяет всем требованиям пользователей к содержимому базы данных. Перед проектированием базы необходимо провести обширные исследования требований пользователей к функционированию базы данных.
2. Гарантирует непротиворечивость и целостность данных. При проектировании таблиц нужно определить их атрибуты и некоторые правила, ограничивающие возможность ввода пользователем неверных значений. Для верификации данных перед непосредственной записью их в таблицу база данных должна осуществлять вызов правил модели данных и тем самым гарантировать сохранение целостности информации.
3. Обеспечивает естественное, легкое для восприятия структурирование информации. Качественное построение базы позволяет делать запросы к базе более “прозрачными” и легкими для понимания; следовательно, снижается вероятность внесения некорректных данных и улучшается качество сопровождения базы.
Рекомендуемые материалы
4. Удовлетворяет требованиям пользователей к производительности базы данных. При больших объемах информации вопросы сохранения производительности начинают играть главную роль, сразу “высвечивая” все недочеты этапа проектирования.
Следующие пункты представляют основные шаги проектирования базы данных:
1. Определить информационные потребности базы данных.
2. Проанализировать объекты реального мира, которые необходимо смоделировать в базе данных. Сформировать из этих объектов сущности и характеристики (атрибуты) этих сущностей (например, для сущности “деталь” характеристиками могут быть “название”, “цвет”, “вес” и т.п.) и сформировать их список.
3. Поставить в соответствие сущностям и характеристикам – таблицы и столбцы (поля) в нотации выбранной Вами СУБД (Paradox, dBase, FoxPro, Access, Clipper, InterBase, Sybase, Informix, Oracle и т.д.).
4. Определить атрибуты, которые уникальным образом идентифицируют каждый объект.
5. Выработать правила, которые будут устанавливать и поддерживать целостность данных.
6. Установить связи между объектами (таблицами и столбцами), провести нормализацию таблиц.
7. Спланировать вопросы надежности данных и, при необходимости, сохранения секретности информации.
Основные понятия, используемые в реляционных БД
В реляционной теории одним из главных является понятие отношения. Математически отношение определяется следующим образом. Пусть даны n множеств D1,D2,...,Dn. Тогда R есть отношение над этими множествами, если R есть множество упорядоченных наборов вида , где d1 - элемент из D1, d2 - элемент из D2, ..., dn - элемент из Dn. При этом наборы вида называются кортежами, а множества D1,D2,...,Dn - доменами. Каждый кортеж состоит из элементов, выбираемых из своих доменов. Эти элементы называются атрибутами, а их значения - значениями атрибутов. рис. a представляет нам графическое изображение отношения с разных точек зрения.
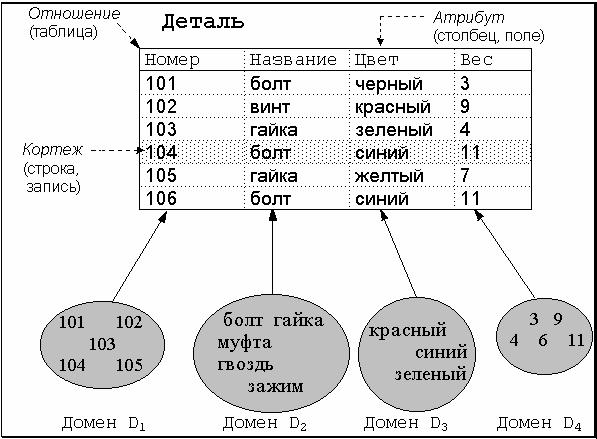
Легко заметить, что отношение является отражением некоторой сущности реального мира (в данном случае – сущности “деталь”) и с точки зрения обработки данных представляет собой таблицу. Поскольку в локальных базах данных каждая таблица размещается в отдельном файле, то с точки зрения размещения данных для локальных баз данных отношение можно отождествлять с файлом. Кортеж представляет собой строку в таблице, или, что то же самое, запись. Атрибут же является столбцом таблицы, или – полем в записи. Домен же представляется неким обобщенным типом, который может быть источником для типов полей в записи. Таким образом, следующие тройки терминов являются эквивалентными:
· отношение, таблица, файл (для локальных баз данных);
· кортеж, строка, запись;
· атрибут, столбец, поле.
Реляционная база данных представляет собой совокупность отношений, содержащих всю необходимую информацию и объединенных различными связями.
Атрибут (или набор атрибутов), который может быть использован для однозначной идентификации конкретного кортежа (строки, записи), называется первичным ключом. Первичный ключ не должен иметь дополнительных атрибутов. Это значит, что если из первичного ключа исключить произвольный атрибут, оставшихся атрибутов будет недостаточно для однозначной идентификации отдельных кортежей. Для ускорения доступа по первичному ключу во всех системах управления базами данных (СУБД) имеется механизм, называемый индексированием. Грубо говоря, индекс представляет собой инвертированный древовидный список, указывающий на истинное местоположение записи для каждого первичного ключа. Естественно, в разных СУБД индексы реализованы по-разному (в локальных СУБД – как правило, в виде отдельных файлов), однако, принципы их организации одинаковы.
Возможно индексирование отношения с использованием атрибутов, отличных от первичного ключа. Данный тип индекса называется вторичным индексом и применяется в целях уменьшения времени доступа при нахождении данных в отношении, а также для сортировки. Таким образом, если само отношение не упорядочено каким-либо образом и в нем могут присутствовать строки, оставшиеся после удаления некоторых кортежей, то индекс (для локальных СУБД – индексный файл), напротив, отсортирован.
Для поддержания ссылочной целостности данных во многих СУБД имеется механизм так называемых внешних ключей. Смысл этого механизма состоит в том, что некоему атрибуту (или группе атрибутов) одного отношения назначается ссылка на первичный ключ другого отношения; тем самым закрепляются связи подчиненности между этими отношениями. При этом отношение, на первичный ключ которого ссылается внешний ключ другого отношения, называется master-отношением, или главным отношением; а отношение, от которого исходит ссылка, называется detail-отношением, или подчиненным отношением. После назначения такой ссылки СУБД имеет возможность автоматически отслеживать вопросы “ненарушения“ связей между отношениями, а именно:
· если Вы попытаетесь вставить в подчиненную таблицу запись, для внешнего ключа которой не существует соответствия в главной таблице (например, там нет еще записи с таким первичным ключом), СУБД сгенерирует ошибку;
· если Вы попытаетесь удалить из главной таблицы запись, на первичный ключ которой имеется хотя бы одна ссылка из подчиненной таблицы, СУБД также сгенерирует ошибку;
· если Вы попытаетесь изменить первичный ключ записи главной таблицы, на которую имеется хотя бы одна ссылка из подчиненной таблицы, СУБД также сгенерирует ошибку.
Замечание. Существует два подхода к удалению и изменению записей из главной таблицы:
1. Запретить удаление всех записей, а также изменение первичных ключей главной таблицы, на которые имеются ссылки подчиненной таблицы.
2. Распространить всякие изменения в первичном ключе главной таблицы на подчиненную таблицу, а именно:
· если в главной таблице удалена запись, то в подчиненной таблице должны быть удалены все записи, ссылающиеся на удаляемую;
· если в главной таблице изменен первичный ключ записи, то в подчиненной таблице должны быть изменены все внешние ключи записей, ссылающихся на изменяемую.
Операции реляционной алгебры
1. В процессе преобразования базы данных (её нормализации) с целью устранения избыточности и повышения надежности часто необходимо разбить большие таблицы на более мелкие. Но как затем сформировать требуемый ответ на запрос пользователя, если нужные для этого данные хранятся в разных таблицах? Для этого в рамках реляционной алгебры разработаны следующие операции над отношениями:
2. Объединение R=R1И R2;
3. Пересечение R=R1З R2
4. Вычитание R=R1–R2;
5. Эти три операции выполняются над строками отношений и имеют полные аналоги с операциями над множествами. При этом требуется одинаковая арность отношений, участвующих в операции.
6. Декартово произведение R = R1*R2.
7. В результате получается отношение R, содержащее все попарные комбинации строк двух перемножаемых отношений R1 и R2. При этом если отношение R1 обладает арностью k1 и количеством строк s1, а отношение R2 – арностью k2 и количеством строк s2, то результирующее отношение R имеет арность k=k1+k2 и содержит в себе s=s1*s2 строк.
8. Проецирование на атрибуты R = ПРA1,…,An R1.
9. Здесь A1,…,An – атрибуты на которые происходит проецирование. В результате этой операции получается отношение, содержащее только указанные атрибуты исходного отношения. Количество строк в отношении при этом остается прежним.
10. Операция выборки R = ПРУСЛОВИЕ R1.
11. В результате этой операции из исходного отношения выбираются только те строки, которые удовлетворяют указанному условию. Число атрибутов в отношении при этом не меняется.
12. Операция соединения отношений по определенному условию.
Почему БД может быть плохой?
Приведем пример плохой БД. Пусть проектируется база “Питание”. Эту базу можно представить в виде одного отношения, представленного на рисунке.
Начинающий проектировщик будет использовать данное отношение в качестве завершенной БД. Действительно, зачем разбивать его на несколько более мелких отношений, если оно заключает в себе все данные? А разбивать надо потому, что при использовании такого единственного отношения возникает несколько проблем:
1. Избыточность. Данные практически всех столбцов многократно повторяются. Повторяются и некоторые наборы данных (Блюдо-Вид-Рецепт, Продукт-Калорийность, Поставщик-Город-Страна). Нежелательно повторение рецептов, некоторые из которых намного больше рецепта «Лобио». И уж совсем плохо, что все данные о блюде (включая рецепт) повторяются каждый раз, когда это блюдо включается в меню.
2. Потенциальная противоречивость (аномалии обновления). Вследствие избыточности можно обновить адрес поставщика в одной строке, оставляя его неизменным в других. Если поставщик кофе сообщил о своем переезде в Харбин и была обновлена строка с продуктом кофе, то у поставщика «Хуанхэ» появляется два адреса, один из которых не актуален. Следовательно, при обновлениях необходимо просматривать всю таблицу для нахождения и изменения всех подходящих строк.
3. Аномалии включения. В БД не может быть записан новый поставщик («Няринга», Вильнюс, Литва), если поставляемый им продукт (Огурцы) не используется ни в одном блюде. Можно, конечно, поместить неопределенные значения в столбцы Блюдо, Вид, Порций и Вес (г) для этого поставщика. Но если появится блюдо, в котором используется этот продукт, не забудем ли мы удалить строку с неопределенными значениями?
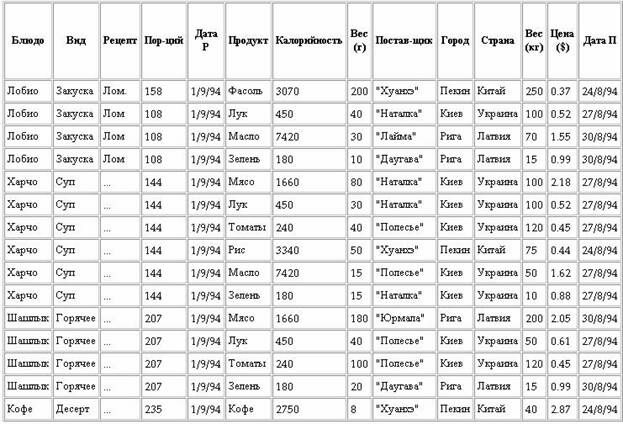
По аналогичным причинам нельзя ввести и новый продукт (например, Баклажаны), который предлагает существующий поставщик (например, "Полесье"). А как ввести новое блюдо, если в нем используется новый продукт (Крабы)?
4. Аномалии удаления. Обратная проблема возникает при необходимости удаления всех продуктов, поставляемых данным поставщиком или всех блюд, использующих эти продукты. При таких удалениях будут утрачены сведения о таком поставщике.
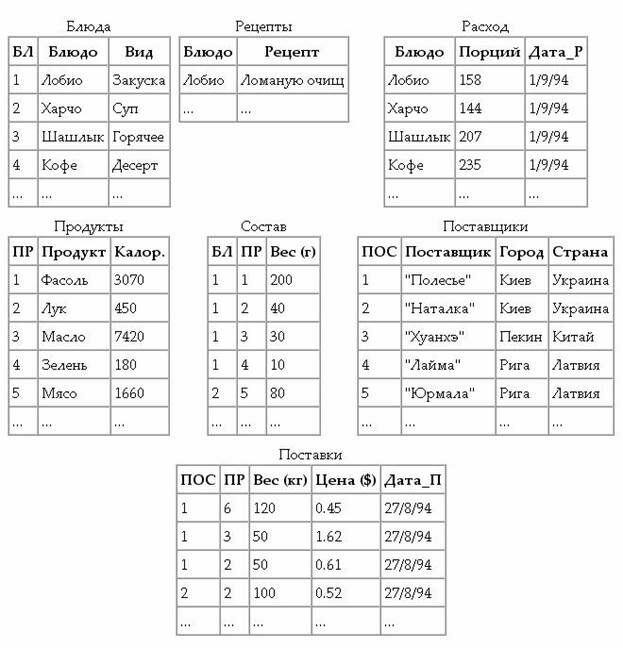
Многие проблемы этого примера исчезнут, если выделить в отдельные таблицы сведения о блюдах, рецептах, расходе блюд, продуктах и их поставщиках, а также создать связующие таблицы «Состав» и «Поставки» .
В полученной БД все еще много повторяющихся данных, находящихся в связующих таблицах (Состав и Поставки). Следовательно, в данном варианте БД сохранилась потенциальная противоречивость: для изменения названия поставщика с «Полесье» на «Днепро» придется изменять не только строку таблицы Поставщики, но и множество строк таблицы Поставки. При этом не исключено, что в БД будут одновременно храниться: "Полесье", "Палесье", «Днепро», «Днипро» и другие варианты названий.
Для исключения ссылок на длинные текстовые значения последние обычно нумеруют: нумеруют блюда в больших кулинарных книгах, товары (продукты) в каталогах и т.д. Воспользуемся этим приемом для исключения избыточного дублирования данных и появления ошибок при копировании длинных текстовых значений. Теперь при изменении названия поставщика «Полесье» на «Днепро» исправляется единственное значение в таблице Поставщики. И даже если оно вводится с ошибкой («Днипро»), то это не может повлиять на связь между поставщиками и продуктами (в связующей таблице Поставки используются номера поставщиков и продуктов, а не их названия). Окончательный вариант базы данных «Питание» приведен на следующем рисунке.
Нормализация таблиц
Нормализация – это разбиение таблицы на две или более, обладающих лучшими свойствами при включении, изменении и удалении данных. Окончательная цель нормализации сводится к получению такого проекта базы данных, в котором каждый факт появляется лишь в одном месте, т.е. исключена избыточность информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных.
Процесс нормализации заключается в приведении таблиц в так называемые нормальные формы. Существует несколько видов нормальных форм: первая нормальная форма (1НФ), вторая нормальная форма (2НФ), третья нормальная форма (3НФ), нормальная форма Бойса-Кодда (НФБК), четвертая нормальная форма (4НФ), пятая нормальная форма (5НФ). С практической точки зрения, достаточно трех первых форм – следует учитывать время, необходимое системе для “соединения” таблиц при отображении их на экране. Поэтому мы ограничимся изучением процесса приведения отношений к первым трем формам.
Этот процесс включает:
· устранение повторяющихся групп (приведение к 1НФ);
· удаление частично зависимых атрибутов (приведение к 2НФ);
· удаление транзитивно зависимых атрибутов (приведение к 3НФ).
Приведение к первой нормальной форме
Когда поле в данной записи содержит более одного значения для каждого вхождения первичного ключа, такие группы данных называются повторяющимися группами. 1НФ не допускает наличия таких многозначных полей. Иными словами, значение каждого атрибута должно быть атомарным. Полная формулировка 1-й НФ следующая:
Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Приведение ко второй нормальной форме
Следующий важный шаг в процессе нормализации состоит в удалении всех неключевых атрибутов, которые зависят только от части первичного ключа. Такие атрибуты называются частично зависимыми. Неключевые атрибуты заключают в себе информацию о данной сущности предметной области, но не идентифицируют ее уникальным образом. В теории вторая нормальная форма определяется через понятия функциональной зависимости:
Вместе с этой лекцией читают "2 Информационно-коммуникационные возможности".
Таблица находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом.
Функциональная зависимость. Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными.
Полная функциональная зависимость. Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А.
Приведение к третьей нормальной форме
Третий этап процесса приведения таблиц к нормальной форме состоит в удалении всех неключевых атрибутов, которые зависят от других неключевых атрибутов. Каждый неключевой атрибут должен быть логически связан с атрибутом (атрибутами), являющимся первичным ключом. Таким образом:
Таблица находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и не одно из ее неключевых полей не зависит функционально от любого другого неключевого поля.



















