61982 (674260), страница 4
Текст из файла (страница 4)
Ребёнок
Вес=30

Миша
Вес=32
Значение нижнего уравнения должно лежать внутри границ определённого в верхнем уравнении.
R
Человек
Вес=2-200
Ребёнок
Вес=2-50
Миша
Вес=32
Если значение не задано то оно наследуется из слота верхнего уравнения, а если оно задано , то наследование игнорируется.
О
Человек
Вес=60
Ребёнок
Вес=30
Миша
Вес=32
Лекция 11 3.12.99
Сочетание сетевой и фреймовой модели в системе представления знаний OPS-5
В этом языке есть продукционные правила и базы данных
<Аз-элемент>::=(<объект> {|<атрибут> <значение>}+)
{}+ - Может повторятся несколько раз
<Элемент –вектор>::=({ значение})
<ЭРП>::=< аз-элемент> | < элемент-вектор>
( Вещество ![]() класс кислота
класс кислота
![]() имя
имя ![]()
![]() цвет бесцветная )
цвет бесцветная )
(Порядок – задач: Источник, утечки Ограждения)
Что собой представляют правила :
<Правило>::=(Р<имя правила> <посылка> ![]() <заключение>)
<заключение>)
<Посылка>::={<условие>}+
<Условие>::=<образец> | - <образец>
<Образец>::= <простой образец> | <образец с дезъюнкцией> | <образец с конъюнкцией>
<Простой образец>::=({значение>}+) |
# ( Порядок задач <первый> )
(<Объект> [{![]() <атрибут> <значение>}+] )
<атрибут> <значение>}+] )
# (Вещество )
В образце не обязательно указываются все атрибуты данного класса , т.е. мы можем записать
(Вешество ![]() класс кислота
класс кислота
![]() имя <вещ> )
имя <вещ> )
т.е. переменная кислота –вещ получит значение ![]()
<образец с дизъюнкцией>::= (<объект> {![]() <атрибут> <<{< значение>}+>>}+)
<атрибут> <<{< значение>}+>>}+)
Значение с соответствующего атрибута элемента работой памяти должно совпадать с одним из элементов указанных в данном листе, хотя бы с одним. Эти значения задаются конкретными словами.
# (Вещество ![]() класс кислота
класс кислота
![]() имя <вещ>
имя <вещ>
![]() цвет <<бесцветный желтый>> )
цвет <<бесцветный желтый>> )
<образец с конъюнкцией>::= (< объект> {![]() < атрибут>{{< значение>}+}}+)
< атрибут>{{< значение>}+}}+)
Список значений может задаваться и в виде ограничений
# (Двигатель ![]() мощность {<х> 100 <х> 200} )
мощность {<х> 100 <х> 200} )
(Двигатель ![]() мощность 160)
мощность 160)
:={}+
::=(make | remove <ссылка> | (modif <ссылка> {![]() <атрибут>< значение>} +)
<атрибут>< значение>} +)
# (Р координировать _а
(цель ![]() состояние активный
состояние активный
![]() имя координировать )
имя координировать )
Если цель находится в состоянии координировать и порядок задач не определён,
то создать
(Порядок задач ) –>
(make цель ![]() состояние активный
состояние активный
![]() имя упорядочить задачи)
имя упорядочить задачи)
( modif1
modif1 ![]() состояние ожидания))
состояние ожидания))
ссылка указывает , что модифицироваться будет элемент рабочей памяти
Стратегия решения задач основана на явном задании цели
Выполнение
-
сопоставление с элементами памяти в результате формируется конфликтное
множество правил
-
Выбор правил из конфликтного множества
-
Выполнение действий, указанных в заключении правил
Выполняется до тех пор, пока не будет достигнута цель.
Приобретение знаний
-
извлечение знаний из источника , преобразование их в нужную форму , а также
перенос в базу знаний интеллектуальной системы.
Знания делятся на :
-
объективизированные ;
-
субъективные
Объективизированные – знания , представленные во внешних источниках –
книгах, журналах, НИР.
-
форматизированные, т.е. представлены в виде законов, формул, моделей, алгоритмов.
Субъективные – знания, которые являются экспертными и эмперическими не представлены
во внешней форме.
Знания экспертом является неформализованными, представляют собой множество эвристических приёмов и правил, позволяют находить подходы к решению задач и выдвигать гипотезы , которые могут быть подтверждены или опровержены.
Знания могут быть получены в процессе наблюдения за каким-либо объектогм.
Режимы работы инженера по знаниям, консультолога в процессе приобретения знаний.
-
протокольный анализ
-
записываются рассуждения вслух в процессе решения задач.
О.с. составляются протоколы, которые анализируются
-
Интервью - ведется диалог с экспериментом, направленный на приобретение знаний.
-
Игровая имитация профессиональной деятельности.
Методы интервьюирования.
-
Рубление на ступени выделяются связи, позволяющие строить иерархические структуры
-
Репертуальная рещётка предлагаются 3 понятия и требуется назвать отличие 2-х понятие 3-его. Эксперту предлагается пара понятий и требуется назвать общие свойства =>
сформировать классы.
Методика работы конитолога по формированию поля знания
Включает 2 этапа
-
подготовительный
1.1. Чёткая подготовка задачи , которая должна решать система
-
Знакомство конит с литовой
-
Выбор экспертов
-
Знакомство экспертов с копией
-
Знакомство эксперта с популярной методикой по искусственному интеллекту
-
Формирование с копии поля знания
-
Основной этап
-
накачка поля знания в режиме
-
командная работа косметолога – анализ протокола, определение связей между понятиями , готовит вопросы к эксперту
-
Подкачка поля знания – задача вопросов эксперту
-
Формализация концептуальной задачи.
-
Проверка полноты модели
Если модель неполная , то используется 2-ое приближение.
Лекция 12 10.12. 99.
Нечёткие множества
[10,40] – толщина изделий
малая [10;20]
средняя [20;30]
большая [30;40]
с тепень
тепень ![]()
принадл
1
0.7
0.1
 х
х
10 15 40 толщина изделий
![]() - нечёткое множество
- нечёткое множество
х - универсальное множество
![]() х - образуют совокупность пар А
х - образуют совокупность пар А
![]()
![]() - называется функцией принадлежности нечёткого множества .
- называется функцией принадлежности нечёткого множества .
Значения функции принадлежности для конкретного элемента Х называется
Степенью принадлежности
![]() - носитель нечёткого множества
- носитель нечёткого множества
![]()

![]()
Нормальным нечётким множеством называется множество для которого
![]()
![]()


 0.6
0.6
![]() - нечёткое множество
- нечёткое множество
Х - универсальное множество
![]() Х - образуют совокупность пар А
Х - образуют совокупность пар А
![]()
![]() :
: ![]() - называется функцией принадлежности нечёткого множества .
- называется функцией принадлежности нечёткого множества .
Значение функции принадлежности для конкретного элемента Х называется степенью
принадлежности
![]() - носитель нечёткого множества
- носитель нечёткого множества
![]() &
&![]()
Нормальным нечётким множеством называется множество для каждого
![]()
![]()
 0,6 x
0,6 x
Если приводить к нормальной форме => нужно поделить все её значения на ![]() .
.
Пример:
Пусть функция принадлежности задаётся целым числом от 10 до 40
Определить понятие малая толщина изделия.

![]()
![]()
 1 . .
1 . .
. ![]()
.
.
.
.

 | | | | | | | | x x
| | | | | | | | x x
10 11 12 13 14 15 16 17 18 18
Операции над нечёткими множествами
-
Объединение нечётких множеств
![]()
![]()
-
Пересечение нечётких множеств
![]()
![]()
-
Дополнение нечёткого множества
![]()
![]()
![]()
![]()






![]()
![]() x x
x x
A
x

Н
AB
x


ачало 12 и 13 лекции.

-
Декартовое произведение нечетких множеств.
A1,A2,….,An
x1,x2,…,xn
x1 X1 x2 X2 … xnXn
A1 xA2 x … xAn = {<x (x1,x2,…,xn )/( x1,x2,…,xn )>}
x (x1,x2,…,xn ) = min{A1 (x1), A2 (x2)…An (xn) }
A = {, , }
B = {, }
A xB = {, , , , , }
-
Возведение нечеткого множества в степень.
An = {<An(x)/x>}
A2 = con(A) - концентрация
A
1
x


A
1 A2
A0.5
0 x2 < x x0.5 > x




A0.5 = dil(A) – растяжение



Методы определения функции принадлежности.
Немного больше 2. От 0 до 5.
| x | 0 | 1 | 2 | 3 | 4 | 5 |
| n1 | - | - | - | 10 | 8 | 4 |
| n2 | 10 | 10 | 10 | - | 2 | 6 |
A = n1 / (n1 + n2)
A (0) = 0
A (1) = 0
A (2) = 0
A (3) = 1
A (4) = 0.8
A (5) = 0.4
Метод рангирования.
ч
u
p
ч
u
p
u ч
р
0 Xчастота
редко иногда часто






























Н
L
x


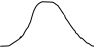


x
р u ч 1
ечеткая переменная.
<, x, A>
- имя нечеткой переменной
х – область ее определения
А – смысл, нечеткое множество определяет семантику нечеткой переменной
Лингвистическая переменная.
<, T, Х, G, M>
- имя лингвистической переменной
Т – базовая терм множество – образует имена нечетких переменных {редко, иногда, часто}, являющихся лингвистическими переменными
Х – носитель лингвистических значений [0; 1] – область определения
G – синтаксическая процедура
М – семантическая процедура
Синтаксическая процедура в виде грамматических терминов, символы которых составляют термы из терм множеств {и, или, не}, модификаторы типов {очень, слегка, не и т.д.}
- частота
Т = {редко, иногда, часто}
X = [0;1]
Не редко
Очень часто
Такие термины вместе с исходными образуют производную терм множества.
Т* = Т G (T)
Семантические процедуры позволяют переписать термо-нечеткую семантику.
М(1 или 2) = А1 А2
(1 , х1 , А1)
(2 , х2 , А2)
М(1 и 2) = А1 А2
М(^) = ^А1
М(очень ) = con (A )
М(слегка ) = dil (A )
Сценарий.
Является классом фреймовых моделей представления знаний, где в обобщенной и структурной форме представлены знания о последовательности действий, событий типичных для предметной области. Рассмотрим стереотип каузальный сценарий – определяет последовательность действий необходимых для достижения целей, это фреймовая модель.
(kcus имя:
имя слота 1(значение слота 1);
имя слота 2(значение слота 2);
…
имя слота n(значение слота n))
(kcus
деятель
цель деятеля
посылка
ключ
следствие
системное имя)
Посылка определяет действия, которые должны быть выполнены раньше ключевого действия, необходимые для его действия. Последствие – заключительное действие. Системное имя – сценарий.
(kcus «тушение пожара»:
деятель (S: )
цель деятеля (С: «прекращение пожара»)
П11, П12 посылки (cus: «поиск средств тушения»R1, «транспортные средства тушения»)
К1 ключ (f: «использование средств тушения для полного прекращения огня»)
следствие (Р: «прекращение огня»)
системное имя (sys: cus*1))
R1 – быть раньше
(kcus «поиск средств тушения »:
деятель (S: )
цель деятеля (С: «нахождение средств тушения»)
П121, П22 посылки (cus: «определение координат местонахождения средств тушения»R1, «перемещение к месту нахождения средств тушения»)
К2 ключ (f: «схватывание средств тушения»)
следствие (Р: «нахождение у места расположения средств тушения»)
системное имя (sys: cus*2))
(kcus «транспортировка средств тушения к месту пожара»:
деятель (S: )
цель деятеля (С: «доставка средств тушения к месту пожара»)
П31, П32 посылки (cus: «наличие средств тушения»R1, «определение координат места пожара»)
К3 ключ (f: «движение к месту пожара»)
следствие (Р: «нахождение на месте пожара средств тушения»)
системное имя (sys: cus*3))
Пополнение знаний на основе сценария.
<посылки>R:
Последовательность действий:
Д = cus: П11 R1 cus: П12 R1 K1 =
П21R1П22R1K2 П31R1П32R1K3
= П21R1П22R1K2 R1 П31R1П32R1K3 R1 K1
Посылки определяют действия, которые должны быть выполнены раньше ключевого действия, необходимы для его действия. Следствие заключительное действие. Системное имя сценарий.
Пополнение знаний на основе псевдофизических логик.
Р1 – посадка самолета
Р2 – подача трапа
Р3 – выход пассажиров из самолета
Р4 – подача автобуса
Р5 – прибытие на аэровокзал
Структура текста на лингвистическом уровне представляется следующей формулой:
TS = PR4dt&P1R3 10,P2&P2R1P3&P4R3 2,P5
t = 15 часов 20 минут
PR4dt , P1R3 10,P2 P2R4 dt + 10
P1R3 10,P2 P1R1P2
P4R3 2,P5 P4R1P5
TS* = P1R1P2& P1R1P3& P2R1P3& P4R1P5
Модели и методы обобщений знаний.
Под обобщением понимается процесс получения знаний, объясняющих имеющиеся факты, а так же способных классифицировать, объяснять и предсказывать новые факты. Исходные данные представляются обучающей выборкой. Объекты могут быть разбиты на классы. В зависимости от того, заданы или нет априорные разбиения объектов на классы, модели обобщения делятся на модели обобщения по выборкам и по классам.
Кi
+ = {01+, 02+…0nj+} – положительная выборка.
Может задаваться отрицательная выборка - = {01-, 02-…0ьj-}
Требуется найти такое правило, которое позволяет установит, относится или нет объект к классу Kj.
В моделях обобщения по данным выборка представляется множеством объектов класса. Методы обобщения делятся на методы обобщения по признакам и структурно-логические методы обобщения.
Z = {z1, z2, …, zr}
Zi = {zi1, zi2, …, zini}
Объект характеризуется множеством значений признаков Qi = {z1j1, z2j2, …, zrjr}.
Структурно-логические методы обобщения используются для представления знаний об объектах, имеющих внутреннюю структуру среди структурно-логических методов. Можно выдвинуть два направления: индуктивные методы нормального исчисления и методы обобщения на семантических сетях.
Алгоритм обобщения понятий по признакам.
hij =
1, если i-ый признак имеет j-ое значение
0, в противном случае
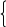
Правила определения принадлежности объектов к некоторому классу представляются в ряде логических формул элементами которых являются hij и функции
Пример:
Z = {z1, z2} {пол, возраст}
Z1 = {z11, z12} {м, ж}
Z2 = {z21, z22, z23} {молодой, средний, старый}
j+ = {01+, 02+} j- = {01-, 02-, 03-}
01+ = (z11, z21) 02+ = (z11, z22)
01- = (z11, z23) 02- = (z12, z21) 03- = (z12, z22)
&i hij - обобщенное конъюнктивное понятие
0 = max(xij – 1/i), где 0 – критерий, xij – частота появления некоторого значения признака, i – количество признаков.
Пример:
0 = 3/5 – 1/2 = 0.1
j+ = {01+, 02+} j- = {01-}
+
-
-1+ = 0 -1- = {02-, 03-}


j+
j-
-1+
-1-
















