
Практические вопросы реализации расслоенного случайного отбора
Практические вопросы реализации расслоенного случайного отбора
При планировании расслоенной случайной выборки нужно ответить на следующие вопросы:
1. Какую переменную(ые) взять в качестве расслаивающей?
2. Каким должно быть количество слоев?
3. Как осуществить расслоение совокупности по количественной переменной на несколько слоев?
4. Каким должен быть общий объем выборки и его размещение по слоям?
1. Выбор расслаивающей переменной
Для формирования слоев обычно используются:
Рекомендуемые материалы
· качественные переменные для обеспечения представительности выборки в целевых группах;
· количественные переменные для включения в слои близких по «размеру» единиц.
Цель – получить  по возможности малыми. Однако на практике значения неизвестны, поэтому в основе выборки необходимо иметь вспомогательную переменную, переменную x, которая была бы хорошо коррелированна с целевым признаком y.
по возможности малыми. Однако на практике значения неизвестны, поэтому в основе выборки необходимо иметь вспомогательную переменную, переменную x, которая была бы хорошо коррелированна с целевым признаком y.
Проблема: расслоение может быть удачным для одной переменной и совершенно быть не эффективным для другой.
2. Определение количества слоев
Теоретически чем больше слоев по количественной переменной тем оценка точнее.
Однако, практически существует "критический уровень" равный 5 – 6 слоям, после которого:
· понижение уровня дисперсии не существенно;
· риск при отсутствии ответов в слоях получить объем выборки  или даже 0 существенно возрастает.
или даже 0 существенно возрастает.
3. Расслоение по количественной переменной.
Рассмотрим два зарекомендовавших себя на практике способа нахождения оптимальных границ слоев для количественной переменной.
Правило Экмана (1959).
Границы слоев выбираются такими, чтобы
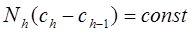
где  - границы слоев.
- границы слоев.
 , а
, а  ;
;
x – вспомогательный количественный признак.
Пример 2.
Нетрудно убедиться в том, что в примере 1 оптимальные границы следующие:



так как имеем
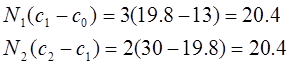
Пример 3. Правило «Корень из F ».
Пусть дано распределение вспомогательного признака x в основе выборки. Разобьем интервал значений признака x на некоторое количество, например, 20 равных интервалов длиной

Подсчитаем число единиц ( ) на каждом из интервалов и вычислим соответствующие значения
) на каждом из интервалов и вычислим соответствующие значения  .
.
Таблица 1.
Распределение основы выборки по интервалам группировки
| Интервал группировки по признаку x (в %) |
| Накопленные значения | Интервал группировки по признаку x (в %) |
| Накопленные значения |
| 0-5 5-10 10-15 15-20 20-25 25-30 30-35 35-40 40-45 45-50 | 3 464 2516 2157 1581 1142 746 512 376 265 207 | 58,9 109,1 155,5 195,3 229,1 256,4 279,0 298,4 314,7 329,1 | 50-55 55-60 60-65 65-70 70-75 75-80 80-85 85-90 90-95 95-100 | 126 107 82 50 39 25 16 19 2 3 | 340,3 350,6 359,7 366,8 373,0 378,0 382,0 386,4 387,8 389,5 |

В столбце накопленные значения вычисляются так:
 ;
;  и т.д.
и т.д.
Приведенные в табл.1 данные показывают, что распределение асимметрично и его медиана расположена на левом конце интервала значений признака (x).
Пусть требуется определить границы слоев: H = 5.
Поскольку максимальное накопленное значение равно 389,5, то оптимальными границами на этой шкале будут концы равных интервалов длиной 389,5/5 = 77,9. А именно:
77,9; 155,8; 233,7; 311,6.
Соответствующие ближайшие значения границ образованных 20 интервалов на шкале признака (x) будут искомыми границами слоев.
Таблица 2.
Распределение основы выборки
| Слой № | |||||
| 1 | 2 | 3 | 4 | 5 | |
| Границы слоя Накопленные значения | 0-5% 58,9 | 5-15% 96,6 | 15-25% 73,6 | 25-45% 85,6 | "12 Уравнение Бернулли" - тут тоже много полезного для Вас. 45-100% 74,8 |
Замечание.
Накопленные значения  в слоях должны быть приблизительно одинаковыми. Однако для первых двух интервалов сильно разнятся (58,9 и 96,6). Чтобы улучшить расслоение нужно перегруппировать эти два слоя, что приведет к неравной длине интервалов.
в слоях должны быть приблизительно одинаковыми. Однако для первых двух интервалов сильно разнятся (58,9 и 96,6). Чтобы улучшить расслоение нужно перегруппировать эти два слоя, что приведет к неравной длине интервалов.
В случае когда интервалы группировки исходного распределения признака (x) разной длины, способ разбиения шкалы меняется. Например, если длины последовательных интервалов составляют d и K*d соответственно, то значение для последующего интервала при построении ряда накопленных значений умножается на  .
.



















